







目录
Python的复杂数据类型包括组合数据类型和自定义数据类型。组合数据类型有:str(字符串)、tuple(元组)、list(列表)、dict(字典)、set(集合)。组合数据类型的名称本身也是函数的名称,可以用于类型转换。例如:
L = list("abcd") #L值为['a','b','c','d']
Python中的函数isinstance(x,y)用于判断x是不是y类型的数据。此处y是类型的名称。例如:
a = "1233"
print(isinstance(a,str)) #>>True
print(isinstance("123",int)) #>>False
b=[1,3] #b是一个列表
print(isinstance(b,list)) #>>TruePython中的len函数用于求组合数据类型中元素的个数。例如,求字符串长度,列表元素个数:
print(len("12345")) #>>5 求字符串长度
print(len([1,2,3,4]) #>>4 求列表长度
print(len((1,2,3))) #>>3 求元组长度
print(len({1,2,3})) #>>3 求集合元素个数
print(len({'tom':2,'jack':3})) #>>2 求字典元素个数组合数据类型中的字符串和元组是不可以修改的。列表、字典和集合可以修改。自定义数据类型也叫“类”,在本章最后一节和第13章讲述。
6.1 Python 变量的指针本质
Python中所有的变量,都是指针。所有可赋值的东西都是变量,因此都是指针。列表的元素是可赋值的,因此列表的元素就是指针。指针的本质是内存地址。可以将指针理解为一个箭头,它指向内存单元中存放的数据。变量是箭头,对变量进行赋值,就是将该箭头指向内存中的某处,而不是改写该箭头指向的地方的内容。请注意:其他程序设计语言中的变量,未必是上述的情况。
也有的教材称Python变量是“引用”,和这里说的指针含义相同。但在其他语言里,“引用”和“指针”未必是一个意思。
a = 3
b = 4
对变量赋值,就是让变量指向某处。上面两条赋值语句的效果,可以理解为图6.1.1。a是个指针,指向内存中某处存放的3。b一样是指针,它指向4。用一个变量对另一个变量进行赋值,就是让两个变量指向相同的地方。因此,若再执行:
a = b
产生的效果如图6.1.2所示。

a指向了b指向的地方,所以a的值也变成4。我们说变量a的值是4,归根到底是在说:a指向4。
Python中有两个运算符,"is"和"==",含义有所不同,但有些类似。aisb为True,说的是a和b指向同一个地方;而a==b为True,说的是a和b指向的地方的内容相同,但a和b未必指向同一个地方。Python中有一个函数id(x),能求表达式x的id。id不能说是内存地址,但类似于内存地址。两个变量如果指向同一个地方,等价于它们的id相同。例如:
a = [1,2,3,4] #a指向列表[1,2,3,4]
b = [1,2,3,4] #b指向另一个列表[1,2,3,4]
print(a == b) #>>True
print(a is b) #>>False
c = a
print(a == c) #>>True
print(a is c) #>>True
a[2] = "ok"
print(c) #>>[1,2,'ok',4]
print(id(a) == id(b)) #>>False
print(id(a) == id(c)) #>>True上面程序执行完第5行时,效果如图6.1.3所示。
内存中有两份列表[1,2,3,4],a和b分别指向它们。因此a和b指向不同的地方,但是它们指向的地方存放的内容是一样的。故第3行输出True而第4行输出False。第5行使得c与a指向同一份列表。因此第6、7行都输出True。
第8行修改了a[2],情况变为如图6.1.4所示。

因为c和a指向同一个地方,所以a的内容变了,c的内容自然也变。所以输出c,结果就是[1,2,'ok',4]。
常见错误:初学者经常会写出a=b=[]这样的语句,本意是形成a、b两个不同的空表。但实际上这么写的结果,a、b都指向同一张列表,往a里添加元素,就等于往b里添加元素。
对于int、float、complex、str、tuple类型的变量a和b,只需关注a==b是否成立,一般不需要关注aisb是否成立。因为这些数据本身都不会更改,不会产生a指向的内容变了,b指向的内容也跟着变的情况。
对于list、dict、set类型的变量a和b,a==b和aisb的结果都需要关注。因为这些数据本身会改变,有可能发生改变了a指向的内容,b指向的内容也会改变的情况。
本书中说a和b相等,或a和b的值相等,意思是a==b成立。而aisb可能成立,也可能不成立,要看具体情况。
因为列表的元素可以被赋值,因此,列表的元素其实也是指针。
a = [1,2,3,4]
b = [1,2,3,4]
执行完上面这两条语句,准确的效果如图6.1.5所示。
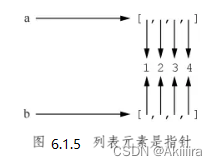
a和b的每个元素,如a[0],b[1],都是指针。a[0]和b[0]没有分别指向不同的两个1,是因为1本身不可变,没有必要保有两份。若对a[0]进行赋值,那就是让a[0]指向别处,而不是将a[0]所指向的那个1改成别的内容。所以,假如a[0]被赋成别的值,b[0]并不会受影响,它仍然指向1。
Python函数的参数也是指针。Python函数的形参是实参的复制即形参和实参指向同一个地方。对形参赋值就是让形参指向别处,当然不会影响实参。例如:
def Swap(x,y):
tmp = x
x = y
y = tmp
a,b = 4,5
Swap(a,b)
print(a,b) #>>4 5进入Swap函数时,x等于a,y等于b。Swap函数执行的过程中交换了x,y的值,但这并不会影响a和b。在函数中的tmp=x刚执行完时,效果如图7.1.6所示。
此刻x,y分别是a和b的复制,即x和a同指向4,y和b同指向5。tmp=x使得tmp也指向4。Swap函数执行完后,x和y的值交换了,本质上是说x和y交换了它们的指向,因此情况变成图6.1.7所示。
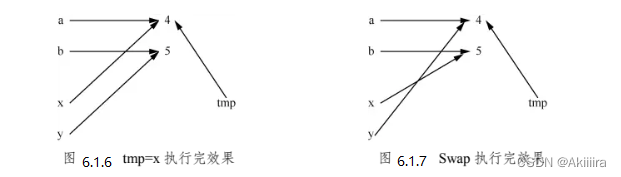
显然,a和b的指向不会发生任何变化,它们的值自然不变。
但是如果函数执行过程中,改变了形参所指向的地方的内容,则实参所指向的地方内容也会被改变。例如:
def Swap(x,y):
tmp = x[0]
x[0] = y[0] #请注意若x,y是列表,则x[0],y[0]都是指针
y[0] = tmp
a = [4,5]
b = [6,7]
Swap(a,b) #进入函数后,x和a指向相同地方,y和b指向相同地方
print(a,b) #>>[6,5] [4,7]这个程序中,Swap(a,b)使得a和b的下标为0的元素发生了交换。这是因为,x和a指向同一张列表[4,5],y和b指向同一张列表[6,7]。因此x[0]就是a[0],y[0]就是b[0]。进入Swap函数,执行完tmp=x[0]时,情况如图6.1.8所示。Swap交换了x[0]和y[0],也就交换了a[0]和b[0]。因此该函数执行完时,情况如图6.1.9所示。
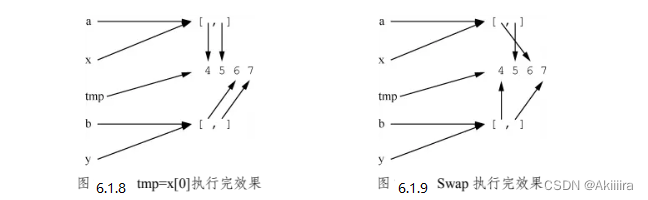
由于a和x指向相同的地方,所以x[0]变了,a[0]自然也变。b和y的关系亦然。函数的返回值也是指针。假设函数中的返回语句是returnx,如果x是变量,则返回值和x指向相同的地方;如果x是一个非变量的表达式,那么返回值指向这个表达式的计算后的值。可赋值的东西都是指针,但是指针未必都可赋值。。例如函数的返回值,就是不可赋值的。比如f是个无参数的函数,f()的返回值就是指针。a=f()是用f的返回值对a进行赋值,使得a和f的返回值指向同一个地方。但f()=100这种写法是不可行的。
6.2 字符串详解
6.2.1 转义字符
在字符串中,“\”及其后面的某些字符会构成转义字符,即两个字符当一个字符看。例如:
print("hello\nworld\tok\"1\\2")输出:
hello
world ok"1\2
'\n'并不是两个字符,'\'和后面的'n'被合在一起当作一个字符看待,这个字符就是换行符,于是在输出时,hello后面换行了。因此,我们说'\n'是一个转义字符,因为它的含义变化了。同理,'\t'也不是两个字符,它也是一个转义字符,代表制表符,所以输出时,world和ok之间会有几个空格。
'\"'也是转义字符,它代表双引号。在一个以双引号括起来的字符串里面,如果出现了双引号,可能会让人比较困惑,因为双引号本来会标志字符串的结束。为避免这种困惑,在字符串里面可以用'\"'来表示双引号。当然,改用单引号括起包含双引号的字符串也能解决这个麻烦。另外,'\''也是转义字符,就代表单引号。
如果想在字符串里面包含字符'\'怎么办呢?只写一个'\'是不保险的,因为它有可能和它后面的那个字符合并起来被当作转义字符看待。Python规定字符串里连续的两个'\'会被当作一个'\'看待,因此保险的办法就是用两个'\'表示一个'\'。字符串'a\\c'其实只包含3个字符,print出来就是a\c。
并不是所有字符出现在'\'后面,都会和'\'构成转义字符,例如:
print('\d')会输出:
\d
因为'd'不会和'\'合在一起被当作一个转义字符,所以'\\d'和'\d'其实一样。而:
print('a\ac')会输出:
ac
因为'a'会和'\'合在一起被当作一个转义字符,这个转义字符是个一般不会用到的怪字符,也没法正常显示。
记住哪些字符跟在'\'后面会形成转义字符,哪些不会,是没有必要的。用到的时候试一下即可。需要在字符串里面表示'\'的时候,不妨都写'\\'。
Python也照顾了讨厌转义字符的程序员。只要在字符串前面加'r',那么字符串里面的'\'就真的只是'\',不会起转义的作用了,实在是非常贴心:
print(r'a\nb') #>>a\nb
print(r"a\\b\tc\'d") #>>a\\b\tc\'d常见错误:'\n'这样的转义字符,只能出现在字符串里面,必须用各种引号括起来。print(a\nb) 不合法,不会打出a的值,然后换行,再打出b的值。不要笑,这是不止一个初学者会犯的错误。
顺便提一下,Python中还有u打头的字符串,如u'ok你好',和普通字符串没任何区别。
6.2.2 三单引号和三双引号字符串
Python是作者见过的最重视字符串的语言。其他语言一般只有一种字符串,就是用双引号括起来的,Python却把字符串玩出了各种花样。
如果想在字符串中不使用'\'转义就可以自由使用单引号和双引号,还希望字符串多行,那么可以写三单引号括起来的字符串。例如:
print('''三单引号的\n字符串。
He said:'I said:"I'mok."'
ONCLICK="window.history.back()"></FORM>
<BODY></HTML>/''')程序输出:
三单引号的
字符串。
He said:'I said:"I'mok."'
ONCLICK="window.history.back()"></FORM>
<BODY></HTML>/
把三单引号换成三双引号"""也是一样的效果。
有一种所谓的Python的多行注释,是个“以讹传讹”的典型例子。几乎每本作者读过的教材,和无数网上资料都说,Python支持以'''(或""")开头和结尾的多行注释。例如下面这个可以运行的程序中的第2行到第5行就是“多行注释”:
a = input()
'''
this is comment
这里是注释
'''
print(a)
"那这个岂不也是注释"
print("hello")其实这所谓“多行注释”(以下简称“伪注释”),并不是注释,而是字符串。在Python开发环境中,“伪注释”呈现字符串的颜色,而不是注释的颜色。而且,“伪注释”开头的'''并不能随意缩进,这充分证明它不是注释。如果它也能算注释,那么上面程序第7行也可以说是单行注释,岂不字符串就是注释?这成何体统。使用“伪注释”,可能没有什么伤害,但业余性极强。在作者看来甚至很好笑,因为其性质和声称下面这条没用的赋值语句是“注释”一样。
x = "本条语句是注释哦。下面这段程序的功能是统计存款总数……"
6.2.3 在字符串中使用编码代替字符
字符串中的'\u'是一个转义字符,它后面必须跟4个十六进制数字('0'~'9'和'A'~'F',大小写均可),代表一个字符的Unicode编码。例如,'a'的Unicode编码是0x0061,'好'的Unicode编码是0x597d,因此,print("k\u0061\u597dQ看")输出:
ka好Q看
可以看到,在字符串中,用'a'的编码'\u0061'可以替代'a',用'好'的编码'\u597d'可以替代'好'。
字符串中的'\x'也是一个转义字符,它后面必须跟2个十六进制数字,代表一个字符的ASCII编码。例如,print("\x61\x62好a高\x63")输出:
ab好a高c
因为'a'的ASCII编码是十六进制的61。
6.2.4 字符串的切片
字符串的切片分为两种。一种是子串,即字符串中连续的一部分,当然也可以是整个字符串;另一种是抽取字符串中不连续但相同间隔的若干字符,按原顺序拼成的字符串。
若a是字符串,则a[x:y]可以表示a的子串。其中,x,y都是值为整数的表达式。a[x:y]所表示的子串,起点是下标为x的字符,终点是下标为y的字符,但是终点不算在内。x也可以省略不写,那么起点就是字符串开头;y也可以省略不写,那么子串就一直取到字符串的最后一个字符(最后一个字符也算)。如果y大于等于字符串长度,则一直取到最后一个字符。例如:
a = "ABCD"
print (a[1:2]) #>>B下标为2的字符'C'不算在内
print (a[0:-1]) #>>ABC下标为-1的字符'D'不算在内
print (a[-3:-1]) #>>BCprint(a[2:])#>>CD终点省略就是一直取到最后一个字符
print (a[:3]) #>>ABC起点省略就是从头开始取
print("abcd"[2:3]) #>>c可以用a[x:y:z]来从字串a中抽取若干字符拼成一个字符串。抽取字符的规则是:以a[x]为起点,每隔|z-1个字符取一个,终点为a[y](但是终点a[y]不能取)。z是正数,则从左往右取;z是负数,则从右往左取。x,y可以省略。如果x省略,则是从头开始取,如果y省略,则一直可以取到最后一个字符。如果x,y都省略,则从头取到尾或从尾取到头:
print("12345678"[1:7:2]) #>>246
print("1234"[3:1:-1]) #>>43
print("12345678"[7:1:-2]) #>>864
print("12345678"[1::2]) #>>2468
print("abcde"[::-1]) #>>edcba 第1行:从下标1的字符'1'开始取,每隔1个字符取一个,终点是下标7的字符,但是下标7的字符'8'不能要,因此取出来的字符串就是'246'。
第2行:−1表示要从右到左取,且是依次取。从下标3的字符'4'开始取,终点是下标1的字符'2',但是下标1的字符不能要。因此取出来的就是'43'。
第3行:从下标7的字符起,从右到左,每隔一个字符取一个,终点是下标1的字符。
第4行:y省略了,所以可以一直取到最后一个字符。
第5行:x,y都省略,而且1表示从右到左依次取,那么结果就是原字符串颠倒过来。要颠倒一个字符串可以用这个办法。
6.2.6 字符串的成员函数
字符串有许多成员函数,简称“字符串的函数”,可以对字符串进行各种操作。“字符串有函数f”或“f是字符串的函数”的意思是,如果s是一个字符串,则可以用s.f(参数1,参数2,......)的形式调用函数f。后文会提到元组的函数、列表的函数、字典的函数等,都是这个意思。字符串的函数名称、作用及示例如下(假设s是个字符串)。
1.s.count(x)求子串x在s中出现的次数
s = 'thisAAbb AA'
print(s.count('AA')) #>>2 因AA在s中出现2次2.s.upper()、s.lower()分别返回s的大写形式和小写形式,不会改变s
print("abc".upper(),"Hello,小明".lower()) #>>ABChello,小明3.s.join(x)返回将序列x中的各项用s连接起来而得到的字符串
print("AA".join(['1','23','4'])) #>>1AA23AA4
print("".join(['1','23','4'])) #>>1234
print(",".join("abcd")) #>>a,b,c,d4.s.find(x)、s.rfind(x)、s.index(x)、s.rindex(x)
在s中查找子串x在s中查找子串x,返回第一次找到的位置(下标)。找不到的话,find返回-1,index引发异常。find和index是从左到右找,rfind和rindex则是右到左找。
s = "1234abc567abc12"
print(s.find("ab")) #>>4 "ab"第一次出现在下标4的位置
print(s.rfind("ab")) #>>10 从尾找起,"ab"第一次出现在下标10的位置
try:
s.index("afb") #找不到"afb"因此会产生异常
except Exception as e:
print(e) #>>substring not foundfind还可以指定查找起点。find(x,n)表示从下标n处开始查找子串x:
s = "1234abc567abc12"
print(s.find("12",4)) #>>13指定从下标4处开始查找rfind,index,rindex同样可以指定查找起点。
5.s.replace(x,y)返回将s中子串x替换成y后的结果,s不变
s = "1234abc567abc12"
b = s.replace("abc","FGHI") #b由把s里所有abc换成FGHI而得
print(b) #>>1234FGHI567FGHI12
print(s.replace("abc","")) #>>123456712用空串替换"abc"等于删除"abc"6.s.isdigit()、s.islower()、s.isupper()分别判断s是否全部由数字组成、是否其中的字母都是小写、是否其中的字母都是大写
print("123.4".isdigit()) #>>False
print("123".isdigit()) #>>True
print("a123.4".isdigit()) #>>False
print("Ab123".islower()) #>>False
print("ab123".islower()) #>>True
print("aB123".isupper()) #>>False7.s.startswith(x)、s.endswith(x)分别判断s是否以字符串x开头、是否以x结尾
print("abcd".startswith("ab")) #>>True
print("abcd".endswith("bcd")) #>>True
print("abcd".endswith("bed")) #>>False8.s.strip()、s.lstrip()、s.rstrip()分别求字符串去除两端、左端、右端的空白字符后的结果。s不变。空白字符包括:空格、'\r'、'\t'、'\n'等
print("\t1234\n".strip()) #>>1234
print("\t12345".lstrip()) #>>123459.s.strip(x)、s.lstrip(x)、s.rstrip(x)分别求除去两端、左端、右端在x中出现的字符后的字符串
print("takeab\n".strip("ba\n")) #>>take
#去除两端的'b','a','','\n'
print("cd\t12345".lstrip("d\tc")) #>>12345
#去除左端的'd','\t','c'6.2.7 字符串的格式化
把一些变量或常量或表达式的值,按照一定格式填到一个字符串里面,叫字符串的格式化。使用格式控制符,可以进行字符串格式化,例如:
"%.2f,%d,%s"%(5.225,78,"hello")
可以得到字符串"5.22,78,hello",这就是字符串的格式化。
字符串还提供format函数,用以返回一个格式化后的字符串,其使用方法是:
s.format(参数0,参数1,参数2......) #s是个字符串
字符串s中可以带有“槽”。槽的基本格式如下:
{<参数序号>:<填充字符><对齐方式><输出宽度><.精度><类型>}
上面的每一项都可以被省略。
s.format返回将s中的槽用参数替代以后得到的字符串。例如:
x = "Hello {0} {1:10},you get ${2:.4f}".format("Mr.","Jack",3.2)
print(x) #>>Hello Mr.Jack ,you get $3.2000
x = "Hello {1} {0:>10},are you ok?".format("Jack","Mr.")
print(x) #>>Hello Mr. Jack,are you ok?第1行:{0}表示此处应该用format函数里面的参数0,即"Mr."替换。{1:10}表示此处应该被参数1替换,且输出宽度至少是10。若输出宽度不足,用填充字符补齐宽度。{1:10}这个槽里没有写填充字符,那填充字符就是空格;这个槽里也没有写对齐方式,那么对齐方式就是左对齐,即填充字符补在右边。因此输出出来Jack右边有6个空格。{2:.4f}表示该槽应被参数2即3.2替换,数据类型是小数,且小数点后面保留4位。
第3行:请注意槽里的参数序号可以和槽的位置无关,本行对应参数1的槽先于对应参数0的槽出现。{0:>10}中的“>”代表对齐方式,表示右对齐,即宽度不足10时,填充字符补在左边。所以输出Jack左边有6个空格。“<”代表左对齐;“^”代表中对齐,即填充字符均匀补在两边。
一个完整的槽如下:{1:*^10.4f},表示此处应用参数1替换,参数1应是小数,以宽度至少是10字符,中对齐,填充字符'*',保留小数点后面4位的方式输出。因此
print("The number is {1:*^10.3f}.".format(0,3.12346))输出结果是:
The number is **3.123***.
如果就是要在字符串中写花括号"{}",不想它被当作槽,那就写两次:
print("{{Jack}} is { }".format("good")) #>>{Jack} is good6.2.8 f-string
f-string是从Python3.6开始支持的一种以“F”或“f”打头的字符串。用f-string实现字符串的格式化,比format函数更方便。f-string和format函数一样,都要使用“槽”,但是,它比format函数的高级之处在于,可以把变量,甚至任何有定义的表达式,写到槽里面,而且f-string的槽的格式更加多样、复杂。f-string的最简单用法如下:
name,age = "Jack",18
print(f"My name is {name}.I'm {age} years old.")第二行的字符串,以“f”开头,因此是个f-string。槽里面的name和age,不再是字符串,而是变量名,会被变量的值替代。上面程序输出:
My name is Jack.I'm 18 years old.
将变量写到字符串里的梦想终于在Python进化到3.6版本以后实现了。
槽内格式控制的规则,和format函数类似:
a,b = 11,4
print(f"The sum is{a+b:.4f},or{a+b:*>10x}") #x表示十六进制形式
#>>The sum is 15.0000,or *********f
print(f"Square of a is:{(lambdax:x*x)(a)}") #>>Squareofais:121可见,f-string中槽里面的表达式,如上面的a+b,(lambdax:x*x)(a),会被计算。
6.3 元组
6.3.1 元组的基本概念
元组是类似于列表的数据类型,也是元素的有序集合,元素可以根据下标来查看。元组和列表最大的区别是:元组不可修改。
元组表示形式如下:
(元素0,元素1,元素2.....)
有时括号也可以省去。没有元素的空元组,就是()。
t = (12,) #t是一个单元素的元组
t = (12,'ok') #t是一个两元素的元组
t = 12345, 54321, 'hello!' #t是一个三元素的元组
print(t[0]) #>>12345
print(t) #>>(12345,54321,'hello!')
u=t, (1,2,3,4,5) #u有两个元素,两个元素都是元组
print(u) #>>((12345,54321,'hello!'),(1,2,3,4,5))
print(u[0][1]) #>>54321
print(u[1][2]) #>>3
t[0] = 88888 #运行错误,不可对元组的元素进行赋值第1行:(12,)表示一个元组,里面只有一个元素12。(12)则不是元组,就表示整数12。想表示单元素元组,要在元素后面加“,”。
第2行:对t重新赋值,就是让变量t指向别处而已,并没有和“元组不可修改”的说法矛盾。
第3行:有的情况下表示元组的时候,括号可以去掉。
第6行:u是有两个元素的元组。这两个元素都是元组,分别是t和(1,2,3,4,5)。
第8行:u[0][1]表示u[0]的下标为1的元素,那就是t[1]。
和列表一样,元组的元素也是指针,但是这个指针只能指向固定的地方,不能修改指向。换句话说,就是不可对元组的元素赋值。正如上面第10行所示。
说元组不可修改,准确地说是指元组不支持以下操作。
(1)对元组的元素进行赋值。
(2)对元组添加元素,或者删除元素。
(3)改变元组元素的顺序,例如对元组排序。
许多教材和网上资料提到“元组元素不能修改”,这个说法不准确,或者含义不明。准确的说法是元组的元素不能被赋值。元组的元素是指针,该指针指向的内容并非不可被修改。例如,如果元组的元素是个列表(或字典、集合),那么这个列表(或字典、集合)是可以被修改的:
v = ("hello",[1,2,3],[3,2,1]) #[1,2,3]是列表
v[1] = 32 #运行错误,元组元素不可修改成指向别处
v[1][0] = 'world' #v[1]指向的内容可以被修改
print(v) #>>('hello',['world',2,3],[3,2,1])
print(len(v)) #>>3
t = [1,2]
v = (t,t) #v的两个元素都和t指向相同的地方
print(v) #>>([1,2],[1,2])
t[0] = 'ok' #t变化会影响v
print(v) #>>(['ok',2],['ok',2])
t = 8 #让t指向别处不会影响到v
print(v) #>>(['ok',2],['ok',2])第1行:元组v的元素v[1]和v[2]都是列表。
第2行:试图对元组的元素进行赋值,这是不允许的。
第3行:v[1]是个指针,指向列表[1,2,3]。可以修改v[1]指向的内容,即将列表[1,2,3]中的1改成了'world'。因此第4行输出v可以看到v[1]的内容变成了['world',2,3]。对v[1][0]进行赋值,并不是对元组v的元素赋值。只有对v[0],v[1],v[2]......进行赋值,才算是对元组元素进行赋值。
第7行:元组v的两个元素都和t指向相同的地方。若t指向的内容发生了变化,正如第9行所做的,那么v的内容自然也会发生变化,正如第10行输出结果所示。
第11行:让t指向别处,自然不会影响到v,正如第12行输出v结果所示。
打个比方,所谓的元组不可修改,类似于组建了一支球队,规定球队建好后不可换人,不可加人,不可减人,不可修改队员号码。但是队员换个发型,增加体重,受伤缺胳膊少腿,甚至长出三头六臂,都是可以的。
有的函数,看上去像返回了多个值,实际上是返回了一个元组,例如:
def sumAndDifference(x,y):
return x+y,x-y #等价于return(x+y,x-y),返回元组
s,d = sumAndDifference(10,5) #返回值是元组(15,5)
print(s,d) #>>15 5第三行也可以写成(s,d)=sumAndDifference(10,5)。
6.3.2 元组的操作
元组和字符串一样,有切片的操作,操作方法也基本相同。元组的切片也是元组。元组可以用“+”连接。用in和notin可以判断元素是否在元组里面。两个元组还可以比大小。元组可以和整数相乘。元组可以用for循环遍历。
tup2 = (1,2,3,4,5,6,7)
print(tup2[1:5]) #>>(2, 3, 4, 5)
print(tup2[::-1]) #>>(7, 6, 5, 4, 3, 2, 1)
print(tup2[-1:0:-2]) #>>(7, 5, 3)
tup1 = (12,34.56)
tup2 = ('abc','xyz')
tup3 = tup1+tup2 #创建一个新的元组
print(tup3) #>>(12, 34.56, 'abc', 'xyz')
tup3 += (10,20) #等价于tup3=tup3+(10,20),新建了一个元组
print(tup3) #>>(12,34.56,'abc','xyz',10,20)
print((1,2,3)*3) #>>(1, 2, 3, 1, 2, 3, 1, 2, 3)
print(3in(1,2,3)) #>>True
foriin(1,2,3): #此循环输出123
print(i,end="")需要注意的是,第9行并不是在tup3尾巴直接添加10和20两个元素。它的效果是新生成一个元组tup3+(10,20),然后把新元组赋值给tup3。
元组可以比大小,可以用“==”和“!=”判断是否相等。两个元组a和b比大小,就是逐个元素比大小,直到分出胜负。如果a的最后一个元素都比完了还胜负未分,且b比a长,则a比b小。如果有两个对应元素不可比大小,则产生运行时错误。例如:
print((1,'a',12) < (1,'b',7)) #>>True
print((1,'a') < (1,'a',13)) #>>True
print((2,'a') > (1,'b',13)) #>>True
print((2,'a') < ('ab','b',13)) #RuntimeError第4行,因2和'ab'不能比大小,于是导致程序出错。有时元组可以用来取代复杂的分支结构。例如输入1~7,相应输出星期一到星期天,这个问题如果用if...elif语句解决,就要写很多个elif,不太方便。用上元组,可以不写if语句:
weekdays = "Monday","Tuesday","Wednesday","Thursday",\
"Friday","Saturday","Sunday"
n = int(input())
if n > 7 or n < 1:
print("Illegal")
else:
print(weekdays[n-1])6.4 列表详解
6.4.1 列表基础用法
列表非常重要。
进一步学习列表之前,请读者再次对自己强调一下:列表的元素都是指针。
列表是可以修改的—可以对元素赋值,可以添加和删除元素,可以修改元素顺序,比如进行排序。元组支持的各种操作,列表同样支持。例如:
#prg0520.py
empty = [] #[]表示空列表
list1 = ['Pku','Huawei',1997,2000]
list1[1] = 100 #列表元素可以赋值
print(list1) #>>['Pku',100,1997,2000]
del list1[2] #删除元素
print(list1) #>>['Pku',100,2000]
list1 += [100,110]
#添加另一列表的元素100和110,在list1原地添加,没有新建一个列表
list1.append(200) #添加元素200,append用于添加单个元素
print(list1) #>>['Pku',100,2000,100,110,200]
list1.append(['ok',123]) #添加单个元素
print(list1) #>>['Pku',100,2000,100,110,200,['ok',123]]
a = ['a','b','c']
n = [1,2,3]
x = [a,n] #a,n若变,x也变
a[0] = 1
print(x) #>>[[1,'b','c'],[1,2,3]]
print(x[0]) #>>[1,'b','c']
print(x[0][1]) #>>b第5行:写list1.pop(2)也可以。pop函数还能返回被删除的元素。
第7行:对于两个列表a和b,a+=b会将b中的元素添加到a的末尾。对列表来说,a+=b和a=a+b是不等价的。后者在“=”右边新生成一张列表,然后将a重新赋值为指向该新列表。而前者并没有对a重新赋值,直接在a的末尾添加进列表b的元素。下面这个程序能体现二者不同:
b = a = [1,2]
a += [3] #b和a指向相同地方,在a末尾添加元素,b也受影响
print(a,b) #>>[1,2,3][1,2,3]
a = a+[4] #对a重新赋值,不会影响到b
print(a) #>>[1,2,3,4]
print(b) #>>[1,2,3]prg0520.py 的第9行:append函数用于在列表末尾添加单个元素。因此本行将元素200添加到list1末尾。第11行将列表['ok',123]作为一个元素添加到list1的末尾。若a是列表,则a.append(x)和a+=[x]是等价的,都是把元素x添加到a末尾。
如果想要在列表中间插入元素,可以用列表的函数insert,后文还会提到。要想替换列表中间的连续若干个元素,可以使用列表切片。列表的切片返回新的列表,用法和元组切片基本相同:
a = [1,2,3,4]
b = a[1:3]
print(b)
b[0] = 100
print(b)
print(a)
print(a[::-1])
print([1,2,3,4,5,6][1:5:2])
print(a[:])
a[1:3] = ['ok','good','well']
print(a)
a[1:3] = []
print(a) 列表的切片是一张新的列表,因此上面第2行的b就是新列表,不是a的一部分。因此第4行修改了b[0],不会影响到a。
第9行:a[:]这个切片,省略起点和终点,那么它就是a的拷贝。注意,它是一张新的列表。
第10行:对列表的切片进行赋值时,等号右边必须是个序列(如列表、字符串等)。赋值的结果是切片被替换成序列中的元素,如第11行输出所示。列表切片赋值这件事很“打脸”,,它成了作者前面说过的“所有可赋值的东西都是指针”和“列表的切片是新列表”这两个说法的例外。作者认为Python语言在这一点上设计得不太合理。
列表相加可以得到新的列表:
a = [1,2,3,4]
b = [5,6]
c = a+b #>>[1,2,3,4,5,6]
print(c)
a[0] = 100
print(c) #>>[1,2,3,4,5,6]第3行:a+b是一张新的列表,c指向该列表。修改a或b的元素都不会影响到c,正如第5、6行所示。列表可以和整数相乘,得到新列表:
print([True] * 3)
a = [1,2]
b = a * 3
print(b)
print([a*3])
c = [a] * 3
print(c)
a.append(3)
print(c)
print(b)如果a是列表,n是整数,则a*n就是一张新列表,其内容是a中的内容写n遍,如上面第3、4行所示,a*n生成以后,和a没有任何联系。[a]*n是一张新列表,里面写了n个a,即里面n个元素都是指针,和a指向同一张列表。因此第8行在a后面添加了元素,c也跟着变,但是b不受影响。
第5行:[a*3]是一个列表,里面只有一个元素,就是a*3。而a*3是[1,2,1,2,1,2],所以[a*3]就是[[1,2,1,2,1,2]]。
#prg0550.py
a = [[0]] * 2 + [[0]] * 2
print(a)
a[0][0] = 5
print(a)
执行完第1行,a的情况如图7.4.1所示。
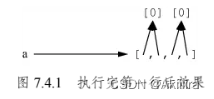
a[0]、a[1]指向同一个列表[0],a[2]、a[3]指向另一个列表[0]。所以,修改a[0][0],a[1][0]跟着变,但是a[2][0]、a[3][0]不变。
上面的两个程序实在有点烧脑,尤其是prg0550.py。但这绝不是在钻牛角尖或者语法炫技,这两个程序体现的是重要的基本概念。记不清是哪一天,一个学习作者慕课的学员,在论坛贴出一段他找不出bug的程序求教,作者发现他犯错误就是因为没有搞清prg0550.py所表达的概念,所以本书才有了prg0550.py。
两个列表可以比大小,规则和元组比大小相同,就是逐个元素比大小,直到分出胜负。如果有两个对应元素不可比大小,则导致运行时错误。两个列表也可以用“==”和“!=”比较是否相等。
可以用for循环来遍历一个列表:
lst = [1,2,3,4]
for x in lst:
print(x,end="") #>>1234
x = 100 #不会修改列表的元素
print(lst) #>>[1,2,3,4]
for i in range(len(lst)): #要依次修改列表元素就这么写
lst[i] = 100
print(lst) #>>[100,100,100,100]第2行:x的值依次是lst[0],lst[1],......。但是要注意,x并不是lst中的元素,它只是和lst中的元素指向同一个地方。因此第4行,对x赋值只是改变x的指向,不会导致对列表元素的修改。
6.4.2 列表的成员函数
列表常用的成员函数见表6.4.1,其他成员函数还请读者自行探索。
| 函数 | 功能 |
| count(x) | 计算列表中有多少个x |
| append(x) | 添加元素x到尾部 |
| copy(x) | 返回自身的复制(浅复制) |
| extend(x) | 添加列表x中的元素到尾部 |
| index(x) | 查找元素x,找到则返回第一次出现的下标,找不到则引发异常 |
| insert(i,x) | 将元素x插入到下标i处 |
| pop(i) | 删除并返回下标为i的元素。i省略则删除最后一个元素 |
| remove(x) | 删除元素x。如果有多个x,只删除第一个。若x不存在,则引发异常 |
| reverse() | 颠倒整个列表 |
| sort() | 排序 |
部分列表成员函数用法示例如下:
a,b = [1,2,3],[5,6]
a.append(b)
print(a)
b.insert(1,100)
print(a)
a.extend(b)
print(a)
a.insert(1,'K')
a.insert(3,'K')
print(a)
a.remove('K')
print(a)
a.reverse()
print(a)
print(a.index('K'))
try:
print(a.index('m'))
except Exception as e:
print(e) 第2行:将b作为一个元素添加到a的末尾。a[3]就和b指向同一张列表。
第5行:由于a[3]和b指向同一个地方,所以a[3]也变成[5,100,6]。
第17行:a中找不到'm',因此本句不会产生输出,而是引发异常,导致程序跳转到第19行,打印出导致异常的原因。
6.4.3 列表的排序
1. 选择排序
排序,是处理许多问题的基础。数据如果有序,查找起来就快,正如字典里的单词是有序排列的,才使查字典成为可能。
排序有各种各样的算法。一些简单的算法,是大家在生活中都会想到并且用到的,比如对扑克牌排序采用的办法。这类简单算法,有插入排序、选择排序、冒泡排序等。
在编程实践中,大部分需要排序的情况,都是对列表中的元素排序。以选择排序算法为例,其基本思路是:如果有n个元素需要排序,那么首先从n个元素中找到最小的那个放在下标0处(可以通过让它和原来的下标为0的元素交换位置来实现), 然后再从剩下的n-1个元素中找到最小的放在下标1处,然后再从剩下的n-2个元素中找到最小的放在下标2处……直到剩下最后2个元素中最小的被放在下标n-2处,那么所有的元素都就位。这个思路用程序实现如下:
可以看到,第9行调用selectionSort函数对列表lst进行排序。由于selectionSort中的a和lst指向同一个列表,因此函数执行过程中a的内容发生了变化,lst自然也跟着变。于是函数执行完,lst也被排好序了。
第6、7行:如果发现a[j]小于a[i],就将a[i]和a[j]位置对换。如果a[i]已经是a[i]及其右边所有元素中最小的,那么a[i]自然不会被换走。因此第6行的循环做完一遍以后,a[i]及其右边的元素中最小的一定就会出现在a[i]的位置。
排序就是个不停比较元素大小,并交换元素的过程。因为比较之后才可能会交换,所以交换的次数不会多于比较的次数。因此排序算法的快慢,就取决于比较的次数。在上面的程序中,第6行中的a[j]<a[i] 的计算次数,就标志着排序的快慢。当 i=0 时,j 的取值范围从 1 到 n-1,a[j]<a[i] 需要计算 n-1 次;当 i=1 时,需要计算 n-2 次……当 i=n-2 时,需要计算1次。故 a[j]<a[i] 的总计算次数是;
当n很大时,1/2n可以忽略不计,因此我们说总的比较次数是n2量级的,记作O(n2)。至于n2前面的系数,不必理会是多少。
和选择排序一样,插入排序、冒泡排序的比较次数,都是O(n2)量级的。这些排序算法虽然容易想到,但都是慢吞吞的,客气一点不妨称之为“朴素的排序算法”。好的排序算法,比较次数是O(n×log(n))量级的。这个log的底数是多少不重要,因此可以不写。
2. 列表排序库函数
实际应用中我们不必自己编写列表排序的函数,Python已经提供函数帮你搞定。如果a是一个列表,那么a.sort()就能将a从小到大排序;sorted(a)就能得到一张新列表,内容是a经过从小到大排序后的结果,而a本身不变。例如:
a = [5,7,6,3,4,1,2]
a.sort() #对a从小到大排序
print(a) #>>[1,2,3,4,5,6,7]
a = [5,7,6,3,4,1,2]
b = sorted(a) #a不因此而改变
print(b) #>>[1,2,3,4,5,6,7]
print(a) #>>[5,7,6,3,4,1,2]
a.sort(reverse=True) #对a从大到小排序
print(a) #>>[7,6,5,4,3,2,1]第2行的a.sort()会改变a,第5行的sorted(a)不会改变a。
第8行:加上参数reverse=True就表示排序规则是从大到小。
对元素都是元组的列表进行排序,是经常会遇到的场景:
students=[('John','A',15),('Mike','C',19),('Mike','B',12),('Mike','C',18),
('Bom','D',10)] #姓名,成绩,年龄
students.sort() #先按姓名,再按成绩,再按年龄排序
print(students)上面程序中,students是若干个学生的信息构成的列表。每个学生的信息是一个包含姓名、成绩和年龄的元组。程序输出结果如下:
[('Bom', 'D', 10), ('John', 'A', 15), ('Mike', 'B', 12), ('Mike', 'C', 18), ('Mike', 'C', 19)]
列表students里的元素都是元组,那么元素比大小的规则,就是元组比大小的规则。因此所谓从小到大排,就是先比较姓名,姓名字典序小的排在前面;如果姓名相同,接着比较成绩,成绩小的排在前面(此处成绩小指的是代表成绩的那个字母小,比如'A'<'B');如果成绩也相同,则年龄小的排在前面。
需要注意的是,如果列表a中有元素不能互相比较大小,则a.sort()和sorted(a)都会导致运行时错误。
3. 自定义比较规则的排序
在很多情况下,排序时只按Python默认的比大小规则进行元素比大小,并不能满足要求。例如,一个整数的列表a,希望将其中的元素按个位数从小到大排序,那么简单的整数比大小的规则显然不适用。此时,就需要自定义一个关键字函数f,并将f作为参数传递给a.sort函数,告诉a.sort函数,排序时如果要比较两个元素x,y,不应该直接比较x,y本身,而应该比较f(x)和f(y)。如果f(x)<f(y),则x算比y小。示例如下:
def mod10(x):
return x % 10
a = [25,7,16,33,4,1,2]
a.sort(key = mod10)
print(a)
print(sorted("This is a test string from Andrew".split(),
key=str.lower))第5行:列表的sort函数可以有一些参数,比如reverse、key等。这些参数调用时不一定要给出。参数key字面意思是关键字,即排序时用来做比较的东西。如果key不给出,则排序时的关键字就是元素本身,即用来做比较的就是元素本身。也可以给出key,将key赋值成一个函数,那么元素x,y比大小的时候,不再比较元素本身,而是比较key(x)和key(y)—如果key(x)。本行key=mod10,那么元素x,y比大小时,比的就是mod10(x)和mod10(y),即比的是x,y的个位数,哪个元素的个位数小,哪个就算小。
第9行:sorted函数同样也可以有key参数。本行的key被指定为str.lower。str.lower(x)是Python的函数,能够返回将字符串x中的字母都变成小写后的结果。以str.lower作为关键字,就意味着sorted在比较元素大小的时候,比较的是它们中的字母都转成小写以后的结果,因此,排序的结果就是不区分大小写的。如果大小写相关的话,'Andrew'会排在'a'前面。
通过指定不同的key,就可以对同一数组,用不同的方式来排序:
students = [('John','A',15),('Mike','B',12),
('Mike','C',18),('Bom','D',10)]
students.sort(key=lambda x:x[2]) #按年龄排序
print(students)
students.sort(key=lambda x:x[0]) #按姓名排序
print(students)第3行:此时students.sort在排序过程中比较两个元素x,y时,比较的不是x,y本身,而是x[2]和y[2],即年龄,于是最终排序结果就是按年龄从小到大排,第4行输出如下:
[('Bom', 'D', 10), ('Mike', 'B', 12), ('John', 'A', 15), ('Mike', 'C', 18)]
同理,第5行就是按姓名从小到大排序。第6行输出如下:
[('Bom', 'D', 10), ('John', 'A', 15), ('Mike', 'B', 12), ('Mike', 'C', 18)]
但是,有两个学生都叫'Mike',谁排在前面?答案是:排序前在前面的,排序后依然在前面。并不是所有的排序算法都能确保两个关键字相同的元素(即这两个元素哪个在前都可以),经过排序后的它们的先后关系不变。能确保这一点的排序算法,称为“稳定”的排序算法。Python提供的排序函数都是稳定的。
有的时候,排序规则比较复杂。例如对学生的记录,希望先按年龄从大到小排序,年龄相同的按成绩从高到低排,成绩相同的,按姓名从小到大排。这样复杂的规则,也可以通过精心设计key函数来实现,诀窍是让key函数返回一个合适的元组,如下面例题所示。
4. 元组排序成列表
元组是不能修改的,因此元组不能排序,当然也就没有sort函数。但是如果x是元组,则可以用sorted(x)得到一个列表,列表内容是元组x元素排序以后的结果:
def f(x):
return(-x[2],x[1],x[0])
students=(('John','A',15),('Mike','C',19),('Wang','B',12),
('Mike','B',12),('Mike','C',12),('Mike','C',18),('Bom','D',10))
print(sorted(students,key=f)) #sorted的结果是列表6.4.4 列表的映射和过滤
Python支持对列表的映射操作(map),可以方便地从一个列表转换得到另一个列表。map函数用法如下:
map(function,sequence)
function是一个函数(也可以是一个lambda表达式),sequence是一个序列(元组、列表、字典、字符串、集合均可)。map的返回值是一个“延时操作对象”,里面存放着一个操作,这个操作就是“依次对sequence里的每个元素x,执行function(x),并将function(x)的返回值收集起来”。这个操作只是被记录在延时操作对象中,并没有真正被执行。当把该延时操作对象转换为列表、元组或者集合时,对象中存着的操作才会真正被执行,并将收集到的结果放到列表、元组或集合中去。例如:
def f(x):
print(x,end="")
return x*x
a = map(f,[1,2,3])
print(list(a)) #>>123[1,4,9]
print(tuple(a)) #>>()第4行:将a赋值为一个延时操作对象,该对象里面记录着“依次对[1,2,3]里的每个元素x,调用f(x),并将f(x)的返回值收集起来”。但这个操作并没有被执行,因此f函数一次也没被执行,自然也不会产生输出。
第5行:list(a)将a转换成一个列表,此时a里存放的操作就会被执行。操作执行的过程中,依次以1,2,3作为参数调用函数f,于是输出“123”。然后,f(1),f(2)和f(3)的返回值被收集到一个列表里,即list(a)的值是列表[1,4,9]。
第6行:将a转换成一个元组。延时操作对象里的操作一旦被执行过,可以认为该操作就从对象里面删除了。因此tuple(a)不会引发a中操作的执行,故其值为空元组。
非计算机专业的读者并不需要理解延时操作对象的概念,只需要知道map用来处理输入特别方便即可。比如,在一行里输入三个整数,希望将其分别读入x,y,z,则可以如下写:
x,y,z = map(int,input().split())
假如输入“12345”后按Enter键,input.split()的返回值是['1','23','45'],上面这条语句将该列表的每个元素依次转换成整数后赋值给x,y,z。延时操作对象在这里自动被转换成元组。延时操作对象什么时候会被自动转换成元组或列表,什么时候不会,讲起来和记起来都麻烦,不如用的时候自己试试。
Python还支持对列表的过滤操作(filter),可以方便地实现从列表中抽取符合某种条件的元素,形成一个新列表。filter的用法如下:
filter(function,sequence)
filter的返回值也是一个“延时操作对象”,里面的操作是“依次对sequence里的每个元素x执行function(x),若function(x)值为True,则将x收集起来”。例如:
tp = tuple(filter(lambdax:x%2==0,[1,2,3,4,5])) #过滤出偶数
print(tp) #>>(2,4)6.4.5 列表生成式
可以通过在列表里面写循环的方式来生成内容有某种规律的列表。例如:
[x * x for x in range(1, 11)]
生成的列表是[1,4,9,16,25,36,49,64,81,100]。即对[1,11)区间里的每个值x,将x*x收集起来形成一张列表。
[x * x for x in range(1, 11) if x % 2 == 0]
生成[4,16,36,64,100],即对[1,11)区间里的每个值x,若x是偶数,则将x*x收集起来形成一张列表。
[ [m + n for m in 'ABC'] for n in 'XYZ']
生成[['AX','BX','CX'],['AY','BY','CY'],['AZ','BZ','CZ']]。对'XYZ'中的每个字符n,生成一个列表。该列表的每一项都是m+n,m依次取'ABC'里的每个字符。然后将所有生成的列表收集起来形成一张列表。
L = ['Hello', 'World', 18, 'Apple', None]
print([s.lower()forsinLifisinstance(s,str)])
#>>['hello','world','apple']
print([s for s in L if isinstance(s,int)]) #>>[18]第2行:将L中的字符串,转小写形式后收集起来形成一张列表。
第4行:将L中的整数收集起来形成一张列表。要想像列表生成式那样生成元组,不是把“[]”替换成“()”就行,要在前面加'tuple':
print(tuple(x * x for x in range(1, 4))) #>>(1,4,9)
6.4.6 二维列表
前面学到的列表,都是一维列表。二维列表可以看作一个矩阵。以行、列号作为下标,就可以访问矩阵中的元素。例如,如果a是一个二维列表,a[i][j]就是a中第i行第j列的元素(i,j都从0开始算)。
m行n列的二维列表,应为一个一维列表,其中的m个元素分别指向m个不同的、长度为n的一维列表,一个一维列表相当于一行。这里的“不同”指的不是内容不同,而是存放的内存地址不同。这样才不会发生修改了某个元素,另一个元素也跟着变的情况。生成二维列表的做法如下:
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
print(matrix)
print(matrix[1][2],matrix[2][2])
matrix[1][1] = 100
print(matrix)
matrix = [[0 for i in range(3)] for i in range(3)]
print(matrix)
matrix = [[i*3+j for j in range(3)] for i in range(3)]
print(matrix)
print(len(matrix)) 第1行:生成的matrix是个3×3的矩阵,即二维列表。该矩阵每行都是一个不同的列表。第0行是列表[1,2,3],第0列的3个数自然就是1,4,7。程序第2、3行的输出能够体现matrix是个矩阵。
第4行:修改了matrix[1][1],从第5行输出结果看出只有第1行第1列的元素变成100。
第6行:如果生成一个矩阵,就要把每个元素直接写出来,显然有点麻烦。所以可以用列表生成式来生成一个二维列表。本行就生成了一个3×3的矩阵,每个元素都是0。。通过第7行的输出结果可以知道matrix的样子。此处的matrix一共三行,虽然每行都是列表[0,0,0],但这三个列表放在内存的不同地方,修改其中一个元素,不会影响到另外两个。本行的写法,是很通用的生成一个m×n的矩阵的方法。
第10行:输出3是因为matrix是一个有3个元素的列表,每个元素又都是列表。
初学者可能会以为下面的方法可以生成一个二维列表b,但实际上是不行的:
a = [0,0,0]
b = [a] * 3 #b有三个元素,都是指针,都和a指向同一地方
print(b) #>>[[0,0,0],[0,0,0],[0,0,0]]
b[0][1] = 1
a[2] = 100
print(b) #>>[[0,1,100],[0,1,100],[0,1,100]]从第3行的输出结果看,似乎b是一个3×3的二维列表(矩阵)。但实际上它不是。因为b[0],b[1],b[2]都和a指向同一个地方。修改了a[2],则b[0][2],b[1][2],b[2][2]都跟着变;修改了b[0][1],则a[1],b[1][1],b[2][1]也跟着变。正如第6行输出结果所示。这显然不符合b是一个3×3的矩阵的预期。如果b是一个3×3的矩阵,b[0][1]和b[1][1]不应该是同一个东西。
生成一个二维列表的方法可以像prg0610.py第6、8行那么花哨,也可以很朴实,即将每一行作为一个元素append到空表上面:
lst=[]
for i in range(3):
lst.append([0] * 4)上面的lst就是一个3行4列的矩阵,元素都是0。
如果矩阵的元素不需要修改,那么定义二维元组来当矩阵用,也是可以的:
matrix = ((1,2,3),(4,5,6),(7,8,9))
print(matrix) #>>((1,2,3),(4,5,6),(7,8,9))
matrix = tuple(tuple(0 for i in range(3)) for i in range(3))
print(matrix) #>>((0,0,0),(0,0,0),(0,0,0))6.4.7 列表的复制
当我们说列表b是列表a的复制时,我们希望的是,a和b的内容相同,但是它们存放在不同的地方,是完全分开的,两者之间没有任何联系,不会发生修改了一个,另一个也跟着变的情况。那么,b=a显然做不到让b成为a的复制,因为b=a使得a,b指向同一张列表。正确的复制列表的方法是使用切片,或者用列表的copy函数:
a = [1,2,3,4]
b = a[:] #b是a的复制,b没有和a指向同一个列表。与b=a.copy()等价
print(b) #>>[1,2,3,4]
b[0] = 5
print(a) #>>[1,2,3,4]
b += [10]
print(a) #>>[1,2,3,4]
print(b) #>>[5,2,3,4,10]第2行:a[:]是一张新的列表,因此,b和a指向不同的列表,虽然这两张列表的内容是一样的,但它们存放在不同的地方,算不同的列表。因此,第4行修改了b[0],a不会受影响,如第5行所示。第6行的b+=[10]在b后面添加元素10,自然也不会影响到a,如第7行所示。本行如果写b=a.copy(),效果也是一样的。
有的时候,即便使用切片,也不能达到复制列表的目的。例如:
a = [1,[2]]
b = a[:]
b.append(4)
print(b)
a[1].append(3)
print(a)
print(b)
第2行的本意是让b成为a的复制。复制后b应该和a没有任何联系。第3行往b末尾添加了元素,的确不会影响到a。但是,第5行往a[1]末尾添加元素3后,再输出b,发现b[1]也被添加了元素3。这不符合b应该和a没有任何联系的想法。
之所以会发生这样的事情,是因为a[1]是个指针,指向列表[2]。b是a的复制,所以b[1]也是个指针,也指向同一个列表[2]。既然a[1]和b[1]指向同样的地方,那么在a[1]末尾添加元素,也等于在b[1]末尾添加元素。
可见,要做到让b和a真的完全没有联系,应该把列表[2]也复制一份,然后让b[1]指向该复制。不但复制指针,还要复制指针指向的东西,这种复制方式,就称为深复制。b=a[:]这种方式,只复制指针(a的元素),没有复制指针指向的东西,因此称为浅复制。列表的函数copy就返回自身的一个浅复制。
可以自己编写一个对列表进行深复制的函数,能够应对列表里面的元素是列表的情况:
def deepCopy(lst):
a = lst[:]
for i in range(len(a)):
if isinstance(a[i],list):
a[i] = deepCopy(a[i])
return a
a = [1,[2,[3,[6]]],[4],5]
b = deepCopy(a)
a[1][1][1].append(100)
print(a)
print(b) 搞懂上面这个程序是对计算机专业学生的要求。不懂也没关系,Python提供了copy库,调用其中的deepcopy函数即可实现深复制:
import copy
a = [1,[2]]
b = copy.deepcopy(a) #b是a的深复制
b.append(4)
print(b) #>>[1,[2],4]
a[1].append(3)
print(a) #>>[1,[2,3]]
print(b) #>>[1,[2],4]可以看到第3行使b成为a的一个深复制,此后b和a不会互相影响。
6.4.8 列表、元组和字符的互相转换
列表和元组可以互相转换,如下所示:
a = [1,2,3]
b = tuple(a) #b: (1,2,3)
c = list(b) #c: [1,2,3]
t = (1,3,2)
(a, b, c) = t # a = 1, b = 3, c = 2
s = [1,2,3]
[a,b,c] = s #a=1,b=2,c=3列表、元组和字符串也可以互相转换,如下所示:
print(list("hello")) #>>['h','e','l','l','o']
print("".join(['a','44','c'])) #>>a44c
print(tuple("hello")) #>>('h','e','l','l','o')
print("".join(('a','44','c'))) #>>a44c6.5 字典
6.5.1 字典的基本概念
字典(dict)是用于快速查找的一种数据类型。字典的每个元素是由“键:值”(key:value)两部分组成,可以根据键快速查找到值。在字典里进行查找,速度比在列表里查找快得多。在未排序的列表里查找元素,所需时间和列表元素个数成正比;在字典里进行查找,所需时间基本是个固定值,和字典里元素个数无关。在排好序的列表里查找元素虽然有办法做到速度很快,但是若要删除或者添加元素,所需时间依然和列表元素个数成正比。而在字典里增删元素,都能做到固定时间内完成。想要记录数百万居民的信息,并希望通过居民的身份证号快速查找到居民,就可以使用字典存放居民信息,每个元素代表一个居民,身份证号是键,其余信息是值。值可以是任何形式,包括但不限于元组、列表、字典、集合等。
字典的形式如下:
{键1 : 值1, 键2 : 值2,……}
元素之间用“,”隔开,每个元素分为两部分,用“:”隔开,“:”左边是键,右边是值。没有元素的空字典,就是“{}”。如果在上面的定义方式中,有两个元素的键相同,则只保留后面的那个元素。
字典的构造方式除了上述形式,还支持以下两种形式:
dict([(键1,值1), (键2,值2),……])
生成的字典相当于{键1:值1,键2:值2,……}
dict(键名1=值1,键名2=值2,……)
此处键名的形式和变量名一样,生成的字典是:{'键名1':值1,'键名2':值2,......}。键都是字符串。
程序示例:
items = [('name','Gumby'),('age',42)]
d = dict(items)
print(d) #>>{'name':'Gumby','age':42}
d = dict(name='Gumby',age=42,height=1.76)
print(d) #>>{'height':1.76,'name':'Gumby','age':42}请注意,第5行输出的元素的顺序,和第4行它们构造时的顺序不一样。在Python3.5及以前的版本中,字典中的元素是完全没有顺序之说的,输出一个字典时,输出的元素顺序可能是任意的。但是在Python3.6及以后的版本中,字典虽然还是不支持“取第i个元素”这样的操作,但是字典的元素是有序的,顺序和元素被加入字典的先后一致。输出一个字典,或者用for循环遍历一个字典,都会遵循这个顺序。OpenJudge上的Python目前是3.5版的,在上面做字典相关题目的时候,要注意不可认为字典元素有序。
字典具有以下特点。
(1)所有元素的键都不相同。
(2)键必须是不可变的数据类型,比如字符串、整数、小数、元组等。列表、集合、字典等可变的数据类型,不可作为字典元素的键。
(3)不同元素的键的数据类型可以不一致,值的数据类型也可以不一致。
(4)元素的值是可赋值的,因此也是指针。
(5)不能修改元素的键。
(6)字典可以增删元素。
(7)两个字典不能比大小,但是可以用“==”比较元素是否相同。
如果dt是字典,则可以用dt[x]的方式访问dt中键为x的元素的值。还可以用xindt判断dt中有没有元素的键是x。
如果dt中没有键值为x的元素,则dt[x]这个表达式会引发异常。
dt[x]=y将dt中键为x的元素的值修改为y,如果dt中没有键为x的元素,则会往dt中添加键为x,值为y的元素。
用deldt[x]可以删除键为x的元素。
需要注意的是,字典元素并没有序号。如果n是整数,则dt[n]不是表示字典dt中的第n个元素,而是表示字典中键值为n的元素。
两个字典a,b,如果内容相同,则a==b为True。
dt = {'Jack':18,'Mike':19, 128:37, (1,2):[4,5] }
print(dt['Jack'])
print(dt[128])
print(dt[(1,2)])
dt['Mike'] = 'ok'
dt['School'] = "Pku"
print(dt)
del dt['Mike']
print(dt)
scope={}
scope['a'] = 3
scope['b'] = 4
print(scope)
print('b' in scope)
scope['k'] = scope.get('k',0) + 1
print(scope['k'])
scope['k'] = scope.get('k',0) + 1
print(scope['k']) 第1行:定义了一个包含4个元素的字典,赋值给dt。其中,键为'Jack'的元素值为19,键为128的元素值为37,键为元组(1,2)的元素值为列表[4,5]。
第5行:若dt是字典,且没有元素键为x,那么dt[x]这个表达式试图读取dt中键为x的元素的值时会导致异常。但是,如果对dt[x]进行赋值,则没有问题。正如第7行所示,dt中没有键为'School'的元素,dt['School']="Pku"导致往dt中添加了一个键为'School',值为'Pku'的元素。
第10行:删除dt中键为'Mike'的元素。如果dt中没有这样的元素,则会导致异常。
第18行:字典的get函数十分方便,其格式为get(key,value)。如果字典中存在键为key的元素,则返回该元素的值,否则就返回value。本句的意思是:如果scope中有键为'k'的元素,则将该元素的值加1,如果没有,则get函数返回0,本句的效果是往scope中添加一个键为'k',值为1的元素。
第20行:此时scope中已经有了键为'k'的元素,故执行完本句,该元素的值变为2。
6.5.2 字典的函数
字典的函数见表 6.5.1。
| 函数名 | 功能 |
| clear() | 清空字典 |
| copy() | 返回自身的浅复制 |
| get(key,value) | 如果字典中存在键为key的元素,则返回该元素的值,否则就返回value |
| items() | 取字典的元素序列,可用于遍历字典 |
| keys() | 取字典的键的序列 |
| pop(key) | 删除键为key的元素,返回该元素的值。如果没有这样的元素,则引发异常 |
keys(),items(),values()返回的序列,既不是list,也不是tuple,但是可以用for循环遍历,也可以转换成list或者tuple。另外,如果字典x的键互相都可以比大小,则可以用a=sorted(x)来得到列表a,其内容是由字典x中的键组成,且经过排序后的列表。字典的函数用法示例如下:
d={'name': 'Gumby', 'age': 42, 'GPA':3.5}
if 'age' in d.keys():
print(d['age'])
for x in d.items():
print(x,end = ",")
print("")
print(sorted(d))
for k,v in d.items():
print (k,v,end = ",")
print("")
for x in d.keys():
print(x,end=",")
print("")
print(list(d.values()))
d.pop('name')
print(d) 第4行:遍历字典d。d.items()的返回值是一个序列,里面每个元素x都是元组,对应于字典中的一个元素。其中,x[0]就是键,x[1]就是值。按此种方法遍历字典时,在Python3.5及以前,访问元素的先后顺序不确定,在Python3.6及以后的版本中,访问元素的先后顺序和定义字典时元素的顺序一样,即和元素被加入字典的先后顺序一致。
第11行:遍历字典的键序列。如果写forxind:效果也一样,也是在遍历字典的键序列。
字典元素的值是可赋值的,因此也是指针。因此做字典复制的时候,也会牵涉到深复制和浅复制的问题。字典本身的函数copy,执行的是浅复制,即不会复制元素的值所指向的内容。如果要做字典的深复制,同样是使用copy库,如下所示:
import copy
x = {'username':'admin',1978:[1,20,3]}
y = copy.deepcopy(x)
y['username'] = 'mlh'
y[1978].remove(20)
print(y) #>>{'username':'mlh',1978:[1,3]}
print(x) #>>{'username':'admin',1978:[1,20,3]}6.6 集合
Python中集合(set)的概念等同数学上的集合,它具有以下特点。
(1)元素类型可以不同。
(2)不会有重复元素。
(3)可以增删元素。
(4)整数、小数、复数、字符串、元组都可以作为集合的元素。但是列表、字典和集合等可变的数据类型不可作为集合的元素。
集合的作用是快速判断某个东西是否在一堆东西里面。用in查询一个元素是否在一个列表中,所需时间和列表元素成正比。查询一个元素是否在集合中,所需时间基本上是固定值,和集合元素个数无关。
集合的定义形式如下:
{元素1,元素2,……}
如果上面的元素有重复,会自动去重。
如果两个集合a,b内容相同,则a==b为True。
集合可以由元组、列表、字符串以及字典转换而来。set()可以表示空集合:
print(set())
a = {1,2,2,"ok",(1,3)}
print(a)
b = (3,4)
c = (3,4)
a = set((1,2,"ok",2,b,c))
for x in a:
print(x,end = " ")
print("")
a = set("abc")
print(a)
a = set({1:2,'ok':3,(3,4):4})
print(a) 集合的元素是无序的,不能通过下标访问。遍历集合时,访问元素的顺序和元素加入集合的先后顺序无关。所以上面程序用print输出集合时,或像第7行那样遍历集合时,元素输出的顺序没有规律且不具有确定性,未必每次运行都得到相同结果。
第6行:看上去b,c是不同的变量,但是由于他们的值相同,因此字典a里面只留下一个(1,2)。
第12行:集合由字典转换而来时,只取字典的键的部分。
集合常用函数见表6.6.1。
| 函数名 | 功能 |
| add(x) | 添加元素x。如果x已经存在,则不添加 |
| clear() | 清空集合 |
| copy() | 返回自身的浅复制 |
| remove(x) | 删除元素x。如果不存在元素x,则引发异常 |
| update(x) | 将序列x中的元素加入到集合 |
还有一些函数,请自行探索。
可以用in来判断一个元素是否在集合中,可以用a=sorted(x)来得到集合x中的元素经过排序以后的列表a。
两个集合a,b还支持以下运算:
| a|b | 求a和b的并 |
| a&b | 求a和b的交 |
| a–b | 求a和b的差,即在a中而不在b中的元素 |
| a^b | 求a和b的对称差,等价于(a|b)–(a&b) |
相应地,集合也支持a=b、a&=b、a-=b、a^=b这4个运算,它们都是对a进行原地修改,没有生成新的集合,即a|=b不等价于a=a|b。
集合还支持以下关系运算:
| a==b | a是否元素和b一样 |
| a!=b | a是否元素和b不一样 |
| a<=b | a是否是b的子集(a有的元素,b都有) |
| a<b | a是否是b的真子集(a有的元素,b都有,且b还包含a中没有的元素) |
| a>=b | b是否是a的子集 |
| a>b | b是否是a的真子集 |
集合综合示例程序如下:
a = set()
b = set()
a.add(1)
a.update([2,3,4])
b.update(['ok',2,3,100])
print(a)
print(b)
print( a | b)
print( a & b )
print( a - b)
a -= b
print(a)
a ^= {3,4,544}
print(a)
a.update("take")
print(a)
print(544 in a)
a.remove(544)
print(a)
a = {1,2,3}
b = {2,3}
print( a > b)
print( a >= b)
print( b < a) 6.7 自定义数据类型:类
一个学生的信息包含姓名、学号、绩点、出生日期等多项。可以用一个元组或列表来表示一个学生,例如:
student = ["张三",20001807,3.4,"1988-01-24"]
这种方式的不便之处在于,当要访问student的某个属性,比如绩点时,需要记住绩点是下标为2的那个元素。如果学生有很多项属性,要记住每个属性对应的下标,对程序员来说是个沉重的心理负担,因为很容易记错导致莫名的bug。对阅读程序的人来说,看到student[i]=4这样的表达式,想搞清楚到底是在对哪项属性赋值,是要骂人的。
为了程序员的心理健康,Python提供自定义数据类型,即“类”,来解决这个问题。以用类来代表一类事物。类是面向对象程序设计的概念,在第14章详细讲述。但是,如果不编写规模较大的程序,并不是很需要学会第14章的内容。因此,在这里对类的用法作最简单的介绍,能解决上述问题即可。
类的最简单写法如下:
class 类名:
def__init__(self,参数1,参数2,......):
self.属性1 = 参数1
self.属性2 = 参数2
......
类中必须要有__init__函数(前后都是两个下画线),该函数称为“构造函数”,其第一个参数一定名为self。
由类生成的变量称为“对象”。由类生成一个对象,也称为类的实例化。生成一个对象的写法是:
类名(实参1,实参2,......)
该表达式会返回一个对象。这个表达式看上去像一个函数调用,实际上也确实调用了类中的init函数。但是,此处的实参个数,比init中的形参个数少1个,即self形参不需要对应实参,self参数就是对象本身。一定要分清“类”和“对象”这两个不同的概念。“类”是对一种事物共同特点的概括,“对象”就是该种事物的一个个体(实例)。
类的用法示例程序如下:
class Student:
def __init__(self, n,i,g,b):
self.name = n
self.id = i
self.gpa = g
self.birthDate = b
student1 = Student("Jack",1877,3.4,"1988-01-02")
print(student1.name, student1.id, student1.gpa, student1.birthDate)
student1.name = "Big Jack"
print(student1.name)
student2 = Student("Big Jack",1877,3.4,"1988-01-02")
print(student1 == student2)
students = [student1, Student("Mary",1876,3.4,"1988-12-02"),
Student("Tom",1782,3.8,"1988-11-02"),
Student("Jane",1762,3.1,"1989-04-02")]
student1.gender = "Female"
students.sort(key=lambda x:(-x.gpa,x.id))
for x in students:
print(x.name,x.id,x.gpa,x.birthDate)
students.sort() #RuntimeError,因对象本身不能比较大小第1行至第6行:定义一个Student类,概括了学生这类事物的特性,即有name,id,gpa,birthDate四种属性。
第7行:由Student类生成一个“对象”student1。由本行进入Student的init函数时,n等于"Jack",i等于1877,g等于3.4,b等于"1988-01-02",而self参数不对应实参,它就是对象student1。
第8行:可以用“对象名.属性名”的方式来访问对象的属性。
第10行:可以对对象的属性赋值。对象的属性也是指针。
第13行:默认的情况下,对象之间不能比较大小且若a,b是两个同类的对象,a==b等价于aisb。至于非默认的情况,第14章有详细讲述,此处不必深究。如果想要比较两个对象内容是否相等,以目前所学,只能专门写一个函数来逐个比较它们的每个属性。
第17行:可以随时为一个对象添加属性。此处让student1对象有了gender属性,但是其他Student对象,如student2,并没有gender属性。所以,是为对象添加属性,而不是为类添加属性。
第18行:将students数组按照gpa从高到低排序,gpa相同的,按id从小到大排序。
第19、20行的输出是:
Tom 1782 3.8 1988-11-02
Mary 1876 3.4 1988-12-02
Big Jack 1877 3.4 1988-01-02
Jane 1762 3.1 1989-04-02
如果要实现对象之间的复制,则不妨在定义类的时候,实现一个copy函数:
class point:
def _init_(self,x,y):
self.x,self.y = x,y
def copy(self):
return point(self.x,self.y)
a = point(3,4)
b = a.copy()类名可以赋值给变量,如下(非计算机专业读者不需理解):
class A:
def _init_(self,x):
self.x = x
b = A #从此b就代表类名A
c = b(5) #生成一个A对象
print(c.x) #>>5除非学习了第13章,对类的概念和用法有深入的了解,不要试图用对象作为字典的键或集合的元素。















 3013
3013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









