







一、知识点
我们常常会面临这样一类搜索问题:起点是给出的,终点也是已知的,需要确定能否从起点到达终点,如果可以,需要多少步。如果我们用常规的搜索方法,从起点开始往下搜,那得到的解答树可能非常庞大,这样漫无目的的搜索就像大海捞针。
因为普通BFS的思路是逐层扩展,每一层的结点衍生出更多的结点,所以每一层的结点数量是不断扩大的,所以层数越小结点数量越小,于是就双向广搜,变成在一条路径上的相遇问题,相当于把结点层数平分了,比如原来是一个点出发搜索10层,现在变成两个点各自搜索5层,在结点数量很大的时候这个方法可以有效缩小时间复杂度
双向广搜的思想就是更换思路: 既然终点是已知的,我们何必让它闲着呢?我们完全可以分别从起点和终点出发,看它们能否相遇
双向广搜有两种实现方式:
1. 起点和终点放在一个队列
2. 起点和终点分别放在两个队列
- 维护两个而不是一个队列
- 然后轮流拓展两个队列
- 同时,用数组(如果状态可以被表示为较小的整数)或哈希表记录当前的搜索情况,给从两个方向拓展的节点以不同的标记
- 当某点被两种标记同时标记时,搜索结束
这样做的好处是,当从起点出发和从终点出发扩展的结点数相差较大时,每一轮可以选择队列大小少的优先扩展,有效减少时间复杂度,下面的练习中也将会提到这种做法
由于BFS逐层扩展的特性,结点的增长有两种形式,1、指数,2、线性增长,当指数增长的时候说明用双向队列非常有用(随着层的增加,结点数量增加非常快)
二、题目
P1032 [NOIP 2002 提高组] 字串变换 - 洛谷【普及+/提高】

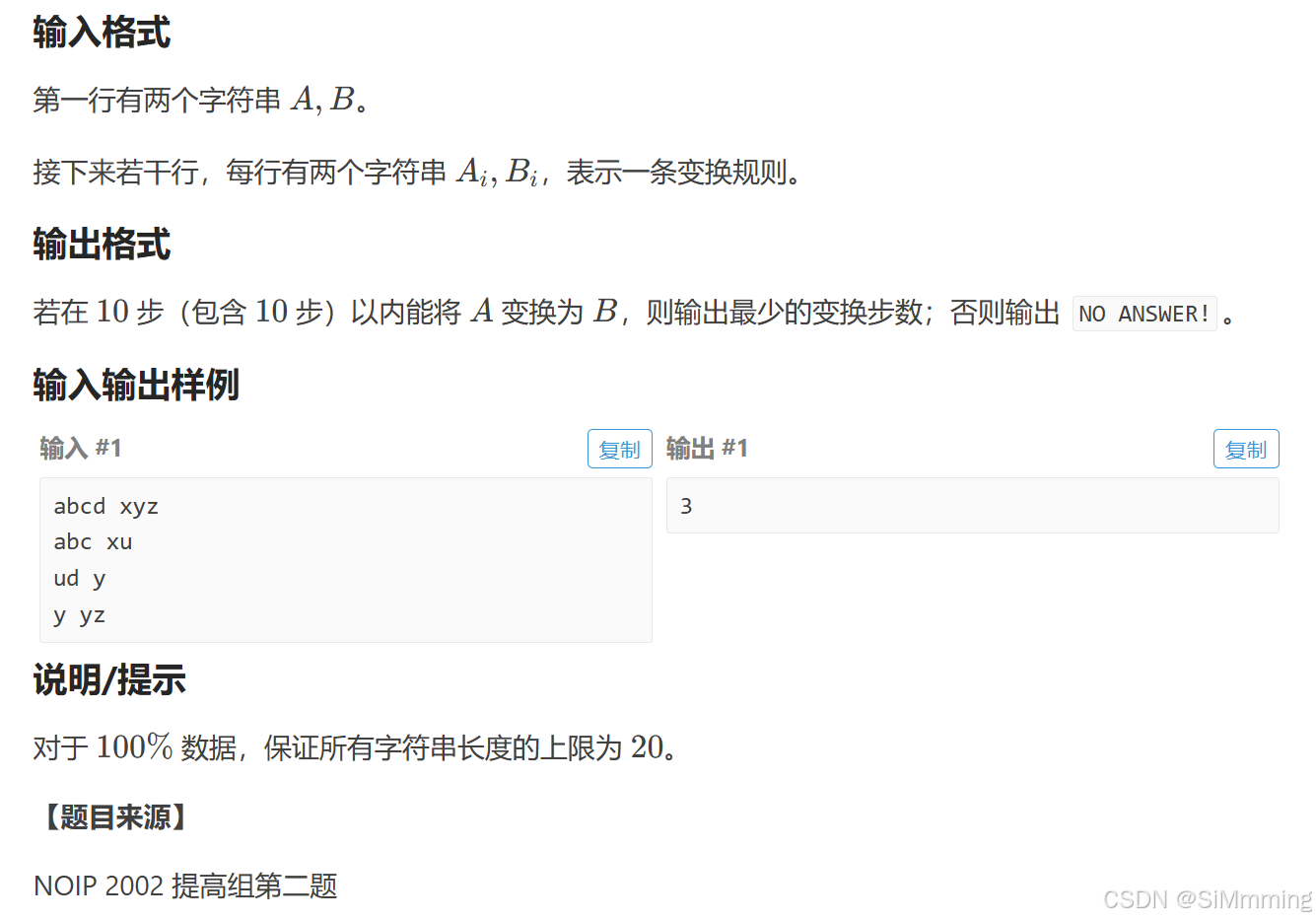
三、 思路及代码
1. 难点1:双向bfs如何判断相遇
bfs相比于dfs最具特色之一就是去重,存储bfs已经出现过的状态,这样在下次出现的时候可以有效判断。对于单向bfs,去重的作用是剪枝,对于双向bfs,去重的作用是判断相遇,因为如果两点出现的状态重合了,那么说明两点相遇了。去重常使用哈希表实现
2. 难点2:双向bfs用什么数据结构实现
此处采用两个队列,一个队列从起点出发,一个起点从终点出发,每次进行“一层”拓展时,优先拓展队列中结点少的那一个
3. 难点3:字符串的各种操作
首先,一开始写的时候出现了一个误区,只能ac80%的点,就是每次替换字符串的时候只替换了第一个位置,而不是全部位置。刚开始的想法是,反正是搜索,不同的选择等到下一次再拓展,但是忽略了下一层拓展不是在s0的基础上替换了,而是在s0基础上替换过的s1的基础上拓展,这样就导致了每次生成的字符串并不全面。所以每次替换时,一定要记录所有可以替换的点。解决办法是:采用一个vector存储所有替换后生成的字符串
其次,字符串的各类操作(string的参数一般都是起点+len,而不是起点+终点)
#include <cstring>
#include <string>①find和rfind
a.find(b):从开始找b第一次出现的位置并返回
a.find(b,pos):从pos开始找b第一次出现的位置并返回
rfind(b)或rfind(b,pos):从结尾开始倒着找
>>>如果没有找到,返回npos,即-1
写代码判断时以下两种方法等价
s.find(s1)==string::nposs.find(s2)==-1②replace
a.replace(pos,len,string b):替换a中pos开始往后len的这些字符为b
>>>常和find一起使用
③substr
sub(start,length):切割从start开始的长度为length的子串
>>>如果第二个参数不写,就是从start到字符串结尾
④insert
a.insert(pos,string b):在pos处插入另一个字符串b
⑤erase
a.erase(pos,n):删除从pos开始的n个字符
⑥clear
a.clear():清空字符串
⑦length
a.length():长度【注意不是size】
⑧swap
swap(a,b):交换字符串a,b的内容
⑨int转string
int x=1;
string y=x.str();⑩string转char*
string str=“world”;
const char *p = str.c_str();//要加const或者等号右边用char*//不加的话devc会报错
String转char[ ],直接循环赋值
string pp = "dagah";
char p[8];
int i;
for( i=0;i<pp.length();i++)
p[i] = pp[i];
p[i] = '\0';> < == != : 根据字典序比较
inline bool cmp(string a,string b)
{return a>b;}
...
int main()
sort(a+1,a+1+n,cmp);4. map的用法
map是STL的一个关联容器,它提供一对一的hash。
- 第一个可以称为关键字(key),每个关键字只能在map中出现一次;
- 第二个可能称为该关键字的值(value);
①插入
(Ⅰ)insert:如果键已经存在,不能再插入值
Student.insert(pair<int, string>(000, "student_zero"));(Ⅱ)array:如果键已经存在,新插入的值会覆盖原来的值
Student[123] = "student_first";②查找
(Ⅰ)mapp.find():找到的话返回索引,没找到的话返回值与end()相等,即mapp.find()==mapp.end()
③删除与清空
(Ⅰ)关键字删除
Student.erase("123"); (Ⅱ)索引删除
iter = mapStudent.find("123");
mapStudent.erase(iter);(Ⅲ)清空1
mapStudent.erase(mapStudent.begin(), mapStudent.end());(Ⅳ)清空2
mapStudent.clear();④大小
mapp.size();⑤元素出现次数
返回指定元素出现的次数,(因为key值不会重复,所以只能是1or0)
mapp.count("123")也可以通过这种方式检查map中是否有某个元素,==0则没有
5. 代码
#include <bits/stdc++.h>
#include <unordered_map>
using namespace std;
string a, b;
string r1[100], r2[100]; // r1 -> r2
int cnt;
// 使用 unordered_map 提高查找效率
unordered_map<string, int> mp1, mp2;
struct Node {
string s;
int num;
};
// 双向 BFS
void bfs() {
queue<Node> q1, q2;
q1.push({ a, 0 });
mp1[a] = 0;
q2.push({ b, 0 });
mp2[b] = 0;
while (!q1.empty() && !q2.empty()) {
// 选择较小的队列进行扩展
if (q1.size() <= q2.size()) {
if (!q1.empty()) {
Node current = q1.front();
q1.pop();
// 判断是否相遇
if (mp2.count(current.s)) {
if (current.num + mp2[current.s] <= 10) {
cout << current.num + mp2[current.s] << endl;
return;
}
}
// 超过 10 步,终止
if (current.num > 10) return;
// 生成所有可能的替换后的字符串
for (int i = 0; i < cnt; ++i) {
const string& from = r1[i];
const string& to = r2[i];
string s = current.s;
vector<string> nexts;
size_t pos = 0;
while (true) {
pos = s.find(from, pos);
if (pos == string::npos) break;
string new_s = s.substr(0, pos) + to + s.substr(pos + from.size());
nexts.push_back(new_s);
pos++; // 避免连续匹配
}
// 处理所有生成的字符串
for (const auto& new_s : nexts) {
int new_num = current.num + 1;
if (mp1.find(new_s) == mp1.end()) {
mp1[new_s] = new_num;
q1.push({ new_s, new_num });
}
}
}
}
}
else {
if (!q2.empty()) {
Node current = q2.front();
q2.pop();
// 判断是否相遇
if (mp1.count(current.s)) {
if (mp1[current.s] + current.num <= 10) {
cout << mp1[current.s] + current.num << endl;
return;
}
}
// 超过 10 步,终止
if (current.num > 10) return;
// 生成所有可能的替换后的字符串(反向规则)
for (int i = 0; i < cnt; ++i) {
const string& from = r2[i];
const string& to = r1[i];
string s = current.s;
vector<string> nexts;
size_t pos = 0;
while (true) {
pos = s.find(from, pos);
if (pos == string::npos) break;
string new_s = s.substr(0, pos) + to + s.substr(pos + from.size());
nexts.push_back(new_s);
pos++; // 避免连续匹配
}
// 处理所有生成的字符串
for (const auto& new_s : nexts) {
int new_num = current.num + 1;
if (mp2.find(new_s) == mp2.end()) {
mp2[new_s] = new_num;
q2.push({ new_s, new_num });
}
}
}
}
}
}
// 未找到路径
cout << "NO ANSWER!" << endl;
}
int main() {
cin >> a >> b;
while (cin >> r1[cnt] >> r2[cnt]) {
cnt++;
}
bfs();
return 0;
}注意:
1.因为bfs是逐层扩展的,所以在判断是否需要将当前步数数值存在哈希表中时,直接判断它原来是否存在,如果不存在则存入,存在的话则不存入,因为逐层扩展,所以当前的步数肯定是大于等于之前的步数的,越先存入步数越小
2.注意搜索到或者步数>10时用return而不是break;用return是直接结束整个函数,break是退出循环,用break的话,最后的no anwser还是会执行,覆盖之前的答案
参考:

















 456
456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









