






目录
1.请求行:POST/user/info?new_user=true HTTP/1.1
(1)Host值是主机域名,主机域名结合请求行里的资源路径可以得到一个完整的网址
3.请求体:可以放入客户端传给服务器的其他任意数据,但是GET方法的请求体一般是空的
一、HTTP概述
HTTP(Hypertext Transfer Protocol)(超文本传输协议)。它是一种客户端和服务器之间的请求-响应协议。比如浏览器可以被看做客户端,当我们再浏览器的网址栏输入网址并按下回车键后,就相当于给服务器发送了一个请求,然后等待服务器返回给浏览器响应。

二、HTTP的请求方法,常见的有GET方法和POST方法
1.GET:主要用于获得数据
比如当我们进入网页时,浏览器会发送GET请求得到网页内容
2.POST:主要用于创建数据
比如当我们提交注册表单时浏览器会发送POST请求,把你的用户名、密码等信息放到请求主体里给到服务器
由于爬虫程序基本上是在获得数据所以我们发送的请求大部分情况用GET方法
三、完整的请求类型:请求行、请求头、请求体
样例:
POST/user/info?new_user=true HTTP/1.1(请求行)
Host:www.example.com (请求头,这三行)
User-Agent:curl/7.77.0
Accept:*/*
{"username":"啦啦啦", (请求体,大括号)
"email":"abababa@qq.com"
}
1.请求行:POST/user/info?new_user=true HTTP/1.1
分别为:方法类型、资源路径、查询参数、协议版本
(1).资源路径:指明了你要访问服务器的哪个资源
比如www.douban.com/moive/top250?start = 75&filter=unwatched ,第一个斜杠表示资源路径的根,根后面的/moive/top250(第一个/到?)就是要访问的资源的路径,样例中是是/user/info。
(2).查询参数:
比如上面的网址的?后面的start = 75&filter=unwatched 就是查询参数,可以传递给服务器额外的信息不同信息之间用&符号分隔,比如start=75可以表示豆瓣的服务器就知道给客户返回的页面内容从排再第75的电影往后展示。样例里就是new_user=true。
(3).协议版本:
指的是HTTP协议的版本比如HTTP/1.0、HTTP/1.1等。
2.请求头:
比如:Host:www.example.com
User-Agent:curl/7.77.0
Accept:*/*
会包含一些给服务器的信息比如Host、User-Agent、Accept等等
(1)Host值是主机域名,主机域名结合请求行里的资源路径和查询参数可以得到一个完整的网址
结合后如下:www.example.com/user/info?new_user=true
www.example.com是域名
/user/info是路径
new_user=true是查询参数
(2)User-Agent:curl
用来告知服务器客户端的相关信息。比如告知服务器客户端的请求是浏览器还是其他东西发出来的,如果是浏览器的话,类型是什么版本是什么等等。
例子:
curl命令行工具发出请求的User-Agent :curl/7.77.0
Python的Requests库发出请求的User-Agent:python-requests/2.25.1
Chrome发出请求的User-Agent:Mozilla/5.0(Macintosh;Intel Mac OS X 10_15_7)
AppleWebKit/537.36(KHTML,like Gecko)Chrome/108.0.0.0Safari/537.36
(3)Accept:*/*是在告诉服务器客户端想接收的响应数据是什么类型的,接收多种类型的话可以用逗号分割,如果是*/*表示啥类型都行
例子:
接受HTML:text/html
接受JSON:application/json
接受HTML和JSON text/html,application/json
接受任意类型:*/*
3.请求体:可以放入客户端传给服务器的其他任意数据,但是GET方法的请求体一般是空的
比如:
{"username":"啦啦啦",
"email":"abababa@qq.com"
}
四、完整的HTTP响应
服务器在接收到HTTP请求后它会根据所有这些信息返回HTTP响应
HTTP响应也分为三部分:状态行、响应头、响应体
比如:
HTTP/1.1 200 OK (状态行)
Date:Fri,27 Jan 2023 02:10:48 GMT (下面两行是响应头)
Content-Type:text/html;charset=utf-8
<!DOCTYPE html> (剩下的是响应体)
<head><title>首页</title></head>
<body><h1>拉拉</h1><p>哈喽!</p></body>
</html>
1.状态行、
HTTP/1.1 200 OK
(1)协议版本
和请求的时候类似:
HTTP/0.9 、HTTP/1.0、HTTP/1.1、HTTP/2.0
(2)状态码和状态消息
常见的状态码和状态消息如下
2开头表示请求成功,3开头表示表示重定向需要进一步的操作,4开头表示客户端错误比如请求里面有错误或者请求资源无效,5表示服务器错误比如服务器错误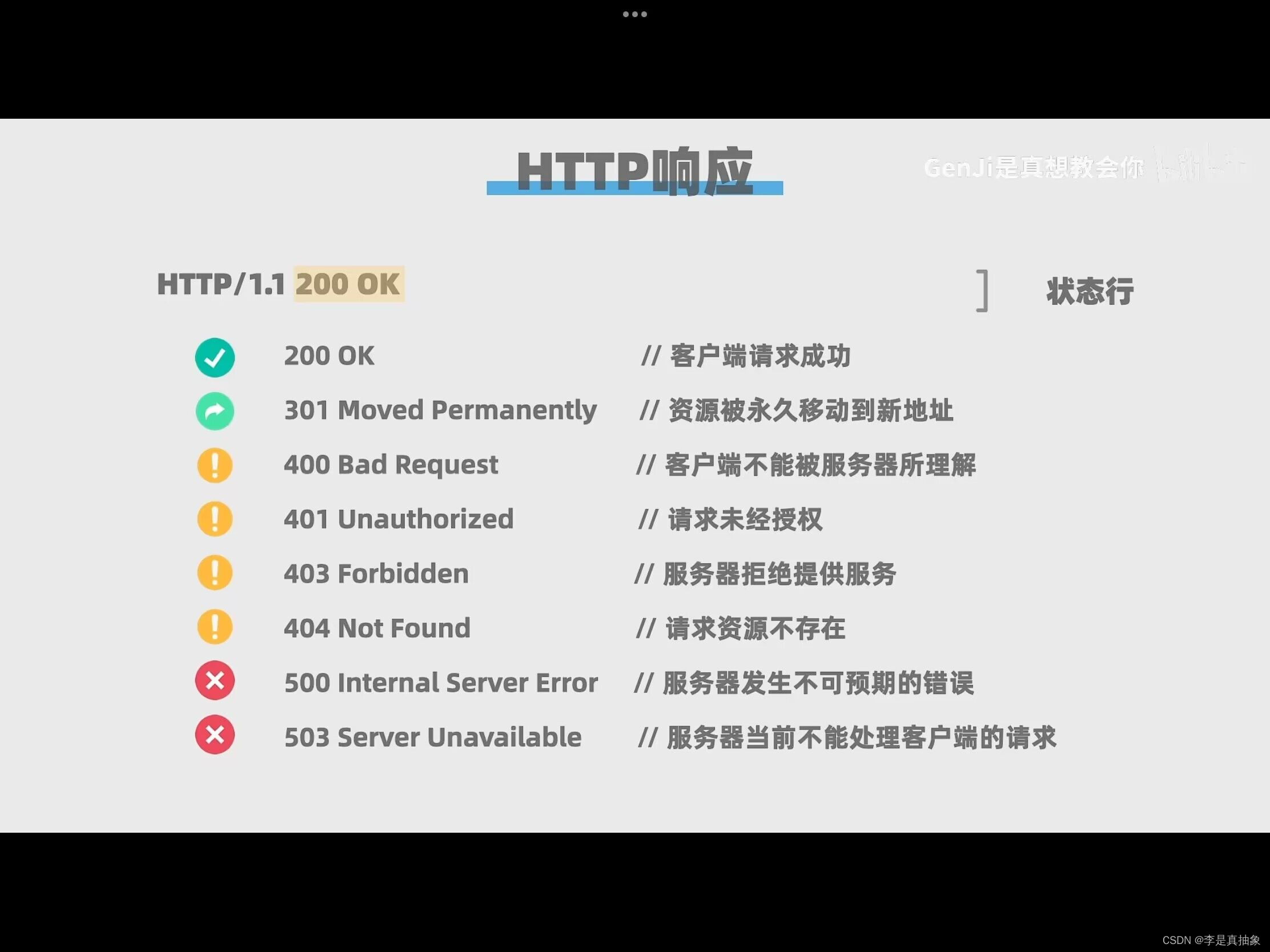
2.响应头
Date:Fri,27 Jan 2023 02:10:48 GMT
Content-Type:text/html;charset=utf-8
会包含一些告知客户端的信息
Date:生成响应的日期和时间
Content-Type:返回内容的类型及编码格式
例子:
text/html;charset=utf-8 响应类型是html,编码是UTF-8
application/json;charset=utf-8 响应类型是html,编码是UTF-8
3.响应体
<!DOCTYPE html>
<head><title>首页</title></head>
<body><h1>拉拉</h1><p>哈喽!</p></body>
</html>
就是服务器想给客户端的数据内容
比如前面的响应类型是html那么这里就是html内容















 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









