






目录
抽象数据类型(ADT)是抽象数据组织及与之相关的操作(使用者)
3.索引存储(相当于不加哈希函数的哈希表,占据空间大,比如数组)
(二)时间复杂度:事前预估算法时间开销T(n)与问题规模n的关系
一、数据结构的基本概念
(一)数据
数据:数据是信息的载体,是描述客观事物属性的数、字符及所有能输入到计算机中并被计算机程序识别和处理的符号的集合。数据是计算机程序加工的原料。
从底层硬件看来,计算机识别的是二进制0和1
早期计算机:只用于处理纯数值型问题(为了适应战争,计算导弹轨道之类)
现代计算机:经常处理非数值型问题:1.我们关心每个个体的具体信息(其实就是数据元素和数据项) 2.关心个体与个体之间的相互逻辑关系
(二)数据元素、数据项
数据元素是数据的基本单位,通常作为一个整体进行考虑和处理。
一个数据元素可由若干数据项组成,数据项是构成数据元素的不可分割的最小单位
用来描述一个个体,和上述现代计算机数据的概念相照应(类似于一个结构体里的某个变量或者一个类里面的成员变量,是用来描述这个类的)
class Person
{
private:
int age;
int height;
int weight;
};
这里 Person类的实例就是数据元素,其age、height、weight就是数据项
如果数据项还能细分,比如年月日,这种数据项我们称之为组合项
(三)数据对象、数据结构
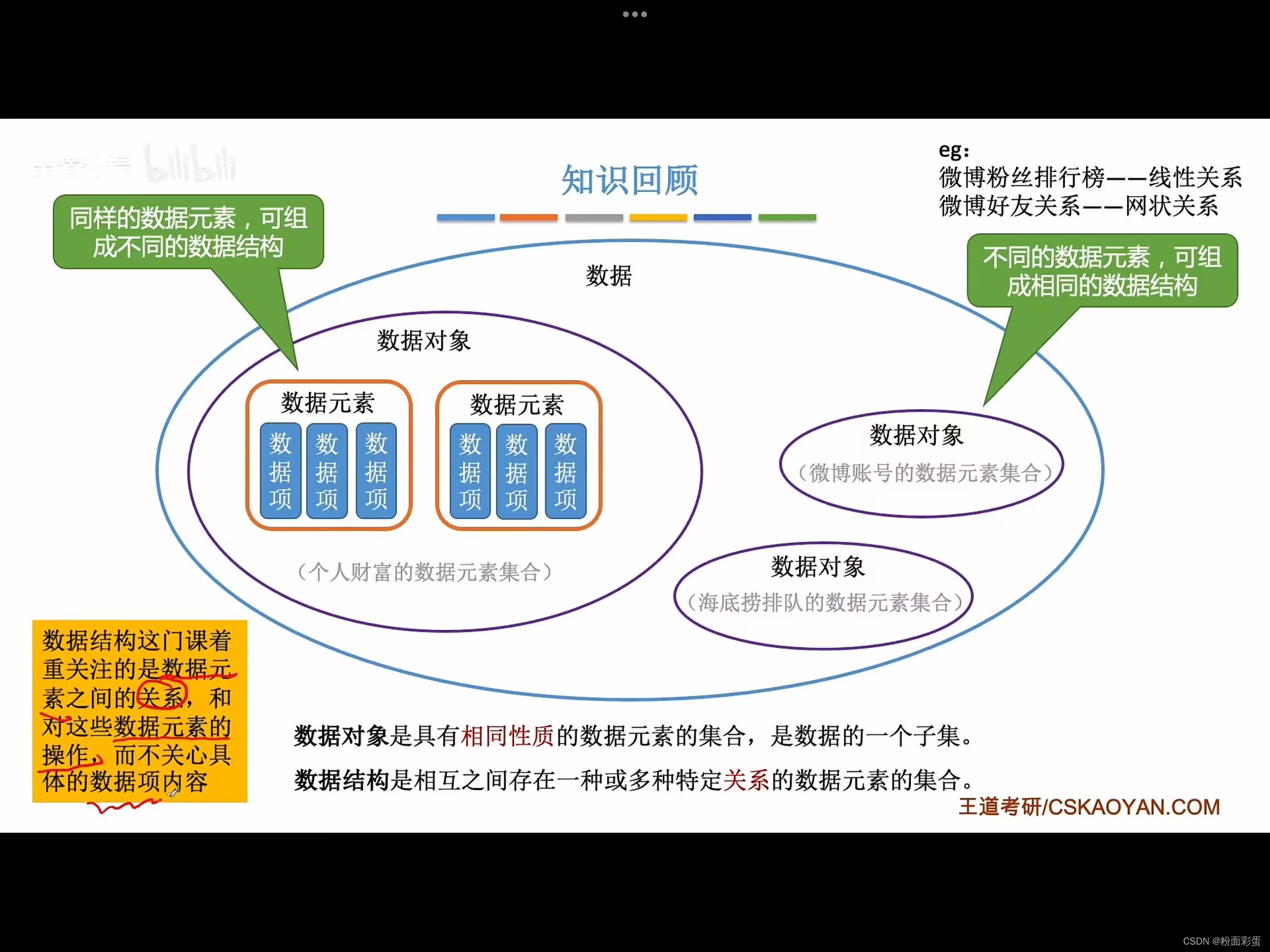
数据对象:是具有相同性质的数据元素的集合,是数据的一个子集
比如一个Person类,它的实例有person1,person2,person3……这些实例都是建立在这个类的基础上产生的,可以看出这些person实例的成员属性的变量名是一样的只不过值不同。因此这些实例是相同性质的数据元素。因而这些实例的集合就称为数据对象。
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。
同一种数据元素,可以组成不同的数据结构,而不同的数据结构也可以组成相同的数据结构。因为数据结构只关心数据之间的逻辑关系,(是线性还是网状?)不关心数据内容,两者之间是互相独立的,互不影响的。这也是数据结构这门课的核心,只关注关系,而不关注数据项的内容。
(四)数据类型、抽象数据类型
数据类型是一个值的集合和定义在此集合上的一组操作的总称(只是逻辑方面,意思是不关系如何用计算机存储实现)
1.原子类型。其值不可再分的数据类型。比如:
bool类型
值的范围:true、false (值的集合)
可进行操作:与、或、非(操作)
int类型
值的范围:-2147483648~2147483647(值的集合)
可进行操作:加、减、乘、除、模运算...(操作)
2.结构类型。其值可以再分解为若干成分(分量)的数据类型。
而且结构内的数据具有一定的逻辑关系(是有序对),相当于pair<x,y>。
(其实就是结构体)比如:
struct Coordinate{
int x; //横坐标
int y; //纵坐标
};
可进行的操作:加、减、计算到原点的距离...(可以用函数封装)
抽象数据类型(ADT)是抽象数据组织及与之相关的操作(使用者)
存储结构是实现者的事,不是使用者的事,因此
定义一个ADT就是定义了一个数据结构
通常用(数据对象,数据关系,基本操作集)这样的三元组来表示
二、数据结构的三要素
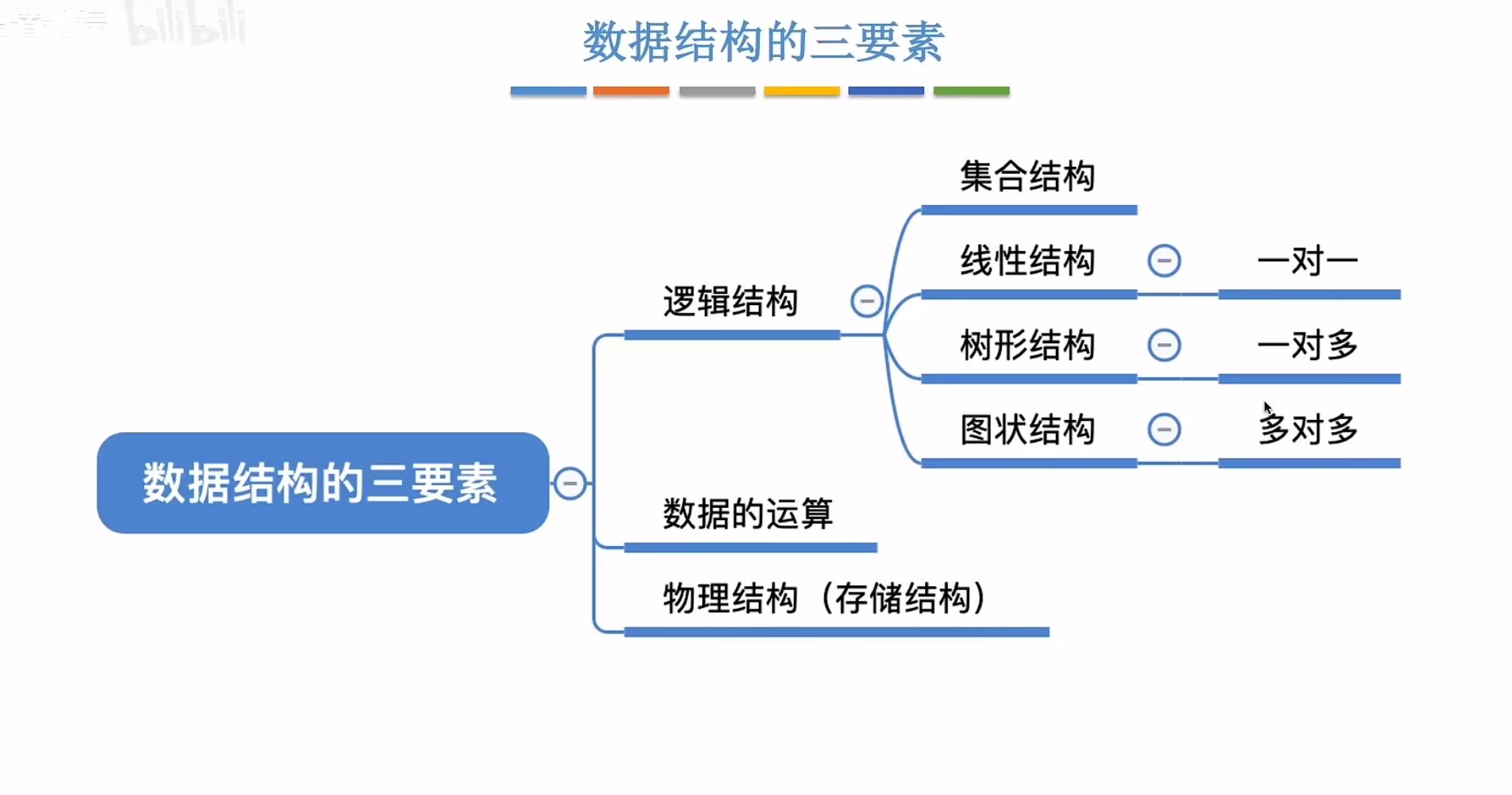
(一)逻辑结构
1.集合结构: 独立且无序
2.线性结构:除了第一个元素都有唯一前驱;除了最后一个元素,所有元素都有唯一后继(队列、栈)
3.树形结构:比如文件夹、思维导图
4.图状结构:比如道路、朋友圈
(二)数据的运算
定义:针对某种逻辑结构,结合实际需求,定义基本运算
比如对于线性结构:
1.查找第i个数据元素(find)
2.在第i个位置插入新的数据元素(insert)
3.删除第i个位置的数据元素(erase)
定义好一个逻辑结构和数据的运算后,相当于定义好了一个数据结构
(三)物理结构(存储结构)(具体的计算机实现)
1.顺序存储(vector)
定义:把逻辑上相邻的元素存储在物理位置上也相邻的存储单元中,元素之间的关系由存储单元的邻接关系来体现。
在顺序存储时,相邻两个元素是各自的前驱和后继
需要开辟大片连续空间
2.链式存储(list)
逻辑上相邻的元素在物理位置上可以不相邻,借助元素存储地址的指针来表示元素之间的逻辑关系
可以是离散存放
3.索引存储(相当于不加哈希函数的哈希表,占据空间大,比如数组)
在存储元素信息的同时,还建立附加的索引表。在索引表中的每项称为索引项,索引项的一般形式是(关键字,地址)
4.散列存储(哈希表 map)
根据元素的关键字直接计算出该元素的存储地址,又称哈希(Hash)存储
为什么需要那么多存储结构?
1.若采用顺序存储,则各个数据元素在物理上必须是连续的;若采用非顺序存储,则各个数据元素在物理上可以是离散的。
2.数据的存储结构会影响存储空间分配的方便程度
3.数据的存储结构会影响对数据运算的速度 Eg:在b和d之间插入新元素c
三、什么是算法
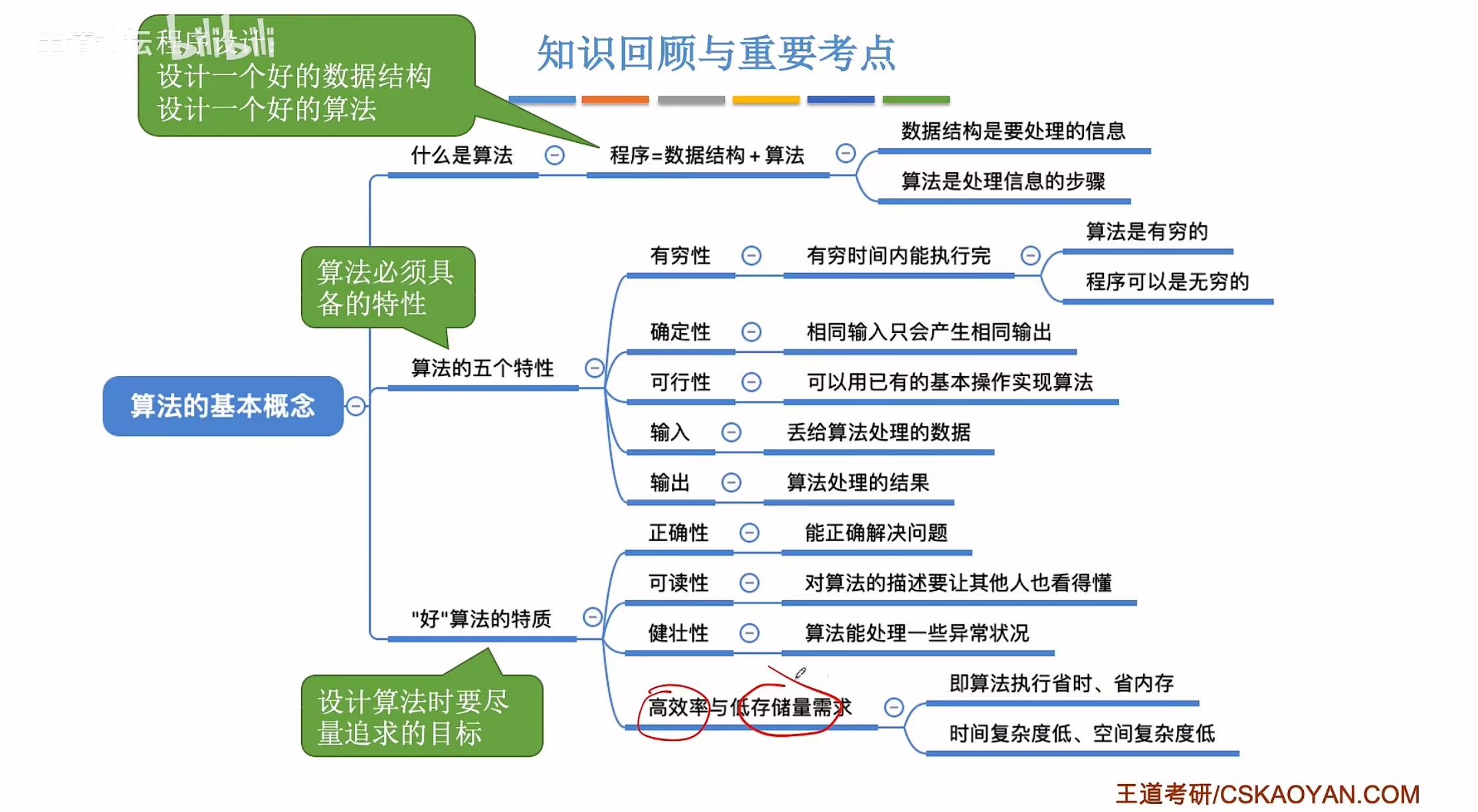 程序=数据结构+算法
程序=数据结构+算法
(正确地描述显示问题,并存入计算机+如何高效地处理这些数据,以解决实际问题)
(一)算法的定义
算法(Algorithm)是对待定问题求解步骤的一种描述,它是指令的有限序列,其中的每条指令表示一个或多个操作
(二)算法的特性(全是必要条件)
1.有穷性。一个算法必须总在执行有穷步之后结束,且每一步都可以在有穷时间内完成(因为要通过一定的步骤解决问题,如果无穷时间那就是解决不了问题)
注:算法必须是有穷的,而程序可以是无穷的(这是算法和程序的区别)(微信不是算法,是程序)
2.确定性。算法中每条指令必须有确切的含义,对于相同的输入只能得出相同的输出。
3.可行性。算法中描述的操作都可以通过已经实现的基本执行有限次来实现。(说人话就是能用编程来实现)
4.输入。一个算法有零个或多个输入,这些输入取自于某个特定的数据对象的集合。
5.输出。一个算法有一个或多个输出,这些输出是与输入有着某种特定关系的量。
算法和函数很像。
(三)好算法的特质
1)正确性。算法能够正确地解决求解问题(虽然有的算法解决不了问题但也叫算法)
2)可读性。算法应具有良好的可读性,以帮助人们理解。//注释
3)健壮性。输入非法数据时,算法能适当地做出反应或进行处理,而不会产生莫名其妙的输出结果。
4)高效率与低存储量需求(时间复杂度和空间复杂度低)
四、算法的时间复杂度
(一).事后统计
缺点:1.和机器性能有关,如:超级计算机 v.s.单片机
2.和编程语言有关,越高级的语言执行效率越低
3.和编译程序产生的机器指令质量有关
4.有些算法使不能事后统计的,如:导弹控制算法
(二)时间复杂度:事前预估算法时间开销T(n)与问题规模n的关系
T(n)只需要考虑阶数高的部分 O(f(n))
O一般表示最坏的时间复杂度,是时间的上限
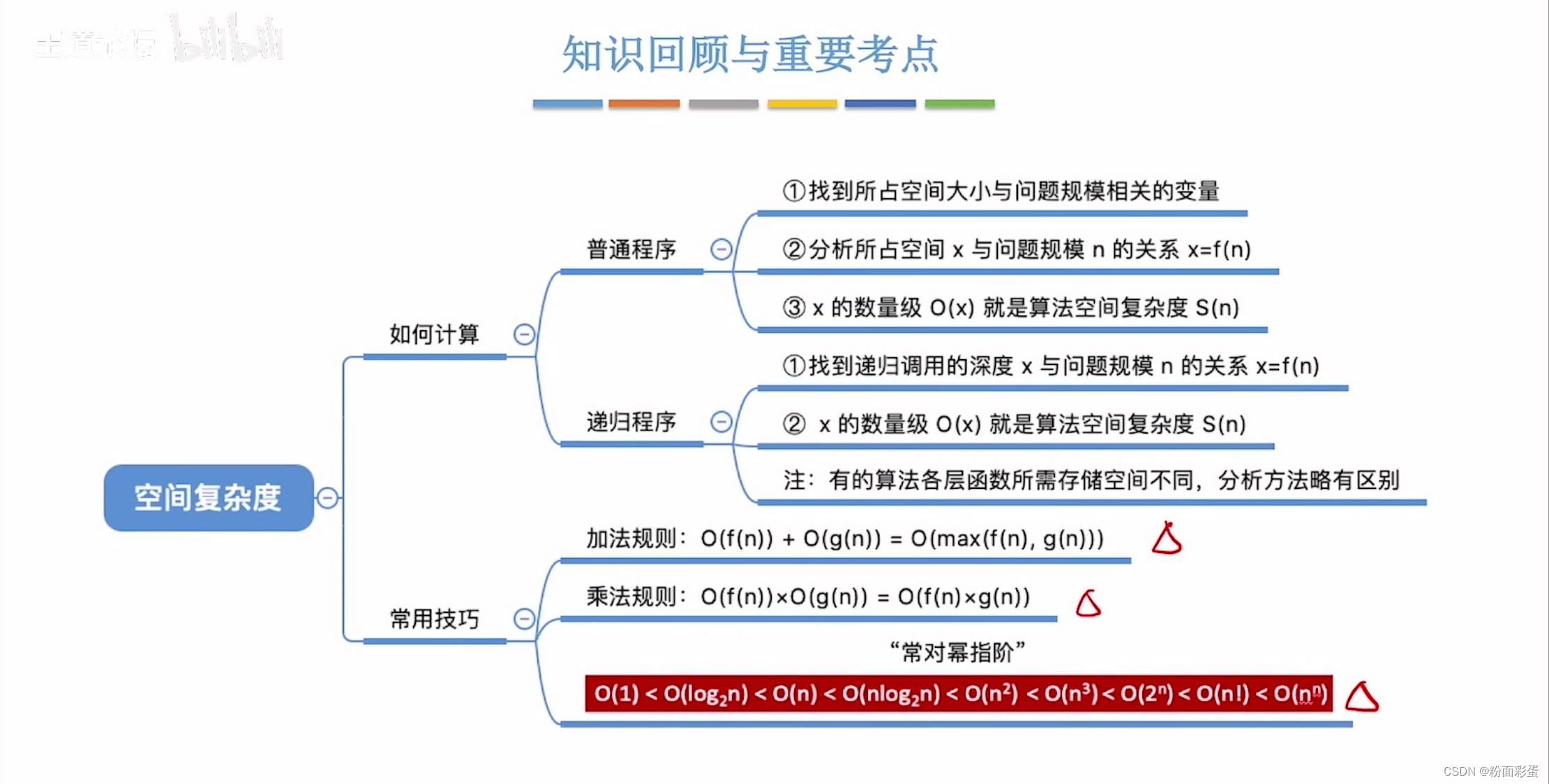
a)加法规则
T(n)=T1(n)+T2(n)=O(f(n))+O(g(n))=O(max(f(n),g(n)))
b)乘法规则
T(n)=T1(n)xT2(n)=O(f(n))xO(g(n))=O(f(n)xg(n))
计算量图像:左边从上往下复杂度越来越高
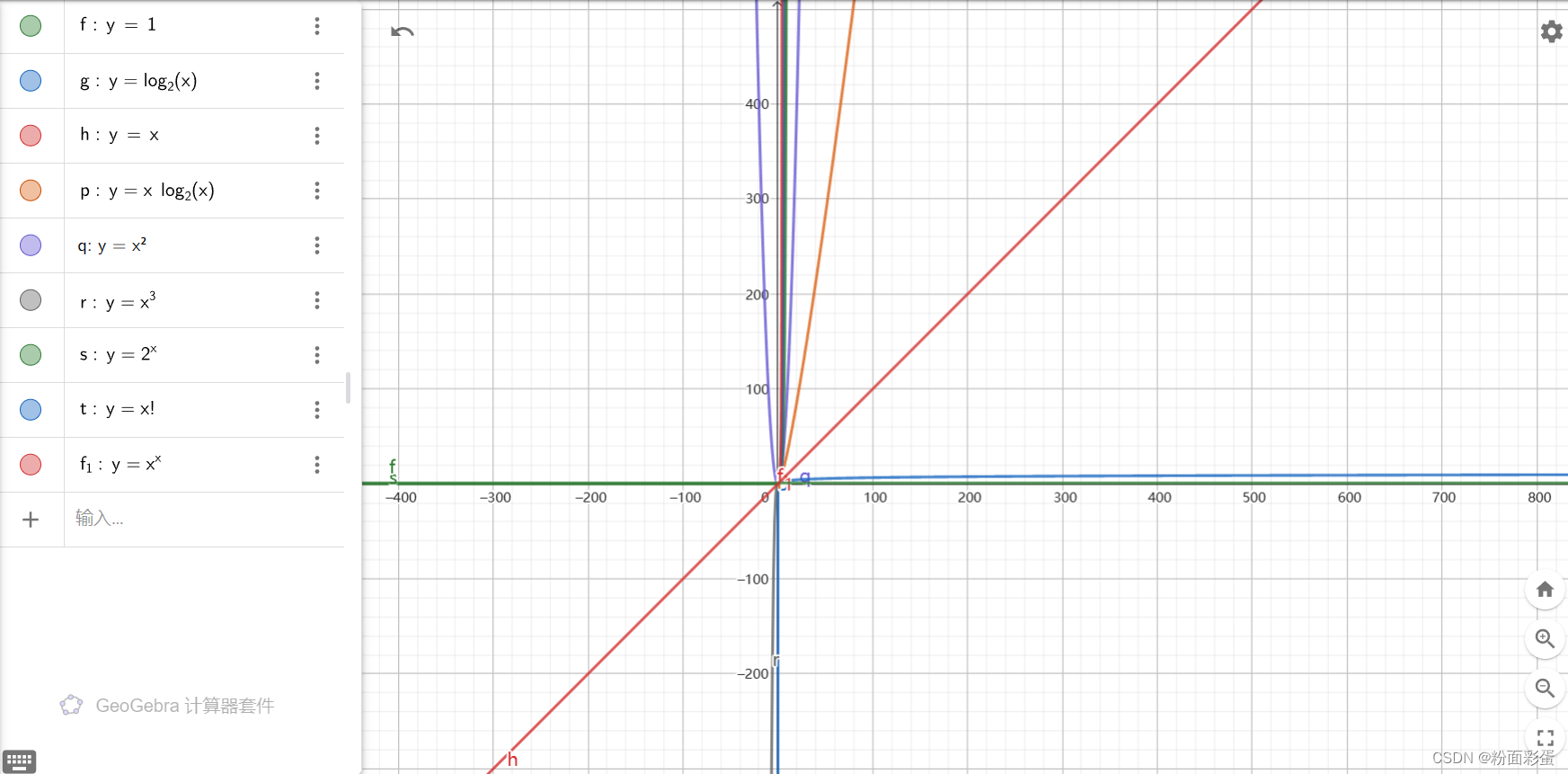 (三)常见时间复杂度所对应的算法
(三)常见时间复杂度所对应的算法
O(1)没有for循环
O(logn):二分查找,分治策略,二叉树的查找,堆的旋转,快速幂、欧几里得算法
O(n):顺序查找、顺序插入、前缀和、一维差分、基数排序、拓扑排序、高精度算法、单调栈、单调队列、数位dp、dfs、bfs
O(nlog2n):归并排序、快速排序、堆排序、n次二分查找,kruskal算法(数据是边)
O(n2):选择排序、插入排序、希尔排序(最坏)、冒泡排序、01背包问题、完全背包问题、多重背包问题、Dijkstra算法、Prim算法、计数dp
O(n3):floyed算法、区间dp
O(2^n):状态压缩dp(Hamilton路径问题)
O(n!):鄙人没遇到过
O(n^n):鄙人没遇到过
(四)时间复杂度类型
最好时间复杂度:一般不考虑
最坏时间复杂度:
平均时间复杂度:算所有元素位置的数学期望(就是循环到某个元素的次数再乘它的概率)
提示:算法的性能问题只有在n很大时才会暴露出来。
五、算法的空间复杂度
空间分类
(一)程序代码:
运行之前经过编译指令生成机器语言所占的空间,和问题规模没什么关系
(二)数据:局部变量i、参数n
S(n)=S(1)表示无论问题规模怎么变,算法运行所需要的内存空间都是固定的常量,算法空间复杂度为S(n)=O(1)
注:S表示“Space”
算法原地工作---算法所需内存空间为常量
int flag[n]//声明一个长度为n的数组,空间复杂度:S(n)=O(n)
int flag[n][n]//声明一个二维数组 空间复杂度:S(n)=O(n^2)
递归调用空间复杂度S(n)=递归层数*每层空间复杂度
六、王道课后题

顺序表的概念:把逻辑上相邻的结点储存在物理位置上的相邻储存单元中,结点的逻辑关系由储存单元的邻接关系来体现(体现了存储结构)
哈希表的性质:哈希表用的是数组支持按照下标随机访问数据的特性,所以哈希表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。(哈希表要用到数组这种存储结构,因此哈希表是一种存储结构)
有序表的概念:是指这样的线性表,其中所有元素以递增或递减方式有序排列。有序表是线性表的一部分。(由此可以知道,有序表是逻辑结构,线性表也是逻辑结构)
单链表的概念:单链表是一种链式存取的数据结构,用一组地址任意的存储单元存放线性表中的数据元素。链表中的数据是以结点来表示的,每个结点的构成:元素(数据元素的映象) + 指针(指示后继元素存储位置),元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。(单链表提到了线性表的计算机实现方式是用指针的形式,因此属于存储结构)

循环队列指定了其实现方式是数组,因此是一种存储结构。而栈既可以是数组实现,也可以链表实现。

数据的操作方法:属于算法,而算法是实现的方法,是不需要存储的。比如玩游戏时,我们只关注生命值的多少和变化,并不在乎生命值是如何用算法实现的。(对于玩家而言)
数据的存取方法:这个也属于算法,比如查找、删除、增加之类
数据元素的类型:当计算机存入数据时,其实存的是一串二进制数据,类型的表示是根据内存的地址不同来区分的。
数据元素的关系:就是用存储结构实现具体的逻辑结构,比如打boss后掉落的装备必须和某个boss相关,不能说打完最弱的boss掉落终极武器,这种逻辑关系需要存储。

瞎了。


A肯定不对,程序是程序,算法是算法。
题干中写到了“是”,说明是考察定义的。C是算法的必要条件,不是算法的定义。

计算时间复杂度可以用放缩的思想,然后把系数省略。

算法原地工作的含义是空间复杂度S(n)=O(1)。
有辅助空间不一定空间复杂度就不是O(1)了。
比如让你统计一篇文章26个字母的每个字母出现个数,那么就可以开辟一个大小为26的辅助数组,这个26就与这篇文章的长短无关了。
这个一眼就看出来是冒泡排序,但还是要学会具体分析的方法的。
两个for循环可以用两个求和公式写出来。要从内往外看,最里面时间复杂度为O(1),
内循环需要从j=1遍历到i-1,外循环需要从i=2遍历到n-1,就分别写在求和公式的上下端,计算即可。

k次循环就会有k+1次判断
计算时间复杂度除了可以设运行t次算出变量的大小与判断值作比较外,还可以设第k次执行循环终止。第k次循环时,写出x与n的大小关系(是判断条件的补集),在写出第k次判断即k-1次循环开始前x的大小(与k)相关,代入即可算出时间复杂度。

只看第三个,应该一眼就能看出来是O(n^3)
但要给出详细的解题步骤:
应该是。算出来是
这个求和 需要用到的前n项和公式
和等差数列的前n项和公式
所以最终结果是
这个很明显是T(n)=O(n^3)
先把前几项直接写出来不化简找规律,找不到规律再化到每一项最简找规律















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









