






 本文介绍了Hive,一个建立在Hadoop之上的数据仓库框架,用于ETL操作,通过HQL查询大规模数据。同时,详细阐述了HDFS作为Hadoop的核心存储系统,其特点和在大数据存储中的应用。
本文介绍了Hive,一个建立在Hadoop之上的数据仓库框架,用于ETL操作,通过HQL查询大规模数据。同时,详细阐述了HDFS作为Hadoop的核心存储系统,其特点和在大数据存储中的应用。
Hive
Hive概述
Hive是建立在 Hadoop 上的数据仓库基础构架。
它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
可以将SQL 查询转换为MapReduce 的job 在Hadoop集群上执行。
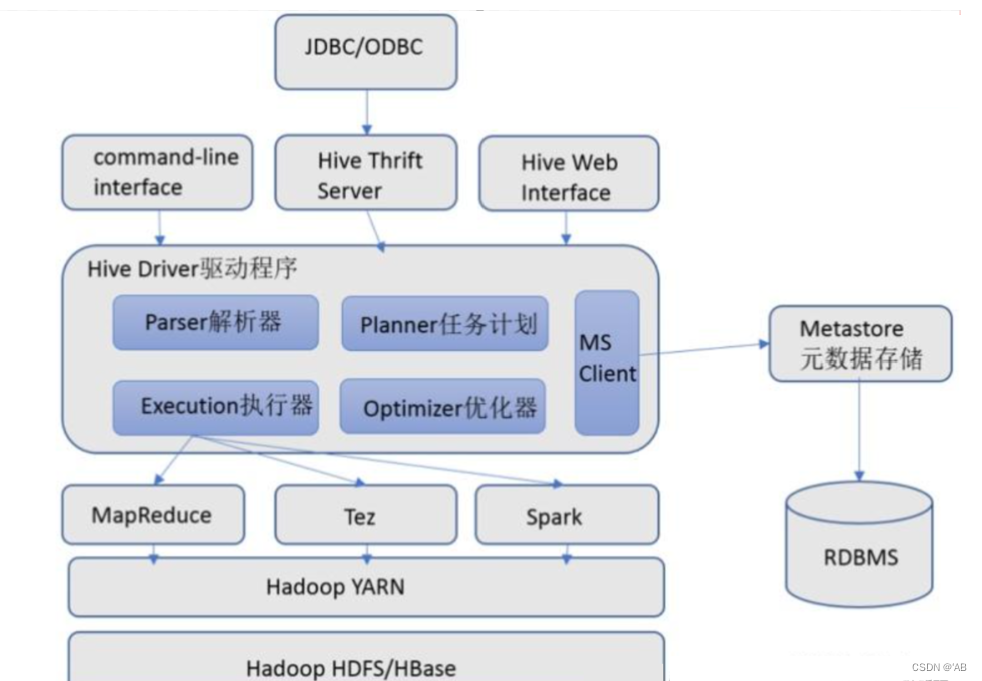
Hive架构
HDFS
HDFS概述
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型 数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统.
分布式文件系统解决的问题就是大数据存储。它们是横跨在多台计算机上的存储系统。分布式文件系统在大数据 时代有着广泛的应用前景,它们为存储和处理超大规模数据提供所需的扩展能力。
HDFS特点
HDFS文件系统可存储超大文件,时效性稍差。
HDFS具有硬件故障检测和自动快速恢复功能。
HDFS为数据存储提供很强的扩展能力。
HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改。
HDFS可在普通廉价的机器上运行。















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









