






目录
一.索引
一.索引的作用
索引是为了加快查询的速度
二. 索引背后的数据结构 B+ 树
一.B+树的特点
1. 一个节点,可以存储N个key,N个key划分出了N个区间~~~而不是(N+1个区间) 2.每个节点中的key的值,都会在子结点中也存在(同时key是子节点的最大值) 3.B+树的叶子节点,是首位相连,类似于一个链表 4. 整个树的所有数据都是包含在 叶子 节点中的!!!(所有的非叶子节点中的key 最终都会出现在叶子节点中) 5. 由于叶子节点是完整的数据集合,只在叶子节点这里存储数据表的每一行数据。 而非叶子节点,只存key值本身即可
这里不做过多介绍B+树, 只是简单提一下索引的实现, 举个例子来了解B+树
B+树就是在B树的基础上继续改进 (也是N叉搜索树)
// 例如 根节点给先给两个数据 : 8 15
// 那么 接下来只会分为两组:
// 小于8 大于8小于15
// 注意!!!此处的15相当于最大值~~~没有大于15的元素了!!
// 接下来继续往下分
// 例如为 [2 5 8] [11 15]
// 注意这时候 8 在父节点中有了 在子节点又来一遍 15也是
// 等排到最后的时候要把全部的叶子节点连接起来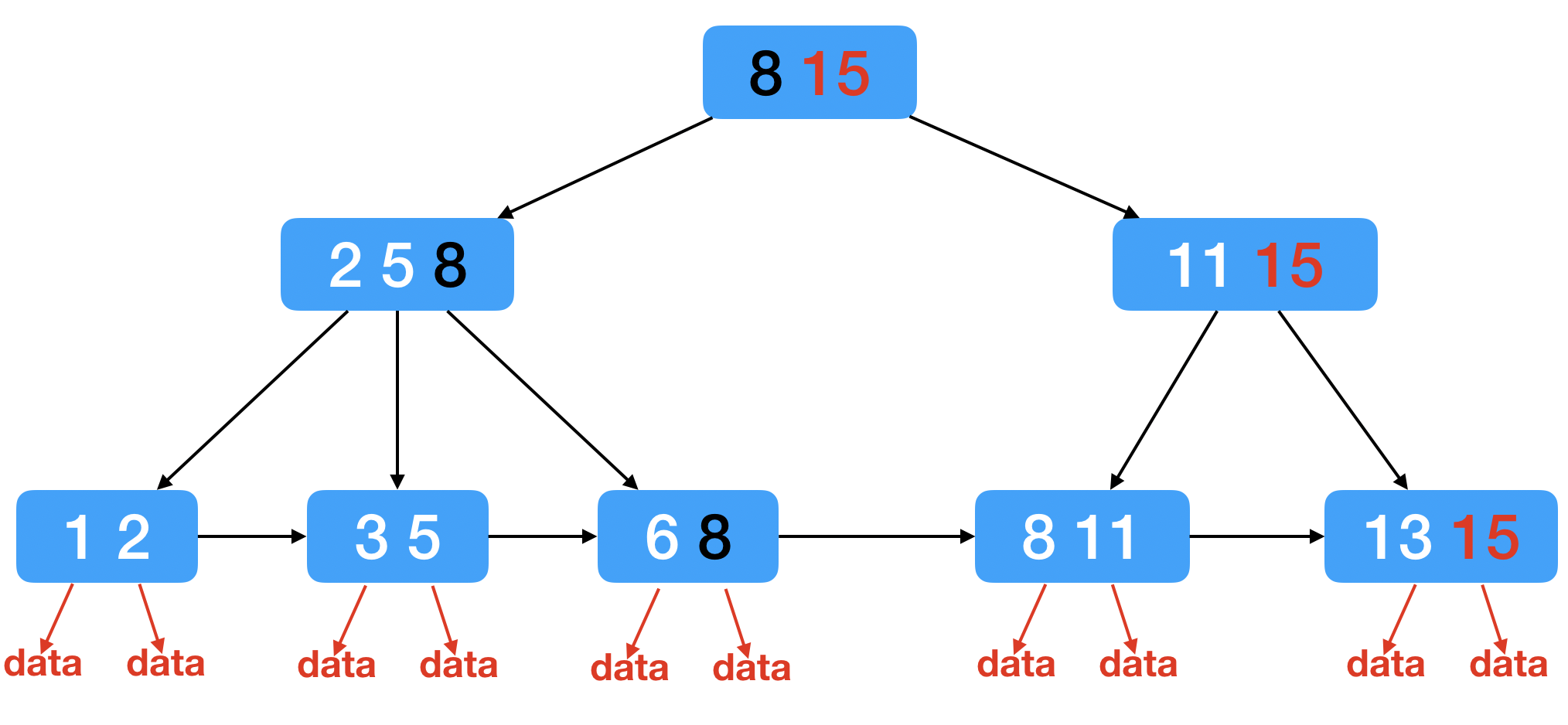
二.B+树的优点
1. 当前一个节点保存更多的key,最终树的高度是相对更矮的,查询的时候减少了IO访问次数。(和B树是一样的) 2. 所有的查询最终都会落到叶子节点上。(查询任何一个数据没经过的IO访问次数,是一样的) 3. B+树的所有的叶子节点,构成链表,此时比较方便进行范围查询 ~ ~ 4.由于数据都在叶子节点上,非叶子节点只存储key,导致非叶子节点占用空间是比较小的~~ 这些非叶子节点就可能在内存中缓存(或者是缓存一部分),又进一步减小了IO的次数
三.创建索引的方法
CREATE INDEX 索引名 ON 表名 (列名[(length)]);
#(列名(length)):length是可选项,下同
#如果忽略 length 的值,则使用整个列的值作为索引
#如果指定使用列前的 length 个字符来创建索引,这样有利于减小索引文件的大小
#索引名建议以“_index”结尾create index phone_index on member (phone);
#直接创建索引
select phone from member;
show create table member;
#展示表的结构以及创建表的具体语句二.事务
一.什么是事务
比如两个人要进行转账
1 给 2 500 (假设 1 里面有 1000 2 里面没有钱)
此时要执行一下sql操作
1. update account set balance = balance - 500 where id = 1;
2. update account set balance = balance + 500 where id = 2;
要分两步执行
而此时如果再转账的过程中 突然没有信号了 , 数据库炸了或者宕机了
而1又已经交过钱了
那么此时只会执行第一条语句 而 第二条语句
那么此时的结果就是 1 少了500 而 2 还是没有钱
那么此时用到 事务
事务就是把这两条语句封装一块
那么就是 要么全部执行要么全部不执行
事务的本质就是 把多个sql语句打包成一个整体 <---(事务的原子性)
要么全部执行要么全部不执行 (这里的不执行不是真的没执行,而是执行力执行到一半出错了。出错之后,选择了回复现场,把数据还原成未执行之前的状态) (这个恢复数据的操作叫做”回滚“(rollback));
而不会出现“执行一半“这样的中间件状态
二.事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务
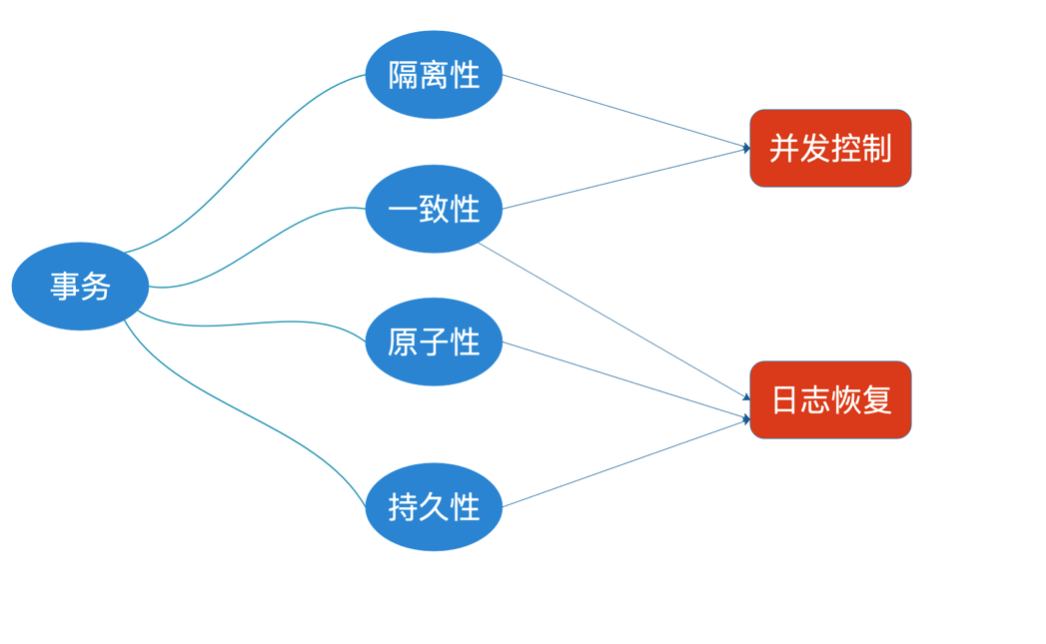
三.事务的四个关键特性
1. 原子性~【最核心的特性】 初心~
2. 一致性 事务执行前后,数据是靠谱的不能不科学~
3. 持久性 事务修改的内容是写到硬盘的,持久存在的。重启后也不丢失~
4. 隔离性 隔离性 是为了解决”并发“执行事务引起的问题
四.并发执行事务可能产生的问题
一.脏读问题:
比如: 一个事务A正在对数据进行修改的过程中,还没提交之前,另一个事务B,也对同一个数据进行了读取。 此时的B的读操作就成为”脏读“, 读到的数据也成为”脏数据“
解决方法:
mysql 引入了”写操作加锁“这样的机制 , 写的时候不能用,写完才可以用
这种操作叫做 写加锁
这个操作降低了并发程度(降低了效率),但是提高了隔离性(提高了数据的准确性)
二.不可重复读问题:
(已经定好了 写加锁)
具体情况解释: 事务1 已经提交了数据,此时事务2 开始去读取数据,在读取过程中,事务3又提交了新的数据。此时意味着同一个事务2之内,多次读取数据,读出来的结果是不相同的~~(预期是一个事务中,多次读取到的结果一样, 第二次的读取结果并与能复现第一次的结果 ~)
解决方法:
进行 ”读加锁“ ; 在事务读取数据的时候进行加锁,不让别人来修改数据
通过这个读加锁 又进一步的降低了事务的并发处理能力(处理效率也降低了),提高了事务的隔离性(数据的准确性又提高了)
三.幻读
当前一定预定了读加锁和写加锁,解决了不可重复读和脏读的问题
幻读的解释: 在读加锁和写加锁的前提下,一个事务两次读取同一个数据,发现读取的数据值是一样的,但是结果不一样~ ~
幻读的两种说法:
说法一:事务 A 根据条件查询得到了 N 条数据,但此时事务 B 删除或者增加了 M 条符合事务 A 查询条件的数据,这样当事务 A 再次进行查询的时候真实的数据集已经发生了变化,但是A却查询不出来这种变化,因此产生了幻读。
这一种说法强调幻读在于某一个范围内的数据行变多或者是变少了,侧重说明的是数据集不一样导致了产生了幻读。
说法二:幻读并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。更为具体一些:A事务select 某记录是否存在,结果为不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。产生这样的原因是因为有另一个事务往表中插入了数据。
解决办法就是
数据库使用”串行化“这样的方式来解决幻读,彻底放弃并发处理事务,一个接一个的串行的处理事务。
这样做,并发程度是最低的(效率最慢的),隔离性是最高的(准确性也是最高的)
四.四种隔离级别
针对上述问题 mysql 提供了4种隔离级别
1.read uncommitted (读未提交) 没有进行任何锁限制,并发最高(效率最高),隔离性最低(准确性最低)
2.read committed (不可重复读) 给了写加锁 并发程度降低 , 隔离性提高了
3.repeatable read (可重复读) 给写和读都加锁 并发程度又降低 , 隔离性又提高了
4.serializable (串行化) 串行化 并发程度最低,隔离性最高















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









