






这里是我找到的几种实现方法
一.用CNN算法的两种算法
1.(1)搭建卷积网络
import torch
from torch import nn
from torchvision import datasets
from torchvision import transforms
from torch.autograd import Variable
from torch.utils.data import DataLoader
from PIL import Image
import matplotlib.pyplot as plt
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(nn.Conv2d(3, 16, 3, padding=1), # 第一个卷积层,输入通道数3,输出通道数16,卷积核大小3*3
nn.ReLU(True), # 第一次卷积结果经过ReLU激活函数处理
nn.MaxPool2d(kernel_size=2, stride=2) # 第一次池化,池化大小2*2,方式Max pooling
)
self.layer2 = nn.Sequential(nn.Conv2d(16, 16, 3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(nn.Linear(56 * 56 * 16, 128), # 第一个全连接层,线性连接,输入节点数56*56*16,输出节点数128
nn.ReLU(True),
nn.Linear(128, 64), # 第二个全连接层,线性连接,输入节点数128,输出节点数64
nn.ReLU(True),
nn.Linear(64, 2) # 第三个全连接层,线性连接,输入节点数64,输出节点数2
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(x.size()[0], -1)
x = self.fc(x)
return x
(2)训练模型
from torch.utils.data import DataLoader
from torchvision import datasets
from CNN import CNN
import torchvision
from CNN import CNN
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
import torchvision
from torchvision import transforms
from PIL import Image
from torch.autograd import Variable
device = torch.device('cuda')
trans = torchvision.transforms.Compose([torchvision.transforms.Resize((224, 224)),
torchvision.transforms.ToTensor()])
root = "C:\DATA\data\mask"
data = datasets.ImageFolder(root="C:\DATA\data\mask", transform=trans)
loader = torch.utils.data.DataLoader(data, 1, True) #数据加载器
# 加载数据集
train_data = datasets.ImageFolder(root=r'C:\DATA\data\mask', transform=trans)
train_loader = torch.utils.data.DataLoader(train_data, 128, True)
learning_rate = 0.01
criterion = nn.CrossEntropyLoss()
####################################
model = CNN()
if torch.cuda.is_available():
print("CUDA is enable!")
model = model.to(device)
####################################
epoches_num = 50
cv.rectangle(img, (x, y), (x + w, y + h), color=(111, 222, 111), thickness=2) # 框上
model.train(True)
for epoch in range(epoches_num):
print('*' * 40)
train_loss = 0.0
train_acc = 0.0
for step, data in enumerate(train_loader):
inputs, label = data
if torch.cuda.is_available():
inputs = Variable(inputs).to(device)
label = Variable(label).to(device)
else:
inputs = Variable(inputs)
label = Variable
optimizer.zero_grad()#清除
outputs = model(inputs) # 网络前向传播
criterion = criterion.to(device)#损失函数
loss = criterion(outputs, label)
loss.backward()#反向loss
optimizer.step()#优化器
train_loss += loss.item() * label.size(0)
_, pred = outputs.max(1)
num_correct = pred.eq(label).sum()
accuracy = pred.eq(label).float().mean()
train_acc += num_correct.item()
torch.save(model, 'ooo.pt')
print('Finish {} Loss: {:.6f}, Acc: {:.6f}'.format(epoch + 1, train_loss / len(train_data),
train_acc / len(train_data)))
(3)人脸检测
import cv2 as cv
from torch.utils.data import DataLoader
from torchvision import datasets
import torchvision
from CNN import CNN
import torch
import torch.nn as nn
import torch.optim
import matplotlib.pyplot as plt
import numpy
from torchvision import transforms
from PIL import Image
from torch.autograd import Variable
device = torch.device('cuda')
model = torch.load('ooo.pt').to(device)
trans = torchvision.transforms.Compose([torchvision.transforms.Resize((224, 224)),
torchvision.transforms.ToTensor()])
model.train(False)
def face_detect_demo(filename):
face_cascade = cv.CascadeClassifier(
"D:\\Opencv\\opencv\\build\\etc\\haarcascades\\haarcascade_frontalface_alt.xml") # 声明face_cascade为CascadeClassifier对象,它负责人脸检测。
img = cv.imread(filename)
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray)
for (x, y, w, h) in faces:
cv.rectangle(img, (x, y), (x + w, y + h), color=(111, 222, 111), thickness=2) # 框上
# cv.imshow('result', img)
cropped_image = img[y:y + h, x:x + w] ##=裁剪后
if len(cropped_image):
cv.imwrite("C:\\DATA\\data\\mask\\no_mask\\10000.jpg", cropped_image)
image_path = Image.open("C:\\DATA\\data\\mask\\no_mask\\10000.jpg")
trans1 = trans(image_path)
trans1 = torch.reshape(trans1, (1, 3, 224, 224)).to(device)
OutPuts = model(trans1)
print(OutPuts)
_, pred = OutPuts.max(1)
# print(pred)
if pred == 1:
print("without_mask")
cv.putText(img, "without_mask", (y, x), cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255))
if pred == 0:
print("with_mask")
cv.putText(img, "with_mask", (y, x), cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255))
# cv.waitKey(0)
cv.imshow('result', img)
# elif(len(cropped_image)==0):
# print("未检测到人脸")
# cv.imshow('result', img) # 显示
cv.waitKey(10) #######!!!!!!!!!!!!!!!!!!!!!!
capture = cv.VideoCapture(0)
# cv.namedWindow("result", cv.WINDOW_AUTOSIZE)
while (True):
ret, frame = capture.read()
cv.imshow('1', frame)
cv.imwrite("C:\\DATA\\data\\mask\\have_mask\\1000.jpg", frame)
path = "C:\\DATA\\data\\mask\\have_mask\\1000.jpg"
face_detect_demo(path)
cv.waitKey(0)
cv.destroyAllWindows()
2.第二张也是cnn人脸检测

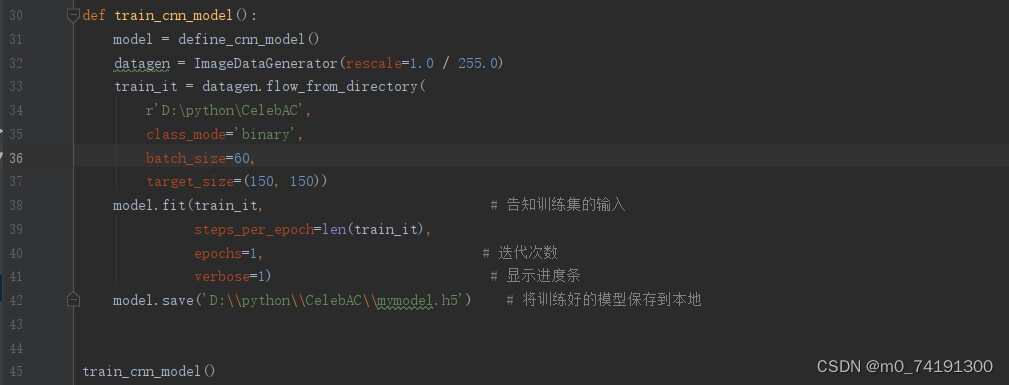


实现方法二
1.运用opencv自身的包来进行检测
import numpy as np
import cv2
import random
# multiple cascades: https://github.com/Itseez/opencv/tree/master/data/haarcascades
face_cascade = cv2.CascadeClassifier('D:\\Opencv\\opencv\\build\\etc\\haarcascades\\haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier('D:\\Opencv\\opencv\\build\\etc\\haarcascades\\haarcascade_eye.xml')
mouth_cascade = cv2.CascadeClassifier('D:\\Opencv\\opencv\\build\\etc\\haarcascades\\haarcascade_mcs_mouth.xml')
upper_body = cv2.CascadeClassifier('D:\\Opencv\\opencv\\build\\etc\\haarcascades\\haarcascade_upperbody.xml')
# Adjust threshold value in range 80 to 105 based on your light.
bw_threshold = 80
# User message
font = cv2.FONT_HERSHEY_SIMPLEX
org = (30, 30)
weared_mask_font_color = (255, 255, 255)
not_weared_mask_font_color = (0, 0, 255)
thickness = 2
font_scale = 1
weared_mask = "WITH MASK"
not_weared_mask = "WITHOUT MASK"
# Read video
cap = cv2.VideoCapture(0)
while 1:
# Get individual frame
ret, img = cap.read()
img = cv2.flip(img, 1)
# Convert Image into gray
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Convert image in black and white
(thresh, black_and_white) = cv2.threshold(gray, bw_threshold, 255, cv2.THRESH_BINARY)
# cv2.imshow('black_and_white', black_and_white)
# detect face
faces = face_cascade.detectMultiScale(gray, 1.1, 4)
# Face prediction for black and white
faces_bw = face_cascade.detectMultiScale(black_and_white, 1.1, 4)
if (len(faces) == 0 and len(faces_bw) == 0):
cv2.putText(img, "No face found...", org, font, font_scale, weared_mask_font_color, thickness, cv2.LINE_AA)
elif (len(faces) == 0 and len(faces_bw) == 1):
# It has been observed that for white mask covering mouth, with gray image face prediction is not happening
cv2.putText(img, weared_mask, org, font, font_scale, weared_mask_font_color, thickness, cv2.LINE_AA)
else:
# Draw rectangle on gace
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 255, 255), 2)
roi_gray = gray[y:y + h, x:x + w]
roi_color = img[y:y + h, x:x + w]
# Detect lips counters
mouth_rects = mouth_cascade.detectMultiScale(gray, 1.5, 5)
# Face detected but Lips not detected which means person is wearing mask
if (len(mouth_rects) == 0):
cv2.putText(img, weared_mask, org, font, font_scale, weared_mask_font_color, thickness, cv2.LINE_AA)
else:
for (mx, my, mw, mh) in mouth_rects:
if (y < my < y + h):
# Face and Lips are detected but lips coordinates are within face cordinates which `means lips prediction is true and
# person is not waring mask
cv2.putText(img, not_weared_mask, org, font, font_scale, not_weared_mask_font_color, thickness,
cv2.LINE_AA)
# cv2.rectangle(img, (mx, my), (mx + mh, my + mw), (0, 0, 255), 3)
break
# Show frame with results
cv2.imshow('Mask Detection', img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
# Release video
cap.release()
cv2.destroyAllWindows()
实现方法二:Python+opencv训练分类器实现人脸口罩检测https://blog.csdn.net/weixin_45137708/article/details/107098266?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-5-107098266-blog-126190589.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-5-107098266-blog-126190589.pc_relevant_default&utm_relevant_index=6实现方法三:yolov5训练目标检测模型实现人脸口罩识别https://www.bilibili.com/video/BV1f44y187Xg/?spm_id_from=333.999.0.0&vd_source=af02455c8d46c6b121c1429f18b87829















 820
820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









