







论文名称: Generalized Robust Regression for Jointly Sparse Subspace Learning
(用于联合稀疏子空间学习的广义鲁棒回归)
一.背景引入
1.岭回归(RR)是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘法(LSR),通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数,使结果更为符合实际、更可靠的回归方法。
优化方程:
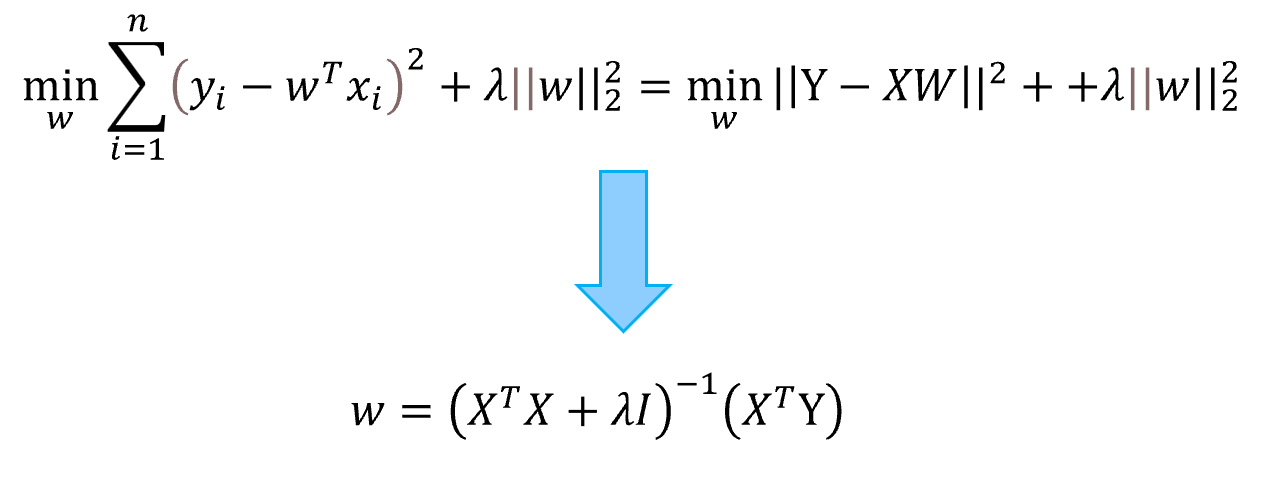
优点:加入L2范数促进了向量趋向较小的值从而实现参数的平滑化和降低过拟合风险;
岭回归在多变量数据分析中有着广泛的应用。然而,在图像特征提取和识别等非常高维的情况下,传统的岭回归或其扩展存在小类问题,即岭回归得到的投影个数受限于类的个数。
小类问题的出现使得可能无法充分利用高维特征的信息,导致特征提取和识别的性能下降。
(小类问题:提取得到特征维数受限于y的rank)
2.经典PCA解决了特征分解问题,获得用于降维的最优向量;
LDA利用标签信息来学习一个最优的投影矩阵(最大化类间距离,还可以最小化特征空间中的类内距离,从而提高模式识别的性能);
缺点1:只考虑了数据集的全局结构而忽略了局部的几何信息,而局部性在降维或特征选择中至关重要;
缺点2:作为基于L2范数的方法,传统的PCA和LDA对离群点敏感,因为L2范数中的平方残差会导致在计算投影矩阵时过度强调噪声和离群点的不良倾向;
缺点3:对于LDA或基于LDA的方法,投影的数量受到类间散度矩阵(即小样本量( SSS ))问题的限制。这种限制会降低特征提取和分类的性能;
在上述问题背景下,我们希望解决一下4个问题:
(1)小类问题 (2)对噪声点的鲁棒性 (3)局部几何结构 (4)学习到的投影稀疏性
针对上述问题文章提出了一种新的联合稀疏子空间学习方法 - - 广义鲁棒回归(GRR)
二.算法介绍

其中d为特征维数,n为样本数量,c为类别数量,k为目标获取投影数量
分片进行分析:

前一部分一部分优化函数类似LPP(局部保持投影)的优化函数,目的也是保持数据的局部几何结构(即高维中相近的两点在低维中也保持相近),后一部分对投影矩阵采用2,1范数,目的是为了使获得的特征是联合稀疏的,同时增强对噪声点的鲁棒性。
特别重要的是我们将原本的投影矩阵P写成,B是目标投影矩阵,A是个正交矩阵,而B矩阵的大小为d × k,k可以设置为任意整数,以获得足够的投影来进行人脸识别。因此,所提出的GRR中投影的个数不受类别数的限制,可以解决RR中的小类问题

![]()
前一部分是经典的最小化重构误差的优化函数,后面是对松弛变量的正则化;加入弹性因子h作为损失函数的补充项,不需要严格的弹性因子h作为损失函数的补充项,不需要严格的矩阵来拟合矩阵𝑌,从而缓解过拟合问题,矩阵
来拟合矩阵Y,从而缓解过拟合问题,保证特征选择或提取具有较强的泛化能力,特别是保证特征选择或提取具有较强的泛化能力,特别是在图像被块相减或噪声破坏的情况在图像被块相减或噪声破坏的情况。
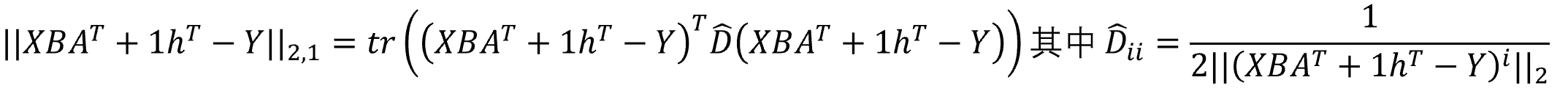
因此,总的优化方程我们可以化成:
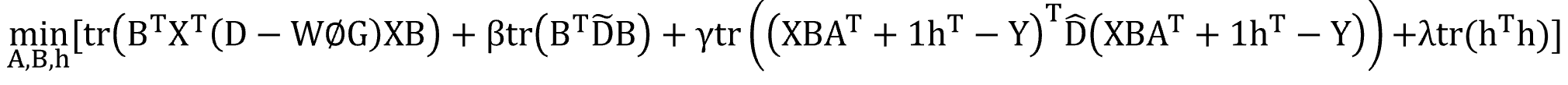
固定A,B,令上式对h求偏导为0可得:
![]()
固定A,h,令上式对B求偏导为0可得:
![]()
而对于A,我们找出所有关于A的部分如下:
![]()
最终我们将求解A的问题转化为下述问题:
![]()
这也是我们很常见的求解问题,利用论文中所给定理:

我们可以对右边部分进行奇异值分解:
![]()
得到
至此我们可以归纳出GRR算法的全部算法流程:

Ps:实验部分由于篇幅有限,可自行查看论文。
三.算法总结
GRR算法是个很综合的算法,在ORL、Yale和AR数据集上的识别率高于目前最好的识别率,在其他数据集上也具有竞争力。这表明GRR是一种有效的特征提取和分类方法。
GRR算法优点:
1.在RR、LPP和L2,1范数最小化的基础上融合了多个鲁棒因子和局部性;
2.GRR可以学习任意数量的投影,保持较高且稳定的识别率;
3.不仅在损失函数和正则化项上都使用了L2,1范数,而且还考虑了局部几何结构,有利于应对姿态和人脸表情发生变化;
4.损失函数上的弹性因子h能够降低块减法、噪声或伪装带来的负面影响;
5.使用L2,1范数在提取特征阶段执行联合稀疏特征选择;
但我个人做实验下来,发现GRR总的有以下两点不足:
1.算法复杂度高,迭代算法需要时间较长;
2.参数不好确认,需要不断优化比较来确定
重中之重--个人对GRR的几何物理意义的理解:
在最小重构误差条件下,最大程度拟合原始数据,获得联合稀疏的、具有正交性、松弛的特征,同时保持数据的局部几何结构,且具有较好的鲁棒性和泛化能力。
--本人对机器学习学习完半程左右或以上的同学比较推荐来理解这一篇论文,可以综合自己的多方面知识和理解更进一步。当然有需要代码的可以私我,有问题欢迎评论区交流!!!















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









