






用pytorch框架,把文件夹中的png图片进行读取,并分成比例为8:2的训练集和测试集
以下是文件夹的形式,图片是已经被分类放入不同的文件里了
接下来就对文件图片进行划分训练集和测试集
1.导入包
import torch
from torch.utils.data import Dataset, DataLoader, random_split
from torchvision import transforms # 图像预处理包
from PIL import Image # 读取图片
import os # 打开文件夹,获取所有图片的地址2.定义函数读取文件夹中的图片
class Mydata(Dataset): # 继承Dataset类
def __init__(self, root_dir, transform=None): # 类的实例化,主函数创建实例对象时,自动调用该函数,主要作为外部信息传入类中私有方法的接口
self.transform = transform
self.datalist = []
self.root_dir = root_dir # 获取文件夹的路径/目录地址
# 获取每一个分类文件的名字
self.label_dir_zero = '0'
self.label_dir_one = '1'
self.label_dir_two = '2'
self.label_dir_three = '3'
self.label_dir_four = '4'
self.label_dir_five = '5'
self.label_dir_six = '6'
self.label_dir_seven = '7'
self.label_dir_eight = '8'
self.label_dir_nine = '9'
# 将两个路径拼接起来(包含所有图片的路径 + 每一个分类文件夹的名字)
self.path_zero = os.path.join(self.root_dir, self.label_dir_zero)
self.path_one = os.path.join(self.root_dir, self.label_dir_one)
self.path_two = os.path.join(self.root_dir, self.label_dir_two)
self.path_three = os.path.join(self.root_dir, self.label_dir_three)
self.path_four = os.path.join(self.root_dir, self.label_dir_four)
self.path_five = os.path.join(self.root_dir, self.label_dir_five)
self.path_six = os.path.join(self.root_dir, self.label_dir_six)
self.path_seven = os.path.join(self.root_dir, self.label_dir_seven)
self.path_eight = os.path.join(self.root_dir, self.label_dir_eight)
self.path_nine = os.path.join(self.root_dir, self.label_dir_nine)
# 以列表的形式返回指定目录self.path_zero下的图片名
self.img_path_zero = os.listdir(self.path_zero)
# 遍历‘0’文件下包含所有图片名的列表
for j in range(len(self.img_path_zero)):
# 得到每一个图片名
img_name = self.img_path_zero[j]
# 包含所有图片的路径 + 每一个分类文件夹的名字 + 图片名 = 每一张图片的路径
img_zero_path = os.path.join(self.root_dir, self.label_dir_zero, img_name)
# 将元组(label, dir)添加到列表里
self.datalist.append(('0', img_zero_path))
self.img_path_one = os.listdir(self.path_one)
for j in range(len(self.img_path_one)):
img_name = self.img_path_one[j]
img_one_path = os.path.join(self.root_dir, self.label_dir_one, img_name)
self.datalist.append(('1', img_one_path))
self.img_path_two = os.listdir(self.path_two)
for j in range(len(self.img_path_two)):
img_name = self.img_path_two[j]
img_two_path = os.path.join(self.root_dir, self.label_dir_two, img_name)
self.datalist.append(('2', img_two_path))
self.img_path_three = os.listdir(self.path_three)
for j in range(len(self.img_path_three)):
img_name = self.img_path_three[j]
img_three_path = os.path.join(self.root_dir, self.label_dir_three, img_name)
self.datalist.append(('3', img_three_path))
self.img_path_four = os.listdir(self.path_four)
for j in range(len(self.img_path_four)):
img_name = self.img_path_four[j]
img_four_path = os.path.join(self.root_dir, self.label_dir_four, img_name)
self.datalist.append(('4', img_four_path))
self.img_path_five = os.listdir(self.path_five)
for j in range(len(self.img_path_five)):
img_name = self.img_path_five[j]
img_five_path = os.path.join(self.root_dir, self.label_dir_five, img_name)
self.datalist.append(('5', img_five_path))
self.img_path_six = os.listdir(self.path_six)
for j in range(len(self.img_path_six)):
img_name = self.img_path_six[j]
img_six_path = os.path.join(self.root_dir, self.label_dir_six, img_name)
self.datalist.append(('6', img_six_path))
self.img_path_seven = os.listdir(self.path_seven)
for j in range(len(self.img_path_seven)):
img_name = self.img_path_seven[j]
img_seven_path = os.path.join(self.root_dir, self.label_dir_seven, img_name)
self.datalist.append(('7', img_seven_path))
self.img_path_eight = os.listdir(self.path_eight)
for j in range(len(self.img_path_eight)):
img_name = self.img_path_eight[j]
img_eight_path = os.path.join(self.root_dir, self.label_dir_eight, img_name)
self.datalist.append(('8', img_eight_path))
self.img_path_nine = os.listdir(self.path_nine)
for j in range(len(self.img_path_nine)):
img_name = self.img_path_nine[j]
img_nine_path = os.path.join(self.root_dir, self.label_dir_nine, img_name)
self.datalist.append(('9', img_nine_path))
print(len(self.datalist)) # 68992
# 从中获取20000张图片
self.new_dataset = []
for m in self.datalist[:10000]:
# print(type(m)) # <class 'tuple'>
label, img_path = m
img = Image.open(img_path)
if img.mode != 'L':
self.datalist.remove(m)
else:
self.new_dataset.append(m)
for n in self.datalist[-10001: -1]:
label, img_path = n
img = Image.open(img_path)
if img.mode != 'L':
self.datalist.remove(n)
else:
self.new_dataset.append(n)
def __getitem__(self, item): # 实例化__getitem__方法,item表示索引,返回的图像必须是tensor
label, img_path = self.new_dataset[item] # 列表中索引为item的值,分别赋值给 label,img_path
img = Image.open(img_path) # 打开图片,将图片信息赋值给img
if self.transform != None:
img = self.transform(img) # 对图片进行预处理
# 创建tensor张量
labels = {'0': torch.tensor(0),
'1': torch.tensor(1),
'2': torch.tensor(2),
'3': torch.tensor(3),
'4': torch.tensor(4),
'5': torch.tensor(5),
'6': torch.tensor(6),
'7': torch.tensor(7),
'8': torch.tensor(8),
'9': torch.tensor(9)}
label = labels[label]
return img, label
def __len__(self):
return len(self.new_dataset) # 返回列表的长度
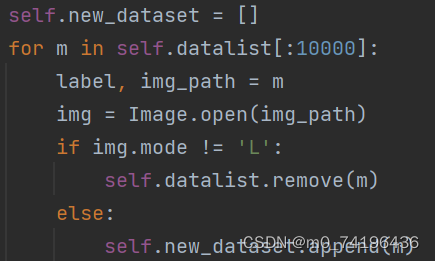
注意:if img.mode != 'L' 这一句代码在写的时候要注意,我这里是png图片,如果是其他后缀的图片(JPG等),要把'L'换了,否则会出现以下错误:mydataset中的长度为0,也就是其判断全为假,无法添加图片到new_dataset中
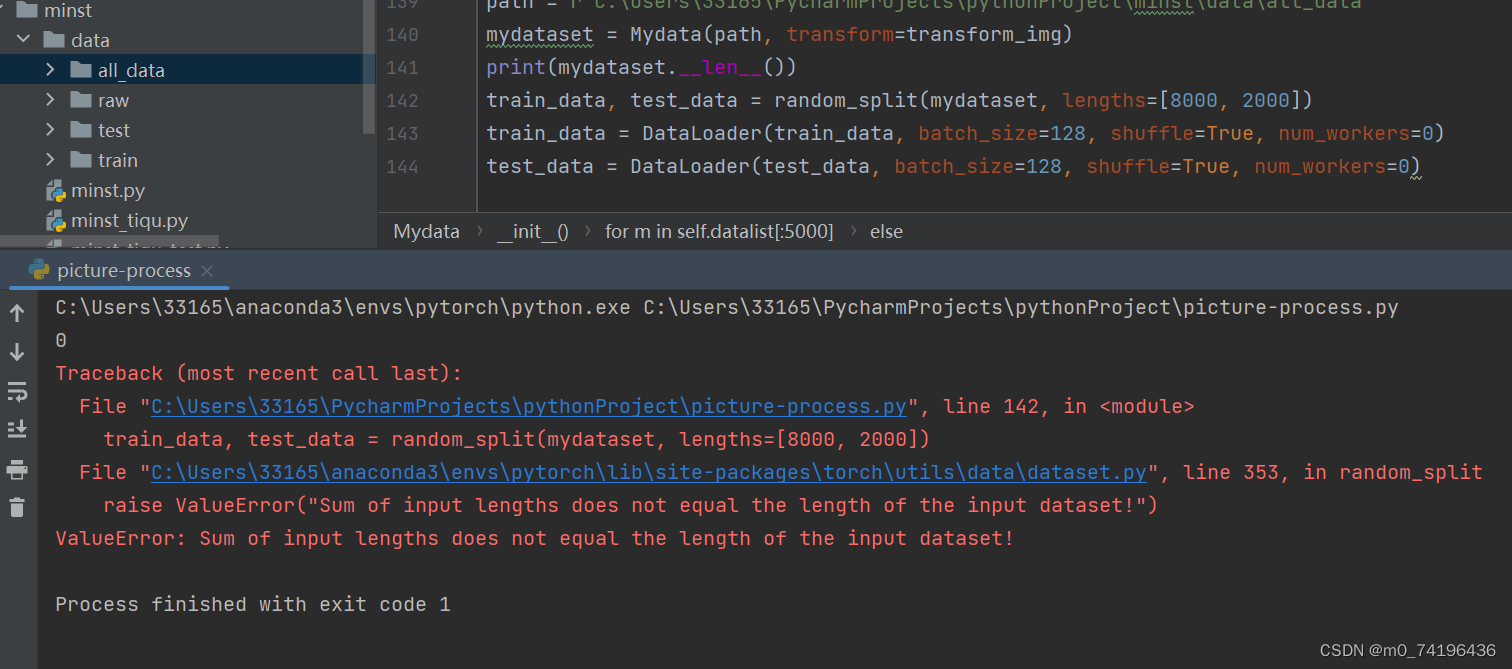
那么,如何判断‘L’应改成什么呢?
通过debug ,将上示代码打上小红点,debug的过程中会看到蓝色那一行,在28x28的前面有 mode=L,其他类型的图片可以通过这个方法进行判断,这样其他已经分类的图片文件也可以
用相同的方法处理啦

3.对图片进行处理(transform)
transform_img = transforms.Compose([
transforms.Resize([28, 28]), # 将图片短边缩放至28,长宽比保持不变:
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型(即:把灰度范围从0-255换成0-1之间)
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 把转换为tensor类型后的0-1再次转换为 -1~1
])4.导入文件夹并进行划分
path = r'C:\Users\33165\PycharmProjects\pythonProject\minst\data\all_data'
mydataset = Mydata(path, transform=transform_img)
print(mydataset.__len__()) # 20000
train_data, test_data = random_split(mydataset, lengths=[16000, 4000]) # 划分数据集8:25.对训练集和测试集进行封装
# 将train_data,test_data分成batch_size大小为一批,进行shuffle(打乱),最后封装
train_data = DataLoader(train_data, batch_size=128, shuffle=True, num_workers=0)
test_data = DataLoader(test_data, batch_size=128, shuffle=True, num_workers=0)完整代码:
import torch
from torch.utils.data import Dataset, DataLoader, random_split
from torchvision import transforms # 图像预处理包
from PIL import Image # 读取图片
import os # 打开文件夹,获取所有图片的地址
# 数据处理
class Mydata(Dataset): # 继承Dataset类
def __init__(self, root_dir, transform=None): # 类的实例化,主函数创建实例对象时,自动调用该函数,主要作为外部信息传入类中私有方法的接口
self.transform = transform
self.datalist = []
self.root_dir = root_dir # 获取文件夹的路径/目录地址
# 获取每一个分类文件的名字
self.label_dir_zero = '0'
self.label_dir_one = '1'
self.label_dir_two = '2'
self.label_dir_three = '3'
self.label_dir_four = '4'
self.label_dir_five = '5'
self.label_dir_six = '6'
self.label_dir_seven = '7'
self.label_dir_eight = '8'
self.label_dir_nine = '9'
# 将两个路径拼接起来(包含所有图片的路径 + 每一个分类文件夹的名字)
self.path_zero = os.path.join(self.root_dir, self.label_dir_zero)
self.path_one = os.path.join(self.root_dir, self.label_dir_one)
self.path_two = os.path.join(self.root_dir, self.label_dir_two)
self.path_three = os.path.join(self.root_dir, self.label_dir_three)
self.path_four = os.path.join(self.root_dir, self.label_dir_four)
self.path_five = os.path.join(self.root_dir, self.label_dir_five)
self.path_six = os.path.join(self.root_dir, self.label_dir_six)
self.path_seven = os.path.join(self.root_dir, self.label_dir_seven)
self.path_eight = os.path.join(self.root_dir, self.label_dir_eight)
self.path_nine = os.path.join(self.root_dir, self.label_dir_nine)
# 以列表的形式返回指定目录self.path_zero下的图片名
self.img_path_zero = os.listdir(self.path_zero)
# 遍历‘0’文件下包含所有图片名的列表
for j in range(len(self.img_path_zero)):
# 得到每一个图片名
img_name = self.img_path_zero[j]
# 包含所有图片的路径 + 每一个分类文件夹的名字 + 图片名 = 每一张图片的路径
img_zero_path = os.path.join(self.root_dir, self.label_dir_zero, img_name)
# 将元组(label, dir)添加到列表里
self.datalist.append(('0', img_zero_path))
self.img_path_one = os.listdir(self.path_one)
for j in range(len(self.img_path_one)):
img_name = self.img_path_one[j]
img_one_path = os.path.join(self.root_dir, self.label_dir_one, img_name)
self.datalist.append(('1', img_one_path))
self.img_path_two = os.listdir(self.path_two)
for j in range(len(self.img_path_two)):
img_name = self.img_path_two[j]
img_two_path = os.path.join(self.root_dir, self.label_dir_two, img_name)
self.datalist.append(('2', img_two_path))
self.img_path_three = os.listdir(self.path_three)
for j in range(len(self.img_path_three)):
img_name = self.img_path_three[j]
img_three_path = os.path.join(self.root_dir, self.label_dir_three, img_name)
self.datalist.append(('3', img_three_path))
self.img_path_four = os.listdir(self.path_four)
for j in range(len(self.img_path_four)):
img_name = self.img_path_four[j]
img_four_path = os.path.join(self.root_dir, self.label_dir_four, img_name)
self.datalist.append(('4', img_four_path))
self.img_path_five = os.listdir(self.path_five)
for j in range(len(self.img_path_five)):
img_name = self.img_path_five[j]
img_five_path = os.path.join(self.root_dir, self.label_dir_five, img_name)
self.datalist.append(('5', img_five_path))
self.img_path_six = os.listdir(self.path_six)
for j in range(len(self.img_path_six)):
img_name = self.img_path_six[j]
img_six_path = os.path.join(self.root_dir, self.label_dir_six, img_name)
self.datalist.append(('6', img_six_path))
self.img_path_seven = os.listdir(self.path_seven)
for j in range(len(self.img_path_seven)):
img_name = self.img_path_seven[j]
img_seven_path = os.path.join(self.root_dir, self.label_dir_seven, img_name)
self.datalist.append(('7', img_seven_path))
self.img_path_eight = os.listdir(self.path_eight)
for j in range(len(self.img_path_eight)):
img_name = self.img_path_eight[j]
img_eight_path = os.path.join(self.root_dir, self.label_dir_eight, img_name)
self.datalist.append(('8', img_eight_path))
self.img_path_nine = os.listdir(self.path_nine)
for j in range(len(self.img_path_nine)):
img_name = self.img_path_nine[j]
img_nine_path = os.path.join(self.root_dir, self.label_dir_nine, img_name)
self.datalist.append(('9', img_nine_path))
print(len(self.datalist)) # 68992
# 从中获取20000张图片
self.new_dataset = []
for m in self.datalist[:10000]:
# print(type(m)) # <class 'tuple'>
label, img_path = m
img = Image.open(img_path)
if img.mode != 'L':
self.datalist.remove(m)
else:
self.new_dataset.append(m)
for n in self.datalist[-10001: -1]:
label, img_path = n
img = Image.open(img_path)
if img.mode != 'L':
self.datalist.remove(n)
else:
self.new_dataset.append(n)
def __getitem__(self, item): # 实例化__getitem__方法,item表示索引,返回的图像必须是tensor
label, img_path = self.new_dataset[item] # 列表中索引为item的值,分别赋值给 label,img_path
img = Image.open(img_path) # 打开图片,将图片信息赋值给img
if self.transform != None:
img = self.transform(img) # 对图片进行预处理
# 创建tensor张量
labels = {'0': torch.tensor(0),
'1': torch.tensor(1),
'2': torch.tensor(2),
'3': torch.tensor(3),
'4': torch.tensor(4),
'5': torch.tensor(5),
'6': torch.tensor(6),
'7': torch.tensor(7),
'8': torch.tensor(8),
'9': torch.tensor(9)}
label = labels[label]
return img, label
def __len__(self):
return len(self.new_dataset) # 返回列表的长度
transform_img = transforms.Compose([
transforms.Resize([28, 28]), # 将图片短边缩放至28,长宽比保持不变:
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型(即:把灰度范围从0-255换成0-1之间)
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 把转换为tensor类型后的0-1再次转换为 -1~1
])
path = r'C:\Users\33165\PycharmProjects\pythonProject\minst\data\all_data'
mydataset = Mydata(path, transform=transform_img)
print(mydataset.__len__()) # 20000
train_data, test_data = random_split(mydataset, lengths=[16000, 4000]) # 划分数据集8:2
# 将train_data,test_data分成batch_size大小为一批,进行shuffle(打乱),最后封装
train_data = DataLoader(train_data, batch_size=128, shuffle=True, num_workers=0)
test_data = DataLoader(test_data, batch_size=128, shuffle=True, num_workers=0)
















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









