







在这篇文章中,我将为大家展示如何使用Python实现一个简单的爬虫,抓取Bilibili首页的视频数据,并通过关键词分析来探索热门话题。这个项目适合初学者学习Python爬虫技术,同时掌握Selenium与BeautifulSoup的使用。
一、项目简介
本项目的目标是使用Python的Selenium库进行网页抓取,获取Bilibili首页视频的相关数据(如视频标题、作者、观看次数、发布时间等),并进行关键词统计。为了避免重复抓取,还将使用集合去重,并结合多线程加快抓取速度。抓取的数据最终用于词频统计,帮助分析当前Bilibili平台上的热门话题。
二、环境配置
在开始之前,我们需要安装一些必要的库:
selenium:用于与浏览器交互,模拟用户行为。beautifulsoup4:用于解析网页内容。re和collections:用于数据处理与关键词分析。threading和concurrent.futures:用于多线程抓取,提升效率。
安装命令:
pip install selenium beautifulsoup4
三、项目步骤
1. 等待扫码登录

首先,我们需要通过Selenium模拟打开Bilibili的登录页面,并等待用户扫描二维码登录。WebDriverWait会帮助我们在页面加载完毕后继续执行后续操作。
def wait_for_login(driver):
print("请扫描二维码进行登录...")
WebDriverWait(driver, 600).until(
EC.presence_of_element_located((By.CLASS_NAME, "header-avatar-wrap")) # 登录后出现的元素
)
print("登录成功,开始获取数据...")
在wait_for_login函数中,我们等待用户登录Bilibili,直到页面上出现个人头像按钮为止。如果超时则说明登录失败。
2. 获取视频数据

登录成功后,接下来我们需要抓取Bilibili首页的视频信息。使用BeautifulSoup解析HTML页面,提取视频的标题、链接、作者、观看次数、时长和发布时间等信息。
def get_video_data(driver, seen_links):
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'html.parser')
video_cards = soup.find_all('div', class_='bili-video-card__wrap')
titles = []
for card in video_cards:
title = card.find('h3', class_='bili-video-card__info--tit')
title_text = title.get_text() if title else 'No Title'
link = card.find('a', class_='bili-video-card__image--link')
video_link = link['href'] if link else 'No Link'
# 如果视频链接已经抓取过,则跳过
if video_link in seen_links:
continue
seen_links.add(video_link) # 添加到已抓取的链接集合中
author = card.find('span', class_='bili-video-card__info--author')
author_name = author.get_text() if author else 'No Author'
views = card.find('span', class_='bili-video-card__stats--text')
views_count = views.get_text() if views else 'No Views'
duration = card.find('span', class_='bili-video-card__stats__duration')
video_duration = duration.get_text() if duration else 'No Duration'
publish_date = card.find('span', class_='bili-video-card__info--date')
publish_date_text = publish_date.get_text() if publish_date else 'No Date'
print(f"Title: {title_text}")
print(f"Link: https:{video_link}")
print(f"Author: {author_name}")
print(f"Views: {views_count}")
print(f"Duration: {video_duration}")
print(f"Publish Date: {publish_date_text}")
print('-' * 40)
titles.append(title_text)
return titles
在这里,我们使用BeautifulSoup来解析每个视频卡片的HTML,提取视频的相关信息。如果视频链接已抓取过,我们会跳过该视频,确保每个视频只被抓取一次。
3. 模拟页面滚动和去重
Bilibili首页会不断加载新的视频,因此我们需要模拟页面滚动。通过执行JavaScript代码window.scrollTo(0, document.body.scrollHeight);,我们可以将页面滚动到底部,以加载更多内容。同时,我们会记录已抓取的视频链接,避免重复抓取。
def scroll_to_bottom(driver, seen_links):
time.sleep(5) # 等待5秒钟
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(3) # 等待页面加载
return get_video_data(driver, seen_links)
4. 多线程抓取
为了提高抓取效率,我们使用了ThreadPoolExecutor来实现多线程抓取。通过多线程,我们可以并行处理多个页面的抓取任务,显著提升程序的运行速度。
from concurrent.futures import ThreadPoolExecutor
def open_browser():
chrome_path = r"C:\Users\Lenovo\AppData\Local\Google\Chrome\Application\chrome.exe"
chromedriver_path = r'C:\Users\Lenovo\.wdm\drivers\chromedriver\win64\131.0.6778.264\chromedriver-win32\chromedriver.exe'
chrome_options = Options()
chrome_options.binary_location = chrome_path
service = Service(chromedriver_path)
driver = webdriver.Chrome(service=service, options=chrome_options)
driver.get('https://passport.bilibili.com/login')
wait_for_login(driver) # 等待扫码登录
print("正在抓取首页数据...")
seen_links = set() # 用集合来存储已抓取过的链接
titles = []
# 使用 ThreadPoolExecutor 进行多线程抓取
with ThreadPoolExecutor(max_workers=5) as executor:
futures = []
for i in range(20): # 设置抓取次数为20,确保抓取更多的页面数据
futures.append(executor.submit(scroll_to_bottom, driver, seen_links))
# 获取所有线程的结果
for future in futures:
titles.extend(future.result())
# 分词和统计
all_titles_text = ' '.join(titles)
words = re.findall(r'\w+', all_titles_text.lower()) # 转换为小写并进行分词
word_counts = Counter(words)
print("\nMost common keywords:")
for word, count in word_counts.most_common(10):
print(f"{word}: {count}")
driver.quit()
在这个部分,我们使用了ThreadPoolExecutor来提交多个抓取任务,每个任务执行滚动并抓取页面数据。通过这种方式,抓取速度得到了有效提升。
5. 关键词分析
抓取到的视频标题数据后,我们进行简单的文本处理,将标题拼接成一个大的文本字符串,并使用正则表达式进行分词,最后统计每个词的出现频率。
all_titles_text = ' '.join(titles)
words = re.findall(r'\w+', all_titles_text.lower()) # 转换为小写并进行分词
word_counts = Counter(words)
print("\nMost common keywords:")
for word, count in word_counts.most_common(10):
print(f"{word}: {count}")
这段代码将显示出出现频率最高的前十个关键词,为我们提供了一个简单的热门话题分析。

其它结果(部分):
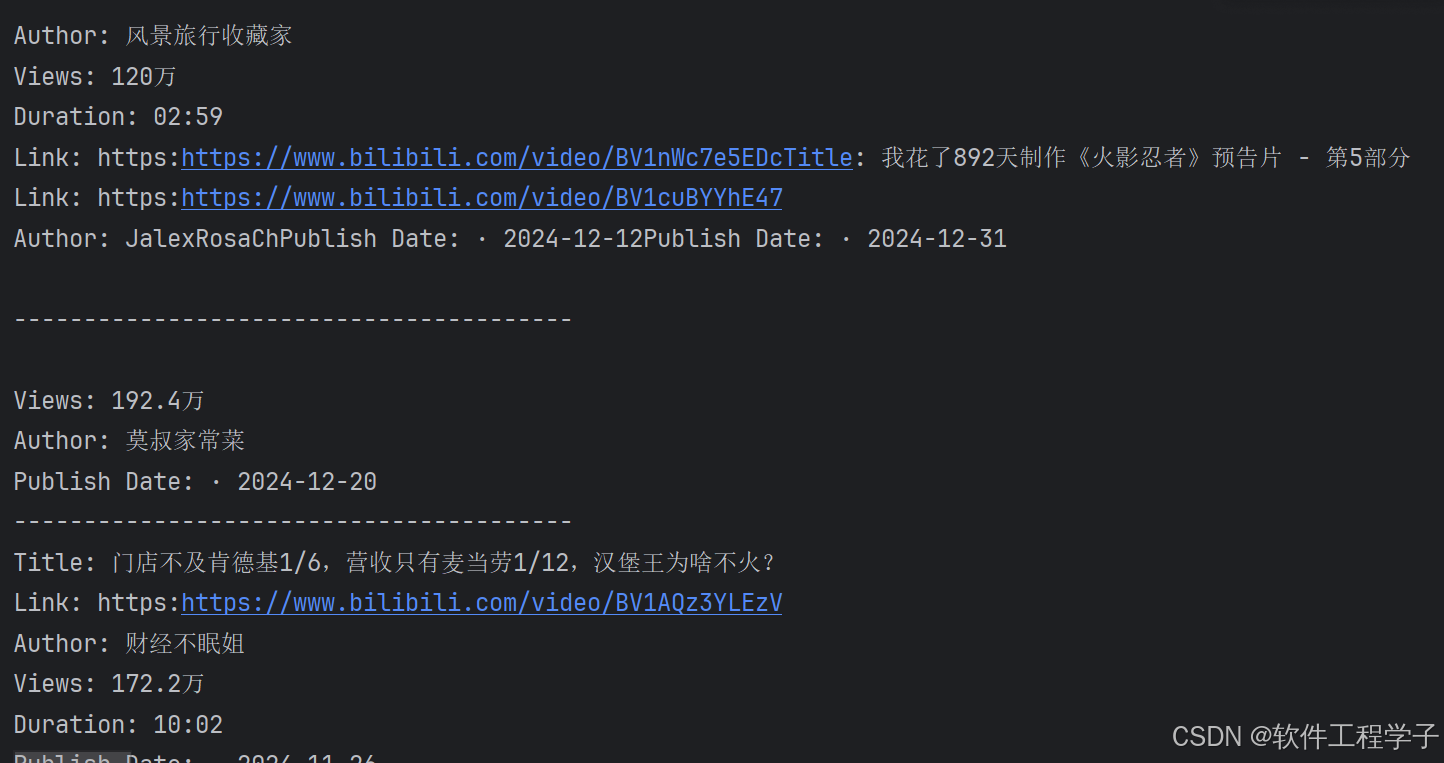
四、总结
通过这个项目,我们学习了如何用Python抓取网页数据并进行简单的文本分析。使用Selenium可以模拟用户行为,而BeautifulSoup帮助我们提取网页中的有用数据。同时,通过引入多线程技术,我们显著提高了抓取的效率。
对于初学Python的朋友,这个项目不仅帮助你掌握了爬虫技术,还能让你更好地理解如何使用Python处理实际问题。如果你想进一步提高,可以尝试优化爬虫,增加更多的功能,例如数据存储、异常处理等,进一步提升程序的健壮性和效率。
五、注意事项
- 在进行爬虫操作时,请确保遵守目标网站的
robots.txt规定,不要恶意抓取。 - 确保你的爬虫不会对网站造成过大压力,使用合理的抓取频率,避免引起反爬虫机制。
- 本项目适合用于个人学习与探索,请勿用于非法用途。

















 631
631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









