






1. 人工智能三大概念——人工智能(AI)、机器学习(ML)和深度学习(DL)
1.1 人工智能
仿智,
使用计算机来模拟或者代替人类
•
Artificial Intelligence
人工智能
•
AI is
the field
that studies the synthesis and analysis of
computational agents that act intelligently
•
AI is to use computers to
analog and instead of human brain
1.2 机器学习
机器自动学习,不是人为规则编程
•
Machine Learning
机器学习
•
Field of study that gives computers
the ability to learn without
being explicitly programmed

1.3 深度学习
•
深度学习
(DL, Deep Learning)
:
,也叫深度神经网络,
大脑仿生
,设计一层一层的神经元模拟万事万物
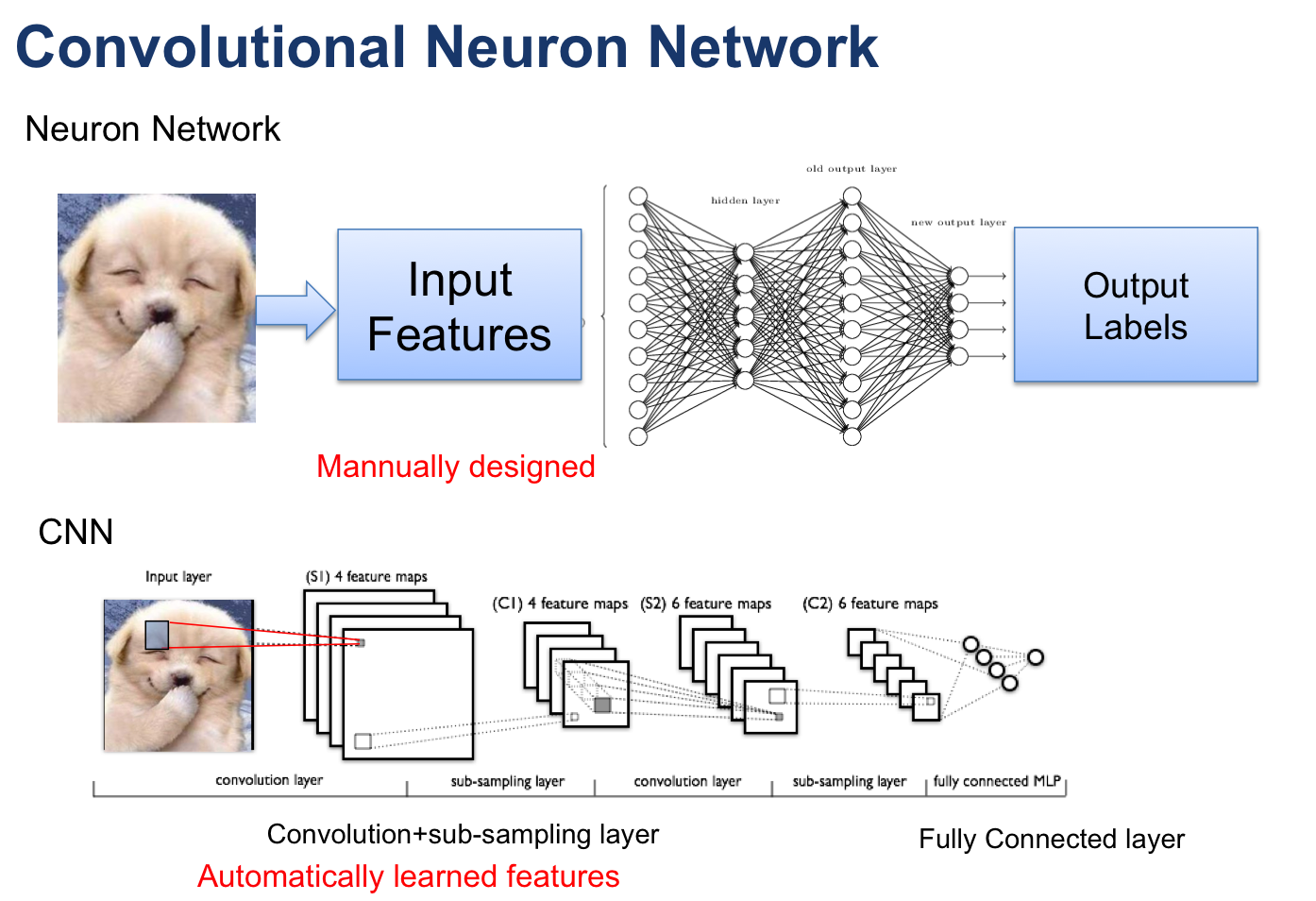
1.4 三者之间的关系
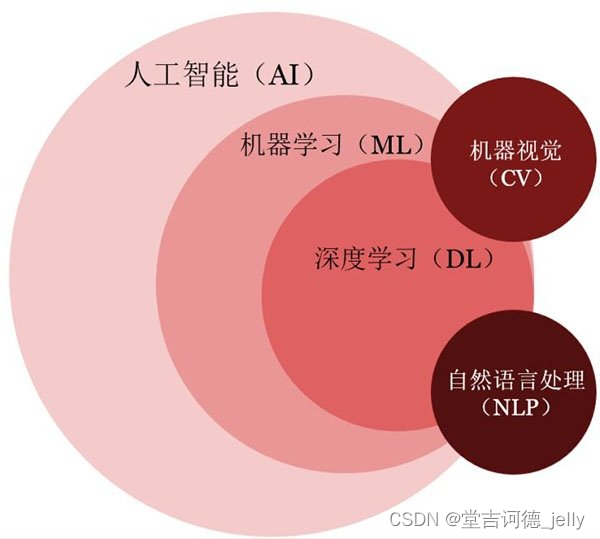
机器学习是
实现人工智能的一种途径
深度学习是机器学习的
一种方法
1.5 算法的两种学习方式
•
基于规则的学习
•
基于模型的学习
2. 机器学习的应用领域和发展史
2.1 机器学习的应用领域
• 计算机视觉CV :对人看到的东西进行理解• 自然语言处理 :对人交流的东西进行理解• 数据挖掘和数据分析 :也属于人工智能的范畴图像识别和分类——人脸识别、图像检索、物体识别等。
自然语言处理——机器翻译、文本分类、语音识别等。
推荐系统——电商、社交媒体等平台中的商品推荐、内容推荐等。
医疗智能诊断-——癌症诊断、疾病预测等。
金融风控——欺诈检测、信用评估等。
工业制造——质量控制、异常检测等。
无人驾驶——视觉感知、路况识别等。
游戏智能——游戏AI、机器人足球等。
网络安全——恶意代码检测、网络攻击识别等。
环境保护——气象预测、大气污染监测等。
2.2 机器学习发展史
•
1956年
人工智能元年
•
2012
年
计算机视觉深度神经网络方法研究兴起
•
2017
年
自然语言处理应用大幕拉开
• 2022
年
chatGPT
的出现,引起
AIGC
的发展
2.3 人工智能发展三要素
数据
,
算法,算力
•
CPU
:主要适合I\O密集型的任务
•
GPU
:主要适合计算密集型任务
•
TPU
:专门针对大型网络训练而设计的一款处理器
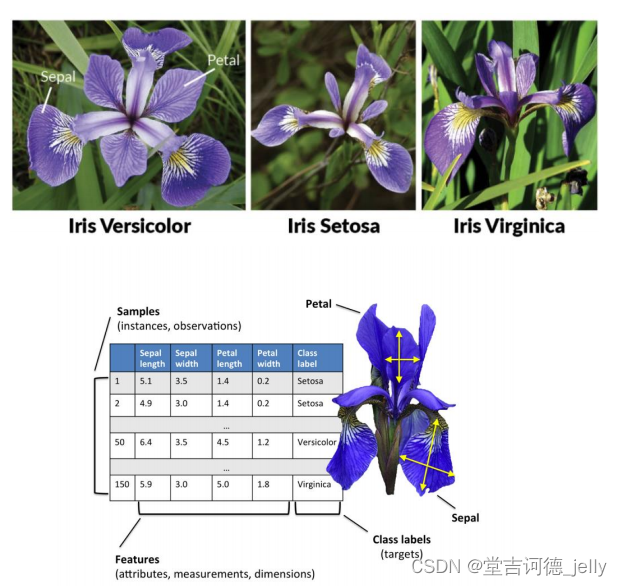
3. 机器学习常用术语——样本、特征、标签、训练集和测试集
3.1 样本,特征,标签
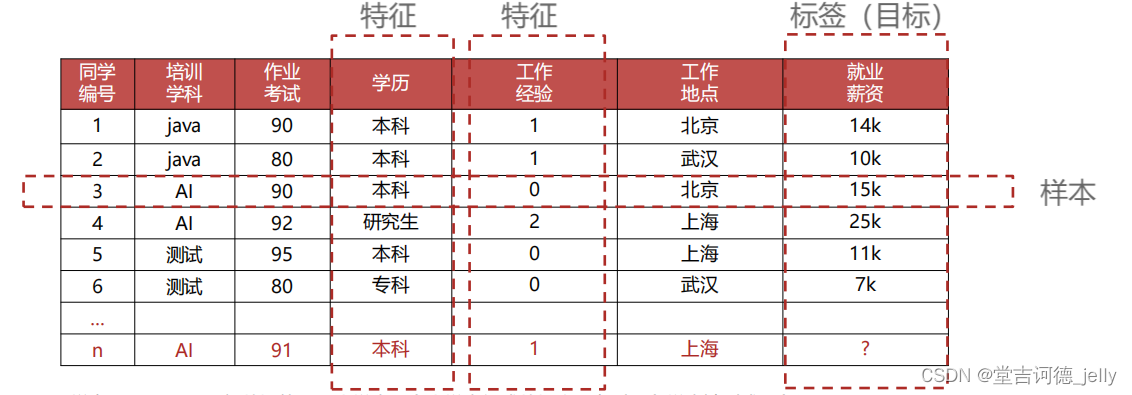
•
样本(sample)
:一行数据就是一个样本
•
特征(feature)
:一列数据一个特征,有时也被称为属性
•
标签/目标(label/target)
:模型要预测的那一列数据。
3.2 数据集划分

• 数据集dataset
:多个样本组成数据集,训练集、测试集
一般划分比例7:3 ~ 8:2
•
训练集(training set)
:用来训练模型(
model
)的数据集
•
测试集(testing set)
:用来测试模型的数据集
4. 机器学习算法分类——有监督学习、无监督学习、半监督、强化学习
4.1 有监督学习
◆
定义:输入数据是由输入特征值和目标值所组成,即 输入的
训练数据有标签的
◆
数据集:需要标注数据的标签/目标值
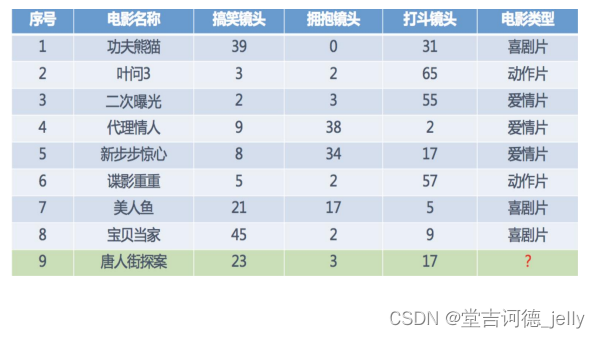
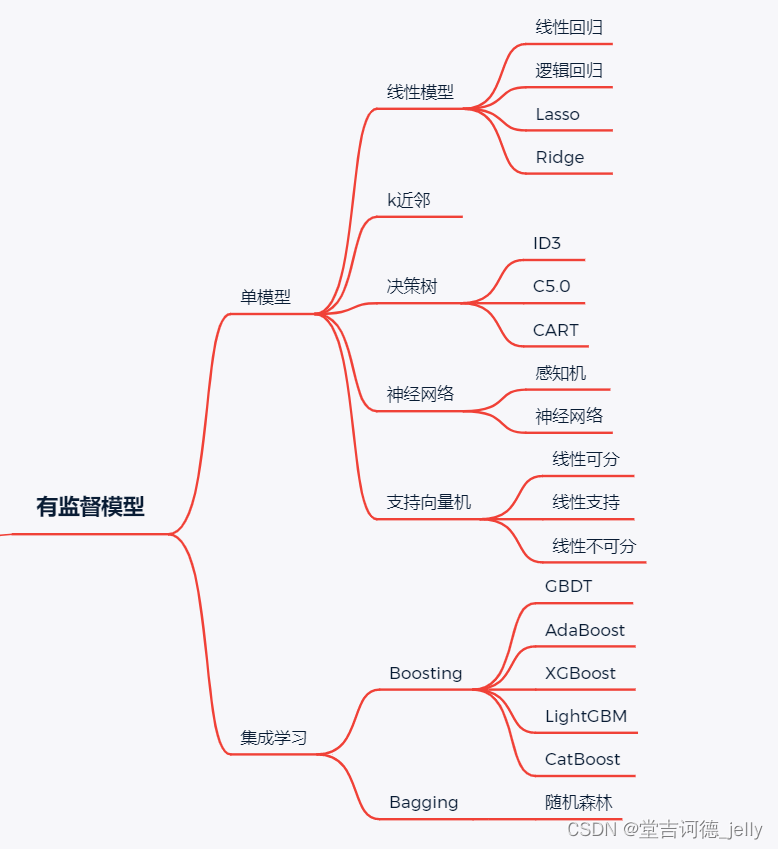
有监督学习的分类问题 & 回归问题
4.2 无监督学习
◆
定义:
输入数据没有被标记,即样本数据类别未知,
没有标签
, 根据样本间的相似性,对样本集聚类,以发现事物内部 结构及相互关系。
◆
数据集:不需要标注数据

无监
 督学习
督学习
督学习
4.3 半监督学习
工作原理:
1 让
专家标注少量数据
,利用已经标记的数据(也就 是带有类标签)训练出一个模型
2 再利用
该模型去套用未标记的数据
3 通过
询问领域专家
分类结果与模型分类结果做对比, 从而对模型做进一步改善和提高
好处:
半监督学习方式可
大幅降低标记成本
4.4 强化学习——机器学习算法分类
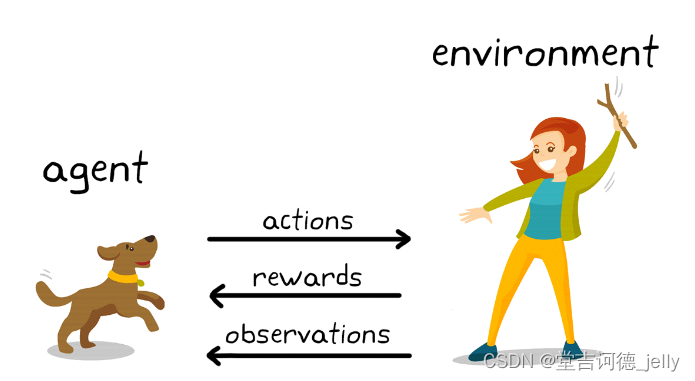
1 强化学习(Reinforcement Learning):机器学习的一个重要分支
2 应用场景:里程碑AlphaGo围棋、各类游戏、对抗比赛、无人驾驶场景
3 基本原理:通过构建四个要素:agent,环境状态,行动,奖励,
agent根据环境状态进行行动获得最多的累计奖励。
4.5 总结


5. 机器学习建模流程
5.1 机器学习建模的一般步骤
•
获取数据
:
搜集与完成机器学习任务相关的数据集
•
数据基本处理
:
数据集中异常值
,
缺失值的处理等
•
特征工程
:
对数据特征进行提取、转成向量,让模型达到最好的效果
•
机器学习
(模型训练):
选择合适的算法对模型进行训练
•
根据不同的任务来选中不同的算法;有监督学习,无监督学习,半监督学
习,强化学习
•
模型评估
:
评估效果好上线服务,评估效果不好则重复上述步骤

在整个建模流程中,数据基本处理、特征工程一般是
耗时、耗精力最多的
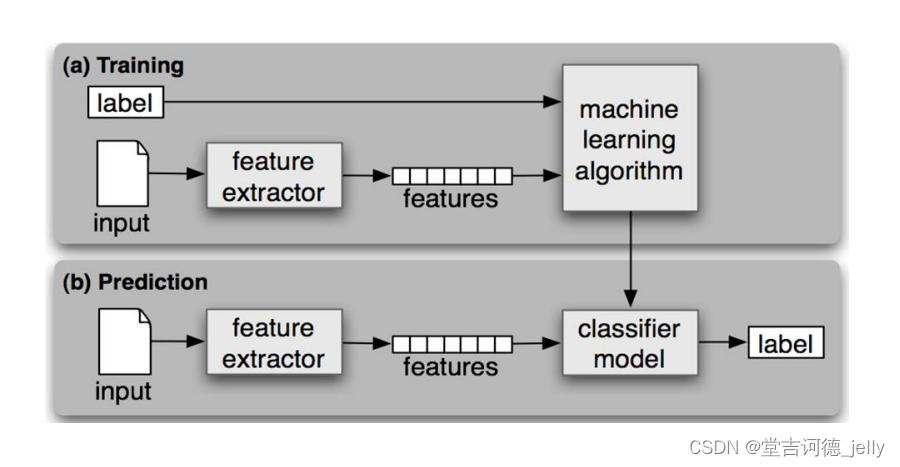
5.2 有监督学习模型训练和模型预测
6. 特征工程概念入门
6.1 特征工程概念
利用专业背景知识和技巧
处理数据
,让机器学习算法效果最好。这个过程就是特征工程
Coming up with features is difficult, time-consuming, requires expert knowledge.
“Applied machine learning” is basically feature engineering. ”
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已
6.2 涉及内容
1. 特征提取
原始数据中提取与任务相关的特征,构成特征向量
2.特征预处理
特征对模型产生影响;
因
量纲问题
,有些特征对模型影响大、有些影响小
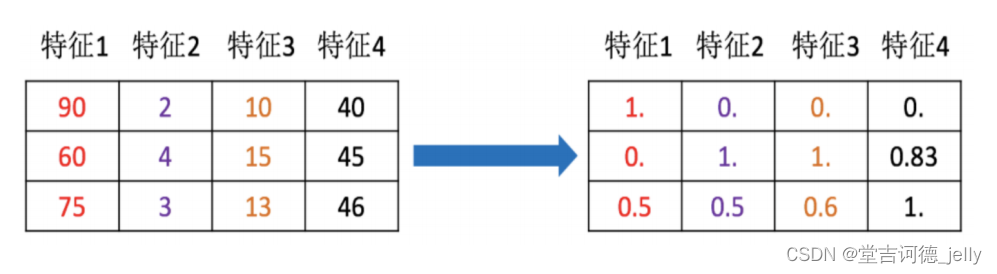
一般是做数据的标准化、归一化等工作
3.特征降维
将原始数据的维度降低,叫做特征降维,
一般会对原始数据产生影响
4.特征选择
原始数据特征很多,与任务相关是其中一个特征集合子集,
不会改变原数据
5.特征组合
把多个的特征合并成一个特征。利用乘法或加法来完成
7. 模型拟合问题
7.1 过拟合欠拟合
• 拟合:用来表示模型对样本分布点的模拟情况
•过拟合: 模型在训练集上表现很好、在测试集表现很差
•
欠拟合:
模型在训练集上表现
很差
、
在测试集表现也
很差
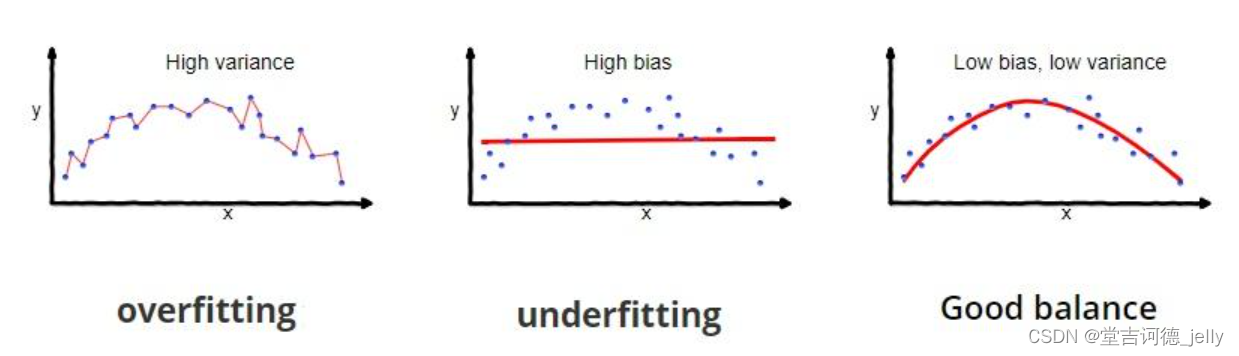
7.2过拟合欠拟合产生的原因
• 欠拟合产生的原因:
模型过于简单
•
过拟合产生的原因:
模型太过于复杂、数据不纯、训练数据太少
7.3 泛化
• 泛化 Generalization :具体的、个别的扩大为一般的能力
•
奥卡姆剃刀原则:
给定两个具有相同泛化误差的模型,倾向选择较简单的模
型
8. 机器学习开发环境
基于
Python
的
scikit-learn
库
1.
简单高效的数据挖掘和数据分析工具
2.
可供大家使用,可在各种环境中重复使用
3.
建立在
NumPy
,
SciPy
和
matplotlib
上
4.
开源,可商业使用
-
获取
BSD
许可证
安装方法:
pip install scikit-learn
官网:
https://scikit-learn.org/stable/















 152
152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









