






 本文详细介绍了KNN算法的工作原理,包括解决分类和回归问题的处理流程,常用的距离度量方法如欧氏、曼哈顿、切比雪夫和闵可夫斯基距离,以及特征预处理中的归一化和标准化。此外,通过鸢尾花数据集展示了KNN算法的应用,包括数据集划分、模型训练和评估,以及超参数调优的方法,如交叉验证和网格搜索。
本文详细介绍了KNN算法的工作原理,包括解决分类和回归问题的处理流程,常用的距离度量方法如欧氏、曼哈顿、切比雪夫和闵可夫斯基距离,以及特征预处理中的归一化和标准化。此外,通过鸢尾花数据集展示了KNN算法的应用,包括数据集划分、模型训练和评估,以及超参数调优的方法,如交叉验证和网格搜索。
目录
1. KNN算法简介
K-近邻算法(K Nearest Neighbor,简称KNN)。比如:根据你的“邻居”来推断出你的类别
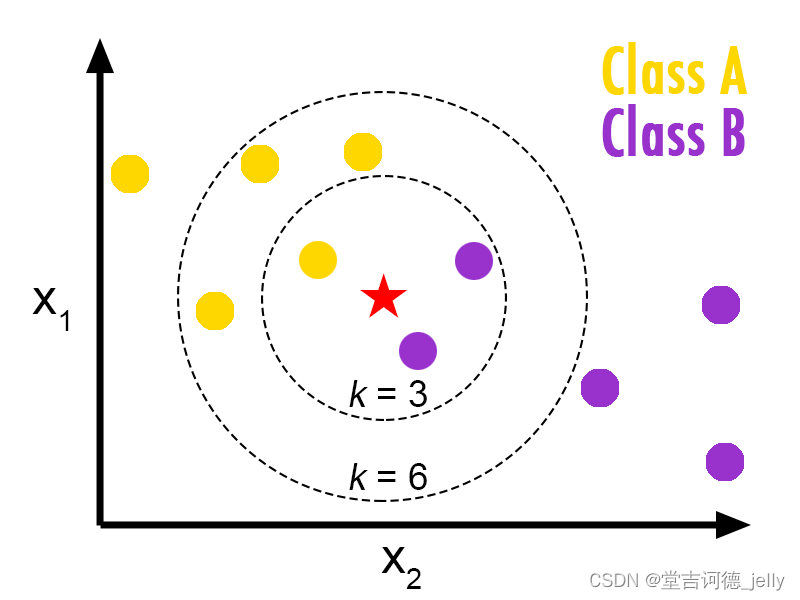
KNN算法思想:如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别
样本相似性:样本都是属于一个任务
数据集
的。样本距离
越近则越相似
。
欧氏距离

KNN算法解决问题:分类问题、回归问题
处理流程
分类问题 *标签是离散的
1.计算未知样本到每一个训练样本的距离2.将训练样本根据距离大小升序排列3.取出距离最近的 K 个训练样本4.进行 多数表决 ,统计 K 个样本中哪个类别的样本个数最多5.将未知的样本归属到 出现次数最多的类别
回归问题 *标签是连续的
1.计算未知样本到每一个训练样本的距离2.将训练样本根据距离大小升序排列3.取出距离最近的 K 个训练样本4.把这个 K 个样本的目标值 计算其平均值5.作为将未知的样本预测的值
k值选择
K
值过小:用
较小邻域中的训练实例
进行预测 容易受到
异常点
的影响
K值的减小就意味着整体模型变得复杂,容易发生
过拟
合
K
值过大:用
较大邻域中的训练实例
进行预测 受到样本均衡的问题
且K值的增大就意味着整体的
模型变得简单
,欠拟合
•
举例:
K=N
(
N
为训练样本个数)
无论输入实例是什么,只会按训练集中最多的类别进行预测
,
受到样本均衡的影响
对
K
超参数进行调优:
需要一些方法来寻找这个最合适的
K
值
交叉验证、网格搜索
2. KNN算法API介绍
KNN算法API使用 - 分类问题
•
KNN分类API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
from sklearn.neighbors import KNeighborsClassifier
def dm01_knnapi_分类():
estimator = KNeighborsClassifier(n_neighbors=1)
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
estimator.fit(X, y)
myret = estimator.predict([[4]])
print('myret-->', myret)KNN算法API使用 - 回归问题
KNN回归API:
sklearn.neighbors.KNeighborsRegressor(n_neighbors=5)
from sklearn.neighbors import KNeighborsRegressor
def dm02_knnapi_回归():
estimator = KNeighborsRegressor(n_neighbors=2)
X = [[0, 0, 1],
[1, 1, 0],
[3, 10, 10],
[4, 11, 12]]
y = [0.1, 0.2, 0.3, 0.4]
estimator.fit(X, y)
myret = estimator.predict([[3, 11, 10]])
print('myret-->', myret)3. 距离度量——常用距离计算方法
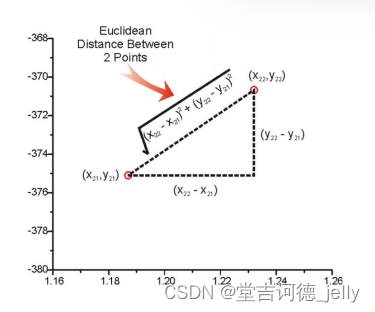
3.1 欧氏距离
欧氏距离 Euclidean Distance
直观的距离度量方法,
两个点在空间中的距离
一般都是指欧氏距离

3.2 曼哈顿距离
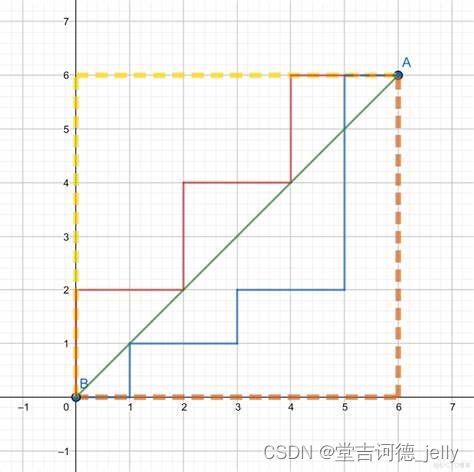
曼哈顿距离(Manhattan Distance)
也称为“
城市街区距离
”
(City Block distance)
,曼哈顿城市特点:
横平竖直

3.3 切比雪夫距离
切比雪夫距离 Chebyshev Distance
国际象棋中,国王可以
直行、横行、斜行
,所以国王走一步可以移动到相邻8个方格中的任意一个。
国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离。


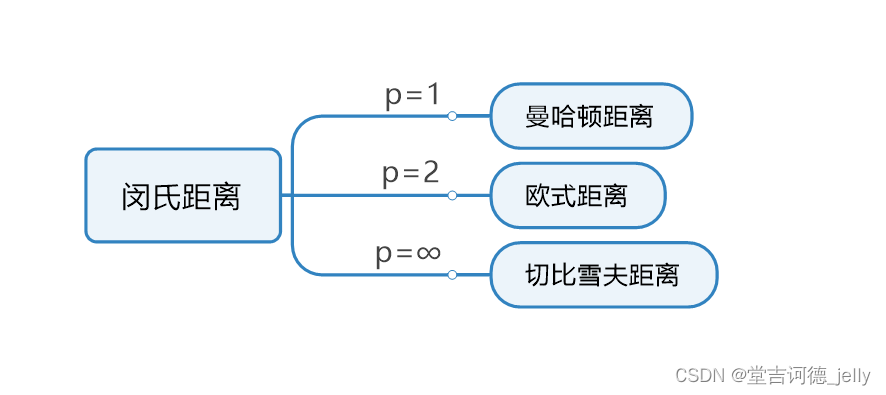
3.4 闵可夫斯基距离
闵可夫斯基距离 Minkowski Distance
闵氏距离
•
不是一种新的距离的度量方式。
•
是对多个距离度量公式的概括性的表述
两个n维变量a(x11 ,x12, …, x1n) 与 b(x21, x22,…, x2n) 间的闵可夫斯基距离定义为

4. 特征预处理
特征工程目的:把数据转换成机器更容易识别的数据
为什么做归一化和标准化 ?
特征的 单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级 , 容易影响 (支配)目标结果 ,使得一些模型(算法)无法学习到其它的特征。
4.1 归一化:
通过对原始数据进行变换
把数据映射到【mi,mx】(默认为[0,1])之间
数据归一化API:
1.sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… )
feature_range 缩放区间
2. fit_transform(X) 将特征进行归一化缩放
import numpy as np
from sklearn.preprocessing import MinMaxScaler
def dm01_MinMaxScaler():
# 1. 准备数据
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 2. 初始化归一化对象
transformer = MinMaxScaler()
# 3. 对原始特征进行变换
data = transformer.fit_transform(data)
# 4. 打印归一化后的结果
print(data)4.2标准化:
通过对原始数据进行标准化,转换为均值为0标准差为1的标准正态分布的数据
数据标准化API:
1.sklearn.preprocessing. StandardScaler()
2. fit_transform(X) 将特征进行归一化缩放
from sklearn.preprocessing import StandardScaler
def dm03_StandardScaler(): # 对特征值进行标准化
# 1. 准备数据
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 2. 初始化标准化对象
transformer = StandardScaler()
# 3. 对原始特征进行变换
data = transformer.fit_transform(data)
# 4. 打印归一化后的结果
print(data)
# 5 打印每1列数据的均值和标准差
print('transformer.mean_-->', transfer.mean_)
print('transformer.var_-->', transfer.var_)正态分布是一种概率分布,大自然很多数据符合正态分布也叫高斯分布,钟形分布。正态分布记作N(μ,σ )μ决定了其位置,其标准差σ决定了分布的幅度当μ = 0, σ = 1时的正态分布是标准正态分布• 方差 𝞼 𝟐 是在概率论和统计方差衡量一组数据时离散程度的度量其中M为均值 n为数据总数• 标准差σ是方差开根号• 正态分布的3σ法则(68-95-99.7 法则)
数据归一化
如果 出现异常点,影响了最大值和最小值 ,那么结果显然会发生改变◆ 应用场景:最大值与最小值非常容易受异常点影响,鲁棒性较差,只适合传统精确小数据场景◆ sklearn.preprocessing.MinMaxScaler(feature_range=(0,1)… )
数据标准化
如果出现异常点,由于具有一定数据量,少量的异常点对于 平均值的影响并不大◆ 应用场景:适合现代嘈杂大数据场景。(以后就是用你了)◆ sklearn.preprocessing.StandardScaler( )
案例·利用KNN算法对鸢尾花分类
也可以看这篇blog进行学习-->基于SKlearn鸢尾花数据的处理
实现流程:
1 获取数据集
2 数据基本处理
3 数据集预处理-数据标准化
4 机器学习(模型训练)
5 模型评估
6 模型预测

鸢尾花数据集记录了三类花以及它们的四种属性。(四种属性:花萼长度,花萼宽度,花瓣长度,花瓣宽度;3种标签:Setosa,versicolor,virginica)。
利用KNN算法对鸢尾花分类 -加载鸢尾花数据集
from sklearn.datasets import load_iris
# 加载鸢尾花数据集, 并显示属性
dataset.data .target .target_names .feature_names .DESCR
def dm01_loadiris():
# 加载数据集
mydataset = load_iris()
# 查看数据集信息
print('\n查看数据集信息-->\n', mydataset.data[:5])
# 查看目标值
print('mydataset.target-->\n', mydataset.target)
# 查看目标值名字
print('mydataset.target_names-->\n', mydataset.target_names)
# 查看特征名
print('mydataset.feature_names-->\n', mydataset.feature_names)
# 查看数据集描述
print('\nmydataset.DESCR-->\n', mydataset.DESCR)
# 数据文件路径
print('mydataset.filename-->\n', mydataset.filename)import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# 显示鸢尾花数据
def dm02_showiris():
# 1 载入鸢尾花数据集 并显示特征名称.feature_names
mydataset = load_iris()
print(mydataset.feature_names)
# 2 把数据转换成dataframe格式 设置data, columns属性 目标值名称
iris_d = pd.DataFrame(mydataset['data'], columns=mydataset.feature_names)
iris_d['Species'] = mydataset.target
print('\niris_d-->\n', iris_d)
col1 = 'sepal length (cm)'
col2 = 'petal width (cm)'
# 3 sns.lmplot()显示
sns.lmplot(x=col1, y=col2, data=iris_d, hue='Species', fit_reg=False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title('iris')
plt.show()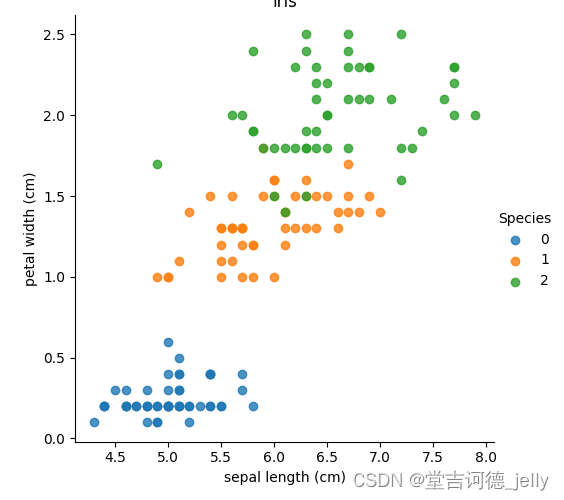
利用KNN算法对鸢尾花分类 - 数据集划分
from sklearn.model_selection import train_test_split
# 数据集划分
def dm03_traintest_split():
# 1 加载数据集
mydataset = load_iris()
# 2 划分数据集
X_train, X_test, y_train, y_test = train_test_split(mydataset.data, mydataset.target,
test_size=0.3, random_state=22)
print('数据总数量', len(mydataset.data))
print('训练集中的x-特征值', len(X_train))
print('测试集中的x-特征值', len(X_test))
print(y_train)利用KNN算法对鸢尾花分类 – 模型训练
# 导入类库
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
def dm04_模型训练和预测():
# 1 获取数据集
mydataset = load_iris()
# 2 数据基本处理
x_train, x_test, y_train, y_test = train_test_split(mydataset.data, mydataset.target, test_size=0.2,
random_state=22)
# 3 数据集预处理-数据标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
# 让测试集的均值和方法, 转换测试集数据;
x_test = transfer.transform(x_test)
# 4 机器学习(模型训练)
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 5 模型评估 直接计算准确率 100个样本中模型预测对了多少
myscore = estimator.score(x_test, y_test)
print(‘myscore-->’, myscore)
# 6 模型预测 # 需要对待预测数据,执行标准化
print('通过模型查看分类类别-->', estimator.classes_)
mydata = [[5.1, 3.5, 1.4, 0.2],
[4.6, 3.1, 1.5, 0.2]]
mydata = transfer.transform(mydata)
print('mydata-->', mydata)
mypred = estimator.predict(mydata)
print('mypred-->\n', mypred)
mypred = estimator.predict_proba(mydata)
print('mypred-->\n', mypred)利用KNN算法对鸢尾花分类 – 模型评估
# 1 获取数据集
mydataset = load_iris()
# 2 数据基本处理
x_train, x_test, y_train, y_test = train_test_split(mydataset.data, mydataset.target, test_size=0.2, random_state=22)
# 3 数据集预处理-数据标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
# 让测试集的均值和方法, 转换测试集数据;
x_test = transfer.transform(x_test)
# 4 机器学习(模型训练)
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 5-1 直接使用score函数 模型评估 100个样本中模型预测对了多少
myscore = estimator.score(x_test, y_test)
print('myscore-->', myscore)
# 5-2 利用sklearn.metrics包中的 accuracy_score 方法
y_predict = estimator.predict(x_test)
myresult = accuracy_score(y_test, y_predict)
print('myresult-->', myresult)5. 超参数选择方法
5.1 交叉验证
交叉验证是一种数据集的分割方法,将训练集划分为 n 份,拿一份做验证集 (测试集)、其他n-1份做训练集 交叉验证法,目的是为了得到更加准确可信的模型评分。
交叉验证法原理:将数据集划分为 cv=4 份
1. 第一次:把
第一份
数据做验证集,其他数据做训练
2. 第二次:把
第二份
数据做验证集,其他数据做训练
3. ... 以此类推,总共
训练4次,评估4次
。
4. 使用
训练集+验证集
多次评估模型,取
平均值
做交叉验证为模型得分
5. 若k=5模型得分最好,再使用
全部训练集
(训练集+验证集) 对k=5模型再训练
一边,
再使用测试集对k=5模型做评估
5.2 网格搜索
网格搜索是
模型调参的有力工具
。寻找最优超参数的工具。
只需要将
若干参数
传递给
网格搜索对象
,它自动帮我们完成不同超参数的组合、模型训练、模型评估, 最终
返回一组最优的超参数
。
网格搜索
+
交叉验证的
强力组合
(
模型选择和调优
)
•
交叉验证解决
模型的数据输入问题(数据集划分)
得到更可靠的模型
•
网格搜索解决
超参数的组合
•
两个组合再一起形成一个模型参数调优的解决方案
5.3利用KNN算法对鸢尾花分类 – 交叉验证网格搜索
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
def dm01_鸢尾花knn分类_交叉验证网格搜索():
# 1 获取数据集
mydataset = load_iris()
# 2 数据基本处理-划分数据集
x_train, x_test, y_train ,y_test = train_test_split(mydataset.data, mydataset.target,
test_size=0.2,random_state=22)
# 3 数据集预处理-数据标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4 机器学习(模型训练)
estimator = KNeighborsClassifier()
print('estimator-->', estimator)
# 4-2 使用校验验证网格搜索
param_grid = {'n_neighbors':[1,3,5,7]}
# 输入一个estimator, 出来一个estimator(功能变的强大)
estimator = GridSearchCV(estimator=estimator, param_grid=param_grid, cv=5)
estimator.fit(x_train, y_train) # 4个模型 每个模型进行网格搜素找到做好的模型
# 4-3 交叉验证网格搜索结果查看
# estimator.best_score_ .best_estimator_ .best_params_ .cv_results_
print('estimator.best_score_---', estimator.best_score_)
print('estimator.best_estimator_---', estimator.best_estimator_)
print('estimator.best_params_---', estimator.best_params_)
print('estimator.cv_results_---', estimator.cv_results_)
# 4-4 保存交叉验证结果
myret = pd.DataFrame(estimator.cv_results_)
myret.to_csv(path_or_buf='./mygridsearchcv.csv')
# 5 模型评估
myscore = estimator.score(x_test, y_test)
print('myscore-->', myscore)














 1377
1377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









