






1.删除表中的数据
delete from student;
2.删除表
drop takle student;
3.设置安全模式
SET SQL_SAFE_UPDATES = 0;//关闭安全模式
SET SQL_SAFE_UPDATES = 1;//打开安全模式
4.联合查询UNION 和 UNION ALL 的区别
在SQL中,`UNION`和`UNION ALL`都是用来合并两个或多个`SELECT`语句的结果集的操作符。以下是具体分析:
- **`UNION`**:当使用`UNION`时,会将多个`SELECT`语句的结果集合并起来,但会自动去除结果中的重复行。`UNION`还会对最终的结果集进行排序,以消除重复的记录。这意味着使用`UNION`可能会比`UNION ALL`慢,因为它需要额外的计算来去除重复和排序。
- **`UNION ALL`**:与`UNION`不同,`UNION ALL`会直接合并所有的结果集,包括重复的行。它不会进行去重操作,因此执行速度通常比`UNION`快,尤其是在处理大量数据时更为明显。如果查询的目的不是为了去重,或者预先知道结果集中没有重复数据,使用`UNION ALL`是一个更高效的选择。
总的来说,`UNION` 和 `UNION ALL`的主要区别在于是否去除结果集中的重复行以及是否进行排序。`UNION`会去除重复并进行排序,而`UNION ALL`则不会。选择使用哪一个取决于查询的需求和性能考虑。
1 了解数据库和表了解数据库和表
SHOW DATABASES;返回可用数据库的一个列表
SHOW TABLES;返回当前选择的数据库内可用表的列表。
DESCRIBE语句 MySQL支持用DESCRIBE作为SHOW COLUMNS FROM的一种快捷方式。换句话说,DESCRIBE customers;是
SHOW COLUMNS FROM customers;的一种快捷方式。
SHOW STATUS,用于显示广泛的服务器状态信
解决办法是使用DISTINCT关键字,顾名思义,此关键字指示MySQL
只返回不同的值。
限制结果
SELECT语句返回所有匹配的行,它们可能是指定表中的每个行。为 了返回第一行或前几行,可使用LIMIT子句
此语句使用SELECT语句检索单个列。LIMIT 5指示MySQL返回 不多于5行。此语句的输出如下所示:
MySQL 5的LIMIT语法 LIMIT 3, 4的含义是从行4开始的3行还是从行3开始的4行?如前所述,它的意思是从行3开始的4行,这容易把人搞糊涂。 由于这个原因,MySQL 5支持LIMIT的另一种替代语法。LIMIT
4 OFFSET 3意为从行3开始取4行,就像LIMIT 3, 4一样。
面试题目
1.使用ORDER BY和LIMIT的组合,能够找出一个列中最高或最低的值。 下面的例子演示如何找出最昂贵物品的值:
prod_price DESC保证行是按照由最昂贵到最便宜检索的,而LIMIT 1告诉MySQL仅返回一行
SEIECT prod_price FROM products ORDER BY prod_price DESC LIMIT 1;
1.先按照降序排列价格
2.
LIMIT 0时:返回0行
LIMIT 1时:返回1行
 LIMIT 0,1;意思是从行0开始的1行
LIMIT 0,1;意思是从行0开始的1行

LIMIT 0,1;意思是从行1开始的1行






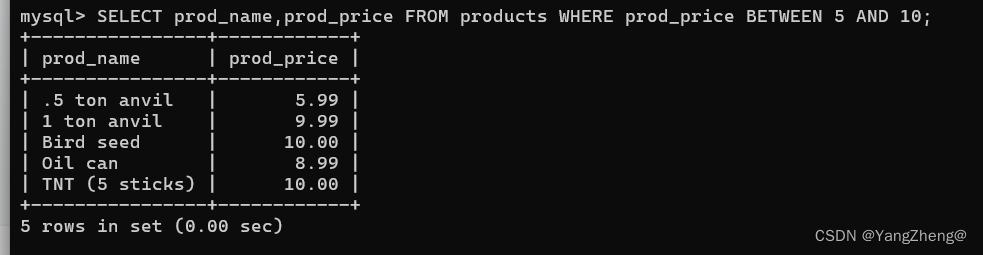
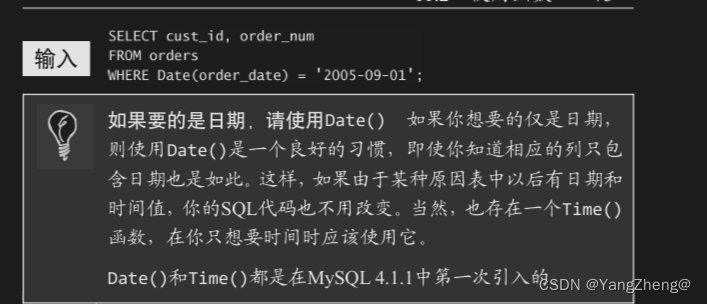
9.2 使用MySQL正则表达式
已经说过,正则表达式的作 用是匹配文本,将一个模式(正则表达式)与一个文本串进行比较
1. LOCK TABLES customers WRITE;
#LOCK TABLES 是 MySQL 中用于锁定表的语句。WRITE 表示对表进行写锁,即在执行此语句后,其他事务无法对表进行写操作,但可以读取数据。
2. ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;?
- ENGINE=InnoDB:设置存储引擎为InnoDB,InnoDB是MySQL的默认存储引擎,支持事务、行级锁定和外键等特性。
- DEFAULT CHARSET=utf8mb4:设置默认字符集为utf8mb4,可以存储更多的Unicode字符,如表情符号等。
- COLLATE=utf8mb4_0900_ai_ci:设置排序规则为utf8mb4_0900_ai_ci,这是一种不区分大小写的排序规则,同时支持AI(Accent Insensitive)排序,即对带有重音符号的字符进行排序时,会忽略重音符号的差异
3.LIKE与REGEXP 在LIKE和REGEXP之间有一个重要的差别。请 看以下两条语句:


如果执行上述两条语句,会发现第一条语句不返回数据,而第 二条语句返回一行。为什么?
正如第8章所述,LIKE匹配整个列。如果被匹配的文本在列值 中出现,LIKE将不会找到它,相应的行也不被返回(除非使用 通配符)。而REGEXP在列值内进行匹配,如果被匹配的文本在 列值中出现,REGEXP将会找到它,相应的行将被返回。这是一 个非常重要的差别。
那么,REGEXP能不能用来匹配整个列值(从而起与LIKE相同的作用)?答案是肯定的,使用^和$定位符(anchor)即可, 本章后面介绍。
4.
匹配不区分大小写 MySQL中的正则表达式匹配(自版本 3.23.4后)不区分大小写(即,大写和小写都匹配)。为区分大 小写,可使用BINARY关键字,如WHERE prod_name REGEXP BINARY 'JetPack .000'。
9.2.2 进行OR匹配 为搜索两个串之一(或者为这个串,或者为另一个串),使用|,如 下所示:
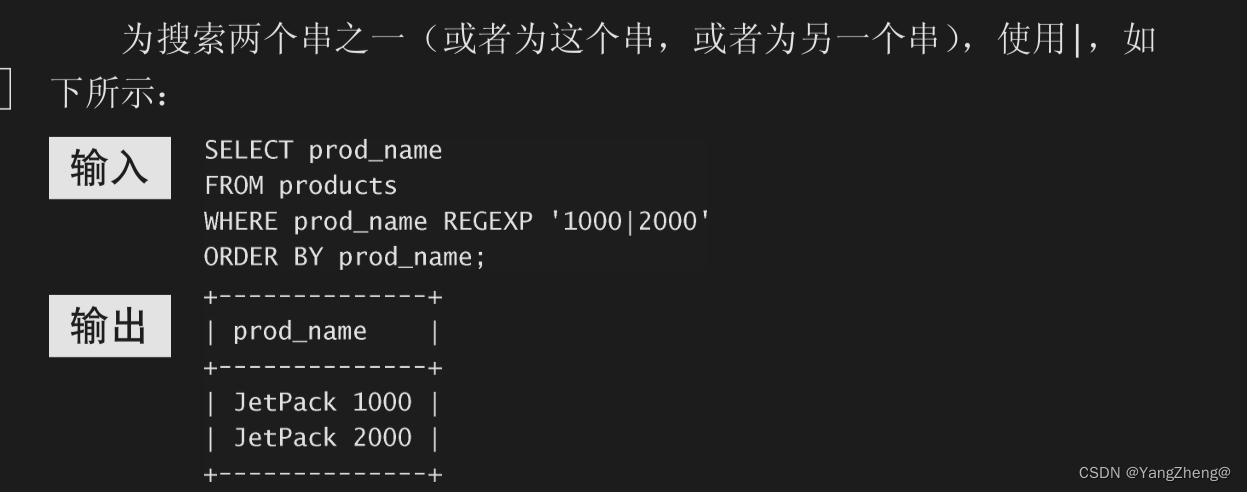
两个以上的OR条件 可以给出两个以上的OR条件。例如, '1000 | 2000 | 3000'将匹配1000或2000或3000。
9.2.3 匹配几个字符之一

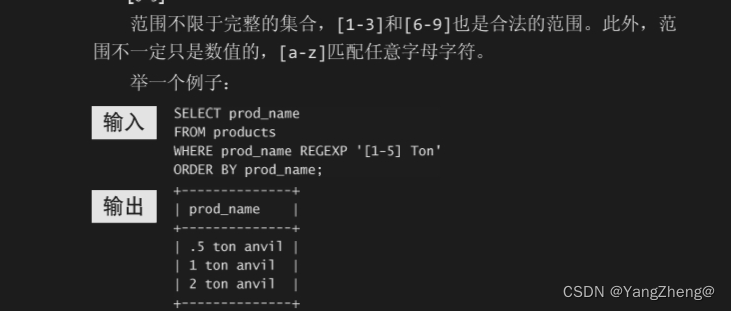
正如所见,[]是另一种形式的OR语句。事实上,正则表达式[123]Ton 为[1|2|3]Ton的缩写,也可以使用后者
9.2.4 匹配范围
9.2.5 匹配特殊字符



9.2.6 匹配字符类

9.2.7 匹配多个实例




9.2.8 定位符



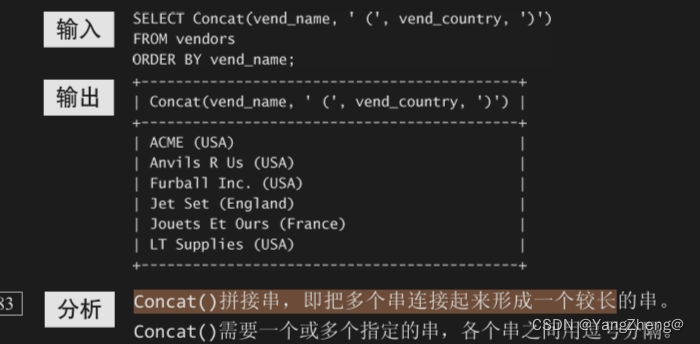
10.2 拼接字段
Concat()拼接(concatenate)
将值联结到一起构成单个值。
解决办法是把两个列拼接起来。在MySQL的SELECT语句中,可使用 Concat()函数来拼接两个列。



使用别名


10.3 执行算术计算


11.2.1 文本处理函数











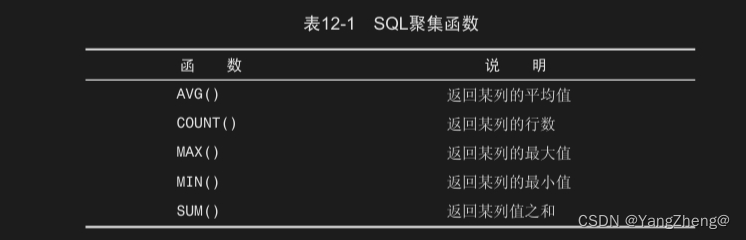




12.1.2 COUNT()函数
COUNT()函数进行计数。可利用COUNT()确定表中行的数目或符合特 定条件的行的数目。
COUNT()函数有两种使用方式。
- 使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空 值(NULL)还是非空值。
- 使用COUNT(column)对特定列中具有值的行进行计数,忽略 NULL值。



12.1.3 MAX()函数

12.1.4 MIN()函数

12.1.5 SUM()函数
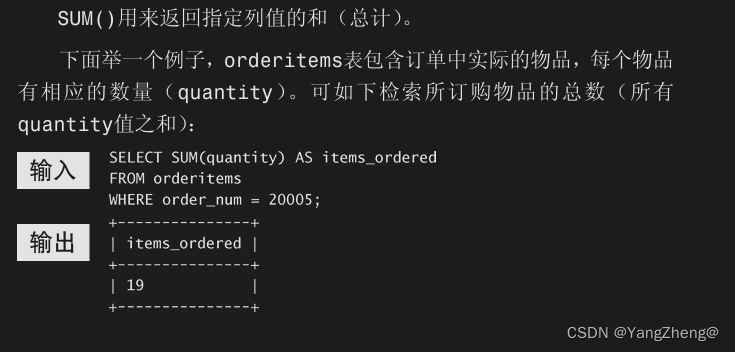
SUM()用来返回指定列值的和(总计)。


12.2 聚集不同值



12.3 组合聚集函数

 第13章 分 组 数 据
第13章 分 组 数 据
本章将介绍如何分组数据,以便能汇总表内容的子集。这涉及两个 新SELECT语句子句,分别是GROUP BY子句和HAVING子句。
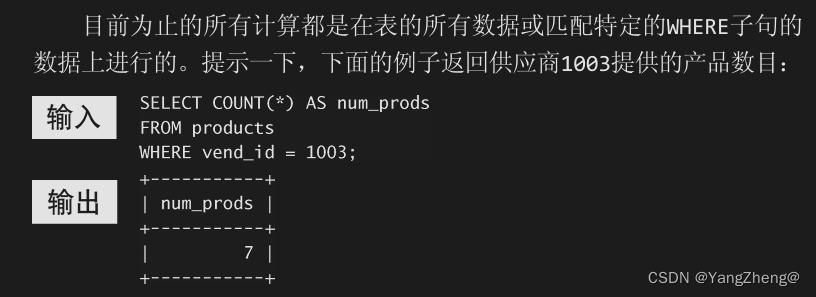
13.1 数据分组
13.2 创建分组





13.3 过滤分组






13.4 分组和排序



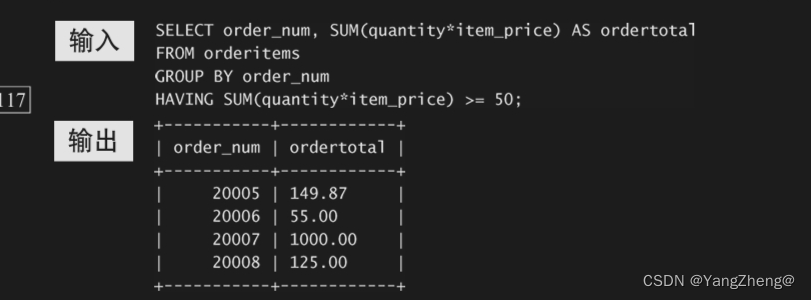

13.5 SELECT子句顺序
下面回顾一下SELECT语句中子句的顺序。表13-2以在SELECT语句中 使用时必须遵循的次序,列出迄今为止所学过的子句。

13.6 小结(需要记住子句之间得差异,可能会问到)
在第12章中,我们学习了如何用SQL聚集函数对数据进行汇总计算。 本章讲授了如何使用GROUP BY子句对数据组进行这些汇总计算,返回每 个组的结果。我们看到了如何使用HAVING子句过滤特定的组,还知道了 ORDER BY和GROUP BY之间以及WHERE和HAVING之间的差异。
第14章 使用子查询
14.1 子查询
SQL还允许创建子查询(subquery),即嵌套在其他查询中的查询
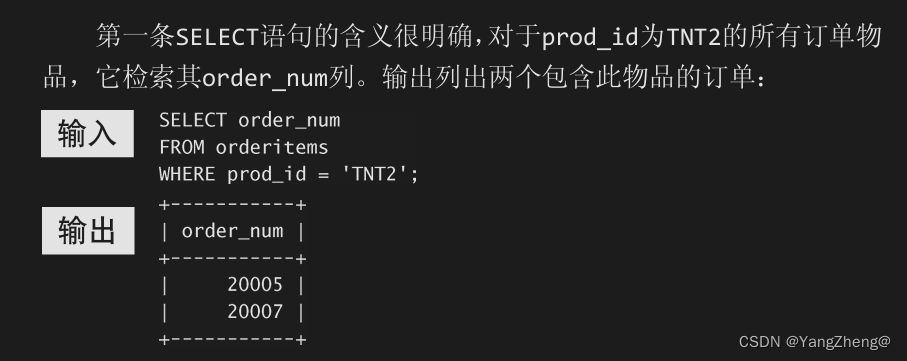
14.2 121 利用子查询进行过滤






14.3 作为计算字段使用子查询
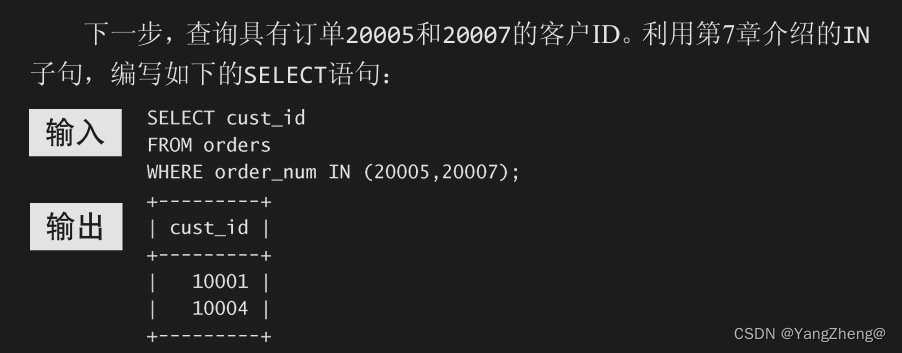
使用子查询的另一方法是创建计算字段。假如需要显示customers 表中每个客户的订单总数。订单与相应的客户ID存储在orders表中。
为了执行这个操作,遵循下面的步骤。
(1) 从customers表中检索客户列表。
(2) 对于检索出的每个客户,统计其在orders表中的订单数目。
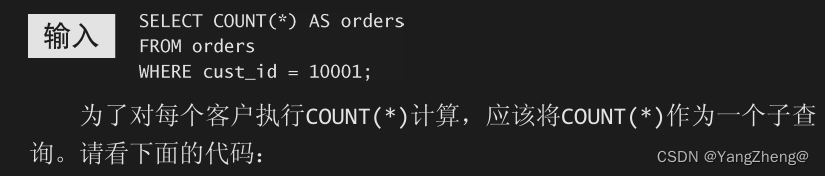
正如前两章所述,可使用SELECT COUNT(*)对表中的行进行计数,并 且通过提供一条WHERE子句来过滤某个特定的客户ID,可仅对该客户的订单进行计数。例如,下面的代码对客户10001的订单进行计数:






14.4 小结

第15章 联 结 表
15.1 联结
SQL最强大的功能之一就是能在数据检索查询的执行中联结(join) 表。联结是利用SQL的SELECT能执行的最重要的操作,很好地理解联结 及其语法是学习SQL的一个极为重要的组成部分。 在能够有效地使用联结前,必须了解关系表以及关系数据库设计的 一些基础知识。下面的介绍并不是这个内容的全部知识,但作为入门已 经足够了。
15.1.1 关系表


15.1.2 为什么要使用联结
正如所述,分解数据为多个表能更有效地存储,更方便地处理,并 且具有更大的可伸缩性。但这些好处是有代价的。
15.2 创建联结
第23章 使用存储过程
- 本章介绍什么是存储过程?
- 为什么要使用存储过程?
- 如何使用存 储过程?
- 掌握创建和使用存储过程的基本语法;
23.1 什么时存储过程

23.2 为什么要使用存储过程(简单,安全,高性能)
1.封装,简化复杂的操作;-------------------》简单
2.防止错误,保证数据的一致性;----------》安全
3.简化对变动的管理;延伸就是安全性,通过存储过程限制对基础数据的访问减少了
数据讹误的机会;
4.提高性能-----------------------------------------》高性能
5.编写功能更强大更灵活的代码



23.3 使用存储过程
执行存储过程开始-----》创建--------》使用三个步骤
23.3.1 执行存储过程

23.3.2 创建存储过程
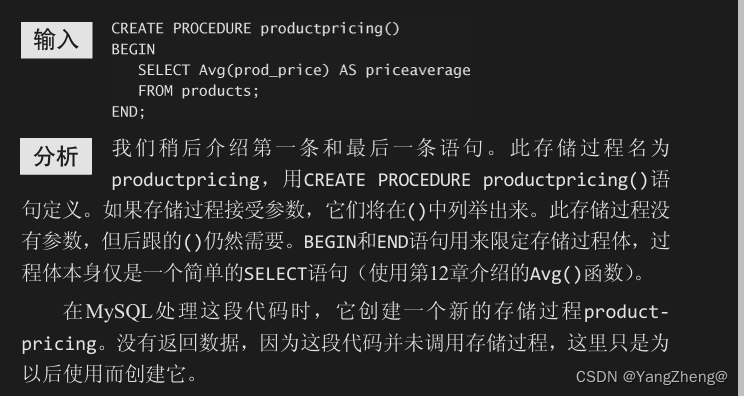



23.3.3 删除存储过程

23.3.4 使用参数
productpricing只是一个简单的存储过程,它简单地显示SELECT语 句的结果。一般,存储过程并不显示结果,而是把结果返回给你指定的变量
















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









