






目录
6.1逻辑回归
6.11介绍
逻辑回归是一种广泛使用的统计方法和机器学习算法,主要用于二分类问题。尽管名字中有“回归”二字,逻辑回归实际上是一种分类算法。它通过线性回归模型的扩展来解决分类问题。逻辑回归的核心思想是将线性回归模型的输出通过sigmoid函数转换为概率,从而将其用于分类。
6.12步骤
1. 收集数据:采用任意方法收集数据。
2. 准备数据:由于需要进行距离计算,因此要求数据类型为数值型。 另外,结构化数据格式则最佳。
3. 分析数据:采用任意方法对数据进行分析。
4. 训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的 分类回归系数。
5. 测试算法:一旦训练步骤完成,分类将会很快。
6. 使用算法:首先,我们需要一些输入数据,并将其转换成对应的结 构化数值;接着,基于训练好的回归系数就可以对这些数值进行简 单的回归计算,判定它们属于哪个类别;在这之后,我们就可以在 输出的类别上做一些其他分析工作。
6.13Sigmod函数
Sigmoid函数(也称为逻辑函数)是一个S形的函数,它将任何实数值映射到0和1之间。它的数学表达式为:
Sigmoid函数的输出值在0到1之间,这使得它非常适合于表示概率。Sigmoid函数是连续且可导的,这意味着可以计算其导数,这在优化过程中非常重要。并且,由于其非线性性质,Sigmoid函数能够将线性模型的输出映射到非线性范围,从而更好地拟合复杂数据。
当输入值 z 为0时,Sigmoid函数的输出为0.5
当z 趋近于正无穷大时,输出趋近于1
当 z 趋近于负无穷大时,输出趋近于0
6.14梯度上升算法
梯度上升算法是一种优化算法,用于最大化目标函数。在机器学习中,梯度上升常用于优化模型参数,使模型的性能(如对数似然函数)达到最大化。它与梯度下降类似,但梯度上升是沿着目标函数的梯度方向更新参数,以找到局部最大值,而梯度下降是沿着梯度的负方向更新参数以找到局部最小值。
6.2逻辑回归进行数据分类
6.21数据准备
在本次逻辑回归实验中,通过查阅资料,获取了一份数据集,包含了一百组数据,且每组数据包含两个特征值x1,x2和一个类别,类别属于{0,1},因此本次实验是进行的是二分类问题。

图一,二:本次实验准备的数据集
6.22导入数据集
通过CreateData函数,将准备好的数据进行导入,值得一提的是,在导入数据的时候,将偏置值b初始化为1,将每个数据的类别存入并将数据集dataSet,labelSet并进行返回
def CreateData():
dataSet = []; labelSet = []
fr = open('D:\Py_project\DecisionTree_project\逻辑回归\data.txt')
for line in fr.readlines():
lineArr = line.strip().split(',')
dataSet.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelSet.append(int(lineArr[2]))
return dataSet,labelSet6.23使用梯度上升求解回归系数
使用梯度上升算法求解逻辑回归模型的最佳回归系数 w 和 b。在逻辑回归模型中,回归系数 w 和偏置项 b 是通过最大化对数似然函数来确定的,而梯度上升算法正是用于实现这一目标的方法之一。
def gradAscent(dataMatIn, classLabels):
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(classLabels).transpose()
m,n = np.shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = np.ones((n,1))
for i in range(maxCycles):
h = sigmoid(dataMatrix*weights)
error = (labelMat - h)
weights = weights + alpha * dataMatrix.transpose()* error
return weights 在求解回归系数的时候,首先初始化数据矩阵和标签矩阵,将标签矩阵从行向量转置为列向量,设置学习率即步长,并设置最大迭代次数,通过多次迭代,使用梯度上升方法更新权重,优化回归系数。最后将所求得的优化后的权重向量进行返回。 
图三:本次实验得到回归系数
6.24画出决策边界
上面已经解出了一组回归系数,它确定了不同类别数据之间的分隔线。需要通过Matplotlib画出来。
def sigmoid(z):
return 1.0/(1+np.exp(-z))def plotBestFit(wei):
weights = wei.getA()
dataMat,labelMat=CreateData()
dataArr = np.array(dataMat)
n = np.shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = np.arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()将传入的权重矩阵转换为数组,为不同类别的数据点初始化 x 和 y 坐标列表,根据标签值,将数据点分类到相应的坐标列表中。绘制两类数据点的散点图,类别 1 用红色方形标记,类别 0 用绿色圆点标记,显示绘制的图表。
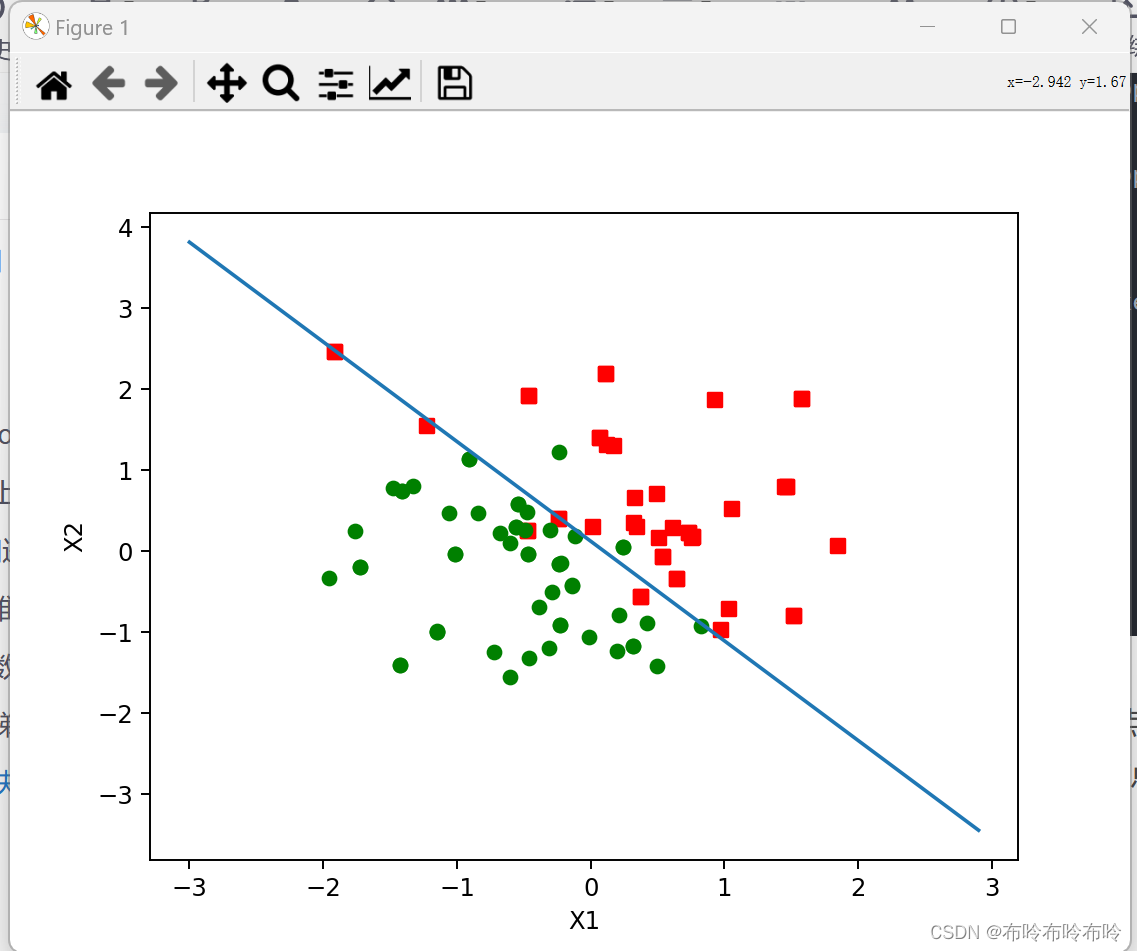
图四:绘制分类边界
6.25类别预测
通过已经求得的回归系数,将预测数据和系数进行矩阵相乘,将结果放入Sigmod函数得到结果,如果结果大于0.5则属于类别1,如果类别小于0.5则属于类别0。
def predict(weights, testData):
testMatrix = np.mat(testData)
probabilities = sigmoid(testMatrix * weights)
return probabilities
testData = [[-1.151,-0.991,0],[0.376,-0.566,1],[0.736,0.227,1],[-1.150,-0.981,0]]
prob = predict(weight,testData)
for i in testData:
if(prob[count]>=0.5 and i[2] == 1):
print('数据'+str(i)+'通过函数得到的结果为'+str(prob[count])+'类别为:1,预测正确')
elif(prob[count]<0.5 and i[2] == 0):
print('数据'+str(i)+'通过函数得到的结果为'+str(prob[count])+'类别为:0,预测正确')
else:
print('数据'+str(i)+'预测错误')
count += 1
图五:类别预测结果
6.3实验结果分析与总结
6.31实验结果分析
在本次逻辑回归实验中,使用了梯度上升算法来训练逻辑回归模型,目的是最大化对数似然函数来优化模型的回归系数。设置了学习率和迭代次数,确保模型能够在训练集上收敛到合适的回归系数,通过绘制决策边界,展示了训练后模型所学习到的分类边界。这条边界将两个类别的数据点分隔开来,最后通过已准备好的测试集,进行预测,通过计算新数据点的概率,并应用阈值(0.5),预测出了它们的类别。
6.32实验总结
在本次实验中,通过该实验展示了逻辑回归在二分类问题上的应用,加深了对逻辑回归算法的理解和应用能力,同时也掌握了数据处理、模型训练和结果验证的基本流程,更进一步地提高自身对机器学习算法地理解和认识,了解了梯度上升算法的基本原理和应用,对于理解和实现其他优化算法有了一定的铺垫。在实验中也了解了Sigmod函数的应用,能够将线性模型的输出映射到非线性范围,从而更好地拟合复杂数据。















 2785
2785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









