






目录
7.1支持向量机
7.11支持向量机介绍
支持向量机是一种用于分类和回归的监督学习模型。它的主要目标是找到一个能够最大化分类间隔的决策边界(或超平面)。SVM 在解决二分类问题方面特别有效,并且可以通过核方法扩展到非线性分类问题。
7.12超平面
在一维空间中,可以利用一个点来区分两类数据点,在二维空间中,超平面是一条直线;在三维空间中,是一个平面。在更高维的空间中,它是一个超平面SVM 的目标是找到能够最大化分类间隔的超平面,即在n维的平面中,总是能找到n-1维的超平面来划分数据。
7.13分类间隔
分类间隔是指从超平面到最近的样本点(支持向量)的距离。SVM 通过最大化这个间隔来找到最佳的决策边界。
7.14支持向量
支持向量是距离决策边界最近的样本点。这些样本点决定了最终的决策边界的具体位置。决策边界由那些靠近边界的点(支持向量)决定。在SVM中,只有支持向量会影响到超平面的方向和位置,其他的点不会对超平面的确定产生影响。
7.15软间隔和硬间隔
硬间隔:要求所有样本点都被正确分类,适用于线性可分的数据。
软间隔:允许一些样本点被误分类,通过引入松弛变量和正则化参数来平衡分类准确性和间隔的大小,适用于线性不可分的数据。
7.2支持向量机进行数据分类
7.21数据准备
本次实验所导入的包:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets在本次实验中,除了利用numpy包来更好地进行计算,matplotli包的pyplot模块来进行可视化展示数据以及超平面,还利用了sklearn包来生成示例数据集。
if __name__ == '__main__':
X, y = datasets.make_blobs(n_samples=100, n_features=2, centers=2, cluster_std=1.05, random_state=40)
y = np.where(y == 0, -1, 1)
svm = LinearSVM()
svm.fit(X, y)
# 绘制决策边界
plot_hyperplane(X, y, svm.w, svm.b)使用datasets.make_blobs 生成一个二分类的数据集并训练 SVM 模型。在本次实验中,主要是对二分类问题进行解决,所以本次生成的数据集,包括了100个样本点、2个特征值、两个类别。并将每个类别中样本点的标准差设置为 1.05,(假设你有一个聚类中心在 (0, 0),标准差为 1.05。那么,大多数样本点会分布在距离 (0, 0) 不超过 1.05 个单位的范围内,但有些点可能会分布得更远。)并设置随机数种子,保证结果的可重复性。
由于上述所生成的数据可以得到,X是一个形状为(100,2)的数组,包含了100个样本点的两个特征,而y是一个长度为100的数组,包含了每个样本点的标签(0,1),并且为了分别对应决策的正类和负类,需要将标签从0/1转化为-1/1。
图一:生成的数据集(部分)和标签集
7.22数据分类
在进行实验的数据分类之前,
学习率设置为:0.001,用于控制每次更新的步长。
正则化参数:0.01,用于控制模型对错误分类的容忍度与决策边界的简单性之间的权衡。
迭代次数:1000,用于表示模型训练过程中更新参数的次数。
class LinearSVM:
def __init__(self, learning_rate=0.001, lambda_param=0.01, n_iters=1000):
self.learning_rate = learning_rate
self.lambda_param = lambda_param
self.n_iters = n_iters
self.w = None
self.b = None
def fit(self, X, y):
n_samples, n_features = X.shape
y_ = np.where(y <= 0, -1, 1)
self.w = np.zeros(n_features)
self.b = 0
for _ in range(self.n_iters):
for idx, x_i in enumerate(X):
condition = y_[idx] * (np.dot(x_i, self.w) - self.b) >= 1
if condition:
self.w -= self.learning_rate * (2 * self.lambda_param * self.w)
else:
self.w -= self.learning_rate * (2 * self.lambda_param * self.w - np.dot(x_i, y_[idx]))
self.b -= self.learning_rate * y_[idx]
def predict(self, X):
linear_output = np.dot(X, self.w) - self.b
return np.sign(linear_output)
在fit函数中,首先获取样本的特征数,并将标签从0/1转化到-1/1,初始化权重向量为全零向量,长度为特征数量。并将偏置值初始化为0。
对数据集进行训练,枚举每个样本点及其索引,检查当前样本点是否满足条件
如果条件成立,更新权重w,仅仅对权重进行衰减,如果不成立则更新权重向量w,和偏置值b。
在predict函数重,首先计算输出,并返回预测结果的符号,+1表示正类,-1表示负类。
这个LinearrSVM类实现了一个简单的线性支持向量机模型,包括训练和预测功能。通过初始化权重和偏置,并在每次迭代中根据 SVM 的条件更新它们,模型可以找到最优的决策边界。fit方法用于训练模型,predict方法用于对新数据进行分类。
7.23可视化超平面
def plot_hyperplane(X, y, w, b):
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y, s=100, edgecolors='k', cmap='winter')
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
xx = np.linspace(xlim[0], xlim[1], 30)
yy = np.linspace(ylim[0], ylim[1], 30)
YY, XX = np.meshgrid(yy, xx)
xy = np.vstack([XX.ravel(), YY.ravel()]).T
Z = (np.dot(xy, w) - b).reshape(XX.shape)
ax.contour(XX, YY, Z, colors='k', levels=[-1, 0, 1], alpha=0.5, linestyles=['--', '-', '--'])
plt.show() 在函数plot_hyperplane中,利用 matplotlib 库来可视化 SVM 模型学习到的决策边界和数据点的分布,帮助理解分类效果和决策边界的位置。 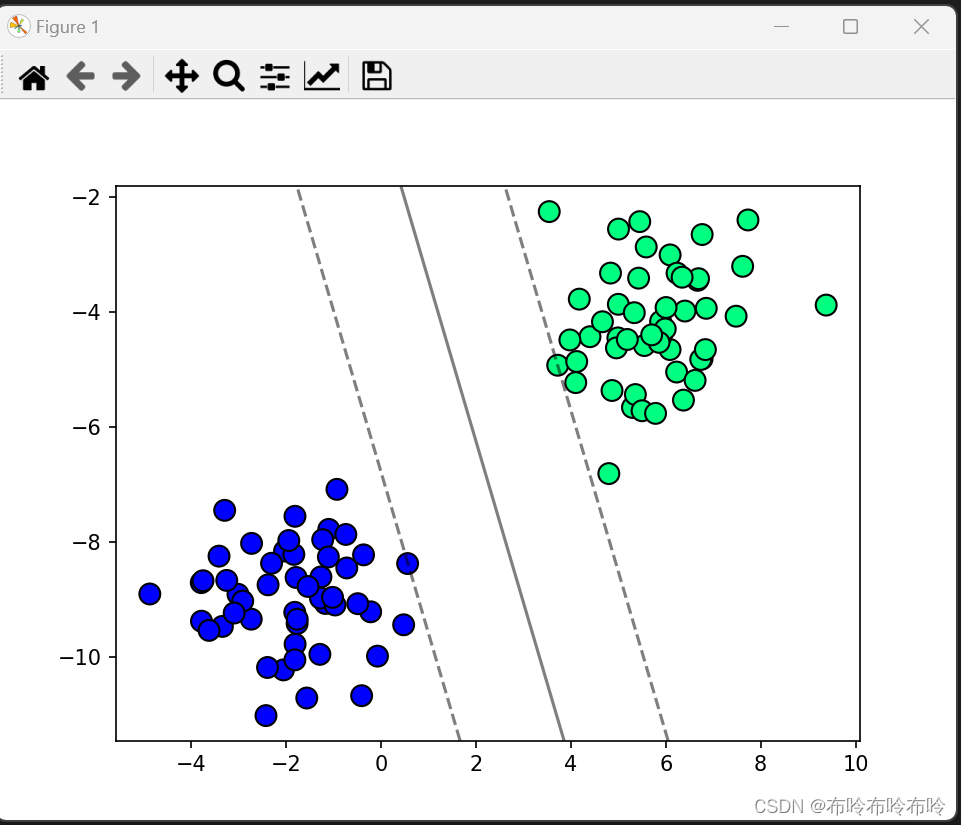
图二:(正则化参数0.01)支持向量机分类效果展示

图三:(正则化参数0.1)支持向量机分类效果展示
7.3实验结果分析与总结
7.31实验结果分析
在本次支持向量机进行数据分类的实验中,首先,可视化的决策边界能够清晰地展示出模型对数据点的分类能力,其次,可以明显通过调整正则化参数(lambda_param)可以影响模型的收敛速度和最终分类效果,需要进行适当的调优。当参数为0.1时可以明显发现有个别样本点落在决策边界和超平面之间,当参数设置为0.01时,这种情况就出现明显好转,因此在进行该实验时,需要进行适当的参数选择,可以使 SVM 在不同类型的数据集上取得良好的分类结果。
优点:
对于样本数量不大但特征维度较高的数据集,SVM 的计算效率较高,因为它主要依赖于支持向量而不是整个数据集。SVM 在高维空间中表现良好,适合处理具有许多特征的数据集。SVM 通过最大化决策边界到支持向量(距离最近的训练样本点)的距离,可以有效地防止过拟合,具有良好的泛化能力。
缺点:
当训练样本数量非常大时,SVM 的训练时间较长,尤其是在非线性核函数和复杂数据结构下。SVM 对数据的质量要求较高,特别是对缺失数据敏感,需要在预处理阶段进行适当的数据调整
7.32实验结果总结
在本次SVM实验中,理解支持向量机的工作原理,以及如何调节参数以优化模型的性能。合适的参数设置和数据条件下,能够提供较好的分类性能和泛化能力。通过实验结果的分析,可以帮助确定在实际应用中如何调整和优化支持向量机模型,以适应不同的数据分布和问题需求。
同时,也让我明白了支持向量的在不同方面的优缺点,SVM 在高维空间中表现良好,适合处理具有许多特征的数据集。并且SVM具有较好的泛化能力,能够较好地来防止过拟合,但对于样本数量较大情况,SVM的效率相对没那么高。















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









