






一、概念:
哈夫曼编码是分组编码,完全依据各字符出现的概率来构造码字。它是一种用于数据压缩的算法,广泛应用于信息存储和传输过程中的数据压缩。该编码方法由David A. Huffman在1952年提出,基本原理是根据字符出现的概率来构造异字头的平均长度最短的码字,其编码长度是变化的,其长度根据字符出现的频率而定。频繁出现的字符使用较短的编码,而较少出现的字符则使用较长的编码,这样可以在保证信息完整性的同时,达到最佳的压缩效果,实现哈夫曼编码的关键在于构建一棵哈夫曼树,这是一棵加权的二进制树。在哈夫曼树中,频繁出现的元素位于树的顶部,而较少出现的元素则位于树的底部。每个左分支分配一个值(通常是0),而每个右分支分配另一个值(通常是1)。这样,从根节点到每个叶节点的路径就形成了一个唯一的二进制编码,代表对应的字符。
二、编码方法:
(1)将信源消息符号按其出现的概率大小依次排列为
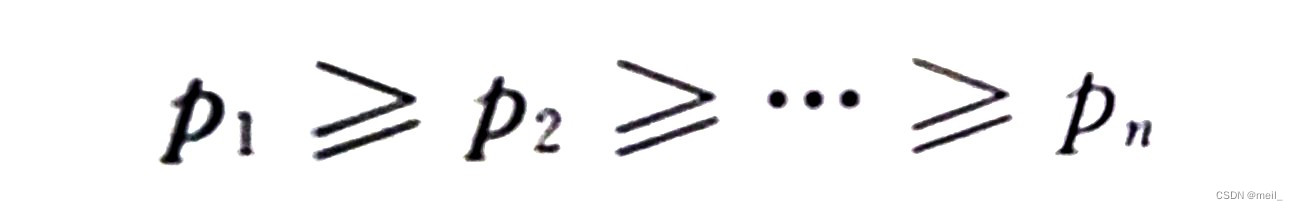
(2)取两个概率最小的字母分别配以0和1两个码元,并将这两个概率相加作为一个新字母的概率,与未分配二进符号的字母一起重新排队。
(3)对重排后的两个概率最小符号重复(2)的过程。
(4)不断继续上述过程,直到最后两个符号配以0和1为止。
(5)从最后一级开始,向前返回得到各个信源符号所对应的码元序列,及相应的码字。
三、哈夫曼编码的优点:
哈夫曼码的平均码长比较小,编码效率高,信息传输速率大。所以在压缩信源信息率的实用设备中,哈夫曼编码还是比较常用的。
四、哈夫曼编码的注意事项:
哈夫曼编码方法得到的码并非是唯一的。每次对信源缩减时,赋予信源最后两个概率最小的符号,用0和1是可以任意的,所以可以得到不同的哈夫曼码,但不会影响码字的长度。对信源进行缩减时,两个概率最小的符号合并后的概率与其他信源符号的概率相同时,这两者在缩减信源中进行概率排序,其位置放置次序可以是任意的,故会得到不同的哈夫曼码。此时将影响码字的长度,一般将合并的概率放在上面,这样可获得较小的码方差。一般进行哈夫曼编码时,为得到码方差最小的码,应使合并的信源符号位于缩减信源序列尽可能高的位置上,以减少再次合并的次数,充分利用短码。
五、哈夫曼编码的一些公式:
码方差: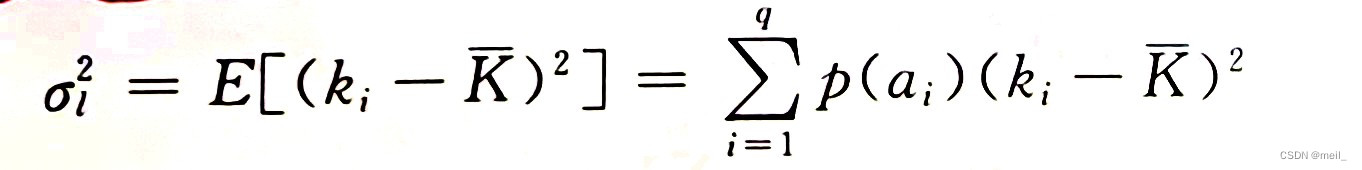
平均码长: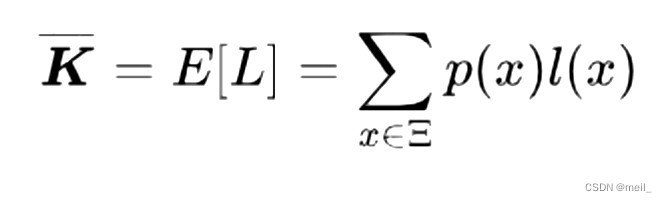
编码效率: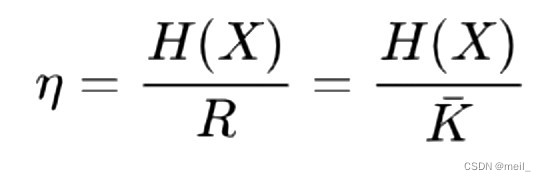















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









