






文章目录
前言
Elasticsearch是一个开源的搜索引擎,主要应用于文章解锁中,如在购物网站搜索物品时快速查找到目标,Elasticsearch的建立是基于一个一个的索引库,与mysql的数据库有些许类似的地方
一、Elasticsearch的安装(以docker为例)
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
- –name设置容器名称
- -e设置环境变量,这里设置的内存大小和是否为集群模式
- -v设置数据卷挂载,前面的目录为自己的目录地址
- -network设置网络名称
- -p设置端口号映射
二、Elasticsearch相关属性
1.分词器
分词器是Elasticsearch内用于定义分割语句标准的工具,在创建倒排索引是对文档进行分词,在搜素是对关键词进行分词,自带的分词器有
- english
- chinese
chinese分词效果:


english分词效果:


但是对于中文语句我们往往使用ik分词器,ik分词器的有2种模式:
- ik_smart:智能切分,粗粒度
- ik_max_word:最细切分,细粒度
ik_smart分词效果:


ik_max_word分词效果:

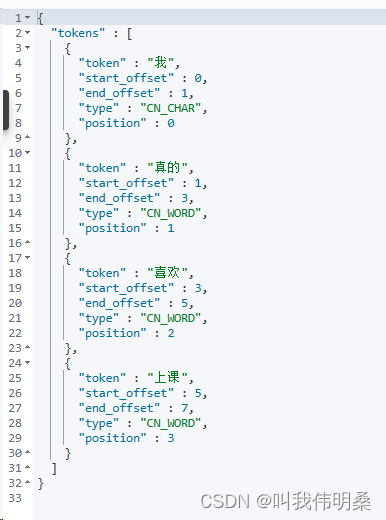
2.倒排索引
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
如图:

3.文档,字段,映射
文档:将索引库类似为Mysql中的表的话,文档就是其中的一条数据,但是他是以json格式存储的
字段:类似与表中的一个属性,如user表中的name属性
映射:定义字段的类型如keyword等
4. mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- 地理坐标:geo_point
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
三、索引库相关操作和java api
1.增加索引库
DSL语句
#创建索引库
PUT /Indexname
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"type": "object",
"properties": {
"firstname":{
"type": "keyword"
},
"lastname":{
"type": "keyword"
}
}
}
}
}
}
java api
//1.创建请求
CreateIndexRequest request = new CreateIndexRequest("hotel");//指定索引库名称
//2.封装数据
request.source(hotelConstants.HOTEL_MAPPING, XContentType.JSON);//为Json风格的DSL语句
//3.发送请求
clinet.indices().create(request, RequestOptions.DEFAULT);
2.删除索引库
DSL语句
#删除索引库
DELETE /Indexname
java api
//1.创建请求
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
//3.发送请求
clinet.indices().delete(request, RequestOptions.DEFAULT);
3.修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
语法说明:
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
4.判断索引库是否存在
java api
//1.创建请求
GetIndexRequest request = new GetIndexRequest("hotel");
//2.发送请求
boolean exists = clinet.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists ? "索引库存在" : "索引库不存在");
四、文档相关操作
1.新增文档
DSL语句
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
java api
@Test
void addDocTest() throws IOException {
//1.查询数据
Hotel byId = service.getById(36934L);
HotelDoc hotelDoc = new HotelDoc(byId);
//2.创建请求
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
//3.封装数据
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);//将hoteldoc转为json
//4.发送请求
clinet.index(request,RequestOptions.DEFAULT);
}
2.查询文档
DSL语句
GET /{索引库名称}/_doc/{id}
java api
@Test
void getDocTest() throws IOException {
GetRequest request = new GetRequest("hotel").id("36934");
GetResponse response = clinet.get(request, RequestOptions.DEFAULT);
//解析返回
String sourceAsString = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);
System.out.println(hotelDoc);
}
3.修改文档
修改有两种方式:
- 全量修改:直接覆盖原来的文档
- 增量修改:修改文档中的部分字段
3.1.全量修改
全量修改是覆盖原来的文档,其本质是:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
示例:
PUT /heima/_doc/1
{
"info": "黑马程序员高级Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
3.2.增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
示例:
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@itcast.cn"
}
}
3.3Java api
@Test
void updateDoctTest() throws IOException {
UpdateRequest request = new UpdateRequest("hotel","36934");
request.doc(
"price","10000",
"startName","三钻"
);
clinet.update(request,RequestOptions.DEFAULT);
}
4.删除文档
DSL语句
DELETE /{索引库名}/_doc/id值
java api
@Test
void deleteDocTest() throws IOException {
DeleteRequest request = new DeleteRequest("hotel","36934");
clinet.delete(request,RequestOptions.DEFAULT);
}
5.批量增加
/**
* 批量增加
*/
@Test
void addBulkDocTest() throws IOException {
//1.准备数据
List<Hotel> list = service.list();
//2.封装数据
BulkRequest requests = new BulkRequest();
for (Hotel hotel : list) {
HotelDoc hotelDoc = new HotelDoc(hotel);
requests.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc),
XContentType.JSON));
}
//3.发送请求
clinet.bulk(requests,RequestOptions.DEFAULT);
}















 26万+
26万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









