






数据结构——树的存储
前言
在树中,除了根节点之外,每个节点必然会对应它的唯一一个父亲,借助这个特性,我们可以通过将每个节点与它的父亲建立联系,来在线性结构中将树中各个节点的非线性关系保存下来
1.双亲表示法
1.1双亲表示法的思路
用顺序表储存,顺序表的每个节点含有数据域,以及其父节点在顺序表中的下标,根节点的父节点下标用-1这一不可能出现的数字表示。节点的定义如下:
typedef struct TreeNode {
int data;//树中存放的真实的数据
int parent;//父节点 -1代表没有父节点
}Node;
为了便于操作,我们还定义几个全局变量。(当然,可以再定义一个结构体,把上面定义的TreeNode数据类型也作为其中的一个成员)
Node* node[5];//父亲表示法的顺序表表示
int size;//当前元素的个数
int maxSize;//元素的总个数
注意,这里我们定义的是一个结构体指针数组,这里我们都是用malloc申请空间的。
定义size是为了记录当前元素个数可以方便遍历结构体数组,不用把数组的所有的地方都给遍历了
对于这棵树,我们给出它的初始化操作,插入操作和查找操作。就需要是三种不同的操作,也就自然地对应三个函数。
void Init();//初始化数据
void insert_root(int);//建立根节点,传入根节点对应的数据
void insert_child(int,int);//插入元素,第一个参数是根节点对应的数据,第二个参数是根节点的父亲对应的数据
int find(int);//找到某个数据对应的节点在顺序表中的下标
这里把初始化分为两个函数来写了,为上面的前两个函数,初始化的话就是建立一个根节点,将其中的数据补充上。
查找函数是为了插入函数服务的,这里先写查找函数,就是普普通通的遍历数组,没什么好说的(主要是重头戏都是第三种表示法【doge】)
插入的话,在逻辑上是在一个较为复杂的树上为某个节点添加一个孩子,实际上就是在顺序表的有空位填上一个节点,把它对应的数据和父亲找到,
1.2双亲表示法的代码实现
#include<stdio.h>
#include<stdlib.h>
typedef struct TreeNode {
int data;//树中存放的真实的数据
int parent;//父节点 -1代表没有父节点
}Node;
/*全局变量*/
Node* node[5];//父亲表示法的顺序表表示
int size;//当前元素的个数
int maxSize;//元素的总个数
void Init();//初始化数据
void insert_root(int);//建立根节点
void insert_child(int,int);//插入元素
int find(int);
void Init()
{
size = 0;
maxSize = 5;
}
/*
创建根节点
key 根节点的关键字
*/
void insert_root(int key)
{
Node* new_node = (Node*)malloc(sizeof(Node));
new_node->data = key;
new_node->parent = -1;
node[size] = new_node;
size++;
}
/*
插入元素
int key 关键字
int parent 父节点的值
*/
void insert_child(int key, int parent)
{
if (size == maxSize)
{
//元素已满 要么提示 要么扩容
}
else
{
//判断一下 是否有这个父节点
int parent_index = find_parent(parent);
if (parent_index == -1)
{
//没有该父节点
}
else
{
Node* new_node = (Node*)malloc(sizeof(Node));
new_node->data = key;
new_node->parent = parent_index;
node[size] = new_node;
size++;
}
}
}
/*
找到节点的下标 返回-1代表没找到
*/
int find(int p)
{
for (int i = 0; i < size; i++) {
if (p == node[i]->data)
{
return i;
}
}
return -1;
}
1.3双亲表示法的优缺点
由于根结点是没有双亲的,所以我们约定根结点的位置域设置为-1,这也就意味着,我们所有的结点都存有它双亲的位置。这样的存储结构,我们可以根据结点中储存的其双亲节点的下标很容易找到它的双亲结点,所⽤的时间复杂度为O(1),直到parent为-1时,表示找到了树结点的根。
可如果我们要知道结点的孩⼦是什么,对不起,请遍历整个结构才⾏,对每个节点都去看他的父亲是不是我们已知的那个节点,并作下记录。
2.孩子表示法
2.1孩子表示法的思路
首先说明,一个节点对应的孩子的个数是未知的,可以没有,可以只有一个,也可用很多,如果对于每个节点的定义,它的孩子都是用数组储存的,这样对于内存的浪费未免太大,于是我们想到链表,但是每个节点的储存我们还是要用顺序表,这样,就有了一个想法:
顺序表+链表的复合结构
我们以顺序表为主体,储存每一个节点,每个节点对应着一个数据域和指针域(实现链表)。
具体定义如下:
typedef struct TreeNode {
char data;
struct TreeNode* next;
}TreeNode;
其余思路和第一种方法差不多,不过注意的是,对于孩子指针域,每个孩子都要重新申请一块空间,不要用已经保存在结构体里的空间了,这样会出现指针指向混乱。就比如下面这张图:
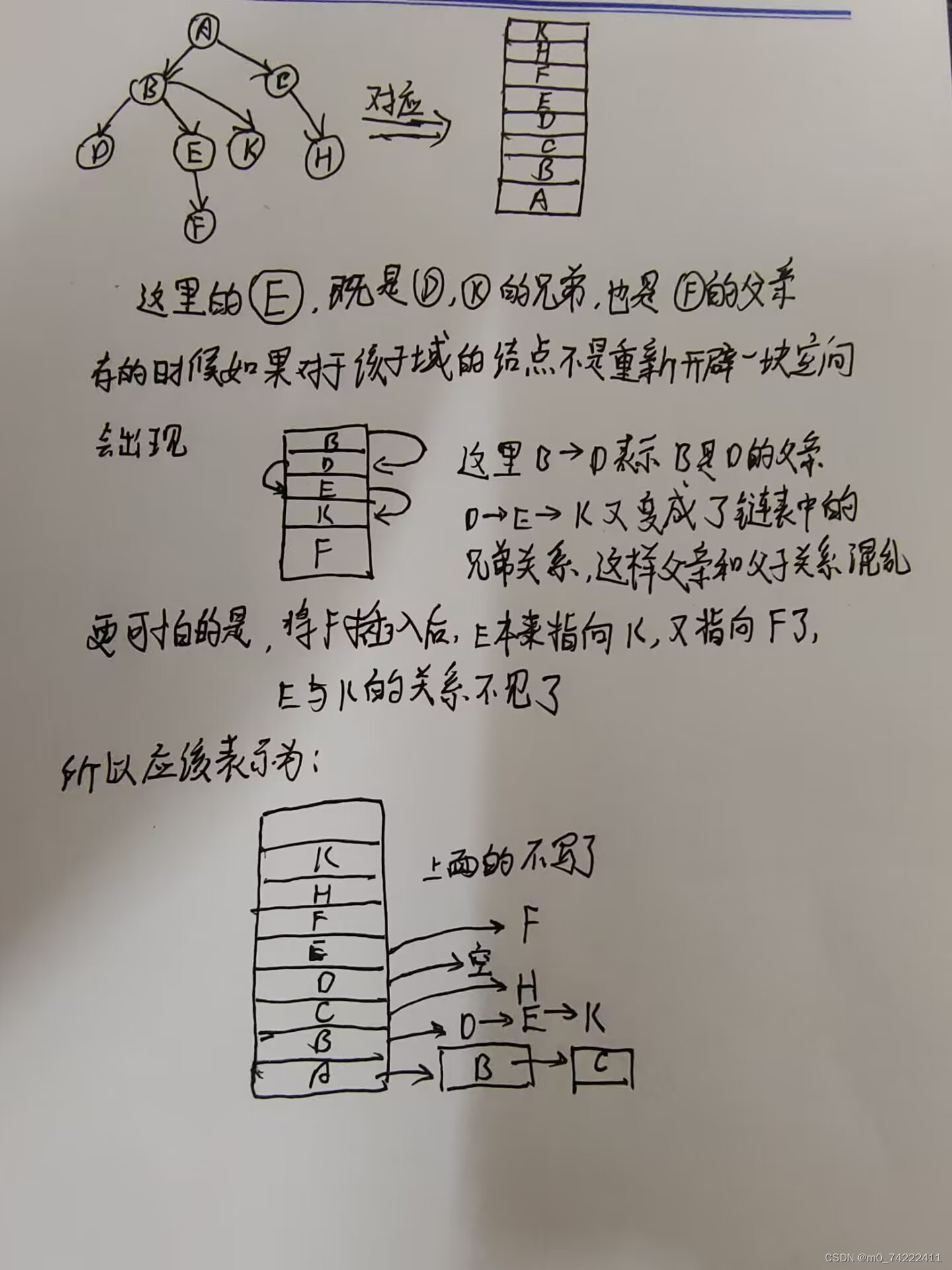
体现在代码上就是:(打了注释的那一块和没打注释的那一块)
/*syx[Size]->next = syx[index]->next;
syx[index]->next = syx[Size];*/
TreeNode* newnode = (TreeNode*)malloc(sizeof(TreeNode));
newnode->data = e;
newnode->next = syx[index]->next;
syx[index]->next = newnode;
对于这个注意事项,现在看不懂没事,下面给出具体代码,结合代码看看,两种思路(上面的代码打了注释的那一块和没打注释的那一块,以及前面图片上的解释)
2.2孩子表示法的代码
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
/*孩子表示法(顺序表和链表的组合结构)*/
#define MAXSIZE 20
typedef struct TreeNode {
char data;
struct TreeNode* next;
}TreeNode;
TreeNode* syx[MAXSIZE];//定义结构体指针数组存放树的节点
int Size;//定义全局变量Size表示树中元素个数
//初始化树的函数
int InitTree(char e) {
Size = 0;
syx[Size] = (TreeNode*)malloc(sizeof(TreeNode));
if (!syx[Size]) {
/*申请空间失败的结果*/
return -1;
}
syx[Size]->data = e;
syx[Size]->next = NULL;
Size++;
return 0;
}
//根据数据部分查找该节点在结构体数组的下标的函数
int FindIndex(char e) {
for (int i = 0; i < Size; i++) {
if (syx[i]->data == e) return i;
}
return -1;
}
//插入节点的函数
int InsertNode(char e, char parent_e) {//parent_e表示插入节点的父节点的数据
//判满
if (Size == MAXSIZE) {
/*满了之后怎么做*/
return -1;
}
//先把这个新加入的节点搞进结构体数组中
syx[Size] = (TreeNode*)malloc(sizeof(TreeNode));
if (!syx[Size]) {
/*申请空间失败的结果*/
return -1;
}
syx[Size]->data = e;
syx[Size]->next = NULL;
Size++;
//考虑把插入的孩子节点储存在孩子链表中
int index = FindIndex(parent_e);
if (index == -1) {
/*说明插入节点的父节点不存在*/
return -1;
}
/*相当于链表的头插操作, 这里我们重新再申请一块空间,
储存要插入的数据作为一个树的节点,储存在链表之中,而不是像下面注释的两行这样
单纯在结构体数组中进行一些指针指向的改变*/
/*syx[Size]->next = syx[index]->next;
syx[index]->next = syx[Size];*/
TreeNode* newnode = (TreeNode*)malloc(sizeof(TreeNode));
newnode->data = e;
newnode->next = syx[index]->next;
syx[index]->next = newnode;
return 0;
}
int main() {//在主函数中测试一下
InitTree('A');
InsertNode('B', 'A');
InsertNode('C', 'A');
InsertNode('D', 'A');
InsertNode('E', 'B');
InsertNode('F', 'B');
InsertNode('G', 'C');
for (int i = 0; i < Size; i++) {
TreeNode* temp = syx[i]->next;
printf("the node is %c\n", syx[i]->data);
if(syx[i]->next!=NULL) printf("here is its children:");
while (temp != NULL) {
printf(" %c", temp->data);
temp = temp->next;
}
if (syx[i]->next != NULL) printf("\n");
}
return 0;
}
2.3孩子表示法的优缺点
这种表示法,给查找某个结点的某个孩⼦带来了⽅便,只需要通过某个节点的孩子们域指针找到此结点的第一个孩子,然后再通过该孩子结点的指针域找到它的⼆弟,接着⼀直下去,直到找到具体的孩⼦。当然,如果想找某个结点的双亲,这个表示法也是有做陷的,那怎么办呢?
对,如果真的有必要,完全可以再增加⼀个parent指针域来解决快速查找双亲的问题,这⾥就不再细谈了。
3.孩子兄弟表示法
3.1孩子兄弟表示法的思路
我们知道一个节点只有一个父亲,但是孩子的个数是不确定的,如果对于每个节点,建立它与它孩子之间的关系,我们自然地想到了上面的第二种表示法,但是上面的两种方法,不管是父亲表示法还是孩子表示法,都离不开线性表这一结构,会存在容量限制问题以及内存浪费问题。
于是,孩子兄弟表示法就出来了,这种方法采用二叉链表的方式储存,给一个节点两个指针域,一个用来指向第一个孩子,另一个指向自己的兄弟。话不多说,下面给几张图看下:
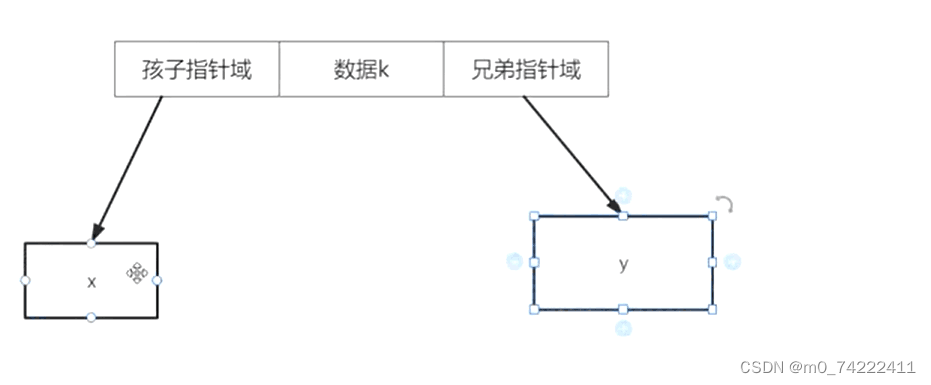
这个就是二叉链表的每个节点的示意图,其中x是该节点的孩子,y是该节点的兄弟,也是x的叔叔
对应的结构体的代码如下:
typedef struct ChildSibling{
int data; //保存树中节点的数据
ChildSibling* child;//孩子域指针
ChildSibling* sibling;//兄弟域指针
}ChildSibling;
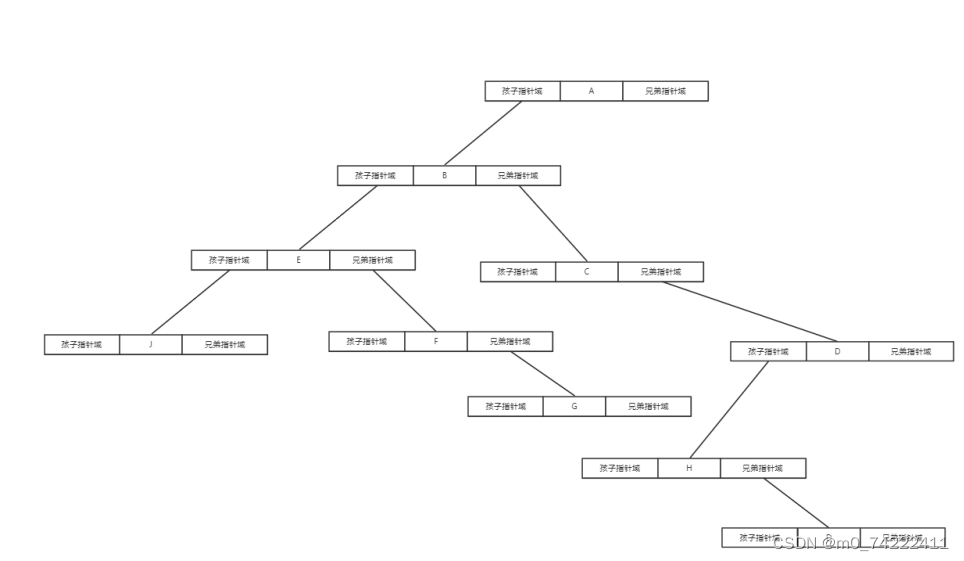
对应的一棵树也便以这种树形式储存下来
这样存储下来没有问题了,但是如何通过数据域的值来找到对应的节点呢,这个问题关系到我们对于节点的插入。
解决这个问题的话,需要遍历这个二叉链表,可这种非线性的结构看着确实头痛,不好遍历。于是便有人想到运用递归来解决这个问题。
这个二叉链表可以看作一个二叉树,对于树来说,每个节点不单单是这整棵树中的一个节点,它更是以它为根节点的子树的一个根节点,就算是叶子结点,也可看作一个只有根节点的树,这样的话,遍历这一整棵树,可以分解为遍历它的子树,再分解为遍历它的子树的子树,与递归建立起联系
具体代码如下:
ChildSibling* Findd(int e,ChildSibling* treenode) {
if (treenode->data == e) { return treenode; }
if (treenode->child != NULL) {
ChildSibling* tmp = Findd(e, treenode->child);
if (tmp != NULL) { return tmp; }
}
if (treenode->sibling != NULL) {
ChildSibling* tmp = Findd(e, treenode->sibling);
if (tmp != NULL) { return tmp; }
}
return NULL;
}
3.2孩子兄弟表示法的代码
下面将给出的代码的main函数部分是以这张图的树为标准的
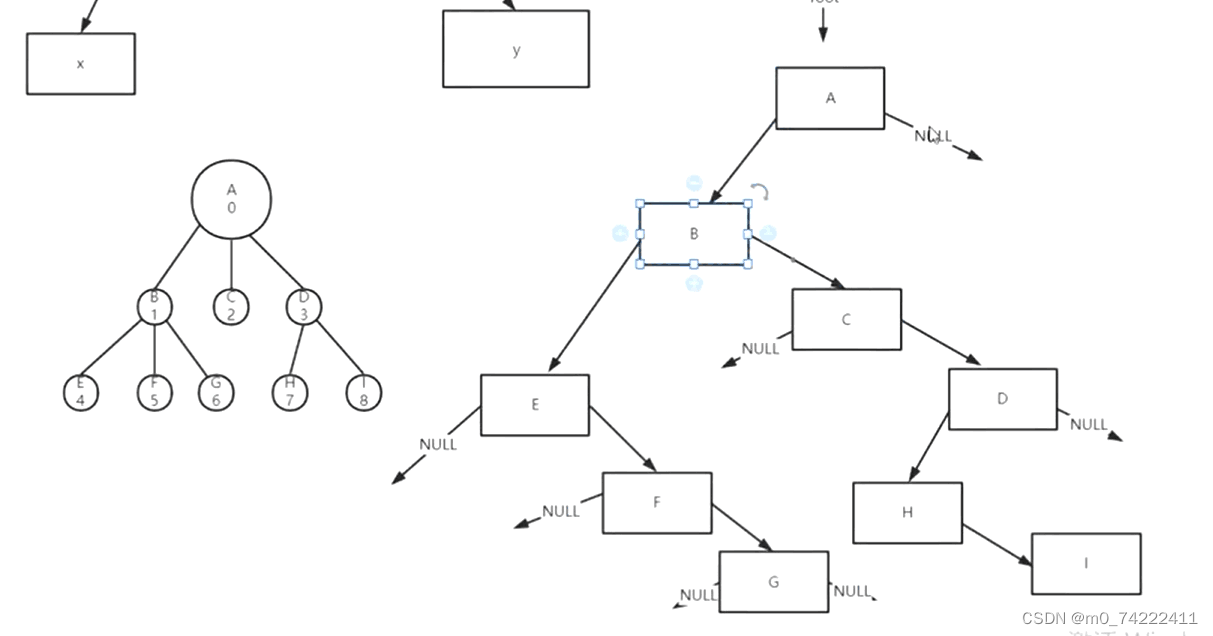
#include <stdio.h>
#include <stdlib.h>
typedef struct ChildSibling{
int data; //保存树中节点的数据
ChildSibling* child;//孩子域指针
ChildSibling* sibling;//兄弟域指针
}ChildSibling;
/*全局变量*/
ChildSibling* root;//定义根节点
/*函数声明*/
//初始化函数
int InitTree(int e); //e为根节点的数据
//插入函数
int InsertNode(int e, int parent);//第一个参数为插入的节点的数据,第二个参数为要插入的节点的父母的数据
//查找函数
ChildSibling* Findd(int e, ChildSibling* treenode);//用于定位数据为“e”的节点的位置,其中第二个参数为所查找的树的根节点
/*函数定义*/
int InitTree(int e) {
root = (ChildSibling*)malloc(sizeof(ChildSibling));
if (root == NULL) {/*进行提示(略)*/ return -1; }
root->data = e;
root->child = root->sibling = NULL;
return 0;
}
ChildSibling* Findd(int e,ChildSibling* treenode) {
if (treenode->data == e) { return treenode; }
if (treenode->child != NULL) {
ChildSibling* tmp = Findd(e, treenode->child);
if (tmp != NULL) { return tmp; }
}
if (treenode->sibling != NULL) {
ChildSibling* tmp = Findd(e, treenode->sibling);
if (tmp != NULL) { return tmp; }
}
return NULL;
}
int InsertNode(int e, int parent) {
ChildSibling* newnode = (ChildSibling*)malloc(sizeof(ChildSibling));
if (newnode == NULL) {/*进行提示(略)*/ return -1; }
newnode->data = e;
ChildSibling* tmp = Findd(parent, root);//
if (tmp == NULL) { printf("没找到该节点的父亲节点\n"); return -1; }
//进行插入
//情况一:新插入的节点的父节点之前没有孩子,也即新节点为该父节点的长子
if (tmp->child == NULL) {
ChildSibling* newnode = (ChildSibling*)malloc(sizeof(ChildSibling));
if (newnode == NULL) {/*进行提示(略)*/ return -1; }
newnode->data = e;
newnode->child = newnode->sibling = NULL;
tmp->child = newnode;
return 0;
}
//情况二:新插入的节点不是长子,所以要放到长子的兄弟域里面
else {
ChildSibling* newnode = (ChildSibling*)malloc(sizeof(ChildSibling));
if (newnode == NULL) {/*进行提示(略)*/ return -1; }
newnode->data = e;
newnode->child = NULL;//别忘了对新节点的孩子赋值
//这里要进行链表中的插入操作,我们选择头插法,也即把新节点插在长子的后面,避免遍历兄弟域的链表
newnode->sibling = tmp->child->sibling;
tmp->child->sibling = newnode;
return 0;
}
}
int main() {
InitTree(0);
InsertNode(1, 0);
InsertNode(2, 0);
InsertNode(3, 0);
InsertNode(4, 1);
InsertNode(5, 1);
InsertNode(6, 1);
InsertNode(7, 3);
InsertNode(8, 3);
//下面看看孩子兄弟关系是不是和我们上面建立的树的一样
ChildSibling* tmp = root->child;
if (tmp) {
printf("根节点0的儿子为");
printf("%d", tmp->data);
while (tmp->sibling) {
printf(" %d", tmp->sibling->data);
tmp = tmp->sibling;
}
printf("\n");
}
tmp = root->child->child;
if (tmp) {
printf("根节点1的儿子为");
printf("%d", tmp->data);
while (tmp->sibling) {
printf(" %d", tmp->sibling->data);
tmp = tmp->sibling;
}
printf("\n");
}
return 0;
}
关于代码部分查找函数的注意点:
可以看到,我在每次调用自身的下面一行又加上了
if (tmp != NULL) { return tmp; }
这一句
这个语句非常关键,因为这里的递归设置了判断孩子和兄弟分别是否为空的两个并列的判断
就是上面的
if (treenode->child != NULL) ;
if (treenode->sibling != NULL);
这两句
可以看一下,去掉了这两句的代码是这个样子的
ChildSibling* Findd(int e,ChildSibling* treenode) {
if (treenode->data == e) { return treenode; }
if (treenode->child != NULL) {
ChildSibling* tmp = Findd(e, treenode->child);
}
if (treenode->sibling != NULL) {
ChildSibling* tmp = Findd(e, treenode->sibling);
}
return NULL;
举个例子,还是这张图(看右边的二叉链表部分)
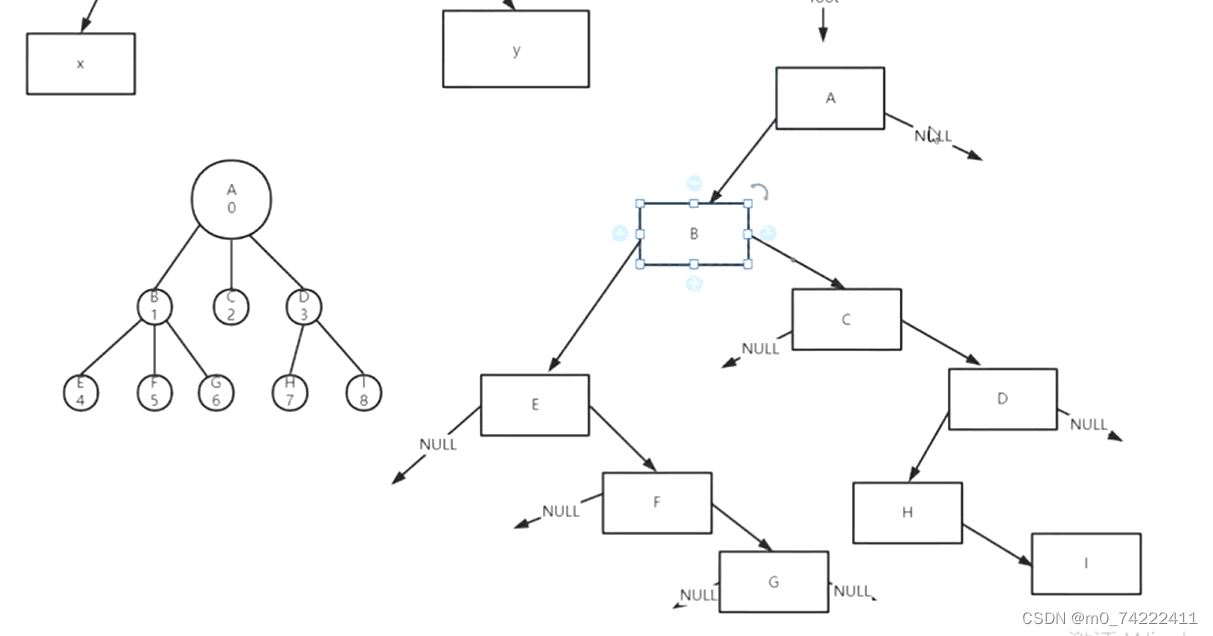
我要查找数据为4的节点E,在递归时候会发现A节点的数据不是4,然后调用自身,会去看节点B的数据是不是4,发现不是,再调用一次自身,去看节点E的数据是不是4,发现对应上了,准备返回这个节点E的地址
不幸的是,返回到节点B的时候下面还有个判断兄弟域的if语句,在里面又进行递归,去看C,D,H,I反正就是没找到数据是4的节点,最后返回了NULL。
这样看来,我们本来是找了节点E和他的地址,但是在返回的时候这个值被“篡改”了,为了避免这种情况发生,我们,在递归语句下面加上了if判断,一旦找到节点E,立即返回,不要再进行下面的if语句了。
3.3孩子兄弟表示法的优缺点
这种表示法,给查找某个结点的某个孩⼦带来了⽅便,只需要通过该节点的孩子指针域找到此结点的⻓⼦,然后再通过⻓⼦结点的兄弟指针域找到它的⼆弟,接着⼀直下去,直到找到具体的孩⼦。当然,如果想找某个结点的双亲,这个表示法也是有做陷的,那怎么办呢?
对,如果真的有必要,完全可以再增加⼀个parent指针域来解决快速查找双亲的问题,这⾥就不再细谈了。















 4481
4481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









