






声明:
1.参考视频b站黑马程序员视频,极力推荐这个视频,侵权删除
2.第一次配置,仅作为个人记录使用。
3.所有软件在Linux安装地址默认/export/server,包括anaconda与spark,创建目录指令:mkdir export
一、准备Linux系统(本人使用VMware虚拟机)、Hadoop(本人使用3.3.4版本,本人使用spark支持Hadoop版本为3+)、spark安装包、anaconda安装包。
1.VMware与Hadoop默认配置完毕。
2.Hadoop在Linux系统里查看版本指令:Hadoop version,版本3+即可。
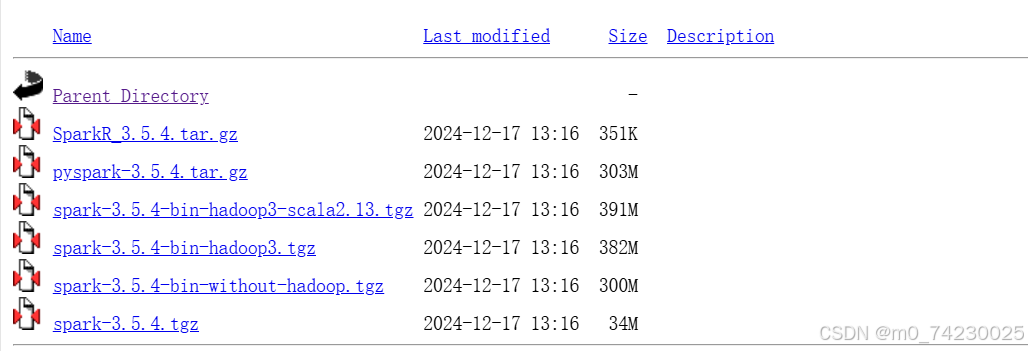
3.spark清华源安装地址( 本人使用安装包:spark-3.5.4-bin-hadoop3.tgz):
Index of /apache/spark/spark-3.5.4
4.anaconda安装包百度网盘:
通过网盘分享的文件:Anaconda3-2021.05-Linux-x86_64.sh
链接: https://pan.baidu.com/s/1rNNupcEHYSE-lBLUQq3EGQ?pwd=s9pm 提取码: s9pm
--来自百度网盘超级会员v1的分享
二、安装anaconda
1.上传安装包Anaconda3-2021.05-Linux-x86_64.sh文件到Linux服务器上
2.安装指令:sh ./Anaconda3-2021.05-Linux-x86_64.sh,加载后 输入yes后就安装完成了
(此处更改,图片误将export写为expert).

3.安装完成后, 退出VM或重新连接虚拟机,看到这个Base开头表明安装好了.base是默认的虚拟环境.
4.修改anaconda清华源
追加以下内容后,esc退出,按shift+:,输入wq!,退出。
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud5.测试:

6.创建anaconda新空间并修改python=3.8

7.使用新空间

anaconda配置完毕,即python配置完毕。
三、安装spark
1.上传安装包文件到Linux服务器上。
2.解压文件

3.配置环境变量(hadoop与Java环境变量默认配置完毕)

export SPARK_HOME=/export/server/spark
export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.8
export HADOOP_CONF_DIR=$HDADOOP_HOME/etc/hadoop
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
4.配置bashrc

此处的Java地址是本人之前配置好的地址
5.测试spark中的bin中的pyspark
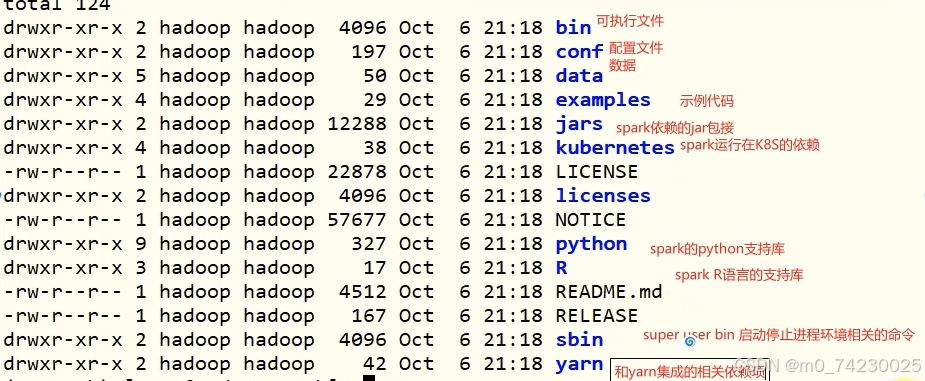
在bin中测试
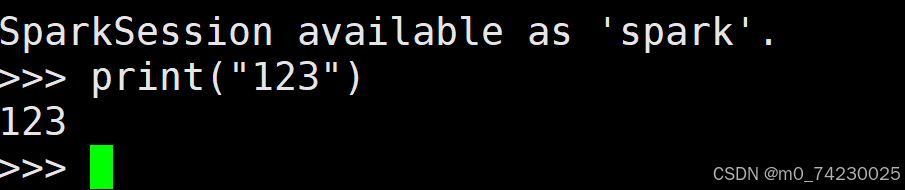
注:
1.local本地模式的原理:
Spark 本地模式的运行原理可以通俗地理解为在一台电脑上模拟整个 Spark 集群的运行。
单一 JVM 进程
所有组件都在一个进程中:在本地模式下,Spark 的驱动程序(Driver)、执行器(Executor)以及任务调度等所有组件都运行在同一个 JVM 进程中。这意味着整个 Spark 应用程序就像一个普通的 Java/Scala 应用程序一样运行在本地机器上。
资源限制:由于所有组件都在一个 JVM 进程中运行,它们共享这个进程的内存和 CPU 资源。因此,在本地模式下,Spark 应用程序的资源使用受到单个 JVM 进程的限制,无法像在集群模式下那样利用多台机器的资源。
任务执行
任务调度和执行:尽管是在本地模式,Spark 的任务调度机制仍然存在。驱动程序会将应用程序的任务分解为多个小任务,并在同一个 JVM 进程中顺序执行这些任务。每个任务都会模拟在集群模式下执行器的行为,处理数据并返回结果。
数据存储:在本地模式下,Spark 会将数据存储在本地机器的内存或磁盘上。对于需要持久化的数据,Spark 会将其保存在本地的存储介质中,以便后续任务可以访问和处理。
适用场景
开发和测试:本地模式非常适合开发和测试阶段。开发者可以在本地机器上快速编写、调试和运行 Spark 应用程序,而不需要搭建一个完整的集群环境。这大大提高了开发效率,降低了开发成本。
小规模数据处理:对于处理小规模数据集的简单任务,本地模式也是一个不错的选择。它能够快速执行任务并返回结果,适合进行数据探索和分析。
限制和注意事项
性能限制:由于资源限制,本地模式下的 Spark 应用程序在处理大规模数据集或复杂任务时可能会遇到性能瓶颈。它不适合用于生产环境或需要高性能计算的场景。
配置参数:在本地模式下,可以通过配置参数来指定使用的线程数,例如使用 local[4] 作为主参数,表示在本地使用 4 个线程来运行 Spark 应用程序。这可以在一定程度上提高并行处理能力,但仍然受到单个 JVM 进程的限制。

















 2051
2051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









