






目录
一、简介
在当今数据驱动的时代,机器学习技术已经渗透到我们生活的方方面面,从在线购物推荐、社交媒体内容过滤,到医疗诊断、金融风险评估,无不体现着机器学习的强大力量。在这些应用场景中,分类问题尤为常见,如判断邮件是否为垃圾邮件、预测用户是否会点击某个广告等。逻辑回归(Logistic Regression)作为一种经典的分类算法,因其简单高效、易于实现和解释性强等特点,在机器学习领域占据了重要地位。
逻辑回归,尽管名字中带有“回归”二字,但实际上它是一种用于解决二分类问题的统计学习方法。它通过计算样本属于某个类别的概率来进行分类,具有明确的概率解释性,使得模型的结果更易于理解和应用。此外,逻辑回归还具有计算速度快、对数据和场景的适应能力较强等优点,因此在很多实际问题中得到了广泛应用。
1. 定义逻辑回归
逻辑回归是一种广义的线性回归分析模型,用于解决二分类问题。它通过建立预测函数(也称为决策函数)来预测因变量(通常为二分类的类别标签)与自变量(特征)之间的关系。逻辑回归的输出是一个介于0和1之间的概率值,表示样本属于某个类别的可能性。
在逻辑回归中,我们使用Sigmoid函数(也称为逻辑函数)将线性回归模型的输出映射到0和1之间,从而得到一个概率值。Sigmoid函数具有连续、可导、单调递增等特性,能够很好地满足逻辑回归的需求。
2. 逻辑回归的假设
逻辑回归基于以下假设:
- 样本数据是线性可分的,即存在一个超平面能够将不同类别的样本分开。
- 因变量是二分类的,即每个样本只属于两个类别中的一个。
- 样本数据满足独立同分布假设,即每个样本都是独立生成的,且服从相同的概率分布。
二、 逻辑回归的数学原理
逻辑回归的数学原理主要涉及到预测函数、损失函数和优化方法三个方面。
预测函数:逻辑回归的预测函数通常采用Sigmoid函数,将线性回归模型的输出映射到0和1之间。预测函数的形式为:,其中是模型参数(权重和偏置项),(x)是输入特征向量。图像如下图所示:

损失函数:逻辑回归的损失函数通常采用交叉熵损失函数(Cross-Entropy Loss),用于衡量模型预测结果与实际标签之间的差异。损失函数的形式为:![]()
,其中(m)是样本数量,(y^{(i)})是第(i)个样本的实际标签,是模型对第(i)个样本的预测概率。
优化方法:逻辑回归的优化方法通常采用梯度下降算法(Gradient Descent),通过迭代更新模型参数来最小化损失函数。在每次迭代中,根据损失函数对模型参数的梯度来更新参数值,直到达到收敛条件或达到最大迭代次数。公式:weights = weights - learning_rate * gradient
逻辑回归的优化也可以使用梯度上升(Gradient Ascent)方法,尽管在实际应用中,梯度下降(Gradient Descent)更为常见。这是因为逻辑回归的损失函数(通常是交叉熵损失)是一个凸函数,对于凸函数来说,梯度下降可以确保找到全局最优解。然而,从数学原理上讲,梯度上升同样可以用来优化逻辑回归。
梯度上升与梯度下降的主要区别在于它们的搜索方向是相反的。梯度下降沿着损失函数的负梯度方向进行搜索,以找到使损失函数最小的参数值;而梯度上升则沿着损失函数的正梯度方向进行搜索,以找到使损失函数最大的参数值。但是,在逻辑回归中,我们通常希望最小化损失函数,因此我们需要对梯度上升进行一些调整。
具体来说,如果我们使用梯度上升来优化逻辑回归,我们可以将参数的更新公式改为:
weights = weights + learning_rate * gradient
其中,weights 是模型的权重参数,learning_rate 是学习率,gradient 是损失函数关于权重的梯度。这样,参数就会沿着损失函数的正梯度方向进行更新,但由于我们在前面加了一个负号,所以实际上参数是朝着使损失函数减小的方向移动的。
三、代码实现
import numpy as np
import matplotlib.pyplot as plt
# 生成数据集
np.random.seed(0)
X1 = np.random.randn(100, 2) - [2, 2] # Class 0
X2 = np.random.randn(100, 2) + [2, 2] # Class 1
X = np.vstack((X1, X2))
y = np.hstack((np.zeros(100), np.ones(100)))
# 定义逻辑回归模型
class LogisticRegression:
def __init__(self, learning_rate=0.01, n_iterations=1000):
self.learning_rate = learning_rate #学习率,即更新的步长
self.n_iterations = n_iterations #迭代次数
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def fit(self, X, y):
#拟合函数,用于训练模型参数
self.weights = np.zeros(X.shape[1])
#初始化权重为零向量:创建一个和特征数量相同长度的全零向量,并将其赋值给逻辑回归模型的权重self.weights。这样初始化的权重向量将在模型的训练过程中进行调整,以便最终得到合适的分类边界。
self.bias = 0 #初始化偏置为0
for _ in range(self.n_iterations):
linear_model = np.dot(X, self.weights) + self.bias #计算线性模型
y_predicted = self.sigmoid(linear_model) #计算预测值
dw = (1 / X.shape[0]) * np.dot(X.T, (y_predicted - y)) #计算权重的梯度向量:
#y_predicted是模型对样本的预测值,是一个包含所有样本预测结果的向量,y是样本的真实标签,(y_predicted - y)计算了每个样本的预测误差。
#X是输入特征的矩阵,每一行代表一个样本,每一列代表一个特征,X.T表示X的转置矩阵。
#(1 / X.shape[0])是为了归一化梯度,其中X.shape[0]表示样本的数量。
db = (1 / X.shape[0]) * np.sum(y_predicted - y) #计算偏置(即截距)的梯度
self.weights -= self.learning_rate * dw #更新权重
self.bias -= self.learning_rate * db #更新偏置
def predict(self, X): #对输入数据进行分类预测
linear_model = np.dot(X, self.weights) + self.bias #计算线性模型
y_predicted = self.sigmoid(linear_model) #计算预测概率
y_predicted_cls = [1 if i > 0.5 else 0 for i in y_predicted] #根据概率分类
return y_predicted_cls
# 实例化逻辑回归模型
model = LogisticRegression(learning_rate=0.1, n_iterations=1000)
# 划分训练集和测试集
indices = np.random.permutation(X.shape[0])
training_idx, test_idx = indices[:150], indices[150:]
X_train, X_test = X[training_idx, :], X[test_idx, :]
y_train, y_test = y[training_idx], y[test_idx]
# 训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
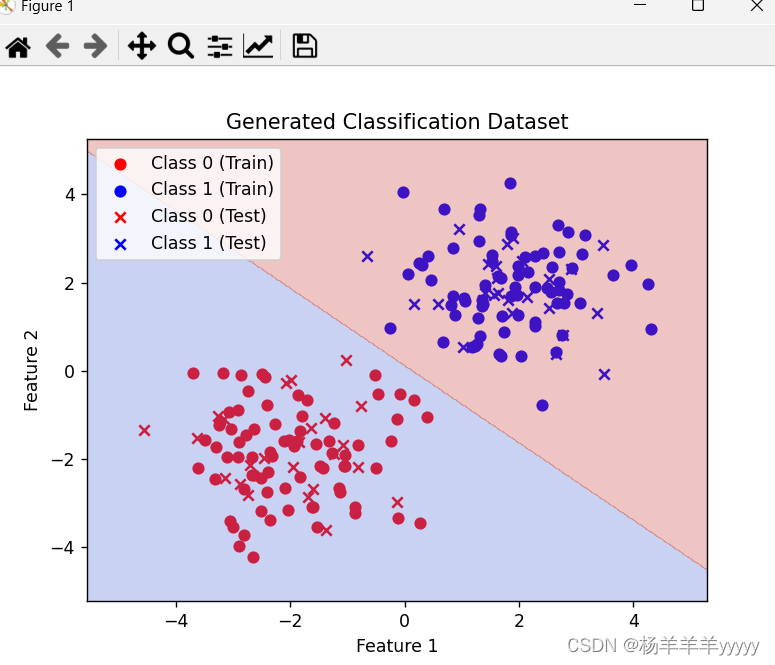
# 绘制训练集和测试集的散点图
plt.scatter(X_train[y_train == 0][:, 0], X_train[y_train == 0][:, 1], color='r', label='Class 0 (Train)')
plt.scatter(X_train[y_train == 1][:, 0], X_train[y_train == 1][:, 1], color='b', label='Class 1 (Train)')
plt.scatter(X_test[y_test == 0][:, 0], X_test[y_test == 0][:, 1], color='r', marker='x', label='Class 0 (Test)')
plt.scatter(X_test[y_test == 1][:, 0], X_test[y_test == 1][:, 1], color='b', marker='x', label='Class 1 (Test)')
plt.legend()
plt.title('Generated Classification Dataset')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
# 绘制决策边界
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = np.array(Z).reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.coolwarm)
plt.show()运算结果
四、总结
逻辑回归是一种简单而有效的分类算法,在实际应用中具有广泛的应用。通过构建逻辑回归模型,我们可以对数据进行二分类预测,并应用在医疗诊断、金融风控、推荐系统等领域。逻辑回归的实现可以借助Python等编程语言和机器学习库,快速搭建和部署算法。
4.1 优点
模型简单:Logistic回归的模型结构简单,易于理解和实现。
速度快:Logistic回归的计算速度相对较快,适合处理大量数据。
适应性:Logistic回归可以处理线性可分问题,对于某些场景具有较好的表现。
易于更新:Logistic回归模型可以容易地更新,吸收新的数据和特征。
稳定性:Logistic回归对异常值和不稳定数据具有一定的鲁棒性。减小极端情况的影响
4.2 缺点
适应性局限:Logistic回归是一个弱分类器,其对数据和场景的适应能力有限,不如决策树等算法强大。仅仅适应于线性分布
特征限制:Logistic回归在处理高维度特征时,表现不如其他算法,如支持向量机等。
无法处理非线性问题:Logistic回归本身仅适用于线性可分问题,处理非线性问题需要借助核技巧等方法。
参数敏感:Logistic回归的参数选择和调整较为复杂,容易受到数据影响,需要多次迭代和调参。
过拟合风险:Logistic回归有可能出现过拟合现象,需要采用特征选择、正则化等方法降低过拟合风险。















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









