







皮尔逊Person相关系数
拿到数据:描述性检验,正态性检验,计算皮尔逊相关系数,假设检验(显著性检验)
步骤
1、对题目中所给数据做描述统计(做成表)
(1)方法一:用matlab中的计算基本统计量的函数
| min | 数组的最小元素 | mink | 计算数组的 k 个最小元素 |
| max | 数组的最大元素 | maxk | 计算数组的 k 个最大元素 |
| mean | 数组的均值 | bounds | 最小元素和最大元素 |
| median | 数组的中位数值 | topkrows | 按排序顺序的前若干行 |
| skewness | 数组的偏度 | mode | 数组的众数 |
| kurtosis | 数组的峰度 | var | 方差 |
| std | 标准差 |
(一般只使用左边一列就够了)
以上函数都默认按列计算,如果令第二个参数为2,则变为按行计算。
将结果复制到excel中,加上标题和行标列表。
(2)方法二:用excel
excel ,数据, 数据分析(这项如果没有的话,需要在excel首页,选项,加载项/自定义项能选),描述统计,勾选汇总统计
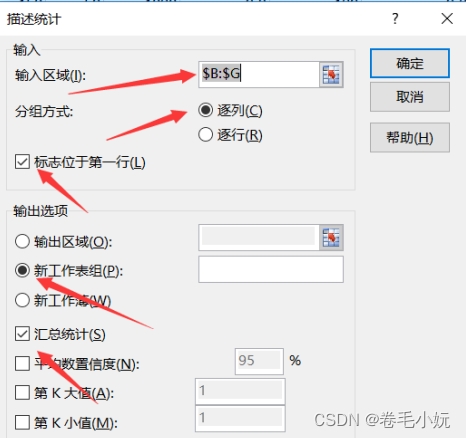
得到的表格精简后粘贴到论文中。
(3)方法三:用SPSS(24之后)
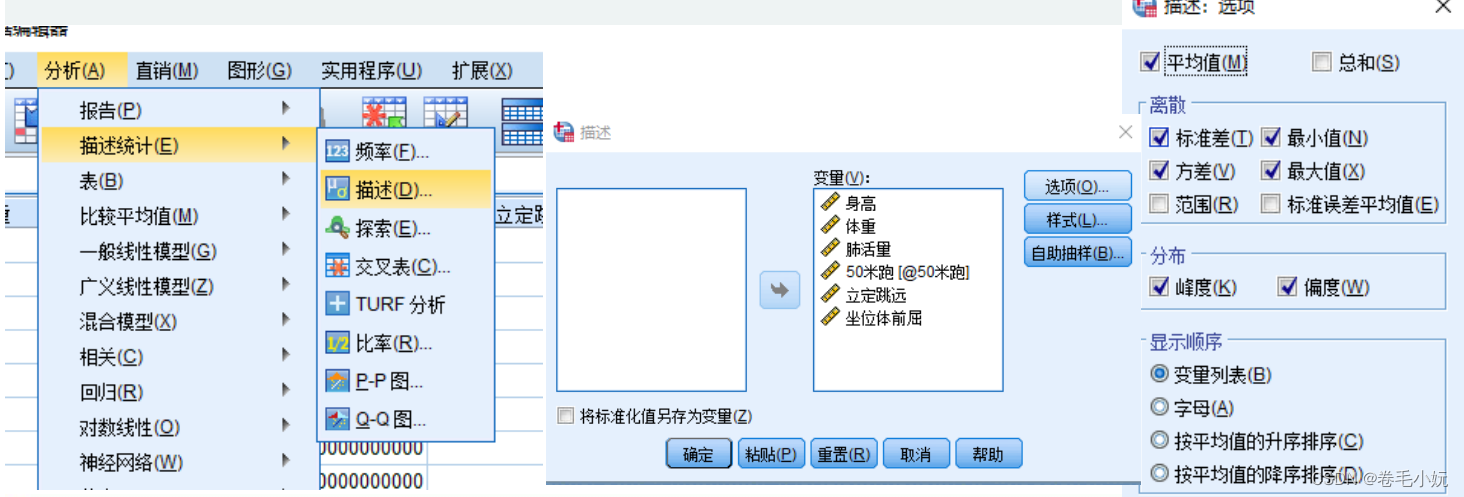
文件,导入数据,excel ,选好后打开,确定,分析,描述统计,描述,ctrl+A,移到右边,选项,勾选想要的,确定
“变量视图”中“测量”:
标度:数值型
有序:分类变量,甲乙丙丁之类有明确顺序的
名义:分类变量,无顺序,如:性别
2、计算皮尔逊相关系数
(1)先画出散点图,使相关性可视化,判断是否有线性关系
在SPSS中导入数据,图形,旧对话框,散点图/点图,矩阵散点图,定义,将指标移到“矩阵变量”框中,确定
如果两个变量线性相关,就能使用皮尔逊相关系数,否则不能。
(2)确定线性关系,计算相关系数(各列之间)
corrcoef函数:correlation coefficient 相关系数
R=corrcoef(A) A的相关系数矩阵(两列两列之间的相关系数)
R=corrcoef(A,B) 两个随机变量A,B(两个向量)之间的系数
R=[]
是第i 列和第j 列的相关系数
(3)美化相关系数表格,相关系数可视化
将相关系数复制到excel表格里,全选中,开始,格式,行高,50(使之呈现正方形),列宽10,两个居中,仅选中数据,保留四位小数,放大字体,条件格式,色阶,选一种(红白蓝),条件格式,管理规则,编辑规则,最小值类型修改为数字 值改为-1,最大值类型修改为数字 值改为1,中间值类型修改为数字 值改为0,确定,应用
3、对皮尔逊相关系数进行假设检验(前提:数据是正态分布)
(1)提出原假设 和备择假设
(两个假设是截然相反的)
(2)在原假设成立的前提下,利用我们要检验的量构造出一个符合某一分布的统计量
统计量相当于我们要检验的量的一个函数,里面不能有其他随机变量。
这里的分布一般有四种:标准正态分布、t 分布、 分布、F分布。
对于皮尔逊相关系数r ,在满足一定条件下,可以构造统计量: 
(n 是样本量,t 是服从自由度为n-2 的t 分布)
注意:皮尔逊相关系数假设检验需要满足的条件如下:
第一,实验数据通常假设是成对的来自于正态分布的总体。
因为我们在求皮尔 逊相关性系数以后,通常还会用t检验之类的方法来进行皮尔逊相关性系数检验, 而t检验是基于数据呈正态分布的假设的。
第二, 实验数据之间的差距不能太大。皮尔逊相关性系数受异常值的影响比较大。
第三:每组样本之间是独立抽样的。构造t统计量时需要用到 。
第二条和第三条在第一条成立的前提下默认成立,要验证第一条是否成立就要验证数据是否是正态分布的。
正态分布检验:
1、大样本 n>30:正态分布JB检验
(1)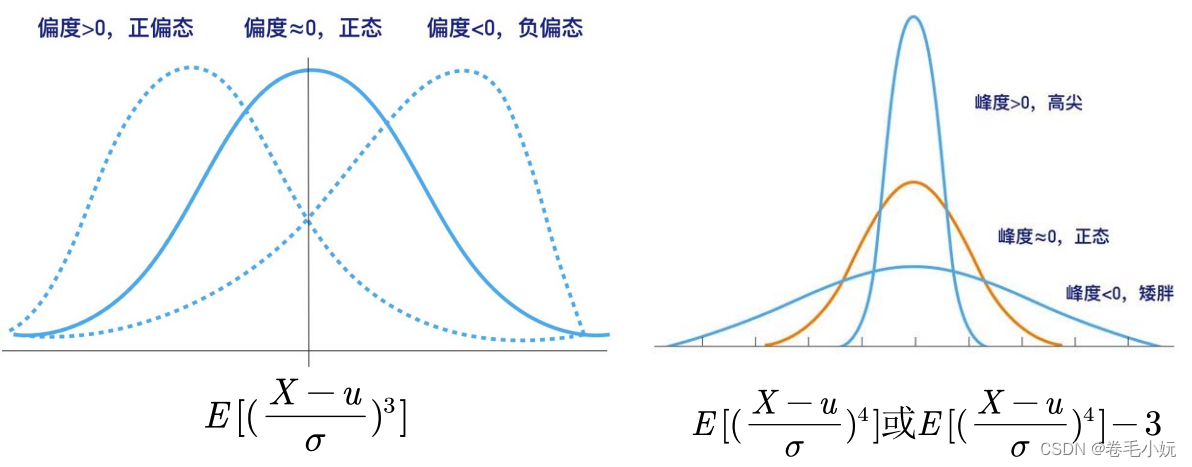
正态分布的偏度为0
正态分布的峰度为3 (有些地方定义的正态分布峰度为0) Matlab软件中使用的是第一种定义
(2)雅克‐贝拉检验(Jarque‐Bera test)
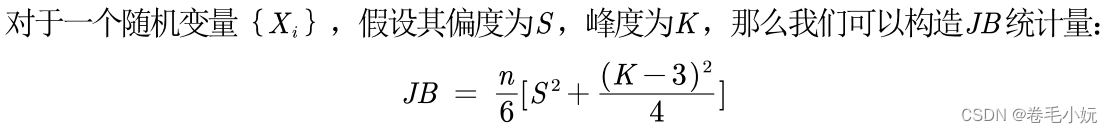

(3)正态分布JB检验的假设检验步骤:
step 1: :该随机变量服从正态分布
:该随机变量不服从正态分布
step 2:计算该变量的峰度、偏度,代入JB统计量,得到检验值,并计算出对应p值
step 3:若p<0.05,则可拒绝原假设(即在95%置信水平下我们拒绝原假设,即该随机变量不服从正态分布),否则不能拒绝原假设
[h ,p]=jbtest (x ,alpha)
x 是随机变量,只能一组一组,不能整个矩阵,可搭配循环使用
alpha 是显著性水平:1-置信水平=显著性水平,一般1-0.95=0.05
h=1,拒绝原假设(同时可以推出p<);h=0,不能拒绝原假设
2、小样本3≤n≤50:Shapiro-wilk检验
(1)夏皮洛‐威尔克检验步骤:
step 1: :该随机变量服从正态分布
:该随机变量不服从正态分布
step 2:计算出威尔克统计量(即检验值)后,得到相应p值
step 3:若p<0.05,则可拒绝原假设,否则不能拒绝原假设
(2)用SPSS
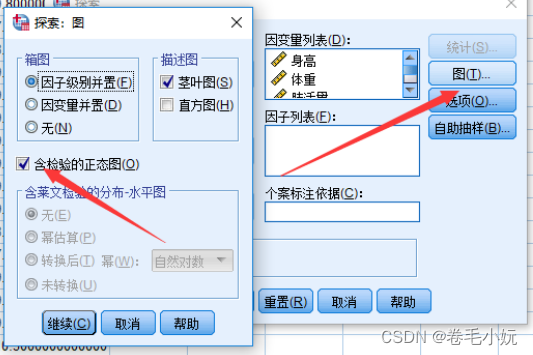
导入数据,分析,描述统计,探索,全选移到右边,图,勾选含检验的正=正态图,确定
(结果的最后一列“显著性”显示的是p值)

3、超大样本:Q-Q图
要利用Q‐Q图鉴别样本数据是否近似于正态分布,只需看Q‐Q图上的点 是否近似地在一条直线附近
qqplot(Test(:,1)) 第一列数据和正态分布的Q-Q图
4、
斯皮尔曼Spearman相关系数
1、一个数的等级:将它所在的一列数按照从小到大排序后,这个数所在的位置。eg: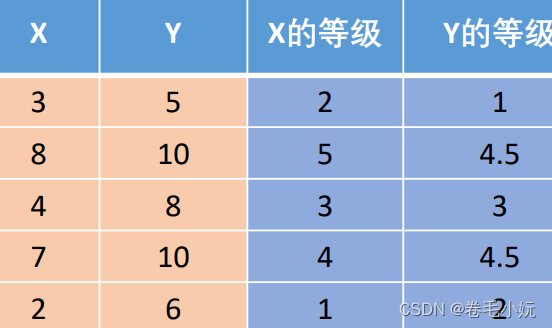
2、计算斯皮尔曼相关系数
(1)方法一:corrcoef(RX,RY) RX是一组数据X的等级 RY是一组数据Y的等级
(2)方法二:corr(X , Y , 'type' , 'Spearman') X、Y都是列向量
corr(X , 'type' , 'Spearman') 计算X各列之间的斯皮尔曼相关系数
3、斯皮尔曼相关系数的假设检验
(1)小样本,n≤30:直接查临界值表即可
样本相关系数r必须>=表中临界值,才能得出显著的结论(拒绝原假设)
(2)大样本: ![]()
(服从标准正态分布)
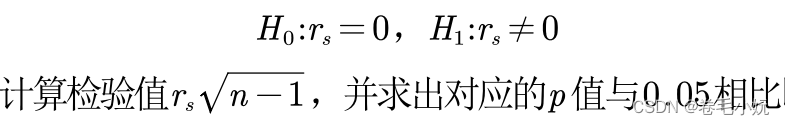
若p<0.05,则可拒绝原假设,否则不能拒绝原假设(如果是双侧检验,p值记得要x2)















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









