







目录
一、定义
相关关系是指变量的数值之间存在着依存关系,即一个变量的数值 会随着另一个变量或几个变量的数值变化而呈现出一定的变化规律。
很多时候,我们都需要分析数据之间的相关性,相关性分析是数据回归前提,具有相关性的数据可以进一步进行回归分析。
在 客观现实中,许多现象之间都存在着某种相互关联的关系。例如,
-
降雨 量与云层厚度之间的关系;
-
居民收入增长率与物价指数的关系;
-
人的身 高和体重的关系;
-
汽车行驶速度与行驶里程之间的关系;
-
圆的面积与圆 的半径之间的关系等。
现象与现象之间的关系如果能够使用数值来描 述,就形成了变量与变量之间的关系,但是这种依存关系不是严格的函 数关系。也就是说,当一个变量或几个变量取某一个数值时,对应变量 的数值也会变化,但是具体数值的函数变化规律是不确定的。例如,人的身高与体重之间的关系就属于相关关系,就全社会而言,对于具有同 样身高的人,体重的数值未必相同。也就是说,同样的身高数值对应的 体重数值是不确定的,但是体重数值却是随着“身高越高,体重越重”这 个一般的规律而变化,因此两者是一种相关关系;出租房的面积变量和 租金变量之间也属于相关关系,当给定一个出租房的面积时,出租房的 出租价格是波动和不确定的,但是房租会伴随着出租房面积的大小变化 而变化。
-
【注意事项】
相关分析研究的是两个变量的相关性,但你研究的两个变量必须是有关联的,如果你把历年人口总量和你历年的身高做相关性分析,分析结果会呈现显著地相关,但它没有实际的意义,因为人口总量和你的身高都是逐步增加的,从数据上来说是有一致性,但他们没有现实意义。
二、相关关系分类
如果变量之间存在相关关系,可能存在以下几种情况:1. 因果关系;2. 相互依存;3. 虚假相关关系;
相关关系从不同的角度有不同的分类方式。
-
首先是按照相关关系的强度进行分类,可以分为完全相关、弱相关 和不相关三种;
-
也能按照相关关系的方向进行分类,可 以分为正相关和负相关两种;
-
其次是按照相关关系的形态划分,可以分为线性相关关系和非线性相关关系;
-
最后还有一种相关关系的分类方式是按照变量的个数进行分类,可 以分为单相关关系、复相关关系和偏相关关系。
三、数据可视化(散点图)
散点图是描述相关关系类型的直观工具,特别适用于单相关关系分析,也就是只涉及两个变量的二元变量相关分析。
如下图所示,根据 散点在二维坐标系中的分布状态,分析者可以直观快速地初步判断两个 变量之间是否存在相关关系,以及存在何种相关关系。
判断相关关系类型是散点图的主要作用。
图:各种相关关系散点图
局限性:散点图只适用于两个变量的相关关系 判断(单相关关系),无法用于涉及多个变量的多重相关关系分析和偏相关关系分析。
四、相关分析
-
相关分析是对变量之间的相关关系进行量化处理的过程,不仅要确定相关关系的类型,还要确定相关关系的强度。
-
相关分析不是一个从无到有的过程,也就是说,实质上没有相关关系的变量不会由于相关分析 而形成相关关系,相关分析只是起到揭示变量之间原本存在的相关关系 的作用。
-
相关分析主要有以下几种类型:两变量的相关分析、偏相关分析和距离相关分析等。
4.1 量化指标
-
显著性检验概率p:反映 没有线性相关关系的可能性,若检验概率p<0.05,则表示两个数据序列之间存在线性相关关系;
-
相关系数r:反映相关关系的强度和方向;
确定简单线性相关系数及相伴概率值p是二元线性相关分析的主要 内容。
注意:相关关系 和 因果关系的区别。
4.1.1 相关系数
数据类型的不同直接导致适用的简单线性相关系数不同。
常用的 两个变量的简单线性相关系数有皮尔森(Pearson)相关系数、斯皮尔曼 (Spearman)相关系数和肯达尔(Kendall)相关系数。
-
这3种简单线性相关系数适用于不同的数据类型和总体情况。取值范围都在 [-1,1]
| 相关系数类型 |
数据类型 |
总体情况 |
原始数据要求 |
精确度 |
|---|---|---|---|---|
| 皮尔森(Pearson) |
定距数据/定比数据(连续型变量) |
正态分布 |
高 |
最高 |
| 斯皮尔曼 (Spearman) |
定距数据/定比数据(连续型变量) |
非正态分布 |
低 |
较差 |
| 肯达尔(Kendall) |
定序数据 |
非正态分布 |
低 |
较差 |
4.1.1.1 皮尔森(Pearson)相关系数
-
皮尔森相关系数适用于两列服从正态分布的定距数据(连续变量)。
-
定距数据的要求是由皮尔森相关系数的原理决定的,而要求正态 分布的理由则依旧老套,只有服从正态分布的总体才是稳定总体,样本才能比较真实地反映总体的情况,分析的结果才有意义。
-
除此之外,皮尔森相关系数还要求两列数据的个数相同且具有一一对应的关系。
假设有两个连续型变量X和Y,它们的数据是一一对 应的,即一个变量改变会引起另一个变量的改变,则表示两个变量相关 性的皮尔森相关系数r的计算公式为: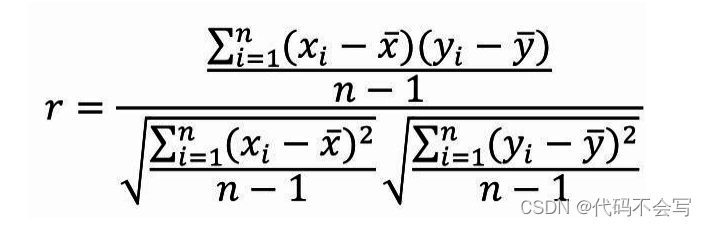
可以将上式进行简化:

![]() - 代表变量X的样本均值;
- 代表变量X的样本均值;
![]()
- 代表变量Y的样本均值;
![]()
代表变量X和变量Y的协方差。 ( 其中,n-1表示自由度,等于两个变量的样本配对数减去1。)
关于协方差
协方差也是常用的反映两个连续型变量的相关性指标,它刻画了两 个连续型变量的相关关系方向:如果协方差的结果为负数,说明两个连 续型变量之间可能是负相关关系;反之,如果协方差的结果为正数,那么两个变量之间可能是正相关关系。
虽然协方差能够反映两个连续型变 量的相关方向,但是它却不能直接用来度量两个连续型变量的相关程度,因为协方差的值与两个变量的测量单位密切
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









