







自监督学习
Downstream Task下游任务:评估任务(分类、目标检测、语义分割等),即建立在预训练模型之上的具体应用任务
Pretext Task:对目标任务有帮助的辅助任务
自监督学习主要是利用辅助任务(Pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。
也就是说自监督学习的监督信息不是人工标注的,而是算法在大规模无监督数据中自动构造监督信息,来进行监督学习或训练。
自监督学习最主要的目的就是学习到更丰富的语义表征,让模型懂得输入究竟是什么,从而帮助下游任务。
常见的Pretext Task
1. 预测旋转角度
2. 预测图像块位置
3. 预测图象拼图(jigsaw)
4. 预测缺失的像素
5. 通过图像重建进行Inpainting
6. 图像着色
7. 视频着色(视频着色与跟踪紧密相关)
如何评估自监督学习方法
1. pretext task 性能:从pretext task中学习好的特征提取器,使用少量有标签数据在目标任务上训练浅层网络
2. 特征质量:线性分类效果、聚类、t-SNE可视化
3. 鲁棒性和泛化性:不同数据集和不同变化
4. 计算效率:训练时间和训练所需资源
5. 迁移学习和Downstream Task性能
我们并不关心这些Pretext Task的性能,而是关心这些学习到的特征对于Downstream Task(分类、检测、分割)的效果,这也是对比学习的衡量标准。
找到合适的辅助任务(pretext)对于自监督学习是最需要解决的问题
数据和资源越多,自监督预训练的效果会更好
更通用的pretext task:对比学习
对比学习的形式化定义,即鼓励相似的实例在学习的嵌入空间中被映射得更近,同时将不相似的实例推得更远,对比学习允许模型捕获数据中的相关特征和相似性。
InfoNCE Loss:
N路softmax分类器的交叉熵损失,即学会从N个样本中找出正样本。
SimCLR
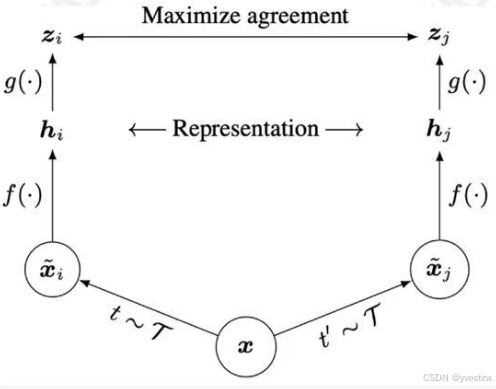
余弦相似度,通过数据增强生成正样本(随即裁剪、随机颜色失真、随机模糊)
SimCLR的思路:(1) 先sample一些图片组为batch;(2) 对batch里的image做两种不同的data augmentation;(3) 希望同一张图像、不同augmentation的结果相近,并互斥其他结果。
SimCLR设计选择:特征投影,利用投影头g(),可以在特征空间h中保留更多信息。投影网络获取编码器网络的输出并将其投影到低维空间,通常称为投影或嵌入空间。这个额外的投影步骤有助于增强所学习的表示的辨别能力。通过将表示映射到较低维的空间,投影网络降低了数据的复杂性和冗余,有助于更好地分离相似和不相似的实例。非线性投影头和强数据增强对于对比学习至关重要,相似的点投到低微空间中,会有较近的距离。
大型训练批量对SimCLR至关重要,但大批量会导致反向传播过程中占用大量内存,需要在TPU上进行分布式训练。
MoCo
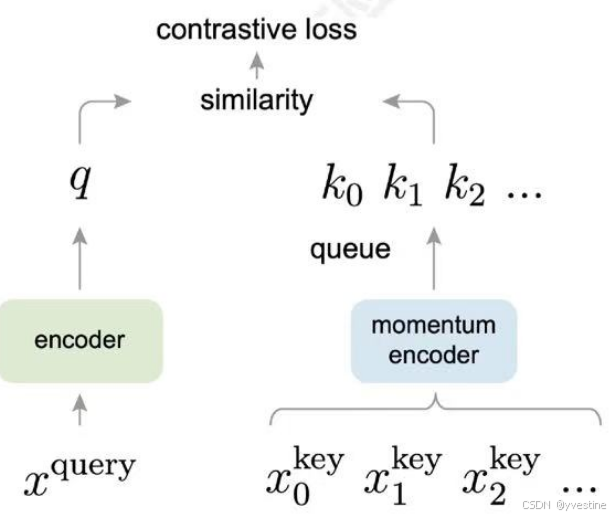
MoCo使用队列存储负样本,仅通过queries计算梯度并更新编码器,将batch大小与keys数量解耦,可以支持大量负样本,key编码器通过动量缓慢更新是新的输入
一个好的字典应该有两个特性:
1. 字典越大,key越多,所能表示的视觉信息、视觉特征就越丰富 ,这样拿query去做对比学习的时候,才越能学到图片的特征。
2. 编码的特征尽量保持一致性,字典里的key都应该用相同或者说相似的编码器去编码得到,这样字典里key的分布才更一致,这样拿query去对比学习的时候,才能更准确的找到正样本。
MoCo 的主要贡献就是把之前对比学习的一些方法都归纳总结成了一个字典查询的问题,并提出了队列存储和动量编码器。前者解决字典太大不好存储和训练的问题,后者解决了字典特征 不一致的问题;从而形成一个又大又一致的字典,能帮助模型更好的进行对比学习。

















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









