







import re
import csv
# 打开名为'a1.txt'的文件,并以只读模式('r')读取其内容。这里使用了'UTF-8'编码。
with open('网页源码a1.txt', 'r', encoding='UTF-8') as f:
# 读取文件的所有内容并赋值给变量'source'
source = f.read()
# 使用正则表达式查找所有匹配'region_header clearfix(.*?)thread_list_bottom clearfix'的字符串,并将结果赋值给变量'every_reply'。
# 这里使用的是非贪婪匹配,即匹配最少的字符以满足正则表达式。
every_reply = re.findall('region_header clearfix(.*?)thread_list_bottom clearfix', source, re.S)
# 打印匹配到的结果数量
print(len(every_reply))
# 遍历每个匹配结果
for each in every_reply:
# 在每个匹配结果中查找主题作者的用户名
t1 = re.findall('title="主题作者:(.*?)"', each, re.S)
# 在每个匹配结果中查找帖子的内容
t2 = re.findall('threadlist_abs_onlyline ">(.*?)<', each, re.S)
# 在每个匹配结果中查找回复的时间
t3 = re.findall('=2023-(.*?)_', each, re.S)
# 打印找到的主题作者的数量
print(len(t1))
# 创建一个空列表用于保存提取的信息
result_list = []
# 遍历每个主题作者的用户名
for i in range(len(t1)):
# 创建一个空字典用于保存提取的信息
result = {}
# 如果当前主题作者的帖子存在,则提取帖子的内容并去除其中的换行符
if i < len(t2):
result['username'] = t1[i]
result['content'] = t2[i].replace('\n ', '')
result['reply_time'] = t3[i]
# 将提取的信息添加到结果列表中
result_list.append(result)
# 打开名为'tieba.csv'的文件,并以写入模式('w')写入数据。这里使用了'UTF-8'编码。
with open('tieba.csv', 'w', encoding='UTF-8') as f:
# 创建一个CSV写入器,指定字段名为'username', 'content', 'reply_time'
writer = csv.DictWriter(f, fieldnames=['username', 'content', 'reply_time'])
# 写入CSV文件的头部(字段名)
writer.writeheader()
# 将提取的信息写入CSV文件中
writer.writerows(result_list)
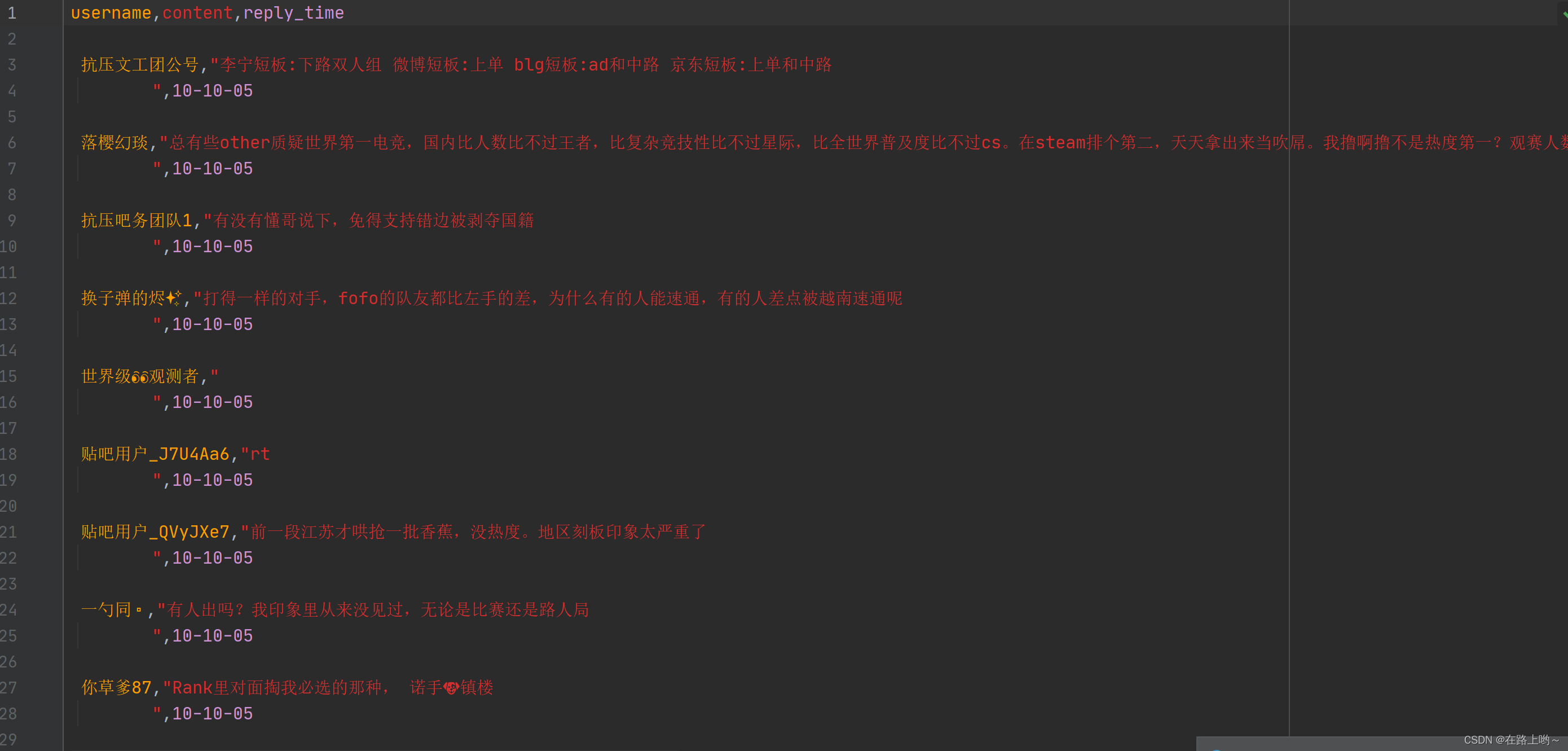
运行后'tieba.csv'的文件















 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









