







文章目录
字符串常量池
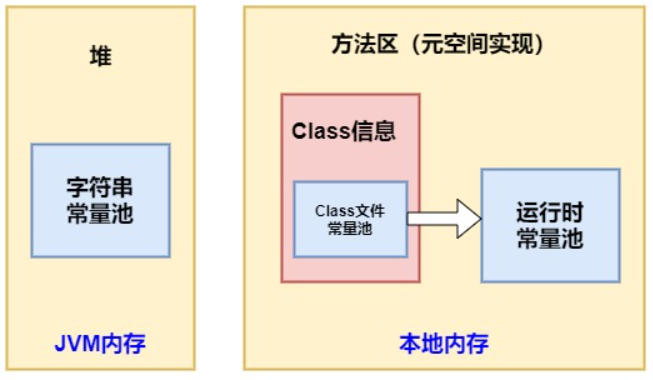
JVM中的三个常量池
- class 文件常量池:在 class 文件中保存了一份常量池(Constant Pool),主要存储编译时确定的数据,包括代码中的字面量(literal)和符号引用
- 运行时常量池:位于方法区中,全局共享,class 文件常量池中的内容会在类加载后存放到方法区的运行时常量池中。除此之外,在运行期间可以将新的变量放入运行时常量池中,相对 class 文件常量池而言运行时常量池更具备动态性
- 字符串常量池:位于堆中,全局共享,这里可以先粗略的认为它存储的是 String 对象的直接引用,而不是直接存放的对象,具体的实例对象是在堆中存放
字符串常量池的结构
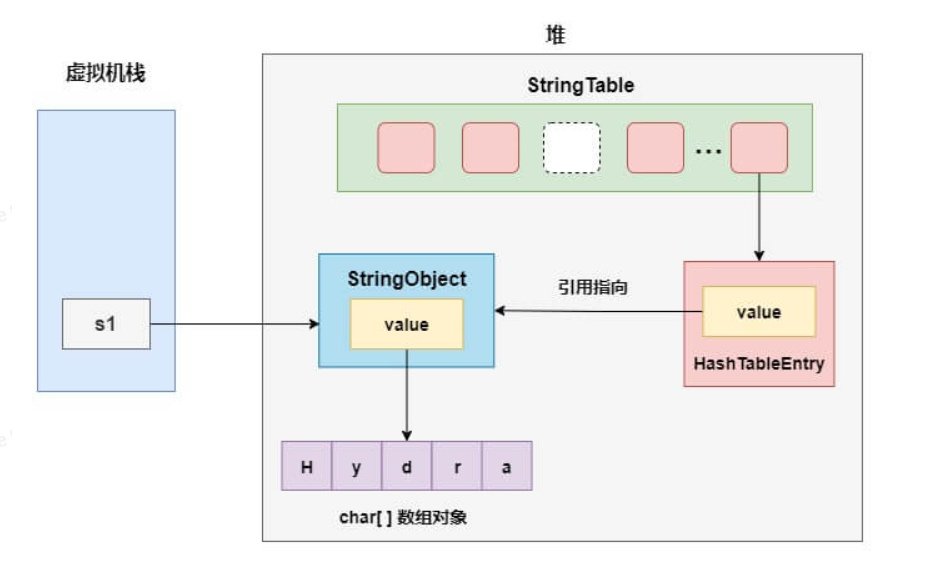
在 Hotspot JVM 中,字符串常量池StringTable的本质是一张HashTable
以字面量的方式创建 String 对象为例,字符串常量池以及堆栈的结构如下图所示
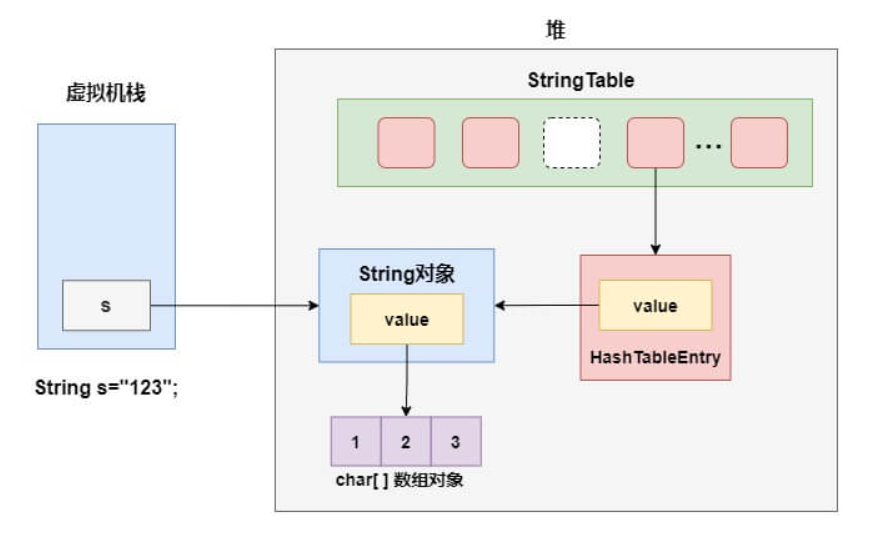
实际上字符串常量池HashTable采用的是数组加链表的结构,链表中的节点是一个个的HashTableEntry,而HashTableEntry中的value则存储了堆上 String 对象的引用。
这个字符串对象的引用是什么时候被放到字符串常量池中的?
具体可为两种情况:
- 使用字面量声明 String 对象时,也就是被双引号包围的字符串,在堆上创建对象,并驻留到字符串常量池中(注意这个用词)
- 调用intern()方法,当字符串常量池没有相等的字符串时,会保存该字符串的引用
注意!我们在上面用到了一个词驻留,这里对它进行一下规范。当我们说驻留一个字符串到字符串常量池时,指的是创建HashTableEntry,再使它的value指向堆上的 String 实例,并把HashTableEntry放入字符串常量池,而不是直接把 String 对象放入字符串常量池中。简单来说,可以理解为将 String 对象的引用保存在字符串常量池中。
第一种情况:
在类加载阶段,JVM 会在堆中创建对应这些 class 文件常量池中的字符串对象实例,并在字符串常量池中驻留其引用。
这一过程具体是在 resolve 阶段(个人理解就是 resolution 解析阶段)执行,但是并不是立即就创建对象并驻留了引用,因为在 JVM 规范里指明了 resolve 阶段可以是 lazy 的。CONSTANT_String 会在第一次引用该项的 ldc 指令被第一次执行到的时候才会 resolve。
就 HotSpot VM 的实现来说,加载类时字符串字面量会进入到运行时常量池,不会进入全局的字符串常量池,即在 StringTable 中并没有相应的引用,在堆中也没有对应的对象产生。
注释:LDC:将int(是绝对值大于2字节带符号的整数)、float或String型常量值从常量池压入栈顶(操作数栈)。
字面量声明 String
public static void main(String[] args) {
String s = "Hydra";
}
反编译生成的字节码文件:
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=2, args_size=1
0: ldc #2 // String Hydra
2: astore_1
3: return
解释一下上面的字节码指令:
- 0: ldc,查找后面索引为#2对应的项,#2表示常量在常量池中的位置。在这个过程中,会触发前面提到的lazy resolve,在 resolve 过程如果发现StringTable已经有了内容匹配的 String 引用,则直接返回这个引用,反之如果StringTable里没有内容匹配的 String 对象的引用,则会在堆里创建一个对应内容的 String 对象,然后在StringTable驻留这个对象引用,并返回这个引用,之后再压入操作数栈中
- 2: astore_1,弹出栈顶元素,并将栈顶引用类型值保存到局部变量 1 中,也就是保存到变量s中
- 3: return,执行void函数返回
可以看到,在这种模式下,只有堆中创建了一个"Hydra"对象,在字符串常量池中驻留了它的引用。并且,如果再给字符串s2、s3也用字面量的形式赋值为"Hydra",它们用的都是堆中的唯一这一个对象。
构造方法创建字符串
public static void main(String[] args) {
String s = new String("Hydra");
}
同样反编译这段代码的字节码文件:
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=2, args_size=1
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String Hydra
6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
9: astore_1
10: return
看一下和之前不同的字节码指令部分:
- 0: new,在堆上创建一个 String 对象,并将它的引用压入操作数栈,注意这时的对象还只是一个空壳,并没有调用类的构造方法进行初始化
- 3: dup,复制栈顶元素,也就是复制了上面的对象引用,并将复制后的对象引用压入栈顶。这里之所以要进行复制,是因为之后要执行的构造方法会从操作数栈弹出需要的参数和这个对象引用本身(这个引用起到的作用就是构造方法中的this指针),如果不进行复制,在弹出后会无法得到初始化后的对象引用
- 4: ldc,在堆上创建字符串对象,驻留到字符串常量池,并将字符串的引用压入操作数栈
- 6: invokespecial,执行 String 的构造方法,这一步执行完成后得到一个完整对象
到这里,我们可以看到一共创建了两个String 对象,并且两个都是在堆上创建的,且字面量方式创建的 String 对象的引用被驻留到了字符串常量池中。而栈里的s只是一个变量,并不是实际意义上的对象,我们不把它包括在内。
当字符串常量池已经驻留过某个字符串引用,再使用构造方法创建 String
public static void main(String[] args) {
String s = "Hydra";
String s2 = new String("Hydra");
}
答案是只创建一个对象,对于这种重复字面量的字符串,看一下反编译后的字节码指令:
Code:
stack=3, locals=3, args_size=1
0: ldc #2 // String Hydra
2: astore_1
3: new #3 // class java/lang/String
6: dup
7: ldc #2 // String Hydra
9: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
12: astore_2
13: return
可以看到两次执行ldc指令时后面索引相同,而ldc判断是否需要创建新的 String 实例的依据是根据在第一次执行这条指令时,StringTable是否已经保存了一个对应内容的 String 实例的引用。所以在第一次执行ldc时会创建 String 实例,而在第二次ldc就会直接返回而不需要再创建实例了。
intern
String 的intern()是一个本地方法,可以强制将 String 驻留进入字符串常量池,可以分为两种情况:
- 如果字符串常量池中已经驻留了一个等于此 String 对象内容的字符串引用,则返回此字符串在常量池中的引用
- 否则,在常量池中创建一个引用指向这个 String 对象,然后返回常量池中的这个引用
好了,我们下面看一下这段代码,它的运行结果应该是什么?
public static void main(String[] args) {
String s1 = new String("Hydra");
String s2 = s1.intern();
System.out.println(s1 == s2);
System.out.println(s1 == "Hydra");
System.out.println(s2 == "Hydra");
}
false
false
true
用一张图来描述它们的关系,就很容易明白了:
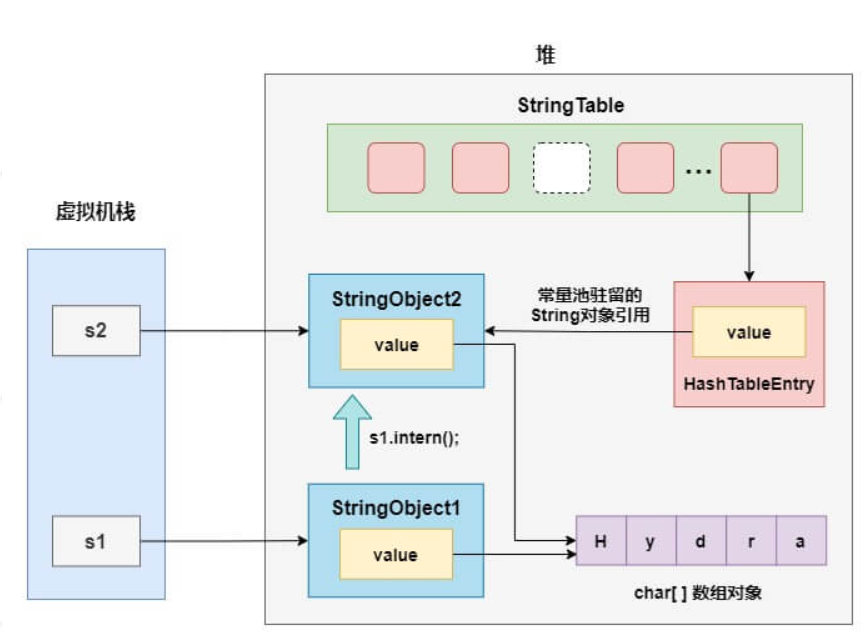
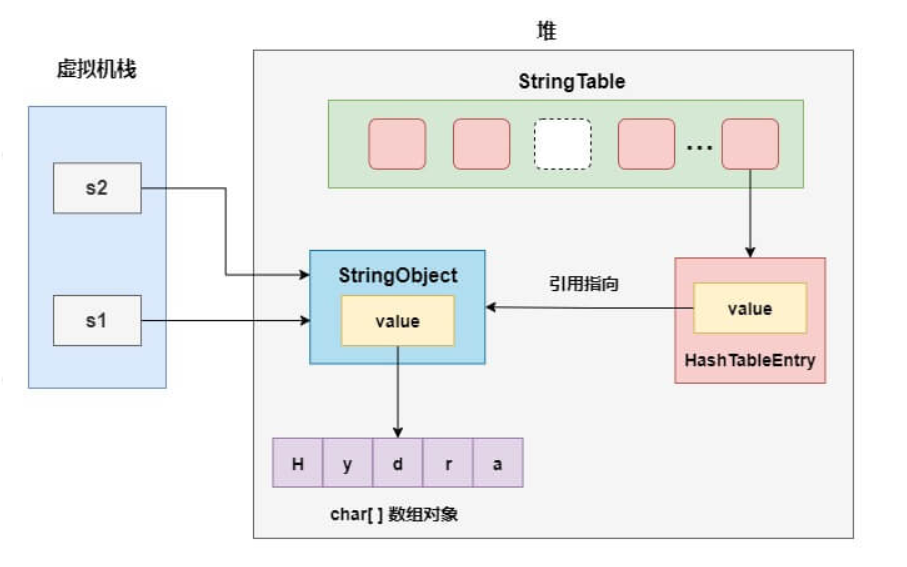
- 在创建s1的时候,其实堆里已经创建了两个字符串对象StringObject1和StringObject2,并且在字符串常量池中驻留了StringObject2
- 当执行s1.intern()方法时,字符串常量池中已经存在内容等于"Hydra"的字符串StringObject2,直接返回这个引用并赋值给s2
- s1和s2指向的是两个不同的 String 对象,因此返回 false
- s2指向的就是驻留在字符串常量池的StringObject2,因此s2=="Hydra"为 true,而s1指向的不是常量池中的对象引用所以返回 false
上面是常量池中已存在内容相等的字符串驻留的情况,下面再看看常量池中不存在的情况,看下面的例子:
public static void main(String[] args) {
String s1 = new String("Hy") + new String("dra");
s1.intern();
String s2 = "Hydra";
System.out.println(s1 == s2);
}
true
执行结果:
简单分析一下这个过程,第一步会在堆上创建"Hy"和"dra"的字符串对象,并驻留到字符串常量池中。
接下来,完成字符串的拼接操作,前面我们说过,实际上 jvm 会把拼接优化成StringBuilder的append方法,并最终调用toString方法返回一个 String 对象。在完成字符串的拼接后,字符串常量池中并没有驻留一个内容等于"Hydra"的字符串。
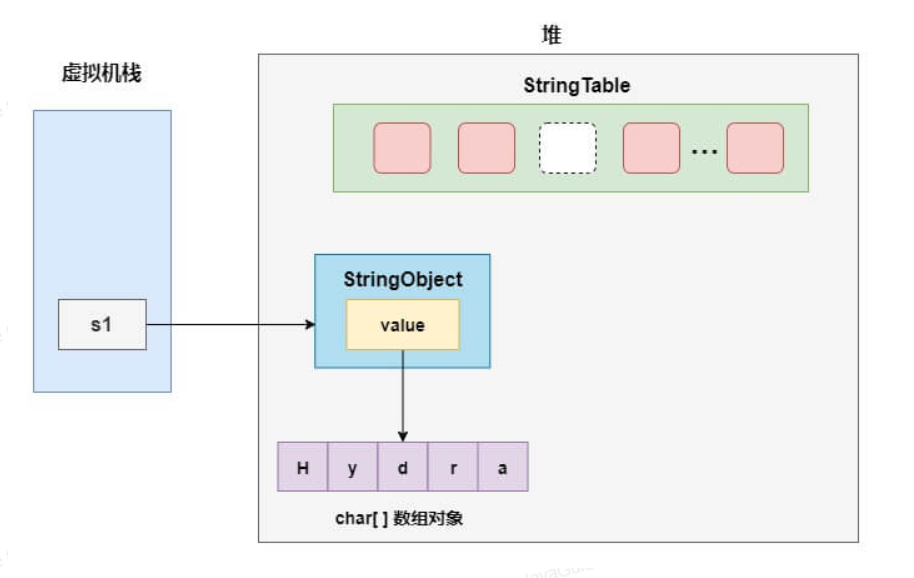
所以,执行s1.intern()时,会在字符串常量池创建一个引用,指向前面StringBuilder创建的那个字符串,也就是变量s1所指向的字符串对象。在《深入理解 Java 虚拟机》这本书中,作者对这进行了解释,因为从 jdk7 开始,字符串常量池就已经移到了堆中,那么这里就只需要在字符串常量池中记录一下首次出现的实例引用即可。
最后,当执行String s2 = "Hydra"时,发现字符串常量池中已经驻留这个字符串,直接返回对象的引用,因此s1和s2指向的是相同的对象。
常量折叠
解决了前面数 String 对象个数的问题,那么我们接着加点难度,看看下面这段代码,创建了几个对象?
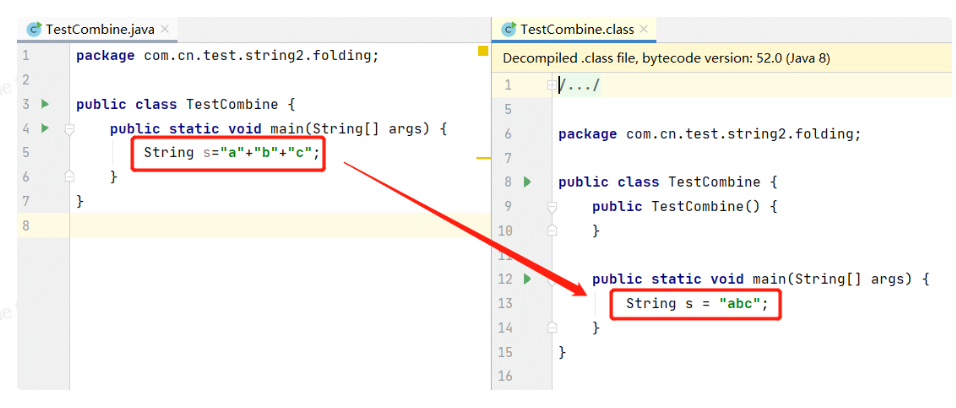
String s="a"+"b"+"c";
先揭晓答案,只创建了一个对象! 可以直观的对比一下源代码和反编译后的字节码文件:
如果使用前面提到过的 debug 小技巧,也可以直观的看到语句执行完后,只增加了一个 String 对象,以及一个 char 数组对象。并且这个字符串就是驻留在字符串常量池中的那一个,如果后面再使用字面量"abc"的方式声明一个字符串,指向的仍是这一个,堆中 String 对象的数量不会发生变化。
至于为什么源代码中字符串拼接的操作,在编译完成后会消失,直接呈现为一个拼接后的完整字符串,是因为在编译期间,应用了编译器优化中一种被称为常量折叠(Constant Folding)的技术。
常量折叠会将编译期常量的加减乘除的运算过程在编译过程中折叠。编译器通过语法分析,会将常量表达式计算求值,并用求出的值来替换表达式,而不必等到运行期间再进行运算处理,从而在运行期间节省处理器资源。
而上边提到的编译期常量的特点就是它的值在编译期就可以确定,并且需要完整满足下面的要求,才可能是一个编译期常量:
- 被声明为final
- 基本类型或者字符串类型
- 声明时就已经初始化
- 使用常量表达式进行初始化
下面我们通过几段代码加深对它的理解:
public static void main(String[] args) {
final String h1 = "hello";
String h2 = "hello";
String s1 = h1 + "Hydra";
String s2 = h2 + "Hydra";
System.out.println((s1 == "helloHydra"));
System.out.println((s2 == "helloHydra"));
}
true
false
代码中字符串h1和h2都使用常量赋值,区别在于是否使用了final进行修饰,对比编译后的代码,s1进行了折叠而s2没有,可以印证上面的理论,final修饰的字符串变量才有可能是编译期常量。
再看一段代码,执行下面的程序,结果会返回什么呢?
public static void main(String[] args) {
String h ="hello";
final String h2 = h;
String s = h2 + "Hydra";
System.out.println(s=="helloHydra");
}
答案是false,因为虽然这里字符串h2被final修饰,但是初始化时没有使用常量表达式,因此它也不是编译期常量。那么,有的小伙伴就要问了,到底什么才是常量表达式呢?
在Oracle官网的文档中,列举了很多种情况,下面对常见的情况进行列举(除了下面这些之外官方文档上还列举了不少情况,如果有兴趣的话,可以自己查看):
- 基本类型和 String 类型的字面量
- 基本类型和 String 类型的强制类型转换
- 使用+或-或!等一元运算符(不包括++和–)进行计算
- 使用加减运算符+、-,乘除运算符*、 / 、% 进行计算
- 使用移位运算符 >>、 <<、 >>>进行位移操作
- ……
至于我们从文章一开始就提到的字面量(literals),是用于表达源代码中一个固定值的表示法,在 Java 中创建一个对象时需要使用new关键字,但是给一个基本类型变量赋值时不需要使用new关键字,这种方式就可以被称为字面量。Java 中字面量主要包括了以下类型的字面量:
//整数型字面量:
long l=1L;
int i=1;
//浮点类型字面量:
float f=11.1f;
double d=11.1;
//字符和字符串类型字面量:
char c='h';
String s="Hydra";
//布尔类型字面量:
boolean b=true;
再说点题外话,和编译期常量相对的,另一种类型的常量是运行时常量,看一下下面这段代码:
final String s1="hello "+"Hydra";
final String s2=UUID.randomUUID().toString()+"Hydra";
编译器能够在编译期就得到s1的值是hello Hydra,不需要等到程序的运行期间,因此s1属于编译期常量。而对s2来说,虽然也被声明为final类型,并且在声明时就已经初始化,但使用的不是常量表达式,因此不属于编译期常量,这一类型的常量被称为运行时常量。
print优化String空值
下面这段代码最终会打印什么?
public class Test1 {
private static String s1;
private static String s2;
public static void main(String[] args) {
String s= s1+s2;
System.out.println(s);
}
}
运行之后,你会发现打印了nullnull:
在分析这个结果之前,先扯点别的,说一下为空null的字符串的打印原理。查看一下PrintStream类的源码,print方法在打印null前进行了处理:
public void print(String s) {
if (s == null) {
s = "null";
}
write(s);
}
因此,一个为null的字符串就可以被打印在我们的控制台上了。
再回头看上面这道题,s1和s2没有经过初始化所以都是空对象null,需要注意这里不是字符串的"null"。
字符串相加
编译器会对String字符串相加的操作进行优化,会把这一过程转化为StringBuilder的append方法。那么,让我们再看看append方法的源码:
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
//...
}
如果append方法的参数字符串为null,那么这里会调用其父类AbstractStringBuilder的appendNull方法:
private AbstractStringBuilder appendNull() {
int c = count;
ensureCapacityInternal(c + 4);
final char[] value = this.value;
value[c++] = 'n';
value[c++] = 'u';
value[c++] = 'l';
value[c++] = 'l';
count = c;
return this;
}
这里的value就是底层用来存储字符的char类型数组,到这里我们就可以明白了,其实StringBuilder也对null的字符串进行了特殊处理,在append的过程中如果碰到是null的字符串,那么就会以"null"的形式被添加进字符数组,这也就导致了两个为空null的字符串相加后会打印为"nullnull"。
String是不可变的
如何改变一个 String 字符串的值,这道题可能看上去有点太简单了,像下面这样直接赋值不就可以了吗?
String s="Hydra";
s="Trunks";
恭喜你,成功掉进了坑里!在回答这道题之前,我们需要知道 String 是不可变的,打开 String 的源码在开头就可以看到:
private final char value[];
可以看到,String 的本质其实是一个char类型的数组,然后我们再看两个关键字。先看final,我们知道final在修饰引用数据类型时,就像这里的数组时,能够保证指向该数组地址的引用不能修改,但是数组本身内的值可以被修改。
也就是说,即使被final修饰,但是我直接操作数组里的元素还是可以的,所以这里还加了另一个关键字private,防止从外部进行修改。此外,String 类本身也被添加了final关键字修饰,防止被继承后对属性进行修改。
到这里,我们就可以理解为什么 String 是不可变的了,那么在上面的代码进行二次赋值的过程中,发生了什么呢?答案很简单,前面的变量s只是一个 String 对象的引用,这里的重新赋值时将变量s指向了新的对象。
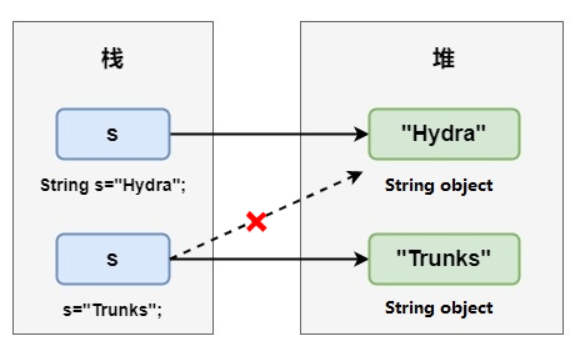
上面白话了一大顿,其实是我们可以通过比较hashCode的方式来看一下引用指向的对象是否发生了改变,修改一下上面的代码,打印字符串的hashCode:
那么,回到上面的问题,如果我想要改变一个 String 的值,而又不想把它重新指向其他对象的话,应该怎么办呢?答案是利用反射修改char数组的值:
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
String s="Hydra";
System.out.println(s+": "+s.hashCode());
Field field = String.class.getDeclaredField("value");
field.setAccessible(true);
field.set(s,new char[]{'T','r','u','n','k','s'});
System.out.println(s+": "+s.hashCode());
}
















 2361
2361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









