






高速缓存(cache) 概念和原理
cache基本思想
▪ cache 存储器( Cache memories )
▪ 在处理器附近增加一个小容量快速存储器(cache)
▪ 基于SRAM,由硬件自动管理
cache基本思想:
▪ 频繁访问的数据块存储在cache中
▪ CPU 首先在cache中查找想访问的数据,而不是直接访问主存
▪ 我们希望被访问数据存放在cache中

Cache 基本概念:块(block)
CPU 从内存中读取数据到 Cache 的时候,并不是一个字节一个字节读取,而是一块一块的方式来读取数据的,这一块一块的数据被称为 CPU Line(缓存行),所以 CPU Line 是 CPU 从内存读取数据到 Cache 的单位。

访问block b 不在 Cache 中,从内存中取出 block b ,将 block b 放置在 cache 中:
•放置策略:
决定 block b 将被放置在哪里
•替换策略:
决定哪个 block 将会被替换
Cache 层次结构举例 :Intel Core i7

dCache(数据缓存) 和 iCache(指令缓存)
Cache 的关键问题
如何判断一个数据在cache中
▪ 数据查找 Data Identification
如需访问的数据在cache中,存放在什么地方
▪ 地址映射 Address Mapping
Cache满了以后如何处理
▪ 替换策略 Placement Policy
如何保证cache与memory的一致性
▪ 写入策略 Write Policy
主存与Cache的地址映射
地址映射:利用某种方法或者规则将主存块定位到cache





主存与cache地址映射
▪ 直接 (direct mapped)
访问过程:
优点
▪ 地址变换速度快,一对一映射
▪ 替换算法简单、容易实现
缺点
▪ 容易冲突,cache利用率低
▪ 命中率低


▪ 全相联 (fully-associated)
主存中任何一块均可定位于Cache中的任意一块,可提高命中率,但是硬件开销增加
全相联映射的优缺点
▪ 一对多映射
▪ cache全部装满后才会出现块冲突
▪ 块冲突的概率低,cache利用率高
▪ 相应的替换算法复杂

▪ 组相联 (set-associated)


组相联映射的特例
▪ 直接映射(direct mapped)
▪ 全相联映射(fully-associated)

组关联映射cache的地址范围



组相联映射应用场合
Cache的容量
▪ 小:采用组相联映射或全相联映射
▪ 大:采用直接映射方式,查找速度快,命中率相对前者稍低
Cache 的访问速度
▪ 要求高的场合采用直接映射
▪ 要求低的场合采用组相联或全相联映射
Cache 伪共享
假设有一个双核心的 CPU,这两个 CPU 核心并行运行着两个不同的线程,它们同时从内存中读取两个不同的数据,分别是类型为 long 的变量 A 和 B,这个两个数据的地址在物理内存上是连续的,如果 Cahce Line 的大小是 64 字节,并且变量 A 在 Cahce Line 的开头位置,那么这两个数据是位于同一个 Cache Line 中,又因为 CPU Line 是 CPU 从内存读取数据到 Cache 的单位,所以这两个数据会被同时读入到了两个 CPU 核心中各自 Cache 中。

如果这两个不同核心的线程分别修改不同的数据,比如 1 号 CPU 核心的线程只修改了 变量 A,或 2 号 CPU 核心的线程的线程只修改了变量 B,会发生什么呢?
分析伪共享的问题
1 号核心需要修改变量 A,发现此 Cache Line 的状态是「共享」状态,所以先需要通过总线发送消息给 2 号核心,通知 2 号核心把 Cache 中对应的 Cache Line 标记为「已失效」状态,然后 1 号核心对应的 Cache Line 状态变成「已修改」状态,并且修改变量 A。

之后,2 号核心需要修改变量 B,此时 2 号核心的 Cache 中对应的 Cache Line 是已失效状态,另外由于 1 号核心的 Cache 也有此相同的数据,且状态为「已修改」状态,所以要先把 1 号核心的 Cache 对应的 Cache Line 写回到内存,然后 2 号核心再从内存读取 Cache Line 大小的数据到 Cache 中,最后把变量 B 修改到 2 号核心的 Cache 中,并将状态标记为「已修改」状态。

1 号和 2 号 CPU 核心这样持续交替的分别修改变量 A 和 B,Cache 并没有起到缓存的效果;因为同时归属于一个 Cache Line ,这个 Cache Line 中的任意数据被修改后,都会相互影响
多个线程同时读写同一个 Cache Line 的不同变量时,而导致 CPU Cache 失效的现象称为伪共享(False Sharing)。
避免伪共享的方法
对于多个线程共享的热点数据,应该避免这些数据刚好在同一个 Cache Line 中,否则就会出现为伪共享的问题。
在 Linux 内核中存在 __cacheline_aligned_in_smp 宏定义,是用于解决伪共享的问题。

如果在多核(MP)系统里,该宏定义是 __cacheline_aligned,也就是 Cache Line 的大小;
而如果在单核系统里,该宏定义是空的;
struct test{
int a;
int b;
}
//针对在同一个 Cache Line 中的共享的数据,如果在多核之间竞争比较严重,采用宏定义使得变量在 Cache Line 里是对齐的
struct test{
int a;
int b __cacheline_aligned_in_smp;
}
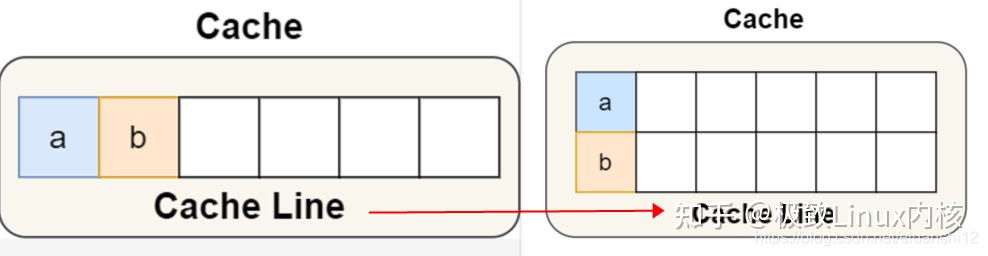
避免 Cache 伪共享实际上是用空间换时间的思想,浪费一部分 Cache 空间,从而换来性能的提升。
Java 并发框架 Disruptor 使用「字节填充 + 继承」的方式,来避免伪共享
Disruptor 中RingBuffer 类

RingBufferPad 类里 7 个 long 类型,用来提升性能
CPU Cache 从内存读取数据的单位是 CPU Line,一般 64 位 CPU 的 CPU Line 的大小是 64 个字节,一个 long 类型的数据是 8 个字节,所以 CPU 一下会加载 8 个 long 类型的数据。
根据 JVM 对象继承关系中父类成员和子类成员,内存地址是连续排列布局的,因此 RingBufferPad 中的 7 个 long 类型数据作为 Cache Line 前置填充,而 RingBuffer 中的 7 个 long 类型数据则作为 Cache Line 后置填充,这 14 个 long 变量没有任何实际用途,更不会对它们进行读写操作。

另外,RingBufferFelds 里面定义的这些变量都是 final 修饰的,意味着第一次加载之后不会再修改, 又由于「前后」各填充了 7 个不会被读写的 long 类型变量,所以无论怎么加载 Cache Line,这整个 Cache Line 里都没有会发生更新操作的数据,于是只要数据被频繁地读取访问,就自然没有数据被换出 Cache 的可能,也因此不会产生伪共享的问题。














 5644
5644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









