






针对字体反爬,接上篇文章(字体反爬:数字),在进行数据解析时,会出现类似汉字的文字,这就是网页对数据的一种加密方式。
 图1
图1
我们在开发者工具栏定位到需要的数据后,右侧找到font-family(图2),在这个字典里面就是对字体的一个显示。随后我们随意对里面的一个属性进行复制,在元素面板里找到相应关键字的标签,在它对应的上一级标签里面,会出现数字、字符串和符号组成的一串代码,这实际就是url编码,里面包含页面所有的数据(图3)
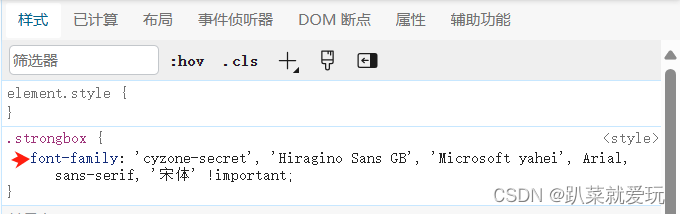 图2
图2
 图3
图3
在发现unescape是url编码之后,就需要进行解码,这里是使用了正则表达式进行数据匹配。然后,回到font-family这段,通过观察,发现了base64,相信都不陌生,这就不多赘述了,具体代码如下。
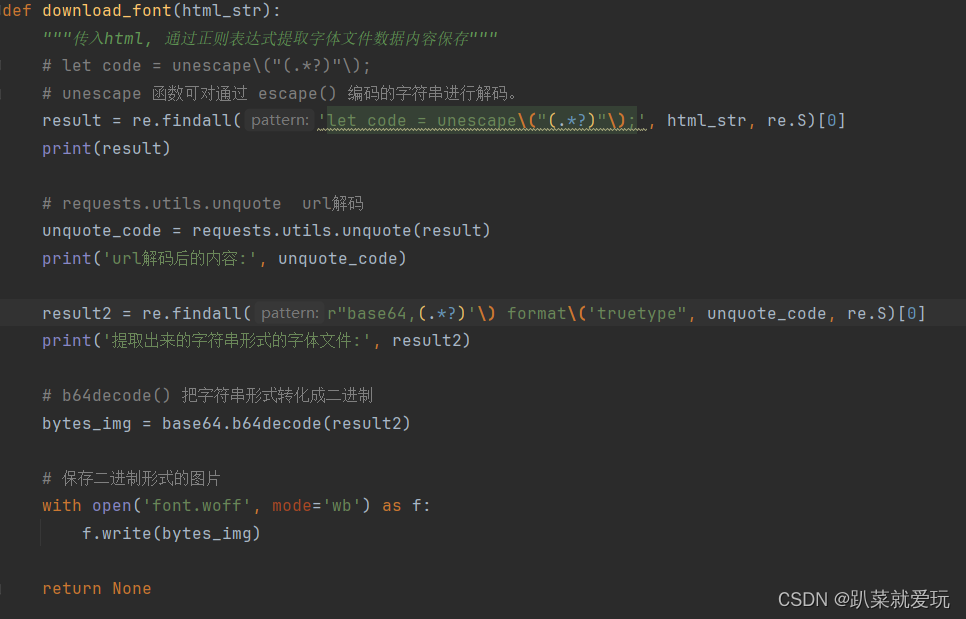 图4
图4
到这里,我们就获取到了字体的.woff文件,接下来就是获取字体映射规则和构建字体映射规则,接上篇(字体反爬:数字)。与上篇不同的是这里替换字体的方式不同,下面的mapping值是指自己构建的字体映射规则,string是指解析数据时得到的汉字乱码(如图1),而后在调用函数将参数进行实例化,用for循环的原因是乱码数据不止一个。
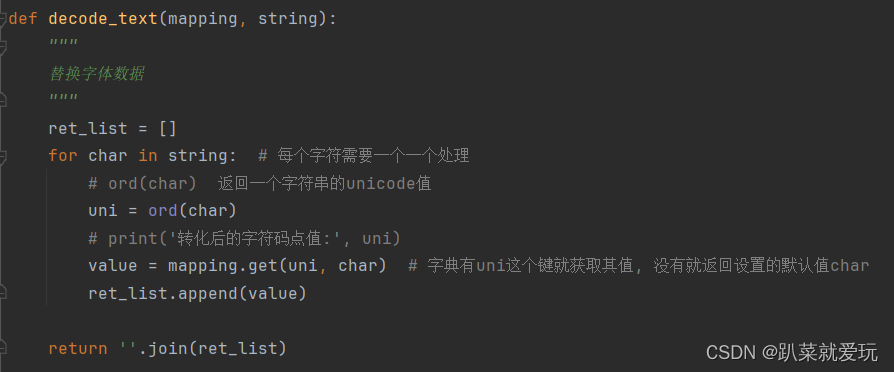 图5
图5
 图6
图6
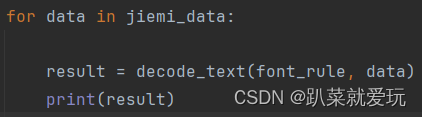 图7
图7

















 1248
1248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









