 MySQL数据库复合查询、索引及事务详解
MySQL数据库复合查询、索引及事务详解




数据库两个编码集:
1.编码集 --写
2.校验集 --查
校验集合utf8_bin区分大小写
 导出数据库
导出数据库
 恢复
恢复
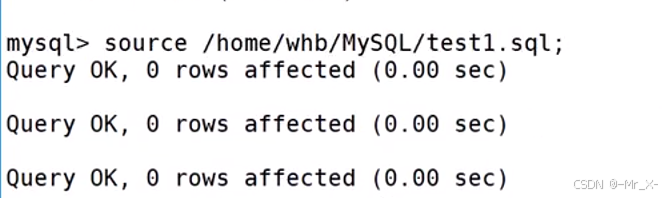
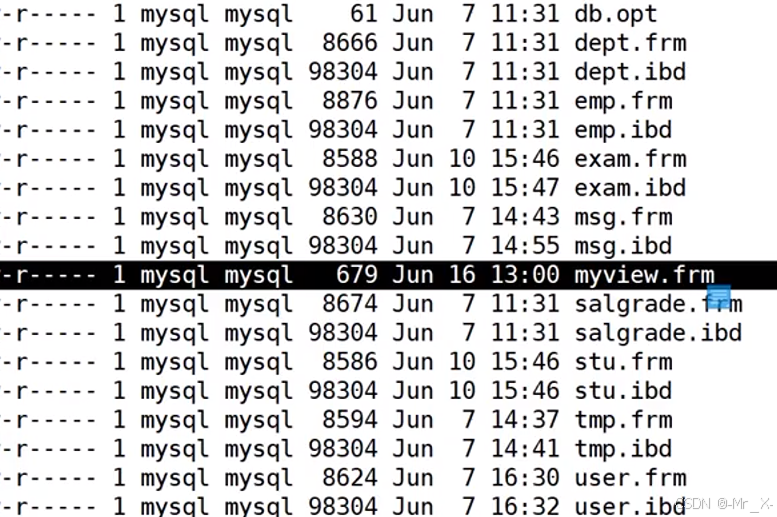
不同的存储引擎建的表对应在linux下的文件结构
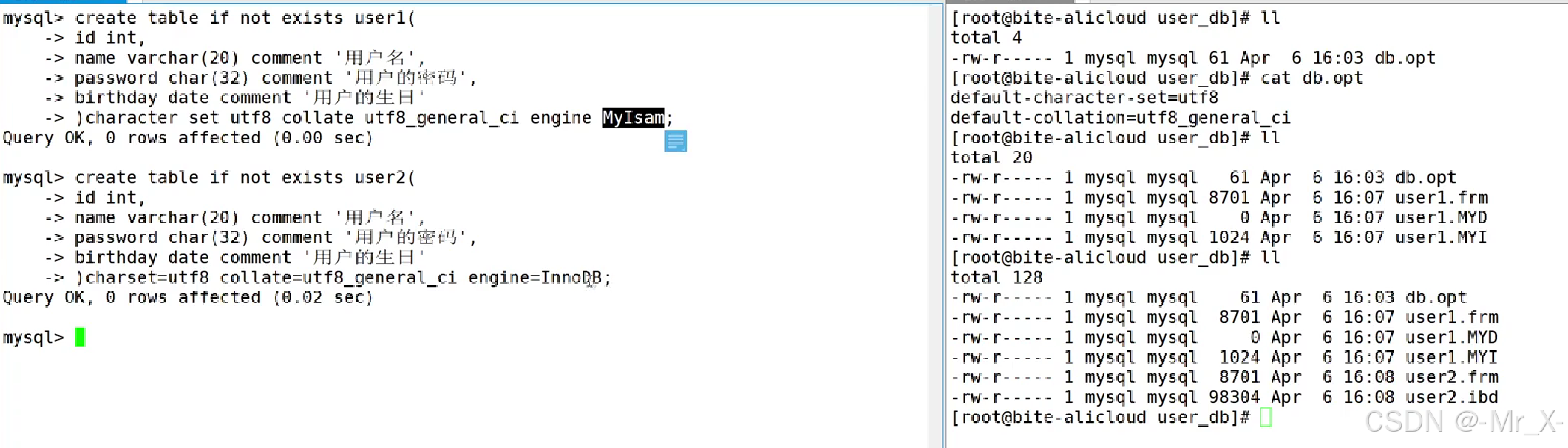
查详细信息

查看sql
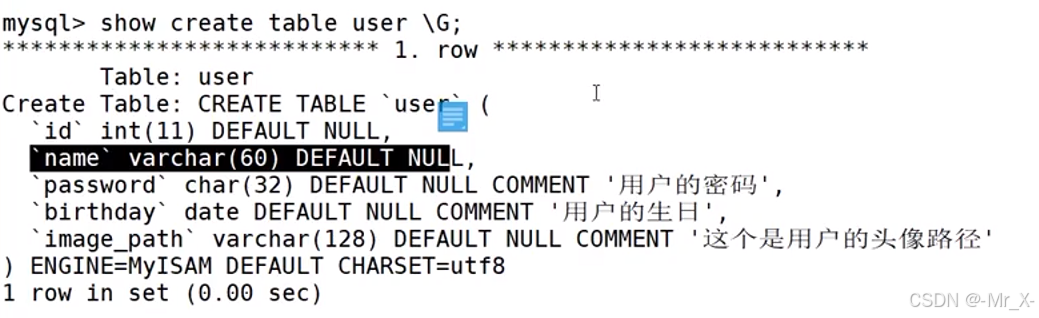
修改表
 alter table users rename to new_users; -- 修改表名
alter table users rename to new_users; -- 修改表名
数据类型及其说明:
bit是位数(默认是1位)显示默认按照ASCII码显示
float(m整型和浮点数字位数的个数,d小数位数-这个位可以多会自动四舍五入)
decimal不会出现精度损失
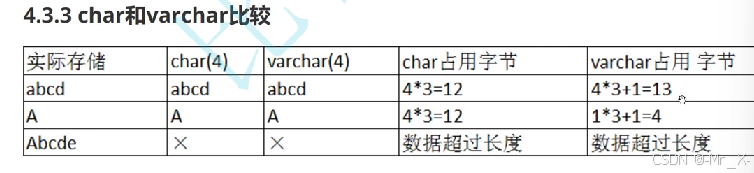
char utf8下一个汉字占3个字节,但mysql说的char是字符长度不是字节
varchar 最大的是65535字节 折合21845个字符不能超过21844
当插入或者更新的时候时间戳会自动变化 !!!!!!

枚举:
enum插入0会报错,1,2,3是下标
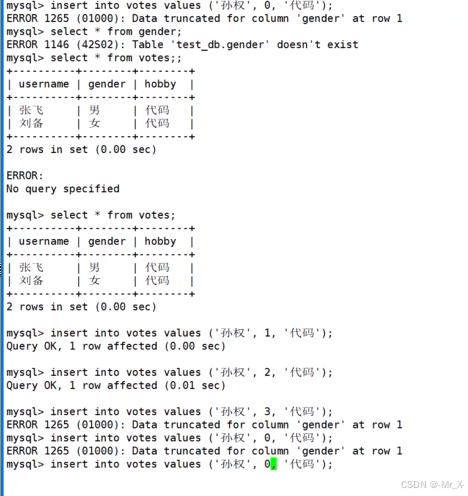

set中插入0会为空,1,2,3对应他们二进制后高低位所对应的枚举类型(位图)
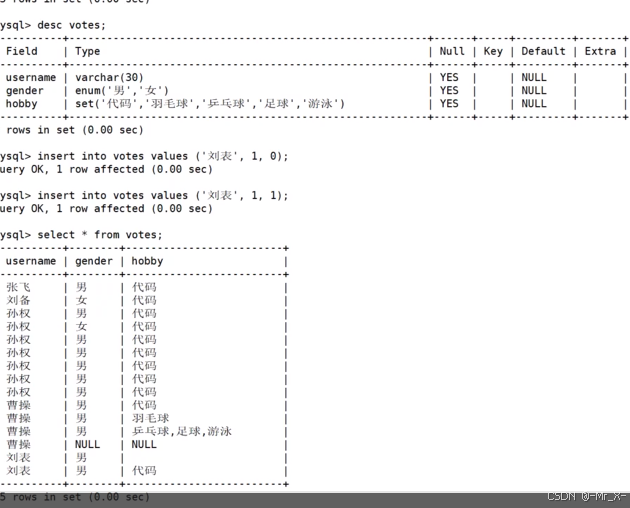
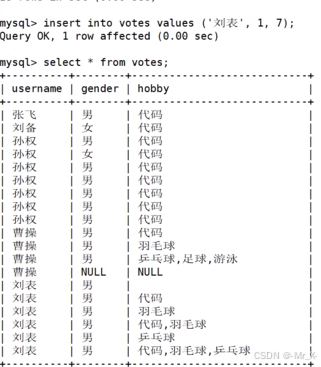
枚举类型的查询:可以使用find_in_set查询
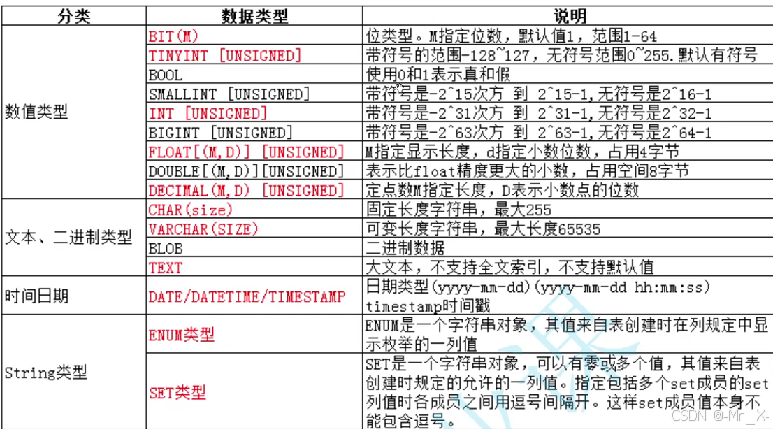 zerofill约束: 补0等宽显示 int(4)r如果不够补0够了不补 int()有符号是10位 无符号11位
zerofill约束: 补0等宽显示 int(4)r如果不够补0够了不补 int()有符号是10位 无符号11位

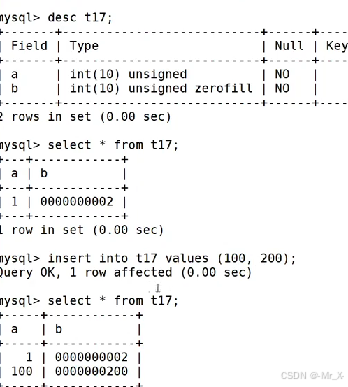
建好表之后添加主键:

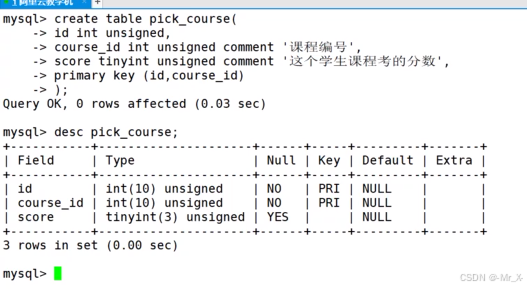
一张表只能有一个主键,但可以两个列合起来成为一个主键:每一个列可以重复但两个列不可以完全重复,比如选课表学生,课程,分数--(学生,课程)-复合组件
自动增长:自增长只能有一个列且主键
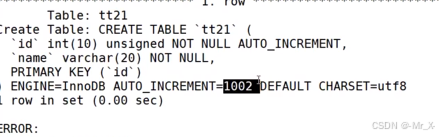
select last_insert_id()上一次i自增后d的值
如果是唯一键不可以重复但可以为null
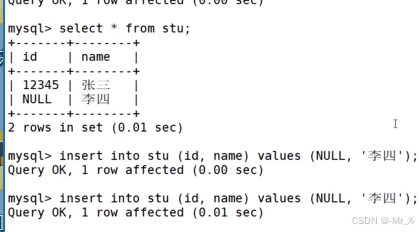
外键:

insert语句支持单行多行指定列插入

如果发生主键列冲突可以捕捉异常修正--插入替换
insert into students value(13,127,'xy','1111') on duplicate key update sn=127,name='xuyou',qq='111';
替换:
replace into students (id,sno,name,qq)value(13,127,'xy','1111')
查询:

基本运算符
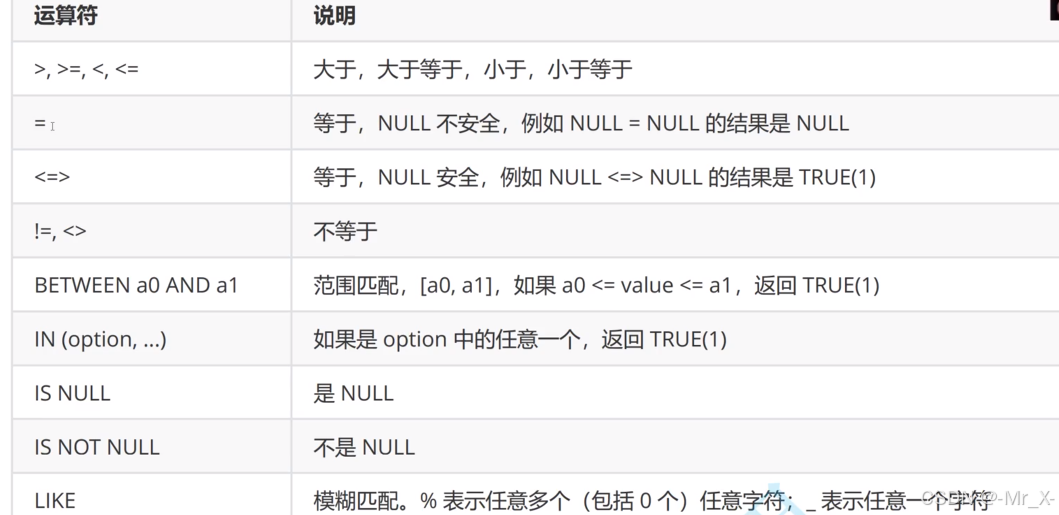
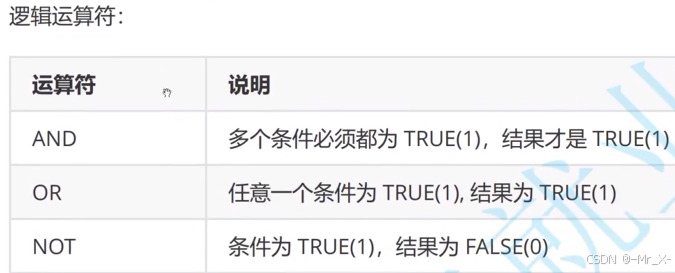
order by可以对多个列进行排序(相同时候下面有效)
limit(3)===limit(0,3),从0开始为第一行
offset其实就是limit的其实值
给总分前三名的人加3分

清空表:
delete from tablename -- 是不会修改自动增长值的并归零 --走事务
截断表: -
truncate tablename -- 会归零auto_increacement并清空表 -- 不走事务-不会记录日志
日志: bin log -- 记录历史sql, redo log -- , undo log - - 事务
删除表中的重复信息:
1.创一个表结构和另外一个表结构一样的表

2.sql语句

3.互相重命名
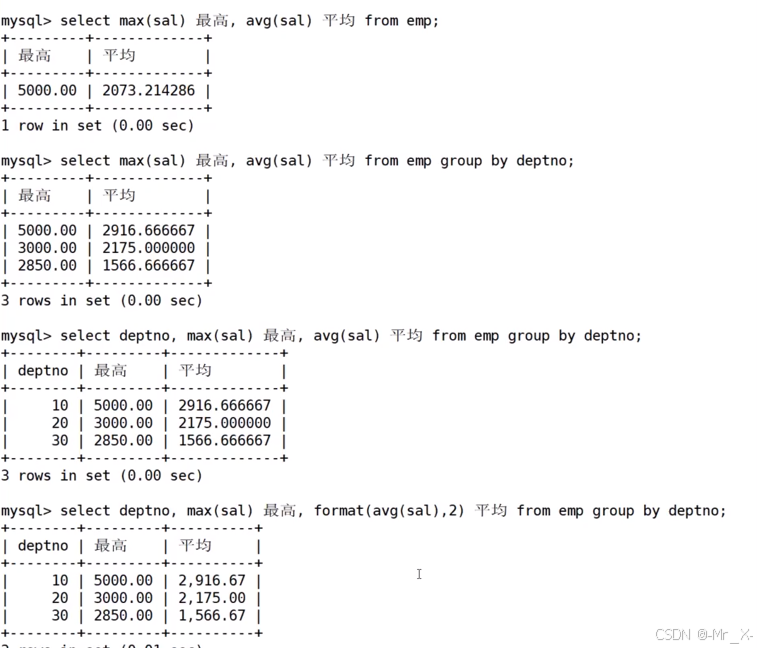
聚合函数:

分组聚合统计:

多个列一起参与分组
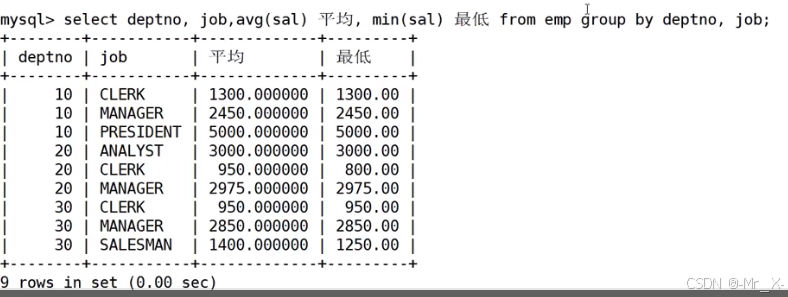
ename不是分组条件就无法进行压缩和聚合

having是对聚合的结果进行判断筛选统计

having其实可以替换掉where但不可以反过来换 --区别是条件筛选的阶段是不同的
统计不包含smith-执行顺序
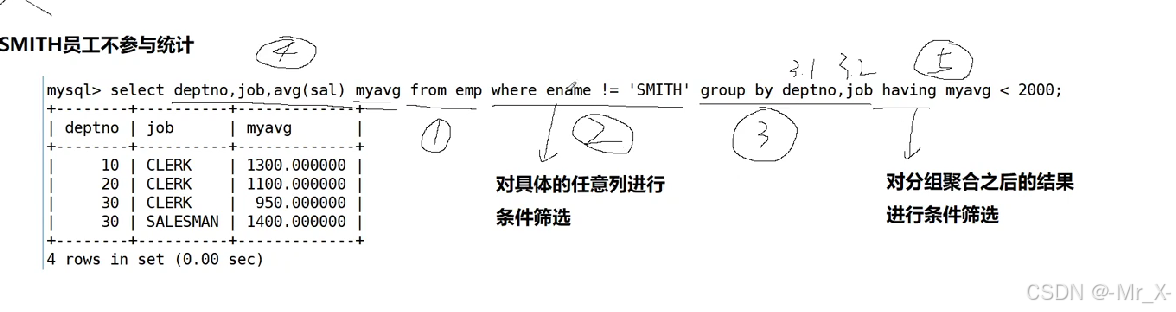
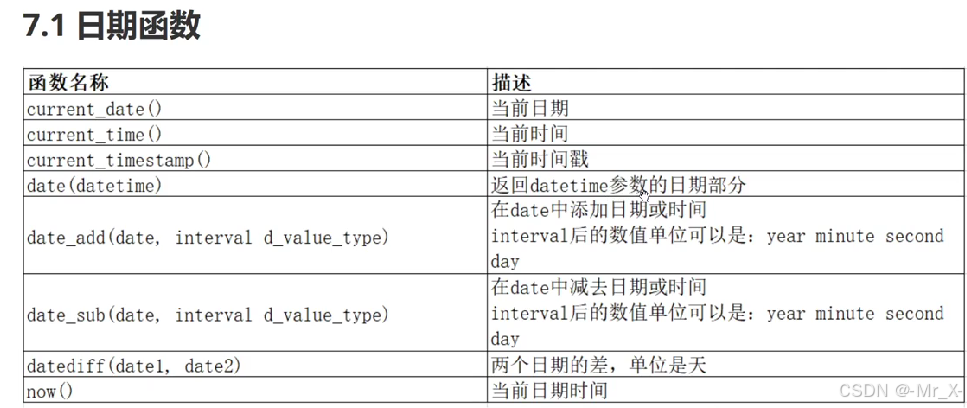
函数
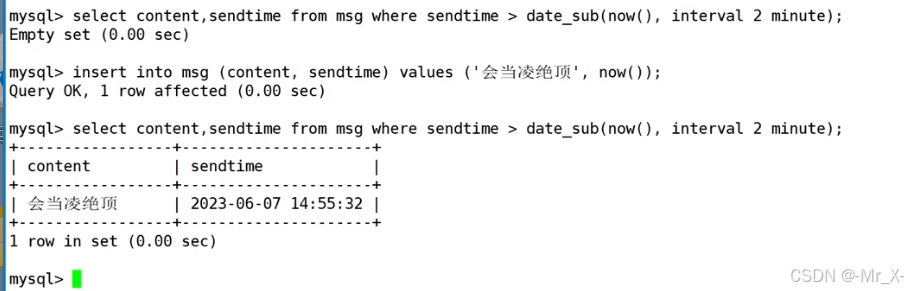
:
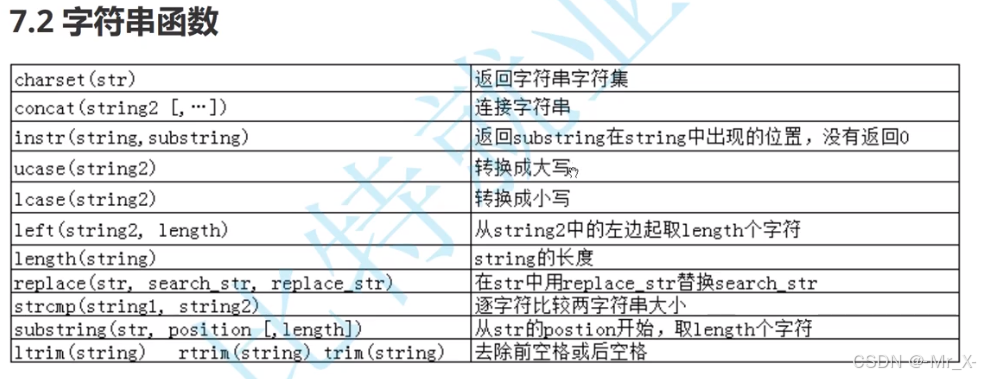
数学函数:
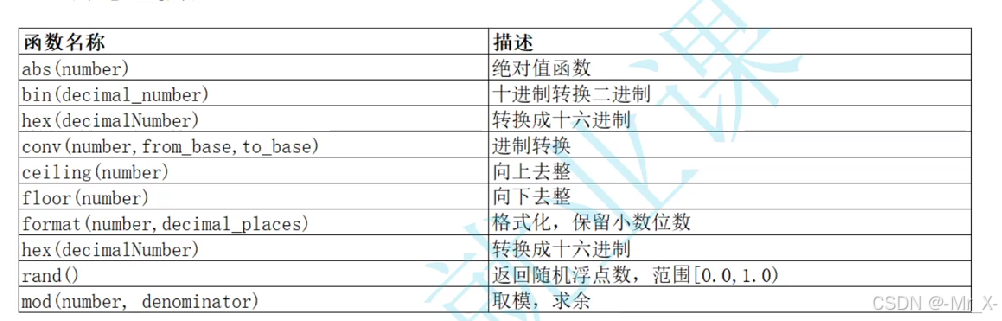 加密password
加密password
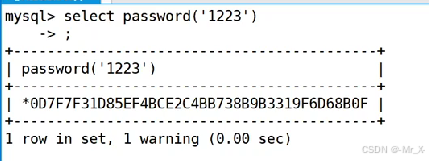
isnull
复合查询
1.模糊查询
2.单行子查询

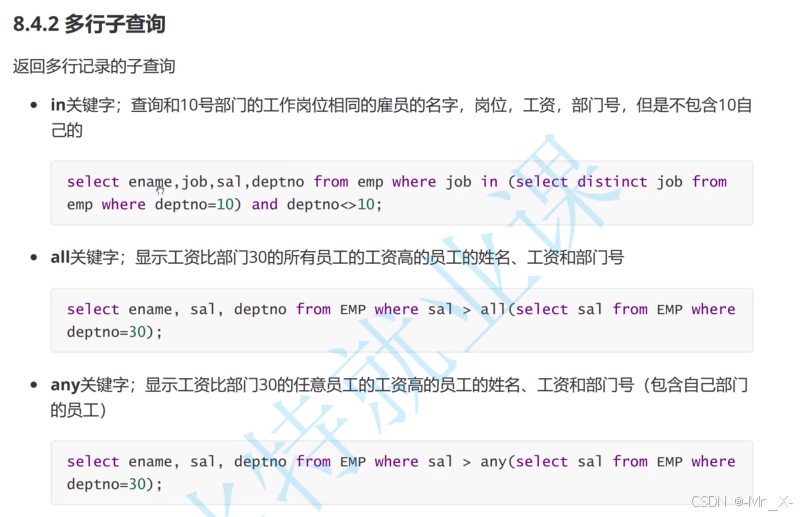
使用in关键字

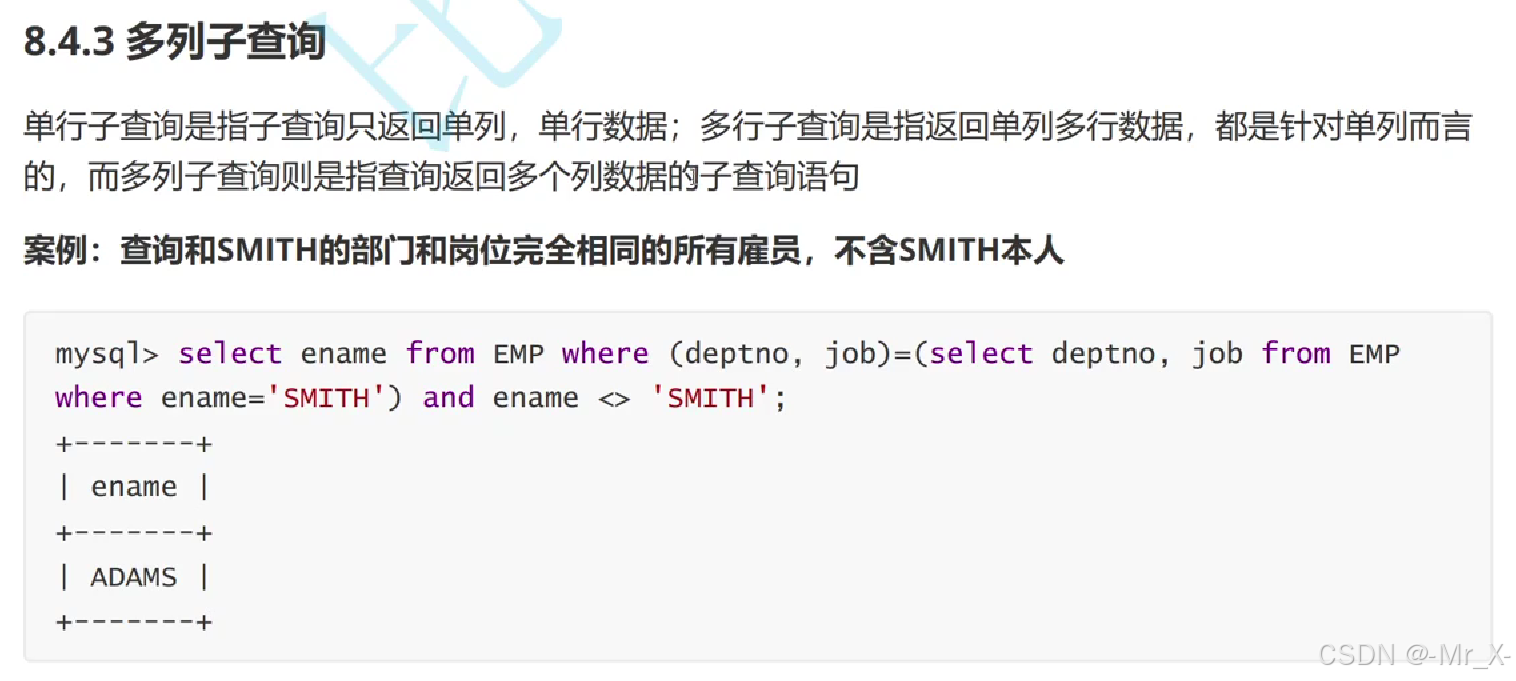

3.分组可以理解成先分组在对每组做聚合统计最后再去做having筛选
 4.多表查询
4.多表查询
多表笛卡尔积 不加过滤条件结果出来m行*n行的表--通常无太大意义如果需要连接表指定字段相等过滤
同一张表笛卡尔积-自连接:员工表中查你自己和上级的信息表-自己和自己笛卡尔集然后过滤
5.合并

内连接其实就是笛卡尔积,只不过where换成on了
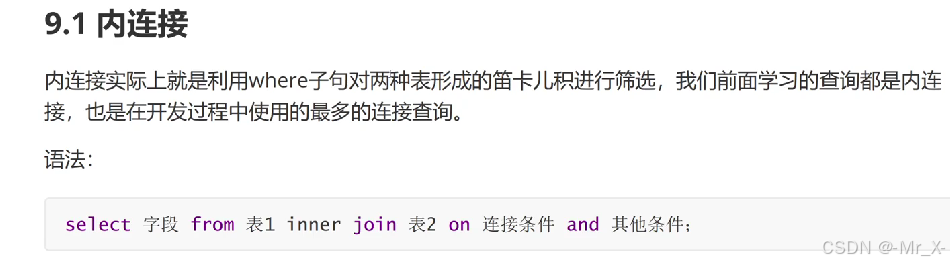
左外连接保留左边,如果右边没有匹配到就弄成null;
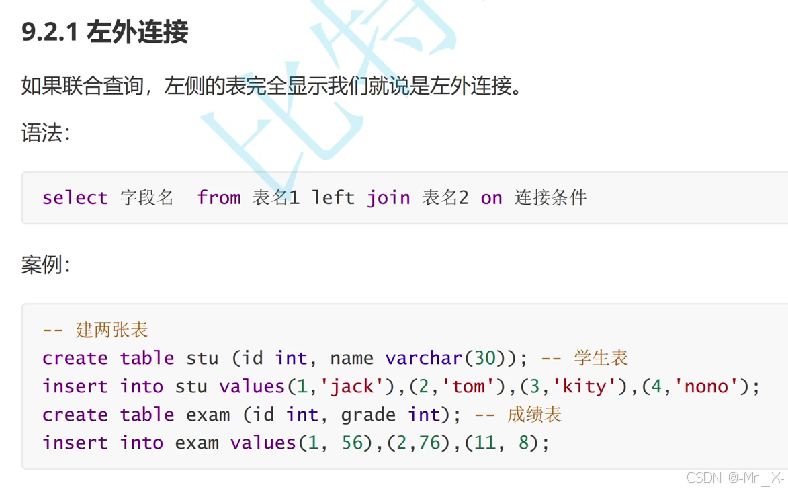 索引
索引

1.创建索引
mysql优化查询速度的三个要点
1.mysql以16mb为单位进行mysql级别的io操作
2.mysql有自己的buffer pool把数据刷新到自己的buffer pool再进行磁盘io
3.减少系统级io

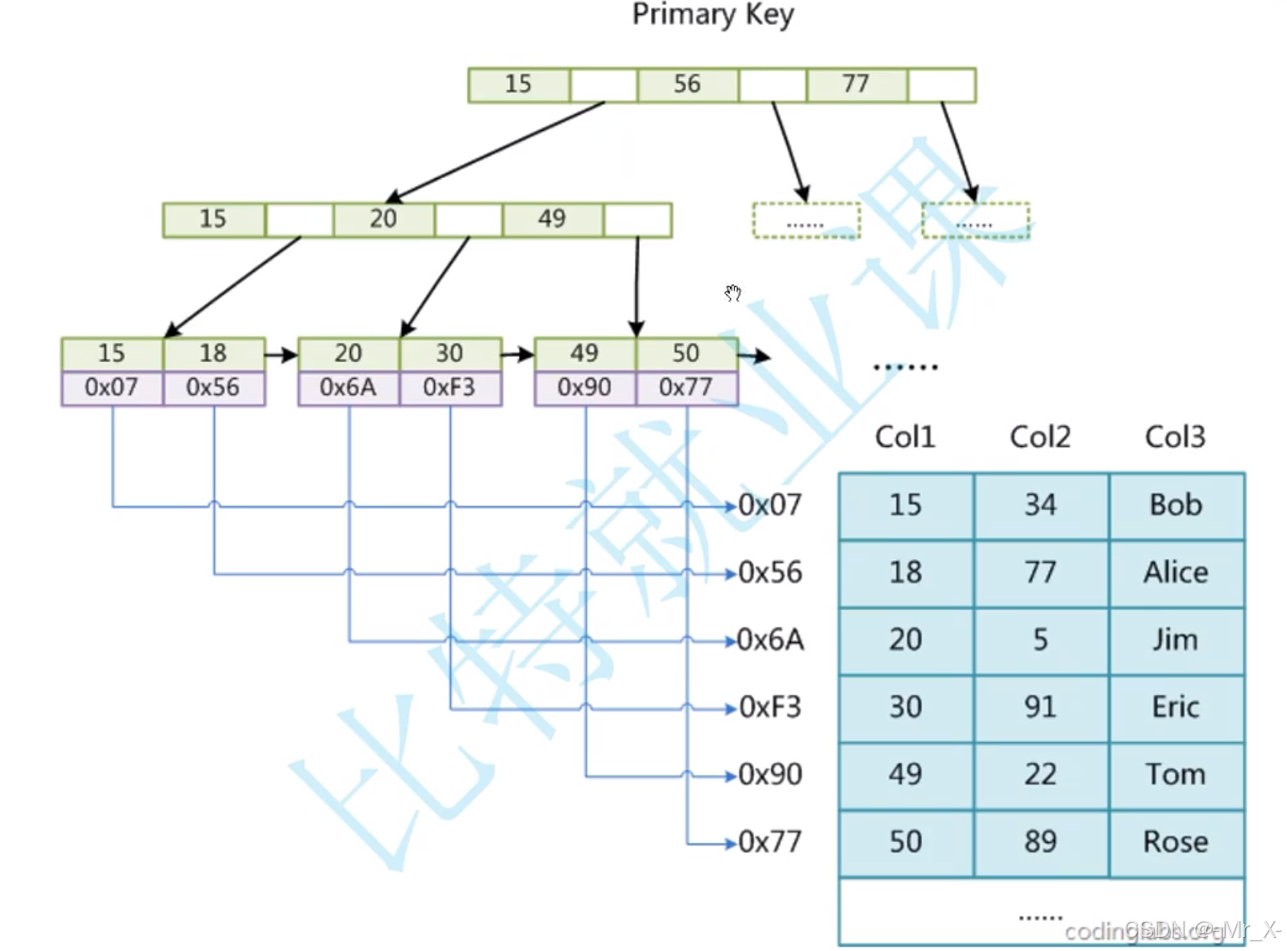
减少数的层高!,减少page的访问次数减少io,所以不进行在路上节点存数据,所以采用b+树而不选择b数
B+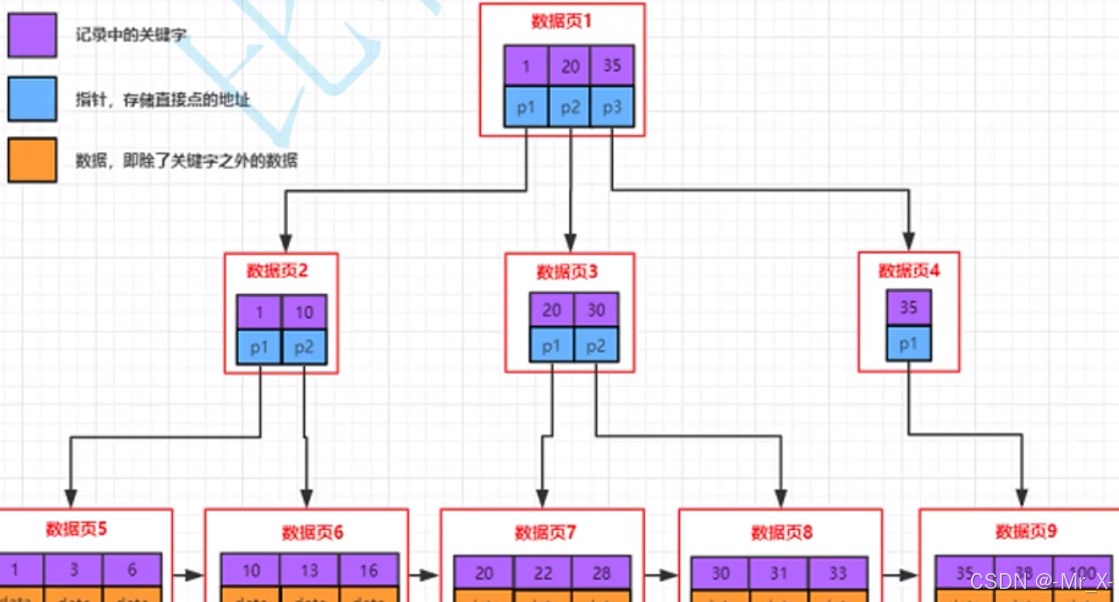
B
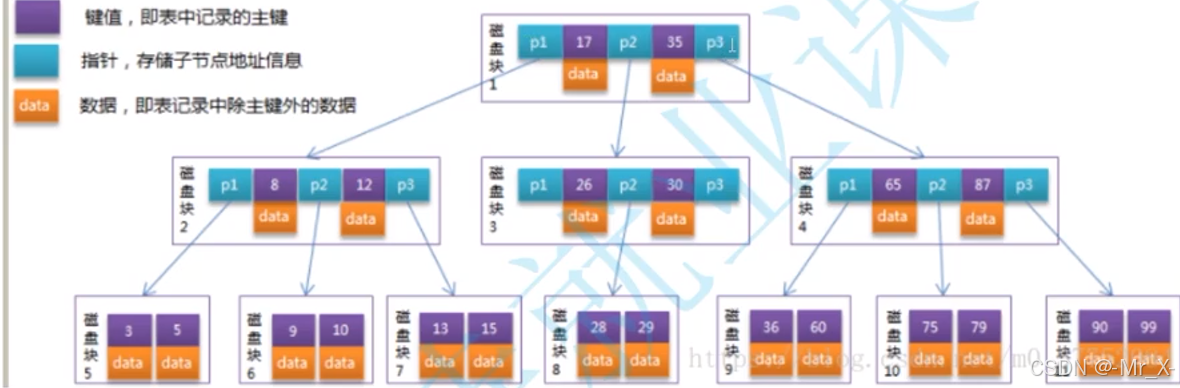
MyIsam -非聚簇索引(数据和地址分离存储)
innodb -- frm 表结构 ibd索引和数据结构
myisam --frm表结构,myd数据,myi索引

MyISAM 与 InnoDB 的索引及回表查询对比
| 特性 | MyISAM | InnoDB |
|---|---|---|
| 索引类型 | 非聚簇索引 | 聚簇索引(主键索引)+ 非聚簇索引 |
| 数据存储方式 | 数据和索引分开存储,索引指向数据行的物理地址 | 数据与主键索引存储在一起(聚簇索引) |
| 主键索引 | 不强制要求主键 | 强制要求主键,且作为聚簇索引 |
| 回表查询 | 二级索引查询直接定位到数据行,无需回表 | 二级索引存储主键值,需要通过主键值回表查找完整数据 |
| 回表性能 | 回表少,查询性能较稳定 | 存在回表查询,性能受主键和索引设计影响 |
| 覆盖索引优化 | 可以使用覆盖索引减少 IO | 覆盖索引更为重要,避免频繁回表 |
总结
- MyISAM:数据和索引分开,回表查询少,适合读密集型场景,但不支持事务。
- InnoDB:依赖聚簇索引,回表查询多,但支持事务和外键,适合写操作多的场景。合理设计主键和覆盖索引是优化关键。
如果表在创建时没有定义主键,不同存储引擎(如 MyISAM 和 InnoDB)处理索引的方式不同:
1. InnoDB:自动创建隐藏的聚簇索引
- 行为:
- InnoDB 强制要求每个表必须有一个聚簇索引。如果没有主键且没有唯一非空的索引,InnoDB 会自动创建一个隐藏的 6 字节的行 ID (
row_id) 作为聚簇索引。
- InnoDB 强制要求每个表必须有一个聚簇索引。如果没有主键且没有唯一非空的索引,InnoDB 会自动创建一个隐藏的 6 字节的行 ID (
- 创建规则:
- 如果表有主键,则主键用作聚簇索引。
- 如果表没有主键,但存在一个非空唯一索引,则该索引被用作聚簇索引。
- 如果表既没有主键,也没有唯一非空索引,则 InnoDB 自动生成一个隐藏的
row_id,并为其创建聚簇索引。
- 示例:
处理方式:InnoDB 会创建一个隐藏的聚簇索引。CREATE TABLE example ( name VARCHAR(50), age INT ) ENGINE=InnoDB;
2. MyISAM:不强制创建聚簇索引
- 行为:
- MyISAM 不支持聚簇索引,因此如果表中没有主键或唯一索引,MyISAM 不会自动创建任何隐式索引。
- 索引情况:
- 数据存储和索引分离,用户可以根据需求手动添加索引。
- 示例:
处理方式:MyISAM 不自动创建任何索引。CREATE TABLE example ( name VARCHAR(50), age INT ) ENGINE=MyISAM;
总结:如何索引是被创建的
| 情况 | InnoDB | MyISAM |
|---|---|---|
| 有主键 | 主键作为聚簇索引 | 主键索引 |
| 无主键,有唯一非空索引 | 唯一索引作为聚簇索引 | 唯一索引 |
| 无主键,无唯一非空索引 | 自动创建隐藏的 row_id 聚簇索引 | 不创建索引 |
优化建议:
- 在设计表时,尽量定义明确的主键或唯一非空索引,以避免 InnoDB 自动生成隐式索引,造成不可见的开销。
- 如果使用 MyISAM,需要手动规划索引策略以提高查询性能。
建立索引:


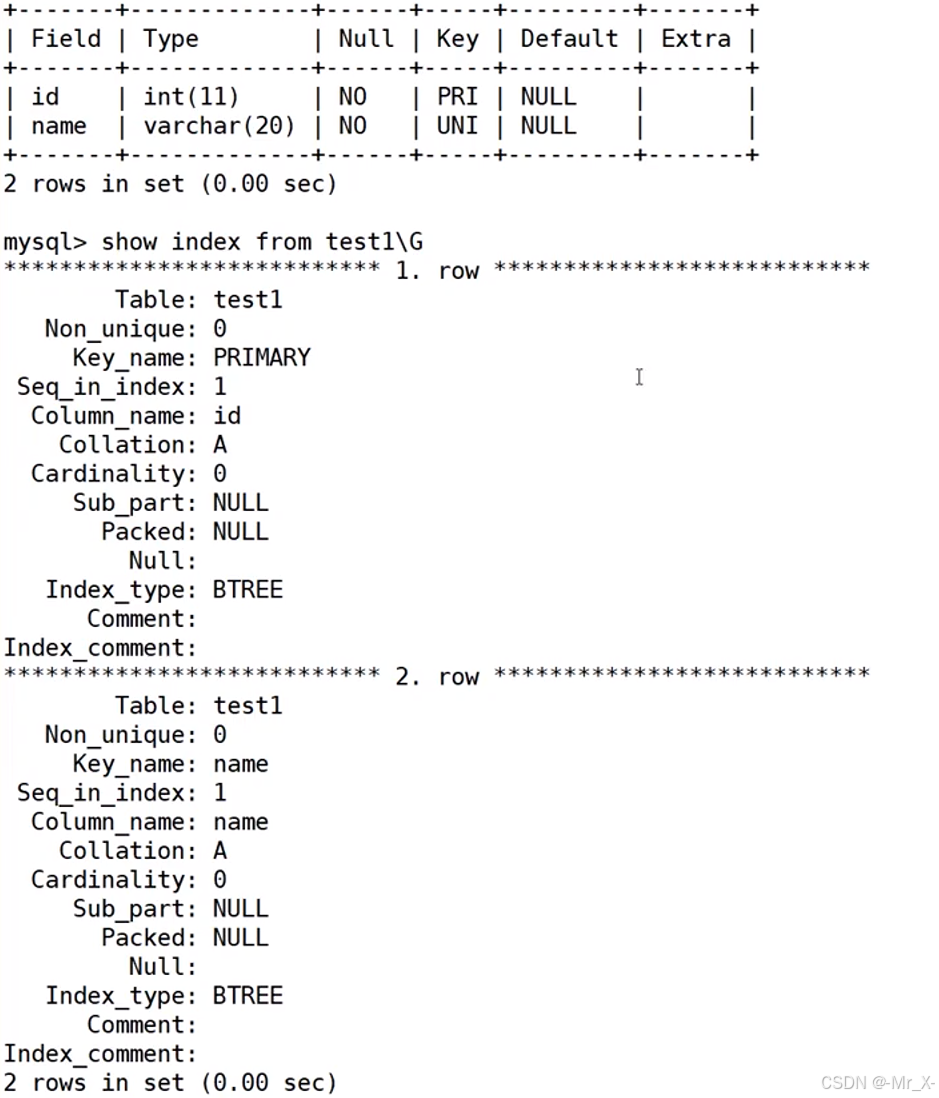
查看表结构(查看全部索引):
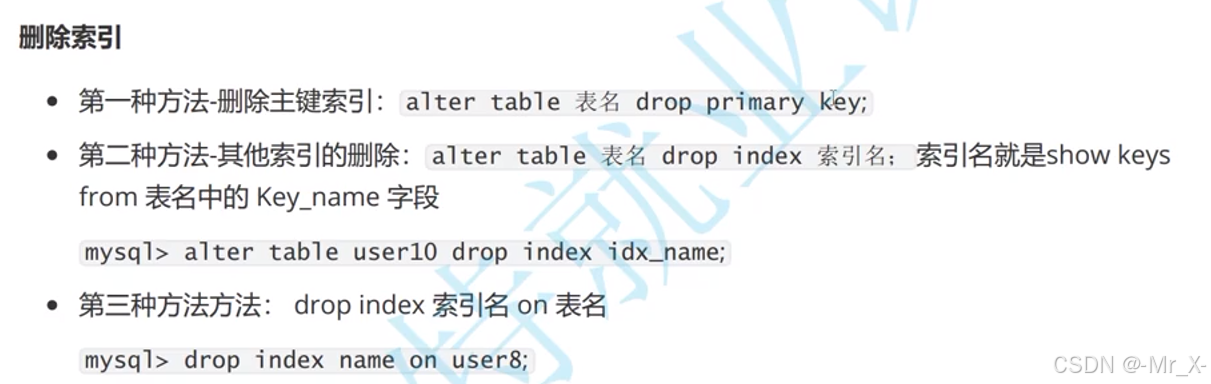
删除索引:
 索引覆盖可以减少回表查询:
索引覆盖可以减少回表查询:
全文索引使用mysiam ----英文

Mysql的事务支持innodb是支持事务的myisam是不支持事务
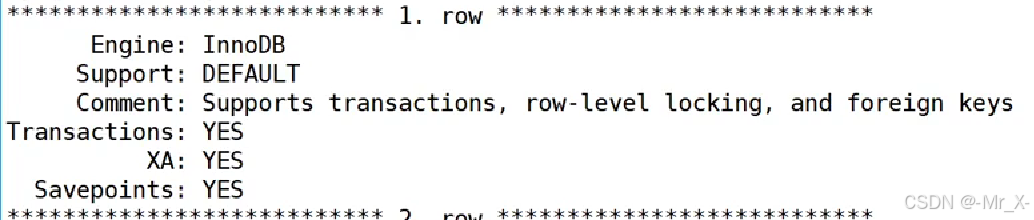
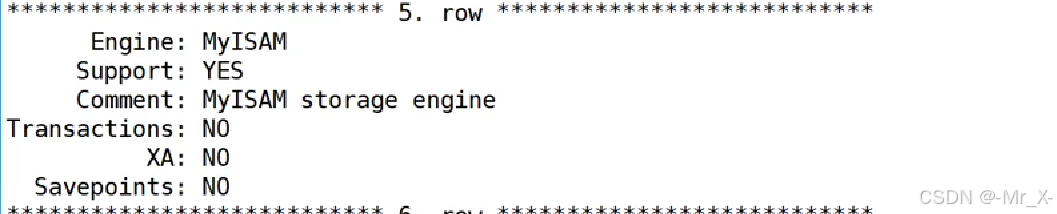

事务:
原子性,开启事务在操作过程中数据库崩溃异常情况,事务会自动回滚
单条的sql本质是一个事务
持久性
隔离性
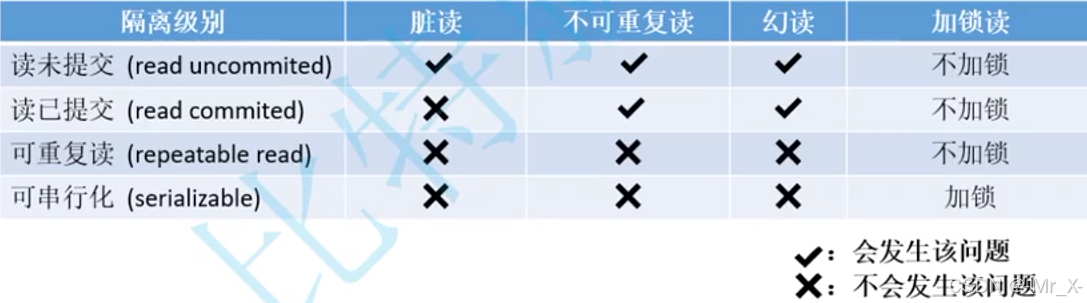
事务的隔离级别:

读未提交(可以读到未提交的数据): 事务还没有被提交就可以被别人看到修改 ----如果别人读到了未被回滚的事务 最终被回滚了就会产生 *****脏读*****
读已提交(可以读到已经提交的数据): 另一个事务提交后, 会产生在另外一个一直执行着查询的事务中读取的数据不一致叫********不可重复读********** --这个会产生什么问题呢? 查到两次Tom
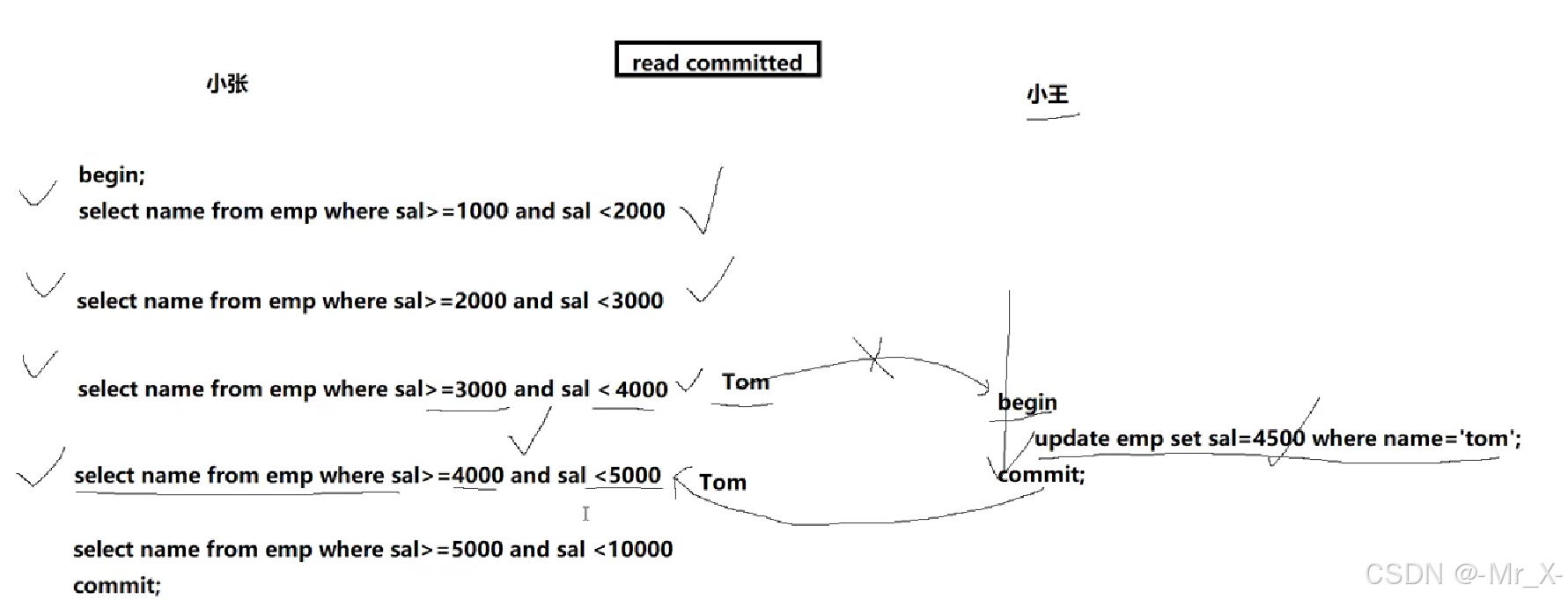
可重复读: 解决了以上一个事务读到数据不一样的问题(是默认隔离级别) 但是在有些数据库的insert的情况就会出现查的时候会***有新数据出现,***会产生不可重复读的情况----幻读

修改操作会产生等待,因为要进行 加锁



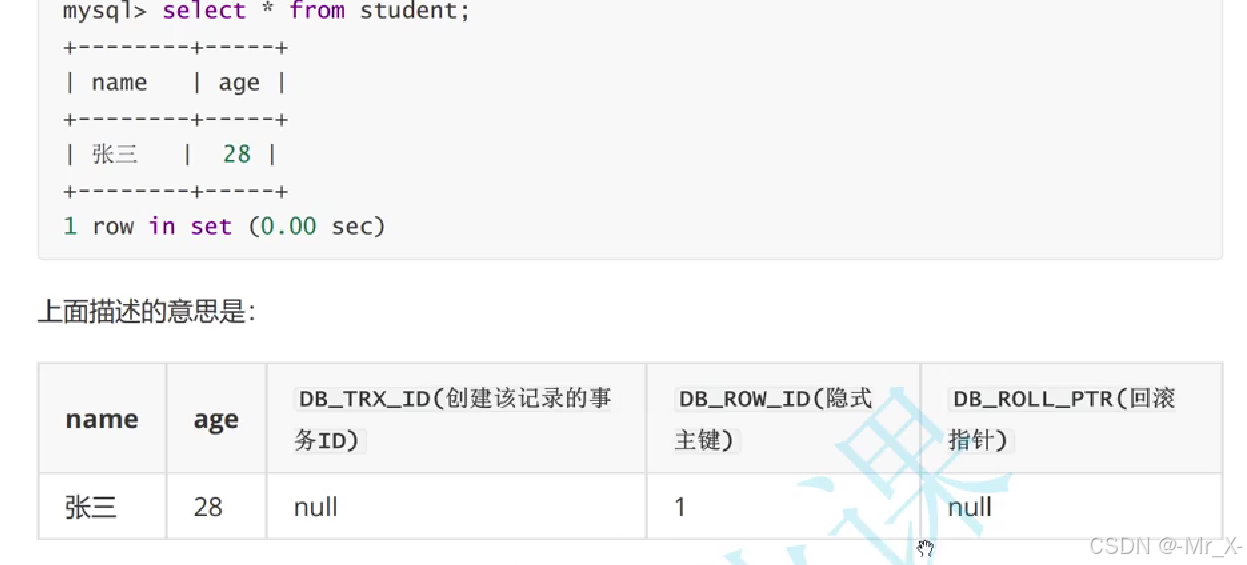
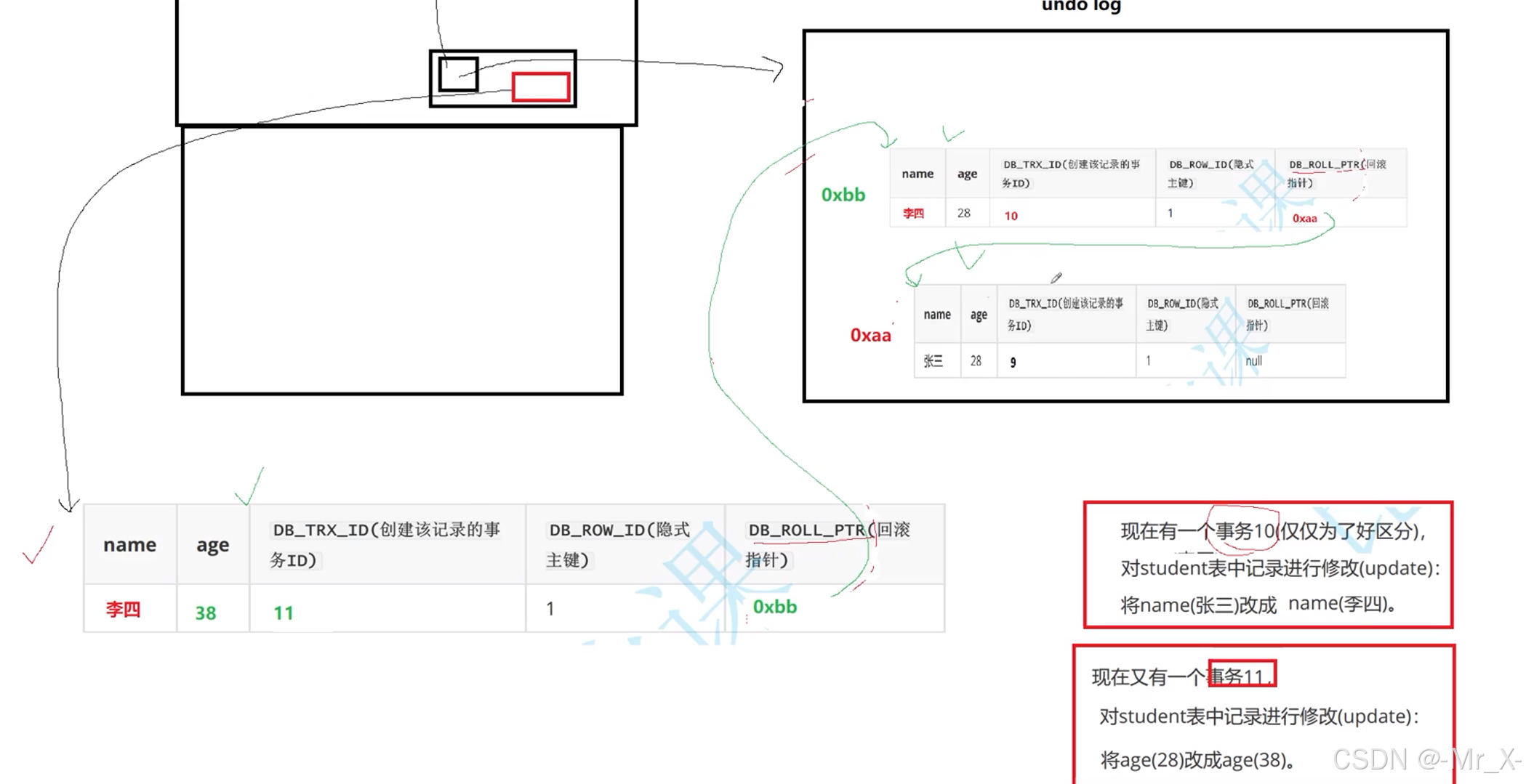
事务的底层实现原理:

版本链隔离性实现事务提交后undolog会被清理readView对象也会删掉无法回滚
MVCC实现读写并发的原因:
- 多版本存储:每次更新生成新版本,读操作可以读取旧版本,不受写操作阻塞。
- 读写分离:读事务用快照读,写事务独占修改,互不干扰。
- 事务版本号:通过时间戳控制版本访问,确保并发安全。
MVCC满足隔离性的原因:
- 快照读:读事务读取一致的快照,避免脏读。
- 版本控制:事务只访问符合隔离级别的版本,避免幻读和不可重复读。
- 锁机制:写事务锁定新版本,保证数据一致性。
ReadView结构

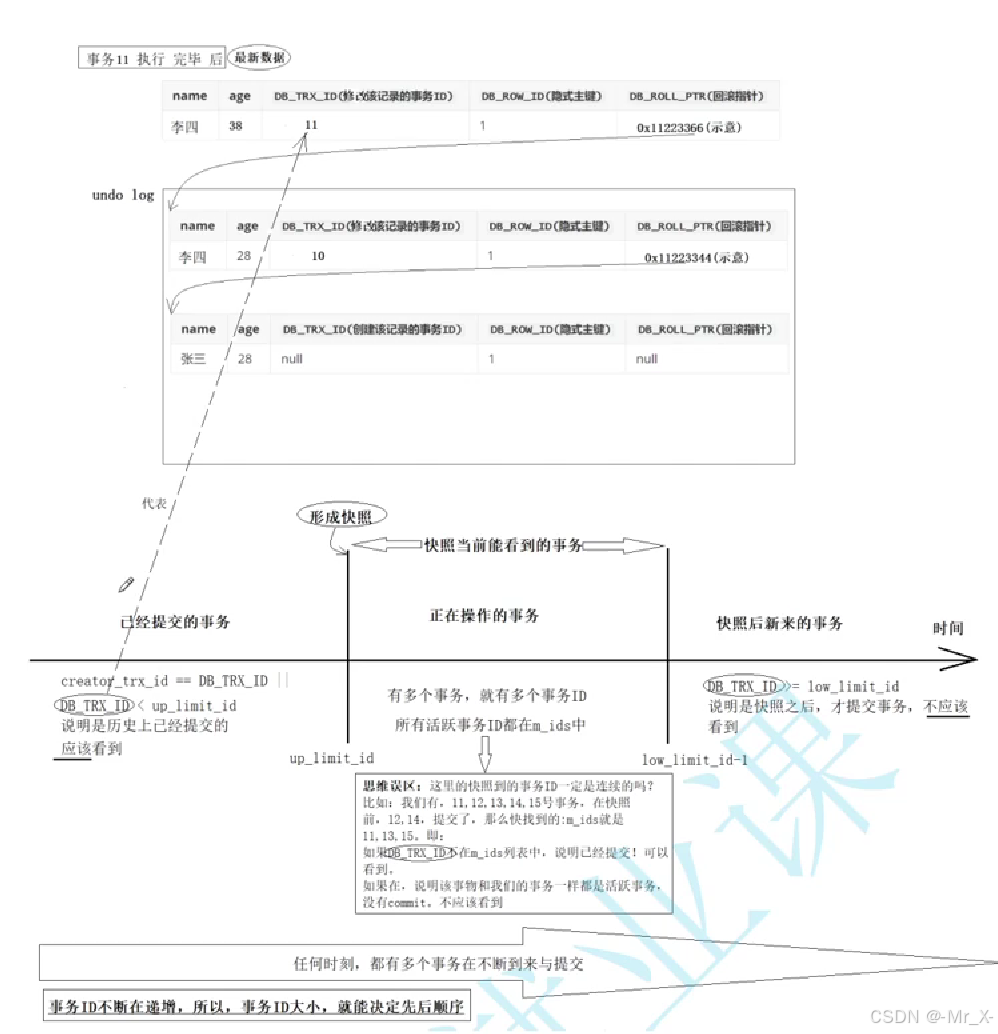


使用lock in share mode可以在RR级别下读到当前其他事务提交的新版本数据
默认使用快照读读的是老数据 形成了ReadView对象
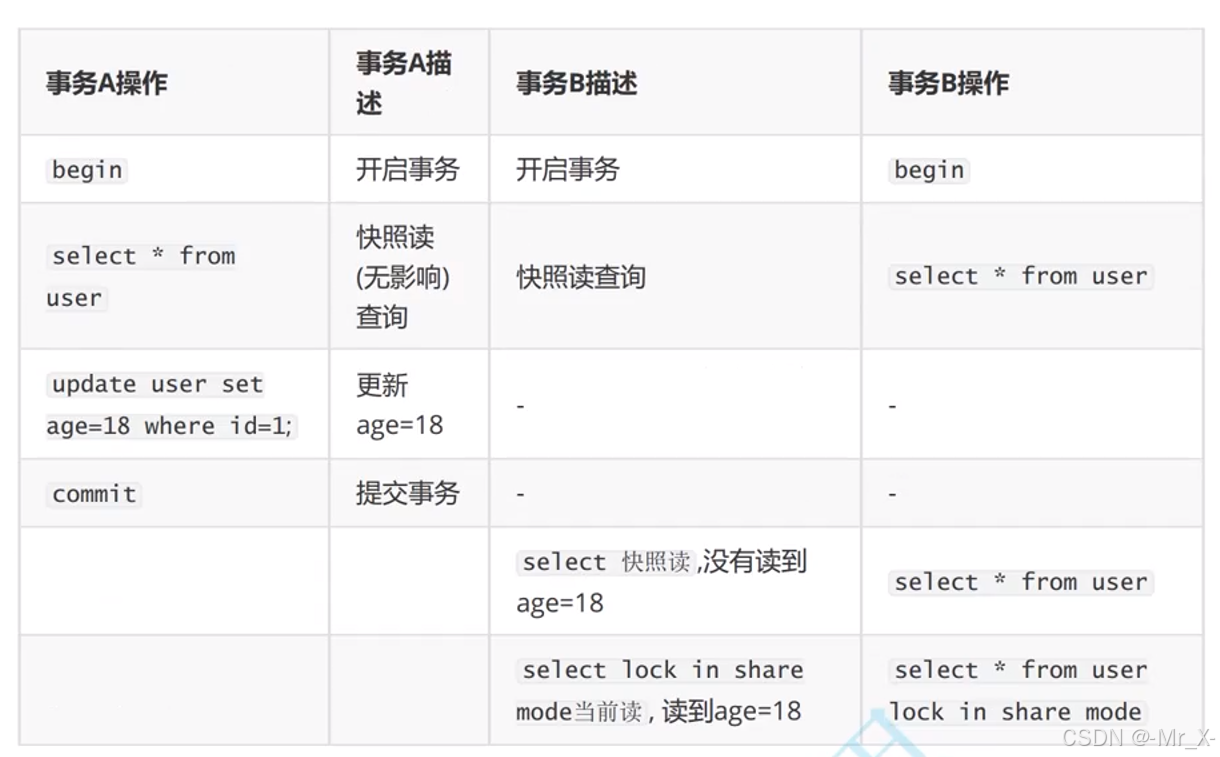
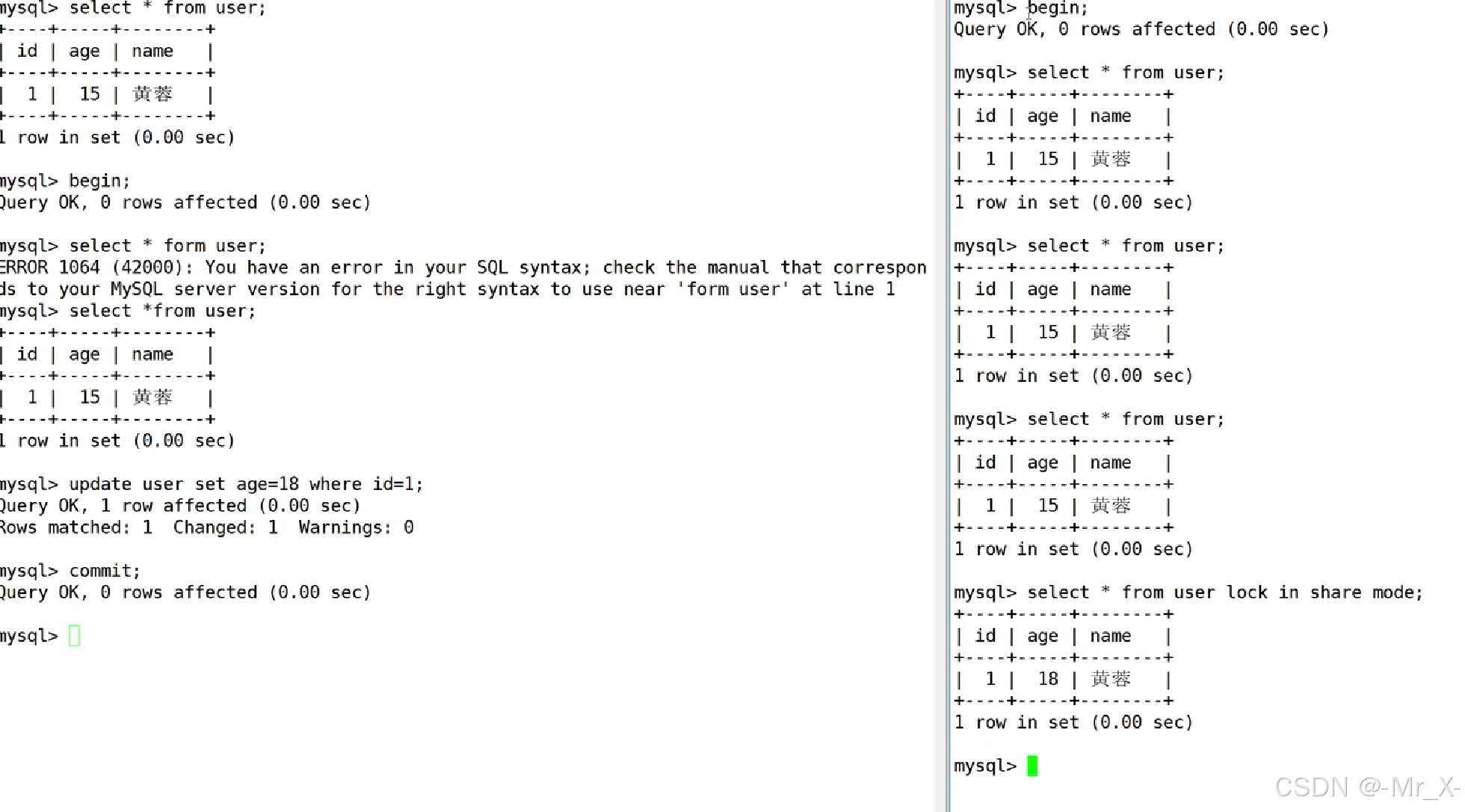
在提交之前没有读数据没有形成readView对象所有不会有快照读
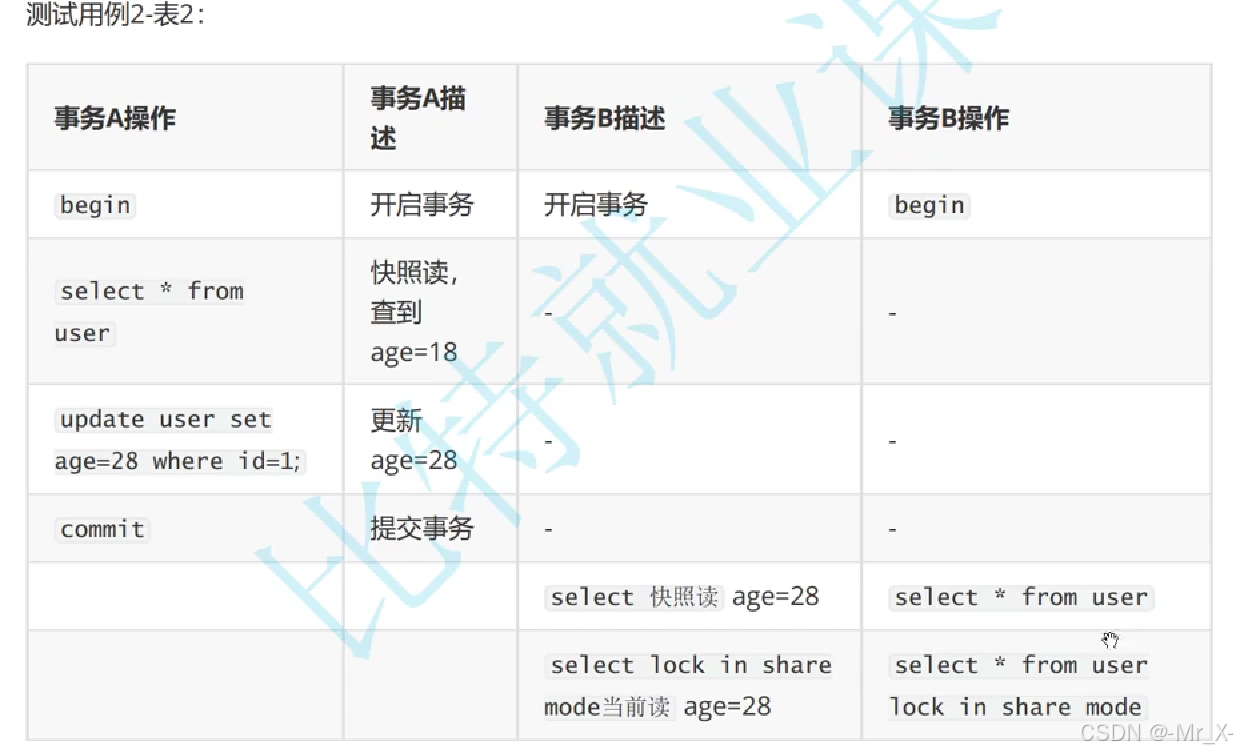
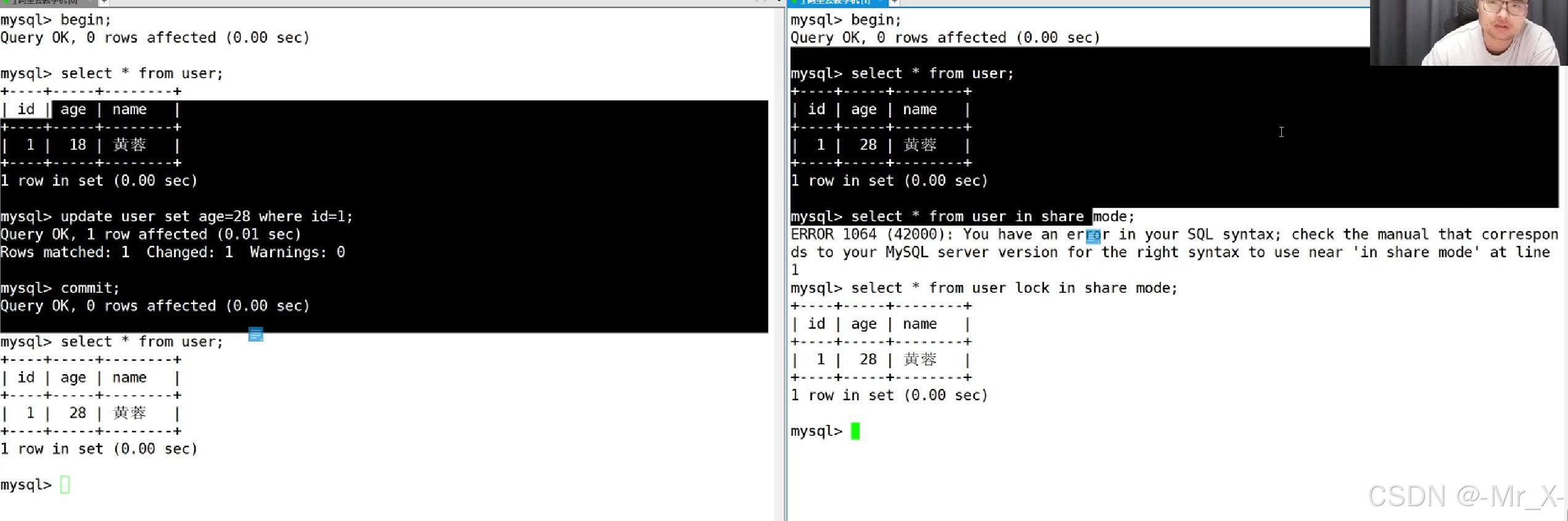




本质就是一个表,根据sql查出来的表直接变成一个新表,修改视图的表并会影响原来的表
修改表也会改变视图的数据,互相影响

触发器:
一、什么是触发器
当我们对一个表进行数据操作时,需要同步对其它的表执行相应的操作,正常情况下,如果我们使用sql语句进行更新,将需要执行多条操作语句!
触发器(TRIGGER)是由事件来触发某个操作。这些事件包括INSERT语句、UPDATE语句和DELETE语句。当数据库系统执行这些事件时,就会激活触发器执行相应的操作。MySQL从5.0.2版本开始支持触发器。
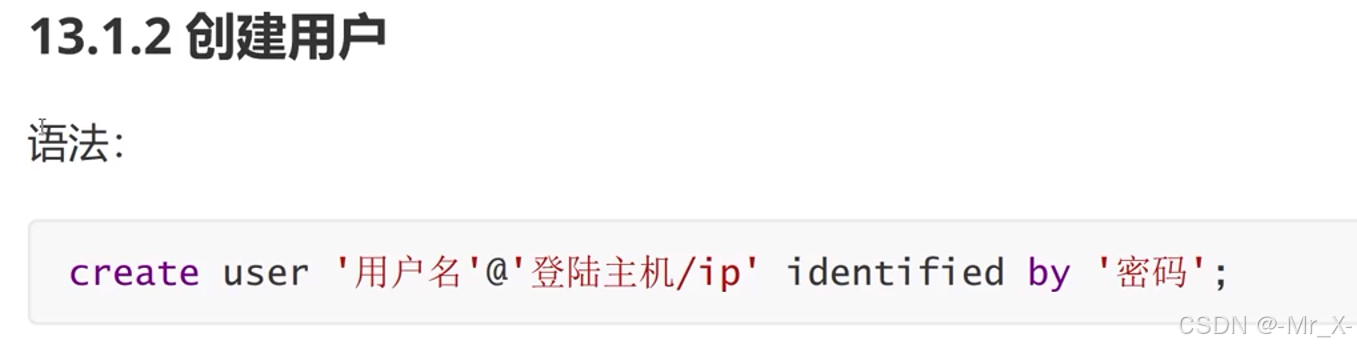
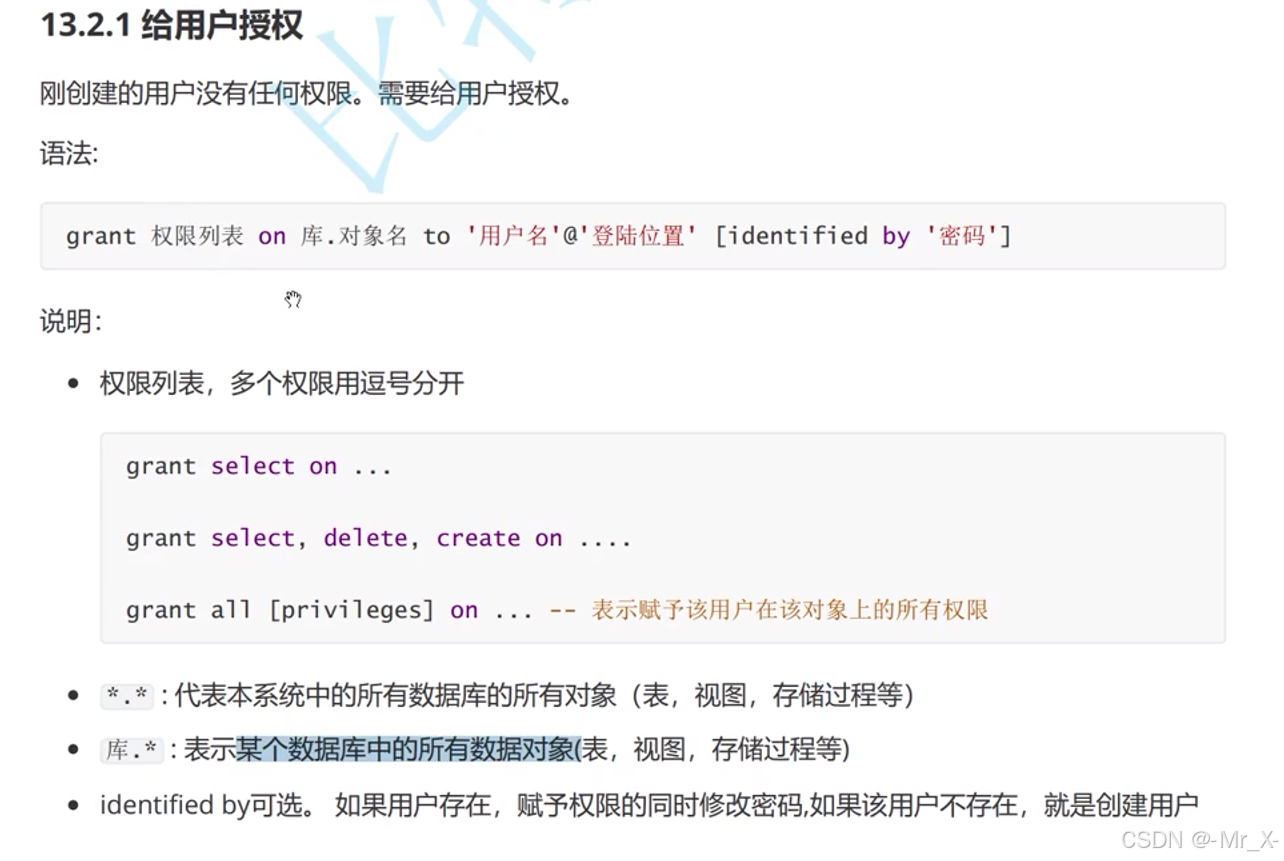
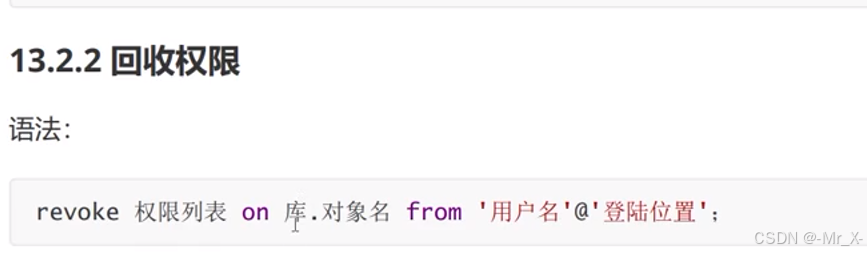
用户管理:mysql数据库下的user表


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









