







目录
一、前言
前段时间有小伙伴私聊我说,快期末考试了,能不能出一个MySQL数据库的教程啊。然后我花了一点时间,从建表到插入数据,从简单的增删改查,再到视图、存储过程、触发器的创建、删除等。其中还包括一些基本概念、E-R图创建及将其转换为关系模式。文章的最后还讲解了关系模式候选码、最小函数依赖集、模式分解的求解过程。文章虽长,但干货满满,希望大家能耐心读下去,最后希望大家能考出理想的成绩。
二、一些基本概念
1、时态数据库
区别于传统的关系型数据库(RDBMS),时态数据库(Temporal Database)主要用于记录那些随着时间而变化的值的历史,而这些历史值对应用领域而言又是重要的,这类应用有:金融、保险、预订系统、决策支持系统等。时态数据库理论提出了三种基本时间:用户自定义时间、有效时间和事务时间。同时把数据库分为四种类型:快照数据库、回滚数据库、历史数据库和双时态数据库。
2、分布式数据库
分布式数据库是指利用高速计算机网络将物理上分散的多个数据存储单元连接起来组成一个逻辑上统一的数据库。它通常使用较小的计算机系统,每台计算机中都可能有DBMS的一份完整拷贝副本,或者部分拷贝副本,并具有自己局部的数据库,位于不同地点的许多计算机通过网络互相连接,共同组成一个完整的、全局的逻辑上集中、物理上分布的大型数据库。分布式数据库的基本思想是将原来集中式数据库中的数据分散存储到多个通过网络连接的数据存储节点上,以获取更大的存储容量和更高的并发访问量。
3、面向对象数据库
面向对象数据库系统是为了满足新的数据库应用需要而产生的新一代数据库系统。面向对象数据库系统是面向对象的程序设计技术与数据库技术相结合的产物。面向对象数据库系统的主要特点是具有面向对象技术的封装性和继承性,提高了软件的可重用性。它应满足两个标准:首先它是数据库系统,其次它也是面向对象系统。第一个标准即作为数据库系统应具备的能力。第二个标准就是要求面向对象数据库充分支持完整的面向对象概念和控制机制。
4、移动数据库
移动数据库(mobile database)是能够支持移动式计算环境的数据库,其数据在物理上分散而逻辑上集中。它涉及到数据库技术,分布式计算技术,移动通信技术等多个学科,与传统的数据库相比,移动数据库具有移动性,位置相关性,频繁的断接性,网络通讯的非对称性等特征。通俗地讲,移动数据库包括以下两层含义:人在移动时可以存取后台数据库的数据或其副本;人可以带着后台数据库的副本移动。
三、数据库的创建
1、工具
MySQL8.0、Navicat Premiun 15、ProcessOn
2、基本需求
1)下图为其中一个小伙伴的期末复习大纲,后面所有的表和库均以其名字缩写命名
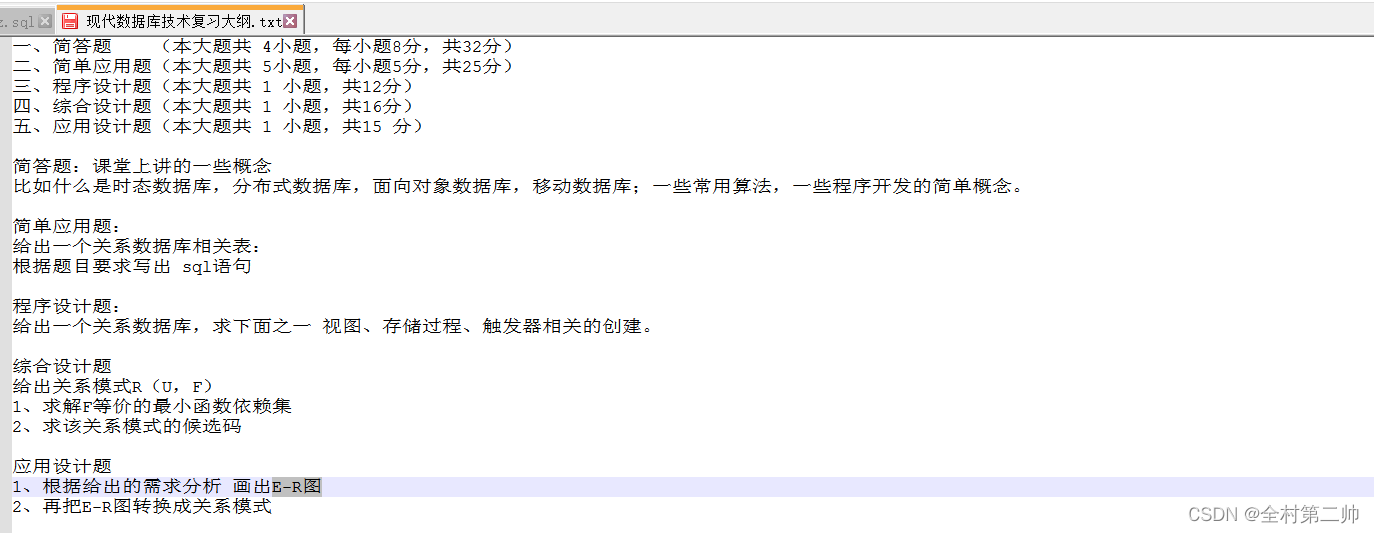 2)建立一个图书管理系统数据库(zyz_library),要求包含的表有:
2)建立一个图书管理系统数据库(zyz_library),要求包含的表有:
读者表(zyz_readers)
图书表(zyz_books)
管理员表(zyz_librarian)
借阅表(zyz_borrow)
3)为每张表设置适当的完整性约束(主键约束、唯一性约束、检查约束、默认约束、外键约束),以上五种约束在4张表中加起来至少涉及一次。
3、根据上述需求画出E-R图
E-R图又称实体关系图,是一种提供了实体,属性和联系的方法,用来描述现实世界的概念模型。通俗点讲就是,当我们理解了实际问题的需求之后,需要用一种方法来表示这种需求,概念模型就是用来描述这种需求。
1)E-R图基本要素:实体型,属性和联系
2)E-R图的构建有以下四个部分组成
矩形框:表示实体,在框中写入实体名,比如:读者、图书、管理员等
菱形框:表示联系,在框中写入联系名,比如:读者借阅图书,“借阅”表示两者的联系。
椭圆框:表示实体的属性,比如:读者的属性有姓名、性别、电话号码等
连线:用线段分别与有关实体相连接,并在线段上标注上联系的类型(1:1、1:n或m:n)。两个不同实体之间之间的联系可分为一对一联系记为1:1,一对多联系记为1:n,多对多联系记为m:n。比如一个管理员能同时登记多个读者,一个读者某个时间内只能被一个管理员登记,关系即为(1:n)。
3)E-R图的绘制
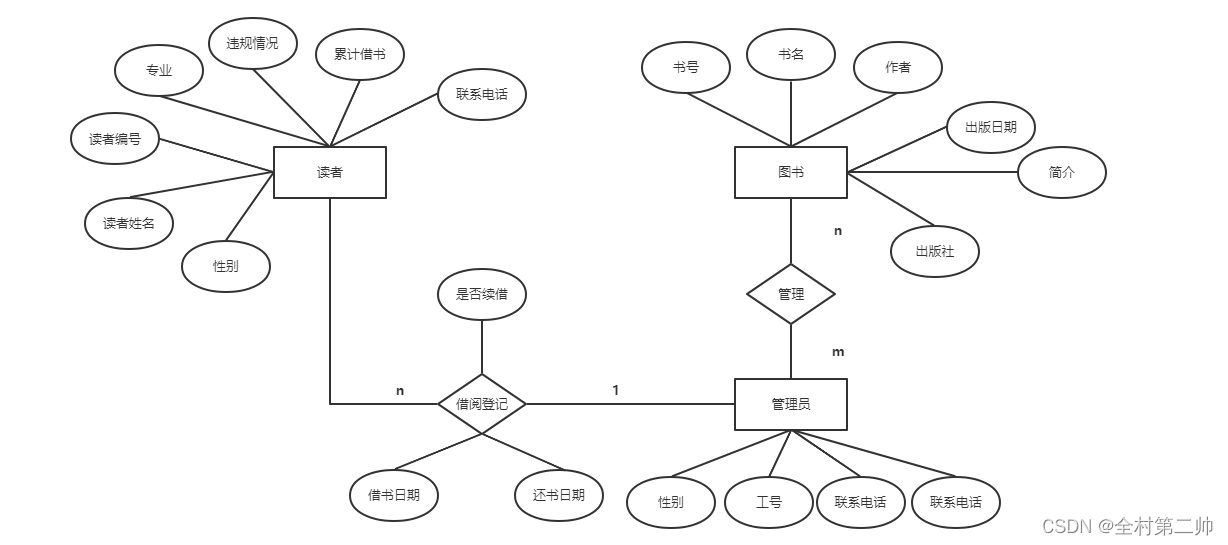
4、将E-R图转换成关系模式
读者(读者编号,读者姓名,性别,联系电话,专业,违规情况,累计借书)
图书(书号,书名,作者,出版社,出版日期,简介)
管理员(工号,姓名,性别,联系电话)
借阅(读者编号,书号,工号,是否续借,借书日期,还书日期)
5、建立数据表
#读者表
create table gzh_readers
(
gzh_rno int(15) primary key not null ,
gzh_rname varchar(30) not null ,
gzh_rsex char(10) check(gzh_rsex='男' or gzh_rsex='女'),
gzh_rphone varchar(50) not null ,
gzh_speciality varchar(50) not null,
gzh_remarks varchar(200) not null ,
gzh_rnum int(40) not null
);
#图书表
create table gzh_books
(
gzh_bno char(20) primary key not null ,
gzh_bname char(40) unique key not null ,
gzh_author varchar(40) not null ,
gzh_press varchar(50) not null ,
gzh_time date not null ,
gzh_profiles varchar(400)
);
#管理员表
create table gzh_librarian
(
gzh_lno varchar(20) primary key not null,
gzh_lname varchar(20) not null ,
gzh_lsex char(10) not null check(gzh_lsex='男' or gzh_lsex='女'),
gzh_lphone varchar(50) not null
);
#借阅表
create table gzh_borrow
(
gzh_rno int(15) not null ,
gzh_bno char(20) not null ,
gzh_lno varchar(20) not null ,
gzh_renew char(4) not null ,
gzh_jtime date not null ,
gzh_htime date not null ,
foreign key(gzh_rno) references gzh_readers(gzh_rno),
foreign key(gzh_bno) references gzh_books(gzh_bno),
foreign key(gzh_lno) references gzh_librarian(gzh_lno)
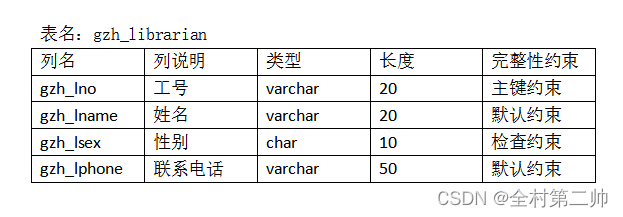
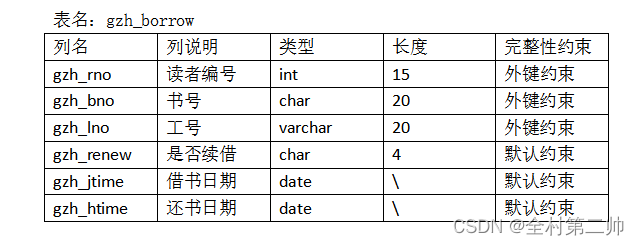
);6、每张数据表的结构
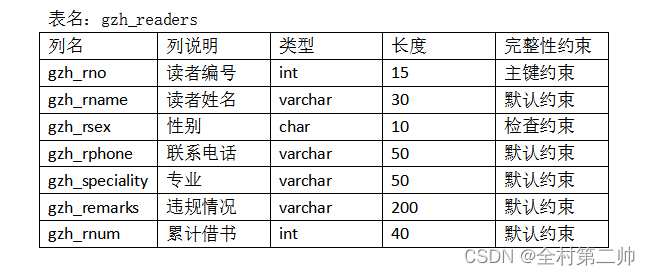
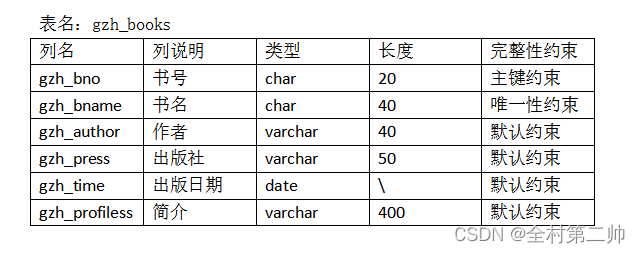
四、视图
1、创建视图
(1)创建单表视图,名字为gzh_view
create view gzh_view
as
select *
from gzh_readers(2)创建多表视图,名字为gzh_view_some
CREATE VIEW gzh_view_some AS SELECT
r.gzh_rno AS 读者编号,
r.gzh_rname AS 读者姓名,
r.gzh_rsex AS 性别,
r.gzh_speciality AS 专业,
b.gzh_bname AS 借阅的书籍,
l.gzh_lname AS 管理员姓名,
r.gzh_rnum AS 累积借书,
r.gzh_remarks AS 违规情况,
w.gzh_jtime AS 借书日期,
w.gzh_htime AS 还书日期
FROM
gzh_readers r,
gzh_books b,
gzh_librarian l,
gzh_borrow w
WHERE
w.gzh_rno = r.gzh_rno
AND w.gzh_bno = b.gzh_bno
AND w.gzh_lno = l.gzh_lno
ORDER BY
r.gzh_rno ASC;2、查看视图
(1)查看所有视图及表
show TABLES;

(2)查看视图基本信息
desc gzh_view;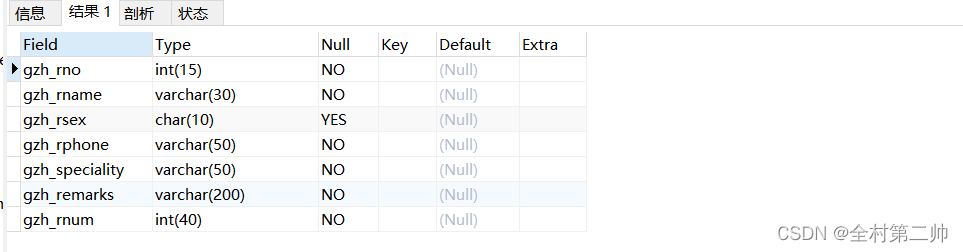
(3)查看视图的创建信息
show create view gzh_view;

(4) 用视图查询读者表中不同的专业
select gzh_speciality as 专业 from gzh_view GROUP BY gzh_speciality

3、更新视图数据
(1)利用视图插入一条数据
insert into gzh_view(gzh_rno,gzh_rname,gzh_rsex,gzh_rphone,gzh_speciality,gzh_remarks,gzh_rnum) values
(20,'郭反','男','855585522','网络工程','无违规行为',1);
(2)利用视图更新一条数据
update gzh_view set gzh_rname='郭小姐',gzh_rsex='女' WHERE gzh_rno=20;
4、修改视图
#修改某个视图的字段
alter view gzh_view as
select gzh_rno as 读者编号,gzh_rname as 读者姓名,gzh_speciality as 专业,gzh_remarks as 违规情况,gzh_rnum as 累计借书
from gzh_readers;
#查看一下视图字段
SELECT * from gzh_view;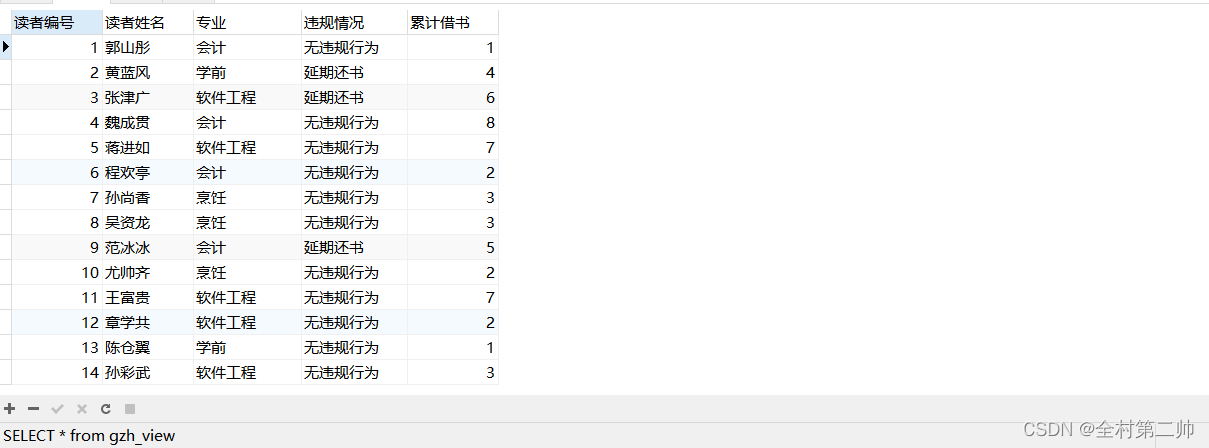
5、删除视图
drop view gzh_view;
show tables;
五、存储过程
1、存储过程
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来调用存储过程。简单的说就是专门干一件事的一段sql语句。
2、存储过程特点
(1)执行效率非常快!存储过程是在数据库的服务器端执行。
(2)移植性很差!不同的数据库的存储过程是不能移植的。
3、创建存储过程
begin后面可以跟多条语句,增删改查语句都可以,每句一定要以分号结尾。in表示参数输入,out表示参数输出。
#根据读者号查询该读者的所有信息
delimiter $$
CREATE PROCEDURE lib_findById(in rid int)
begin
SELECT *from gzh_readers where gzh_rno=rid;
END $$
delimiter;4、调用存储过程
call lib_findById(10);
5、删除存储过程
drop PROCEDURE lib_findById;6、参考案例
实例1:存储过程实现输入数字,输出一个对应的星期数
delimiter $$
create procedure week_testIf(in num int,out str varchar(20))
begin
if num=1 then
set str='星期一';
elseif num=2 then
set str='星期二';
elseif num=3 then
set str='星期三';
elseif num=4 then
set str='星期四';
elseif num=5 then
set str='星期五';
elseif num=6 then
set str='星期六';
elseif num=7 then
set str='星期天';
else
set str='输入错误';
end if;
end $$
delimiter;
-- 执行存储过程
call week_testIf(7,@str);
select @str;
实例 2:学校图书馆出台了一项借阅评级政策,想通过借阅量评借阅之星,评级如下:
#借阅3本以下,评为普通借阅者
#借阅3-5本,评为优质借阅者
#借阅5-9本,评为优秀借阅者
#借阅9本以上,评为借阅之星
要求使用存储过程,当输入姓名时,输出评级,比如:云凌可是借阅之星,郭山彤是普通借阅者
注:mysql的参数赋值语句必须是只能够选出一行(包括存储过程),这样的语句必须要加上limit 1才可以,否则报Result consisted of more than one row错误。
delimiter $$
CREATE PROCEDURE lib_bestReaders(in rname varchar(20),out str varchar(20))
begin
declare num int;
select gzh_rnum into num from gzh_readers where gzh_rname=rname ;
if num>9 then
set str='借阅之星';
elseif num>=5 and num<=9 then
set str='优秀借阅者';
elseif num>=3 and num<5 then
set str='优质借阅者';
else
set str='普通借阅者';
end if;
end $$
delimiter;
call lib_bestReaders('云凌可',@str);
select @str as 评级;
------------------------------------
call lib_bestReaders('郭山彤',@str);
select @str as 评级;
-----------------------------------------
call lib_bestReaders('蒋进如',@str);
select @str as 评级;
六、触发器
触发器用于在 MySQL 执行插入、更新或删除语句时,自动触发执行其他SQL代码。触发器可以在执行语句前或执行后触发其他 SQL 代码运行。触发器可以读取触发语句改变了哪些数据,但是没有返回值。因此可以使用触发器加强业务逻辑的约束而不需要在应用程序写对应的代码。
1、触发器的创建
(1)简单触发器
创建一个简单的触发器gzh_trigger,当执行插入语句之后激活触发器,如果超过某个自己设定的阙值,触发器被触发并给出相应的提示信息
delimiter $$
CREATE TRIGGER gzh_trigger #触发器的名称
AFTER INSERT #当执行插入语句之后激活触发器
ON gzh_readers #作用于那个表
FOR EACH ROW #触发器作用在每条记录上
#以上都是固定的写法,可以直接套
# 触发器需要执行的操作
if NEW.gzh_rnum>50 then
SIGNAL SQLSTATE '45000' #错误状态信息
set message_text="你输入的数字过大,检查后输入";
end if $$
delimiter;
insert into gzh_readers values
(29,'刘小燕','女','42123456789','计算机应用','超时还书',105)
(2)复杂触发器
创建一个复杂的触发器gzh_trigger2并且单独创建一个表来保存触发信息
create table readers_log(
operation VARCHAR(50) not null,
operation_time TIMESTAMP not null
);
delimiter $$
CREATE TRIGGER gzh_trigger2 #触发器的名称
AFTER INSERT #当执行插入语句之后激活触发器
ON gzh_readers #作用于那个表
FOR EACH ROW #触发器作用在每条记录上
# 触发器需要执行的操作
BEGIN
set @r_name = new.gzh_rname;
#当插入一条读者记录就向日志表插入一条记录此次操作
INSERT INTO readers_log(operation,operation_time) VALUES (concat("被操作人:",@r_name),NOW());
END $$
delimiter;
insert into gzh_readers values
(23,'刘小燕','女','42123456789','计算机应用','超时还书',7);
2、查看触发器
show triggers;

3、触发器的删除
#删除触发器
drop trigger gzh_trigger2;七、一些sql语句案例
1、单表操作
(1)新增一条图书信息,'116','《Java》','吴某凡','机械工业','2022-11-22','大碗宽面'
insert into gzh_books values
('116','《Java》','吴某凡','机械工业','2022-11-22','大碗宽面')
(2)将读者表中名字有“谢”的读者的累积借书增加1次
update gzh_readers set gzh_rnum=gzh_rnum+1 where gzh_rname like '%谢%'修改之前:
![]()
修改之后:
![]()
(3)删除书号为115和116的图书
delete from gzh_books where gzh_bno in('115','116')删除之前:
删除之后:

(4)删除最早出版的三本图书信息
#先查出最早出版的三本图书的信息,然后删除
DELETE
FROM
gzh_books
WHERE
gzh_time =(
SELECT
gzh_time
FROM
gzh_books
ORDER BY
gzh_time ASC
LIMIT 0,3
)
先查出最早出版的三本图书的信息:

然后再进行删除:
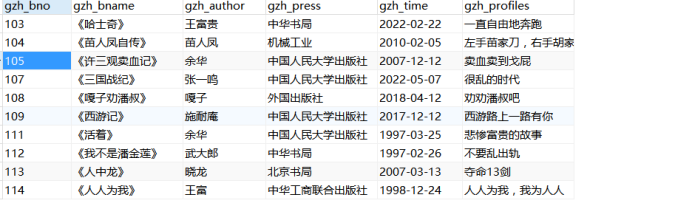
(5)修改《我不是潘金莲》的作者为武松、出版社为机械工业
update gzh_books set gzh_author='武松',gzh_press='机械工业' where gzh_bname='《我不是潘金莲》'
修改之前:
![]()
修改之后:
![]()
(6)查询读者表中的所有数据
select * from gzh_readers
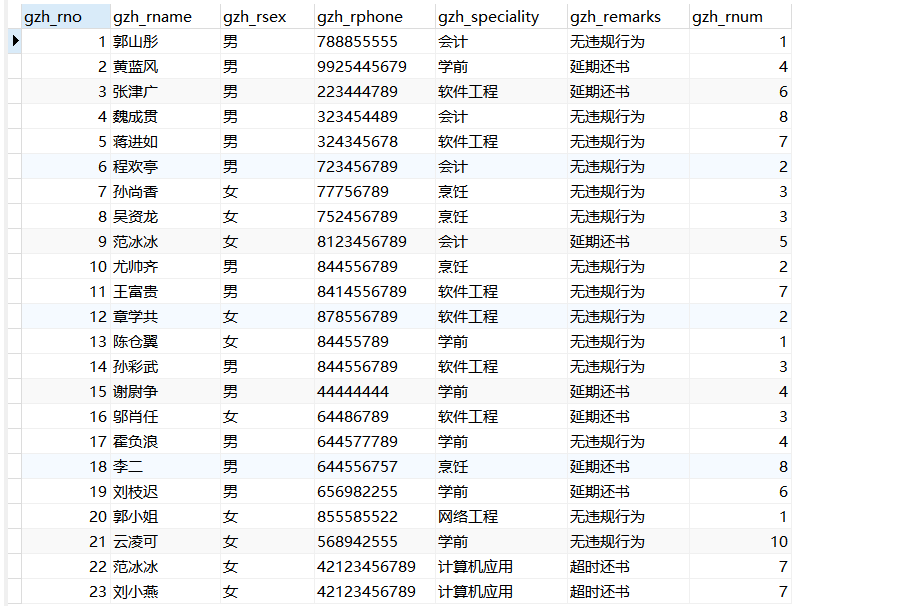
(7) 查询管理员表中的姓名和电话
select gzh_lname as 姓名,gzh_lphone as 电话 from gzh_librarian
 (8)查询读者表中不同的专业
(8)查询读者表中不同的专业
select gzh_speciality as 专业类别 from gzh_readers GROUP BY gzh_speciality
 (9)查询所有图书的作者,并按作者统计不同作者下的书本数
(9)查询所有图书的作者,并按作者统计不同作者下的书本数
select gzh_author as 作者,count(*) as 书本数 from gzh_books group by gzh_author
(10)使用子查询,查询累计借书次数在某个范围之间的所有读者的姓名,例如借书次数3-9次的所有读者的姓名
SELECT
gzh_rname AS 读者的姓名,gzh_rnum AS 借书次数
FROM
gzh_readers
WHERE
gzh_rnum in(
SELECT
gzh_rnum AS 借书次数
FROM
gzh_readers
WHERE
gzh_rnum BETWEEN 3 AND 9);

(11)查询所有1990-07-11之后的并且书名中包含“人”字的所有图书
select * from gzh_books where gzh_time>= '1990-07-11' and gzh_bname like'%人%'
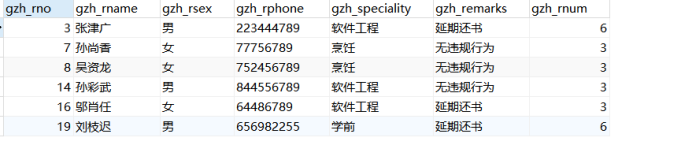
(12)查询累计借书次数为3、6、9的所有用户
select * from gzh_readers where gzh_rnum in (3,6,9)
(13)查询所有借阅情况并按照借书日期倒序排列
select * from gzh_borrow order by gzh_jtime desc
(14)查询包含“人”字的所有图书并按出版日期升序排列
select * from gzh_books where gzh_bname like'%人%' ORDER BY gzh_time  (15)查询读者表中读者总人数
(15)查询读者表中读者总人数
select count(*) as 读者总人数 from gzh_readers

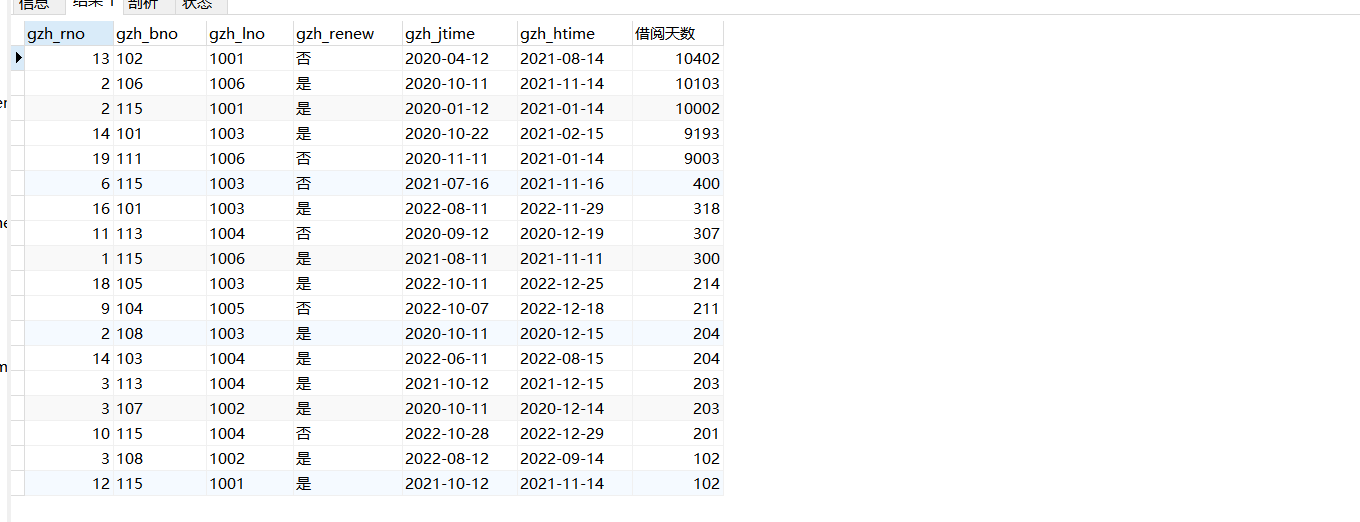
(16)查询借书天数大于20天的借阅信息
select *,(gzh_htime-gzh_jtime) as 借阅天数 from gzh_borrow where (gzh_htime-gzh_jtime)>20 order by 借阅天数 desc;
(17)查询读者表中各个专业下的学生人数,字段名分别为专业名称、读者人数
select gzh_speciality as 专业名称, count(*) as 读者人数 from gzh_readers GROUP BY gzh_speciality

(18)查询累计借书最多的读者信息
select * from gzh_readers where gzh_rnum =(select max(gzh_rnum) from gzh_readers)
 (19)查询借书日期最早的读者
(19)查询借书日期最早的读者
select * from gzh_readers r ,gzh_borrow w where r.gzh_rno=w.gzh_rno and gzh_jtime =(select min(gzh_jtime) from gzh_borrow)
![]() (20)查询借阅天数最长的借阅信息
(20)查询借阅天数最长的借阅信息
select *,max(gzh_htime-gzh_jtime) as 借阅天数最长 from gzh_borrow

(21)学校图书馆出台了一项借阅评级政策,想通过借阅量评借阅之星,评级如下:
借阅3本以下,评为普通借阅者
借阅3-5本,评为优质借阅者
借阅5-9本,评为优秀借阅者
借阅9本以上,评为借阅之星
要求:输出读者的编号、姓名、专业、违规情况、借阅量和评级状况,并按评级高到低排列
select gzh_rno as 读者号, gzh_rname as 姓名,gzh_speciality as 专业,gzh_remarks as 违规情况,gzh_rnum as 借阅量,
case
when gzh_rnum>9 then '借阅之星'
when gzh_rnum>5 and gzh_rnum<=9 then '优秀借阅者'
when gzh_rnum>3 and gzh_rnum<=5 then '优质借阅者'
else '普通借阅者' end as 评级状况
from gzh_readers
order by gzh_rnum desc;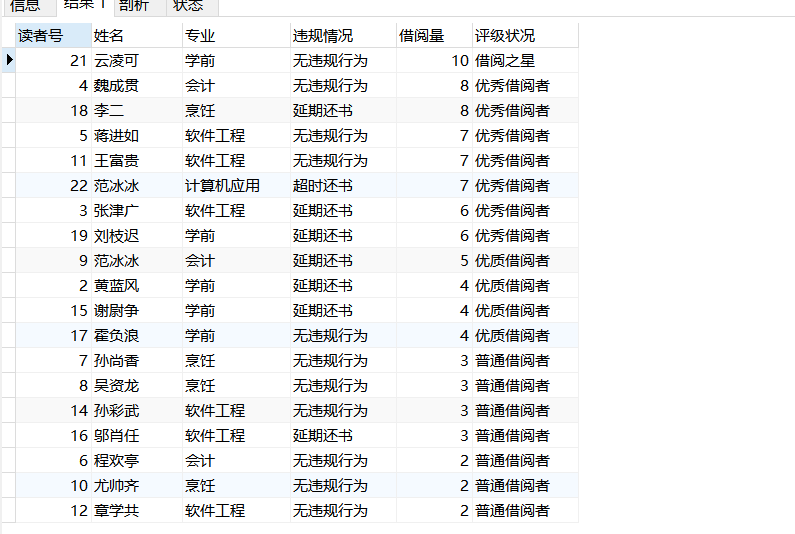
2、多表操作
(1)要求查询读者编号、读者姓名、性别、专业、借阅的书籍、管理员姓名、累积借书、违规情况、借书日期、还书日期并按读者编号升序排列
SELECT
r.gzh_rno AS 读者编号,
r.gzh_rname AS 读者姓名,
r.gzh_rsex AS 性别,
r.gzh_speciality AS 专业,
b.gzh_bname AS 借阅的书籍,
l.gzh_lname AS 管理员姓名,
r.gzh_rnum AS 累积借书,
r.gzh_remarks AS 违规情况,
w.gzh_jtime AS 借书日期,
w.gzh_htime AS 还书日期
FROM
gzh_readers r,
gzh_books b,
gzh_librarian l,
gzh_borrow w
WHERE
w.gzh_rno = r.gzh_rno
AND w.gzh_bno = b.gzh_bno
AND w.gzh_lno = l.gzh_lno
ORDER BY
r.gzh_rno ASC;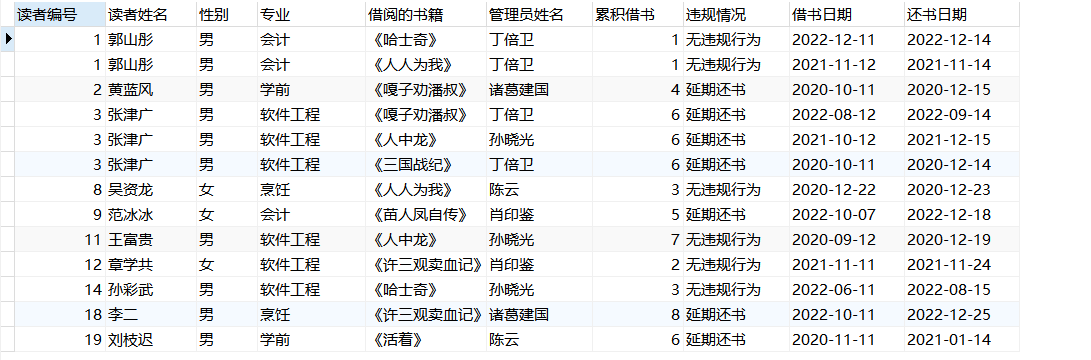
(2)查询借书总天数>200天读者的所有借阅情况(可能有多次借书的经历),包括读者号、姓名、借书、还书日期以及借书总天数,并按借书总天数降序排列。
select r.gzh_rno as 读者号,r.gzh_rname as 读者姓名,w.gzh_jtime as 借书日期,w.gzh_htime as 还书日期
,(w.gzh_htime-w.gzh_jtime) as 借书总天数
from gzh_readers r
inner join gzh_borrow w
on r.gzh_rno=w.gzh_rno
HAVING 借书总天数>200
ORDER BY 借书总天数 desc;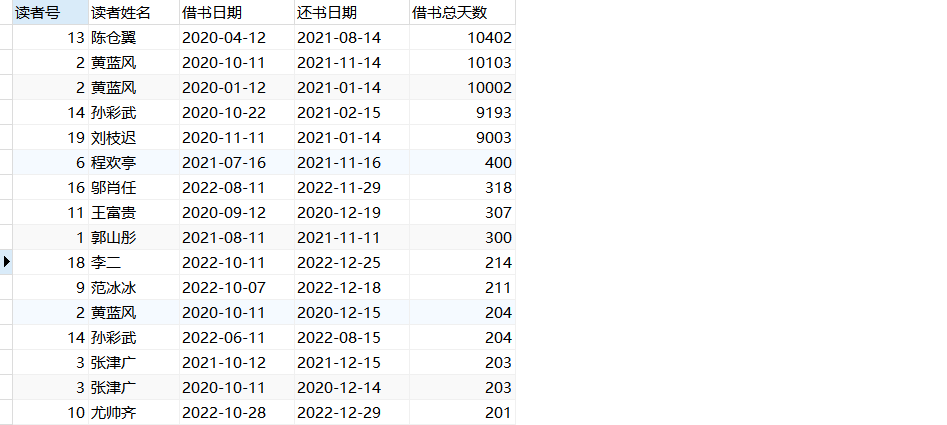
(3)查询借阅书籍时间>200天的读者名字、读者号,且读者号为5~10
SELECT
gzh_rno as 读者号,gzh_rname as 读者名字
FROM
gzh_readers
WHERE
gzh_rno IN ( SELECT gzh_rno FROM gzh_borrow
WHERE ( gzh_htime - gzh_jtime )> 200 )
and gzh_rno BETWEEN 5 and 10;
(4)查询专业为“软件工程”且读者号大于等于10的读者借阅书籍的情况,包括读者的基本信息和借阅情况
select * from gzh_readers r left join gzh_borrow w
on r.gzh_rno=w.gzh_rno where r.gzh_speciality='软件工程' and r.gzh_rno>=10;
(5) 查询姓周的书籍管理人员的姓名以及被该管理人员借记过书籍的读者姓名、专业、书籍名
select r.gzh_rname as 读者姓名,r.gzh_speciality as 专业,
l.gzh_lname as 管理人员姓名,b.gzh_bname as 书籍名字
from gzh_readers r,gzh_librarian l,gzh_borrow w,gzh_books b
where r.gzh_rno=w.gzh_rno and w.gzh_lno=l.gzh_lno and w.gzh_bno=b.gzh_bno
and l.gzh_lname like '周%';
(6) 学校现想统计出版社借阅总量>=2的借阅信息,要求输出出版社的名称、借阅数量,并按借阅量降序排列
select b.gzh_press as 出版社,count(*) as 借阅量
from gzh_books b,gzh_borrow w
where b.gzh_bno=w.gzh_bno
GROUP BY gzh_press
Having 借阅量>=2
ORDER BY 借阅量 desc;
(7) 查询被借阅最多的前三本书籍,要求输出书籍名称,出版社,借阅量并按借阅量降序排列
select b.gzh_bname as 书籍名称,b.gzh_press as 出版社,count(*) as 借阅量
from gzh_books b,gzh_borrow w
where w.gzh_bno=b.gzh_bno
group by b.gzh_bno
order by 借阅量 desc
limit 0,3;
八、求关系模式的候选码
给出一个关系模式R<U,F>,其中U={A,B,C,D,E,F,G},F={ABC,CD
E,E
A,A
G},求候选码
候选码选取规则:
1、只在右边出现的属性,不属于候选码;
2、只在左边出现的属性,一定存在于某候选码当中;
3、外部属性一定存在于任何候选码当中;4、其他属性逐个与2,3的属性组合,求属性闭包,直至X的闭包等于U,若等于U,则X为候选码。
L:A,B,C,D,E
R:C,E,A,G
N: F
1、只在右边出现的一定不是候选码,所以候选码不包含G
2、在左边出现的B、D,属于主属性,一定存在于某候选码当中
3、既不出现在左边又不出现在右边的F,属于主属性,一定存在于某候选码当中
所以有可能是候选码的是BDF、BDCF、BDEF、BDAF
(BDF)+BDF
U
(BDCF)+BDCFEAG=U
(BDEF)+BDEFAGC=U
(BDAF)+BDAFGCE=U
注:(X)+是表示属性闭包,用我的话来解释一下闭包,就是包括元素本身以及以它为基点,所能推导出的所有元素组成的一个集合。
所以由上可知候选码是BDCF、BDEF、BDAF这三个,最小函数依赖集为 F={ABC,CD
E,E
A,A
G}
再来一道题目练练手
设有关系模式R(A,B,C,D,E),其上的函数依赖集:U={A→BC,CD→E,B→D,E→A},求出R的所有候选关键字。
解:
L:A,B,C,D,E
R:A,B,C,D,E
N:无
乍一看,怎么和我们上述做的不一样呢?其实都是一样的。左右边都没有单独出现元素,所以无法判断候选码包含哪个元素。A,B,C,D,E和两两组合都有可能是候选码。
(A)+
BCDEA=U,所以A是候选码,所以和A组合的诸如AB、AC等都可以排除。(E)+
(B)+
U,B不是候选码,但BC、BD有可能是候选码
(BC)+
(BD)+
以此类推,可以得到候选码为A,BC,CD,E。
九、最小函数依赖集
求解最小函数依赖集分三步:
1、将F中的所有依赖右边化为单一元素
2、去掉F中所有冗余依赖关系
3、去掉F中的所有依赖左边的冗余属性
给出一个关系模式R<U,F>,其中U={A,B,C,D,E,F,G,H,I,J},F={ABDE,AB
G,B
F,C
J,CJ
I,G
H},求最小函数依赖集
1、将F中的所有依赖右边化为单一元素
F={ABDE,AB
G,B
F,C
J,CJ
I,G
H}
2、去掉F中所有冗余依赖关系
简单来说,从第一个函数依赖XY开始将其从F中去掉,然后在剩下的函数依赖中求X的闭包X+,看X+是否包含Y,若是,则去掉X
Y;否则不能去掉,依次下去直到找不到冗余的函数依赖。
(1)去掉ABDE,(ABD)+
ABDGFH,不包含E,所以不冗余,不能去掉。
(2)去掉 ABG,(AB)+
ABF,不包含G,所以不冗余,不能去掉。
(3)去掉 BF,(B)+
B,不包含F,所以不冗余,不能去掉。
(4)去掉CJ,(C)+
C,不包含J,所以不冗余,不能去掉。
(5)去掉CJI,(CJ)+
CJ,不包含I,所以不冗余,不能去掉。
(6)去掉GH,(G)+
G,不包含H,所以不冗余,不能去掉。
所以,F= {ABDE,AB
G,B
F,C
J,CJ
I,G
H}
3、去掉F中的所有依赖左边的冗余属性
简单来说,一个一个地检查函数依赖左部非单个属性的依赖。例如XYA,若要判断Y为多余元素,则以X
A代替XY
A是否等价?若A属于(X)+,则Y是多余属性,可以去掉。同理,若要判断X多余元素, 则以Y
A代替XY
A看是否等价。
(1)ABDE去掉A,(BD)+
BDF不包含E,同理可得BD都不是冗余元素。
(2)ABG,因为G只能由AB推出,所以AB都不是冗余元素。
(3)CJI,去掉C,(J)+
J,不包含I,所以C不能去掉;去掉J,(C)+
CJI,包含I,所以J是冗余元素。CJ
I变为C
I。
综上所诉,所求的最小函数依赖集为F={ABDE,AB
G,B
F,C
J,C
I,G
H} ,只有一个候选码,且为ABDC
十、模式分解
例题:U=(A,B,C,D,E) ,F={ABC,C
B,D
E,D
C} 若R不是3NF,将R分解为无损且保持函数依赖的3NF。
我们先把前面的知识串起来,先求候选码,再求函数依赖,再进行模式分解
L:A,B,C,D
R:B,C,E
N:无
可能候选码:AD、ADB、ADC
(AD)+ADECB=U,所以候选码是AD,且为唯一候选码
最小函数依赖:
1、所有右边已经是单一元素了,不用拆分
2、去掉F中所有冗余依赖关系
去掉ABC,(AB)+
AB,不包含C,所以不冗余,不能去掉
去掉CB,(C)+
C,不包含B,所以不冗余,不能去掉
去掉DE,(D)+
DCB,不包含E,所以不冗余,不能去掉
去掉DC,(D)+
DE,不包含C,所以不冗余,不能去掉
所以, F={ABC,C
B,D
E,D
C}
3、去掉F中的所有依赖左边的冗余属性
ABC,去掉B,(A)+
A,不包含C,B不是冗余元素,不能去掉,同理A也不是冗余元素。
故最小函数依赖集为Fm= {ABC,C
B,D
E,D
C}
模式分解:
已知候选码为AD,为第一范式,原因如下:
在关系模式中若没有非主属性对码的部分函数依赖即可称为2NF。何为主属性?候选码里的每个元素都属于主属性,比如:A,D。何为非主属性?剩下的即是,B,C,E。如何解读范式那句话?因为D
第一步:左部相同原则分组:对Fm按具有相同左部的原则分组,然后左部∪右部。
U1=ABC U2=BC U3=DCE( DE,D
C由于具有相同的左部,故进行合并)
第二步:看有没有包含关系,有的话,合并吸收。
将R分解为
ρ={ R1({A,B,C},{ABC}),
R2({B,C},{CB}),
R3({D,C,E},{DE,D
C}) }
我们可以看见R1,R2存在包含关系,
故进行合并吸收
ρ={ R1({A,B,C},{ABC,C
B}),
R2({D,C,E},{DE,D
C}) }
第三步:判断是不是无损连接
若关系模式R(U,F)中,被分解为p={R1, R2}是R的⼀个分解,若R1∩R2 R1 - R2或者R1∩R2
R2 - R1,则为无损连接。
R1∩R2为C,R1-R2=AB,C不能推出AB,即 R1∩R2 不能推出R2 - R1,故不是无损连接,需添加候选码R3({A,D},{∅})。
所以模式分解的结果为:
ρ={ R1({A,B,C},{ABC,C
B}),
R2({D,C,E},{DE,D
C}) ,
R3({A,D},{∅}) }
严正声明:创作不易,白嫖有罪,拒绝白嫖,欢迎支持博主。您的支持是我进步最大的动力!!!



















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









