









金融大数据分析-练习六
数据描述:
标准普尔500指数和股票市场分析
标准普尔500指数(S&P 500指数)也被称为标准普尔指数,是一个市值加权的指数,包括美国领先的500家公开交易公司。
现有来自标准普尔500指数自2010年1月至2024年6月的元数据,该股票市场指数追踪的是在美国证券交易所上市的500家大型公司的表现。截至2020年12月31日,超过5.4万亿美元投资于与该指数表现相关的资产。
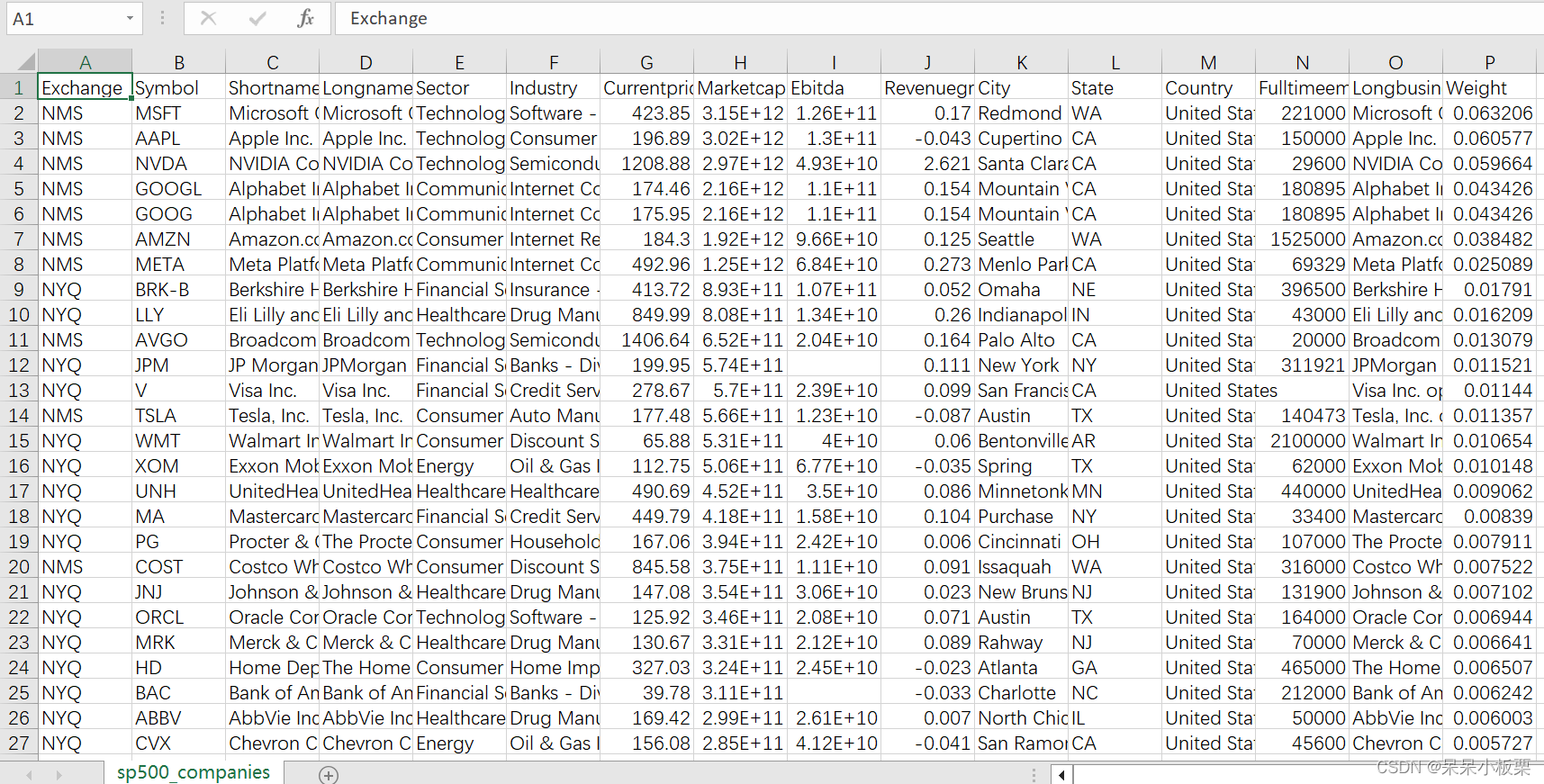
元数据文件【sp500_companies.csv】中包含16个字段:
- Exchange - 股票被谈判的交易所
- Symbol - 股票代码
- Shortname - 公司简称
- Longname - 公司全称
- Sector - 公司经营的行业
- Industry - 公司经营行业下属领域
- Currentprice - 目前股价
- Marketcap - 当前市值
- Ebitda - 息税折旧摊销前利润
- Revenuegrowth - 收入增长
- City - 所在城市
- State - 所在州
- Country - 所在国
- Fulltimeemployees - 全职员工数量
- Longbusinesssummary - 公司概要
- Weight - 权重比
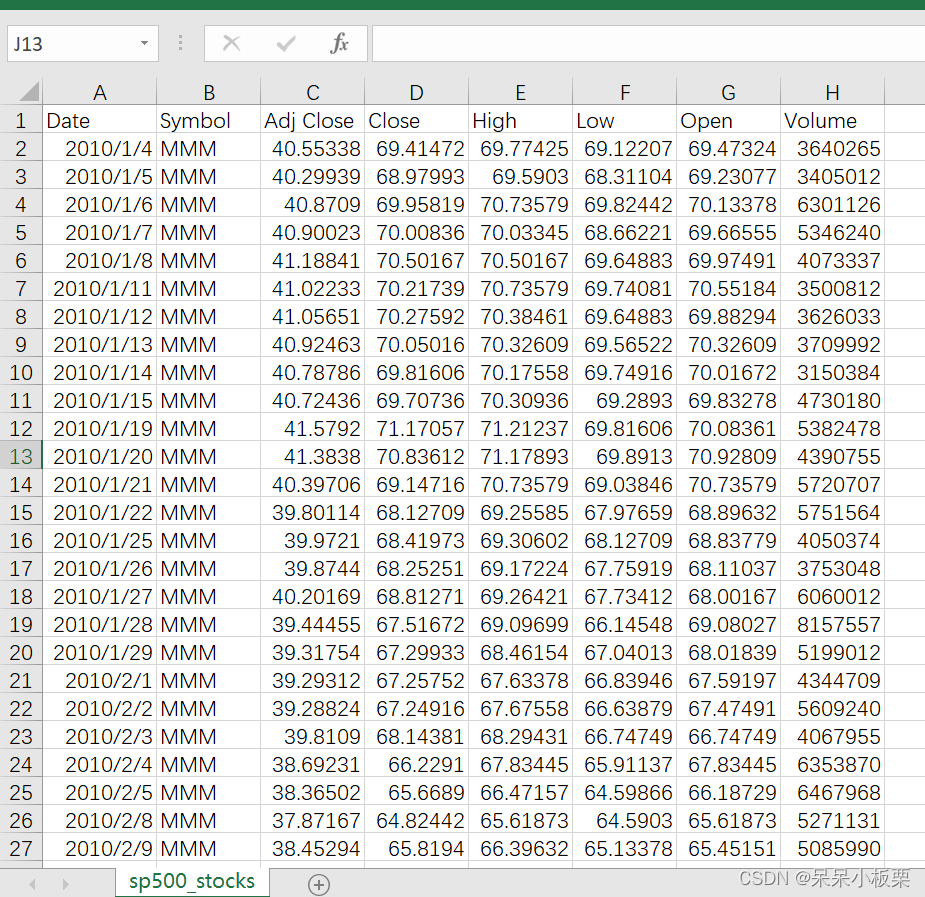
元数据文件【sp500_stocks.csv】中包含8个字段:
- Date - 日期
- Symbol - 公司代码/股票代码
- Adj Close - 类似收盘价,也考虑了股息和拆股等公司行为
- Close - 收盘价
- High - 周期内最大值
- Low - 周期内最小值
- Open - 开盘价
- Volume - 交易量
基于以上两个数据文件中的数据内容,完成以下任务。
问题一
1、要求
任务1 —— 数据读取与预处理
- 编写python代码,用read_csv函数读取sp500_stocks.csv文件【注意:由于文件数据行数过大,可能会导致在用Microsoft或WPS软件打开时显示数据不完整】。
- 对读取的原始数据进行清洗,对数据中具有NaN空值的数据进行去除,再将除日期和股票代码列之外的列进行切分,存于一个新的对象x中。
- 为了避免后续训练过程中造成模型失真,需要对x进行标准化处理,使用均值-方差规范化模块对其进行处理。处理后将返回的结果赋值回给x。
- 将处理好的x赋值回给切分前的数据框中,保持原始的日期和股票代码列不变。
- 对股票代码列进行筛选,筛选出统计出现3632次的所有股票代码,存于一个list列表对象stkcd中。
- 用read_csv函数读取sp500_companies.csv文件。
- 对读取的文件进行切分,选取出需要进行分析的字段,包括:股票代码、公司简称、公司经营的行业、目前股价、当前市值、息税折旧摊销前利润、收入增长、全职员工数量。将切分的数据存于新的数据框df2中。
- 对df2进行切分,把除股票代码、公司简称、公司经营的行业列之外的列进行切分,存于一个新的对象x2中,对x2具有NaN空值的数据进行填充,选择均值填充策略。对x2进行均值-方差标准化处理,处理后将返回的结果赋值回给x2,保持原始的股票代码、公司简称、公司经营的行业列不变。
2、代码(仅供参考)
# 任务一 数据读取与预处理
# 导入所需库
import pandas as pd
# 导入均值-方差规范化模块StandardScaler
from sklearn.preprocessing import StandardScaler
# 读取sp500_stocks.csv文件
df = pd.read_csv('E:/金融大数据分析/sp500_stocks.csv')
# print(df.head())
# 数据清洗,去除具有NaN空值的数据
df.dropna(inplace=True)
# 切分数据,除日期和股票代码列之外的列存于一个新的对象x中
x = df.drop(['Date', 'Symbol'], axis=1)
# print(x.head())
# 标准化处理,对x进行均值-方差规范化处理
# 创建均值-方差规范化对象scaler
scaler = StandardScaler()
# 调用fit()拟合方法,对数据x进行拟合训练
scaler.fit(x)
# 调用transform()方法,返回规范化后的数据,并将处理后将返回的结果赋值回给x
x = scaler.transform(x)
# print(x)
# 将处理好的x赋值回给切分前的数据框中,保持原始的日期和股票代码列不变
df.iloc[:, 2:] = x
# print(df)
# 筛选出统计出现3632次的所有股票代码,存于一个list列表对象stkcd中
stkcd = df['Symbol'].value_counts()[df['Symbol'].value_counts() == 3632].index.tolist()
# print(stkcd)
# 读取sp500_companies.csv文件
df2 = pd.read_csv('E:/金融大数据分析/sp500_companies.csv')
# print(df2.head())
# 切分数据,选取需要进行分析的字段,将切分的数据存于新的数据框df2中
df2 = df2[['Symbol', 'Shortname', 'Sector', 'Currentprice', 'Marketcap', 'Ebitda', 'Revenuegrowth', 'Fulltimeemployees']]
# print(df2.head())
# 切分数据,除股票代码、公司简称、公司经营的行业列之外的列存于一个新的对象x2中
x2 = df2.drop(['Symbol', 'Shortname', 'Sector'], axis=1)
# print(x2)
# 对x2具有NaN空值的数据进行填充,选择均值填充策略
x2.fillna(x2.mean(), inplace=True)
# print(x2)
# 对x2进行均值-方差标准化处理,处理后将返回的结果赋值回给x2
x2 = scaler.fit_transform(x2)
# print(x2)
# 保持原始的股票代码、公司简称、公司经营的行业列不变
df2.iloc[:, 3:] = x2
# print(df2)问题二
1、要求
任务2 —— 主成分分析提取排名(20分)
- 对标准化之后的指标数据x2作主成分分析,提取其主成分,要求累计贡献率在95%以上。
- 计算综合得分,其中综合得分等于提取的各个主成分与其贡献率的加权求和,整理排名结果,并采用降序序列作为排名结果的储存数据结构,index为股票代码,存为对象Fscore1。
- 根据前面任务中的列表对象stkcd,用isin函数筛选出Fscore1中的index和stkcd共同具有的股票代码,筛选后赋值回给Fscore1。
- 根据筛选后的序列Fscore1,把排名前40的股票代码、公司简称、得分,存到一个新的数据框df3中后,打印输出df3的结果。
2、代码(仅供参考)
# 任务二 主成分分析提取排名
# 导入主成分分析模块
from sklearn.decomposition import PCA
import numpy as np
import pandas as pd
# 对标准化之后的指标数据x2作主成分分析,提取其主成分,要求累计贡献率在95%以上
pca = PCA(n_components=0.95) #累计贡献率为95%
# 调用fit()方法,对数据进行拟合训练
pca.fit(x2)
# 调用transform()方法,返回提取的主成分
Y = pca.transform(x2)
# print(Y)
# 贡献率
gxl = pca.explained_variance_ratio_
# print(gxl)
# 计算综合得分,其中综合得分等于提取的各个主成分与其贡献率的加权求和
F = np.zeros((len(Y)))
for i in range(len(gxl)):
f = Y[:, i] * gxl[i]
F = F + f
# 整理排名结果,并采用降序序列作为排名结果的储存数据结构,index为股票代码,存为对象Fscore1
Fscore1 = pd.Series(F, index=df2['Symbol'])
Fscore1 = Fscore1.sort_values(ascending=False) #降序,True为升序
# print(Fscore1)
# 根据前面任务中的列表对象stkcd,用isin函数筛选出Fscore1中的index和stkcd共同具有的股票代码
Fscore1 = Fscore1[Fscore1.index.isin(stkcd)]
# print(Fscore1)
# 根据筛选后的序列Fscore1,把排名前40的股票代码、公司简称、得分,存到一个新的数据框df3中后,打印输出df3的结果
df3 = Fscore1.head(40).reset_index()
df3.columns = ['Symbol', 'FScore1'] # 重命名第二列列名为'FScore1'
# 使用merge方法将两个DataFrame按照Symbol列进行合并
df3 = pd.merge(df3, df2[['Symbol', 'Shortname']], on='Symbol', how='left')
# 重新调整列的顺序
df3 = df3[['Symbol', 'Shortname', 'FScore1']]
print(df3)
问题三
1、要求
任务3 —— 收益率计算与绘制(20分)
- 对任务2中得到的排名前40的股票代码计算其收益率,这里使用类似收盘价来计算其收益率。考虑年份为近5年,即2019-2023年,持有期在每年1月1日至12月31日之间,每只股票的收益率计算方法为:以该股票持有期内首个交易日类似收盘价p1买入,持有期内最后交易日的类似收盘价p2卖出,计算其收益率,收益率计算公式为:(p2-p1)/p1。
- 基于此任务,需要对任务1中最后获得的数据框进行切分筛选,限制时间年份在2019年到2023年时间内的数据。还要考虑持有期在1月1日至12月31日之间。
- 根据时间筛选出的数据,找到每支股票的首个交易日和最后交易日的类似收盘价。计算出(p2-p1)/p1的收益率。把计算得到的40支股票5年的200个收益率结果直接放置于一个列表r_list中。
- r_list中,每40个数据为一组代表一个年份的收益率,绘制出每个年份每支股票的收益率柱状图,其中x轴为各个股票代码,y轴为当下年份的收益率,共5张图像。请使用plt.show()或plt.savefig()来显示或保存图像。
2、代码(仅供参考)
# 任务三 收益率计算与绘制
import matplotlib.pyplot as plt
from matplotlib import rcParams
# 定义年份范围2019-2023年
years = list(range(2019, 2024))
# 初始化r_list存储所有年份的收益率
r_list = []
# 遍历每个年份
for year in years:
# 构造当年的起始和结束日期字符串,持有期在每年1月1日至12月31日之间
start_date = f'{year}-01-01'
end_date = f'{year}-12-31'
# 筛选对应年份的数据
df_year = df[(df['Date'] >= start_date) & (df['Date'] <= end_date)]
# 初始化该年所有股票的收益率列表
yearly_returns = []
# 遍历排名前40的股票代码
for stock_code in df3['Symbol']:
# 获取该股票在当年的数据
stock_data = df_year[df_year['Symbol'] == stock_code]
# 确保数据存在且至少有两个点以计算收益率
if len(stock_data) > 1:
# 找到首尾交易日的收盘价
p1 = stock_data.iloc[0]['Close']
p2 = stock_data.iloc[-1]['Close']
# 计算收益率,收益率计算公式为:(p2-p1)/p1
return_rate = (p2 - p1) / p1
yearly_returns.append(return_rate)
else:
# 若数据不足,可视为无数据
yearly_returns.append(np.nan)
# 将该年的收益率列表添加到r_lists中
r_list.append(yearly_returns)
# 设置字体为SimHei显示中文
rcParams['font.family'] = ['sans-serif']
rcParams['font.sans-serif'] = ['SimHei']
rcParams['axes.unicode_minus'] = False # 解决负号'-'显示为方块的问题
# 绘制每年的收益率柱状图
for idx, yearly_returns in enumerate(r_list):
year = years[idx]
fig, ax = plt.subplots(figsize=(12, 6))
ax.bar(df3['Symbol'], yearly_returns, color='skyblue')
ax.set_title(f'排名前40的股票代码{year}年度收益率')
ax.set_xlabel('股票代码')
ax.set_ylabel('收益率')
plt.xticks(rotation=90)
plt.tight_layout()
plt.savefig(f'E:/金融大数据分析/img/排名前40的股票代码{year}年度收益率.png') # 保存图像
plt.show() # 显示图像问题四
1、要求
任务4 —— 趋势预测(20分)
- 选择Fscore1中得分排名第一的股票代码,筛选sp500_stocks.csv中所有时间内的数据。
- 对筛选出的数据进行切分,将2024年1月1日之前的数据作为训练数据,2024年1月1日起至6月7日的数据作为测试数据进行划分。
- 将类似收盘价、收盘价、周期内最大值、周期内最小值、开盘价、交易量作为输入数据指标X,预测指标Y作为决策变量,使用后一个交易日的类似收盘价 - 当前交易日类似收盘价计算,如果大于 0,记为 1;如果小于等于 0,记为 -1。因此进行数据划分时需注意X和Y的长度和日期是否匹配。
- 分别使用支持向量机模型、逻辑回归模型、神经网络模型对数据进行训练预测,并输出所有模型的准确率。
2、代码(仅供参考)
# 任务四 趋势预测
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
# 选择Fscore1中得分排名第一的股票代码
symbol = Fscore1.index[0]
# print(symbol)
# 筛选sp500_stocks.csv中所有时间内的数据
data = df[df['Symbol'] == symbol]
# 对筛选出的数据进行切分,将2024年1月1日之前的数据作为训练数据,2024年1月1日起至6月7日的数据作为测试数据进行划分
train_data = data[data['Date'] < '2024-01-01']
test_data = data[(data['Date'] >= '2024-01-01') & (data['Date'] <= '2024-06-07')]
# 将类似收盘价、收盘价、周期内最大值、周期内最小值、开盘价、交易量作为输入数据指标X,预测指标Y作为决策变量
X_train = train_data[['Adj Close', 'Close', 'High', 'Low', 'Open', 'Volume']]
# 预测指标Y作为决策变量,使用后一个交易日的类似收盘价 - 当前交易日类似收盘价计算,如果大于 0,记为 1;如果小于等于 0,记为 -1。因此进行数据划分时需注意X和Y的长度和日期是否匹配。
y_train = (train_data['Adj Close'].shift(-1) - train_data['Adj Close']).apply(lambda x: 1 if x > 0 else -1)
X_test = test_data[['Adj Close', 'Close', 'High', 'Low', 'Open', 'Volume']]
y_test = (test_data['Adj Close'].shift(-1) - test_data['Adj Close']).apply(lambda x: 1 if x > 0 else -1)
# 分别使用支持向量机模型、逻辑回归模型、神经网络模型对数据进行训练预测,并输出所有模型的准确率
# 使用支持向量机模型进行训练预测
svm = SVC()
svm.fit(X_train, y_train)
y_pred_svm = svm.predict(X_test)
print('支持向量机模型准确率:', accuracy_score(y_test, y_pred_svm))
# 使用逻辑回归模型进行训练预测
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_pred_lr = lr.predict(X_test)
print('逻辑回归模型准确率:', accuracy_score(y_test, y_pred_lr))
# 使用神经网络模型进行训练预测
nn = MLPClassifier()
nn.fit(X_train, y_train)
y_pred_nn = nn.predict(X_test)
print('神经网络模型准确率:', accuracy_score(y_test, y_pred_nn))















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









