






本章记录个人做BOSS直聘爬虫项目时的思路及步骤
背景是,在BOSS直聘网页中,搜索关键词:“爬虫”,城市为:“广州”

1. 搜素关键信息找到具体接口,并用其他页的接口进行比较,下面以第一页和第三页的url比较:
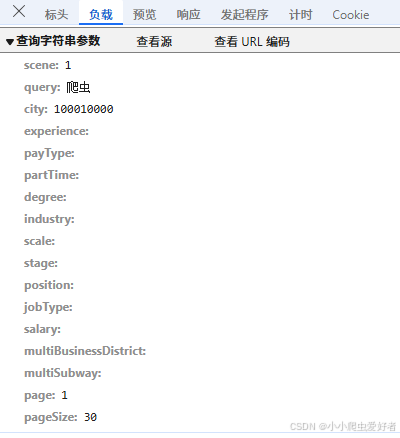
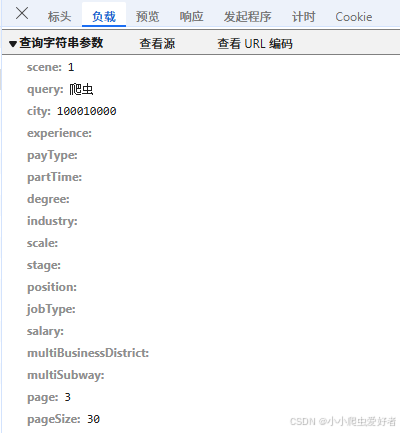
由上图可发现对同一个关键词的搜索中,接口内容只有page(页数)发生改变,因此只需要搞定第一页,通过对page值的修改就可以爬取所有关于“爬虫”的招聘数据。
2. 对于第一页的爬取,需要有以下五个参数:
- scene:通过搜索其他关键词,能发现该值一直不变,因此可以直接设置为1
- query:该值为关键词信息
- city:该值为城市编码
- page:页数
- pageSize:每页显示的数据量
3. query的值可以通过用户输入来获得
query = input("请输入关键词搜索职位")4. city的值需要通过搜索工具查找到对应的接口
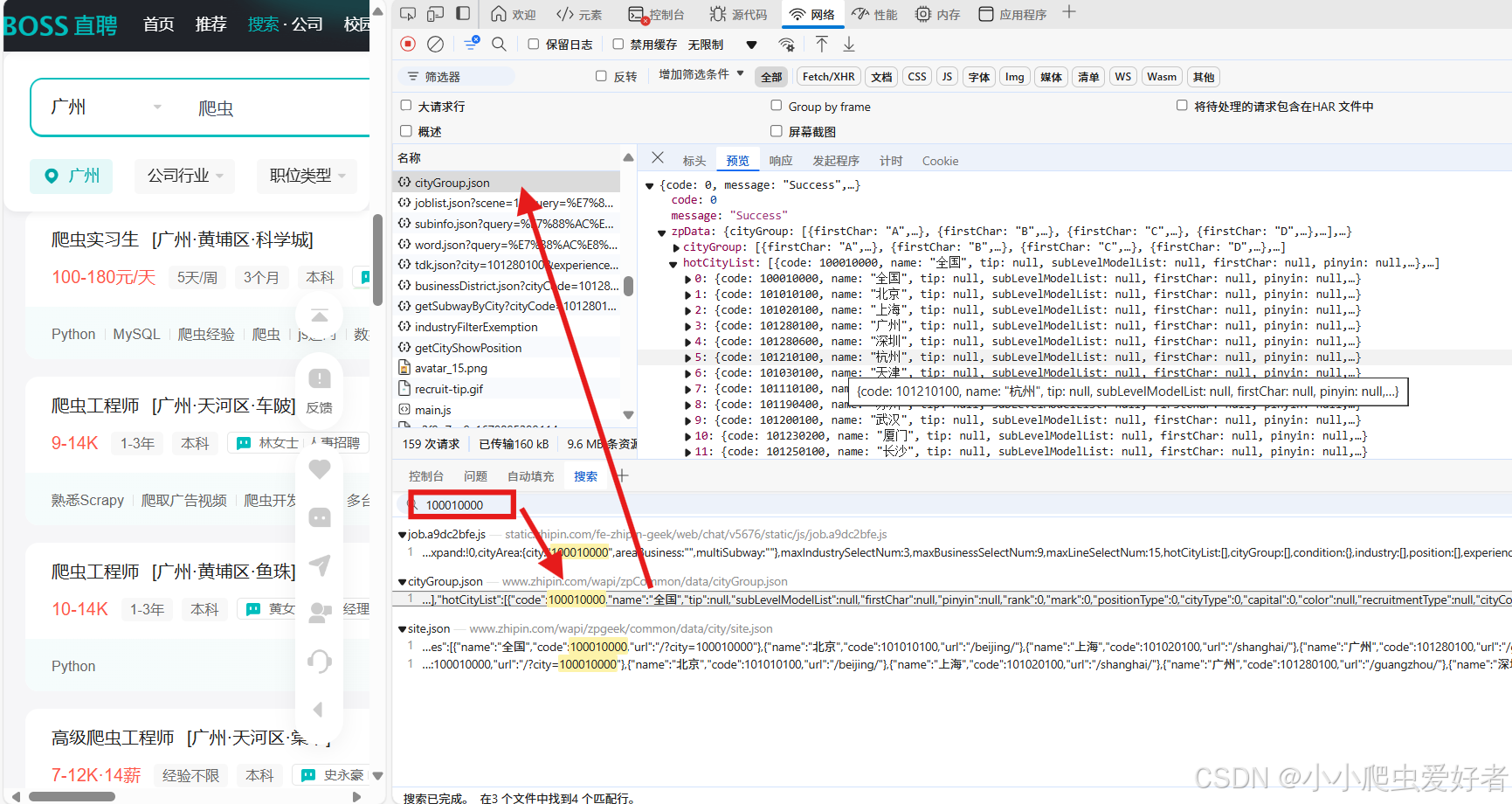
具体代码实现如下:
# 提供city编码
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0'
}
response = requests.get(url='https://www.zhipin.com/wapi/zpCommon/data/cityGroup.json', headers=headers)
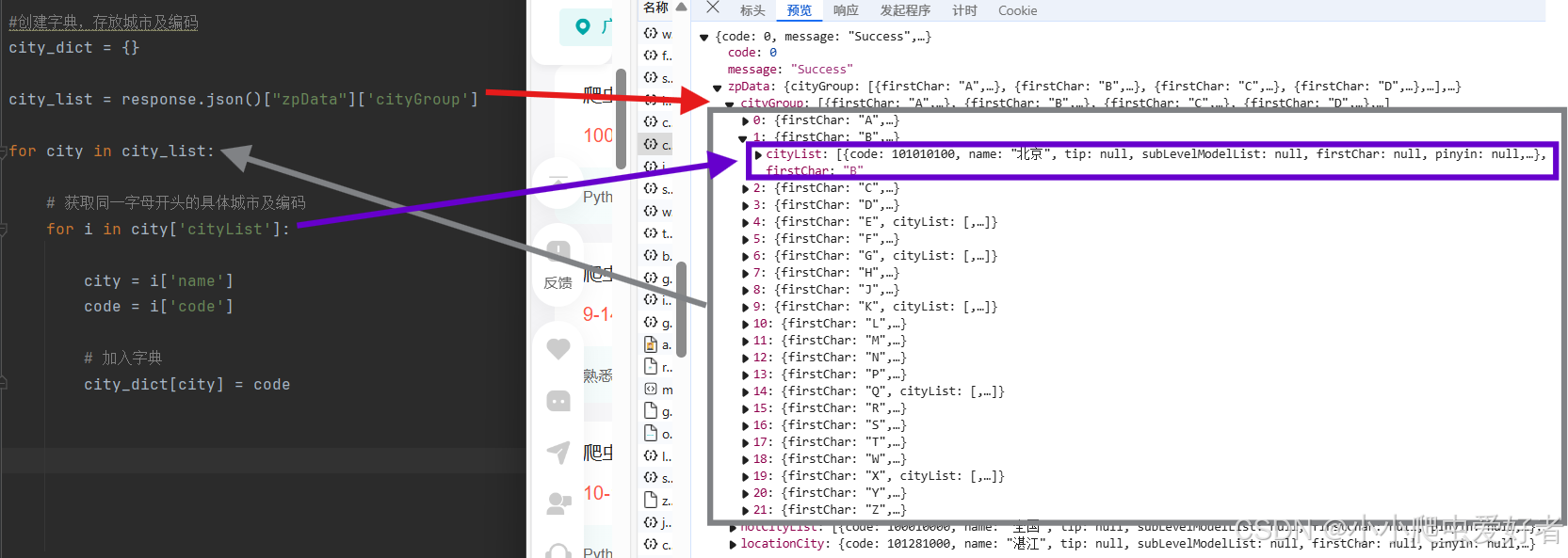
#创建字典,存放城市及编码
city_dict = {}
city_list = response.json()["zpData"]['cityGroup']
for city in city_list:
# 获取同一字母开头的具体城市及编码
for i in city['cityList']:
city = i['name']
code = i['code']
# 加入字典
city_dict[city] = code
5. 先不考虑参数值的获取,先对第一页数据进行爬取
import requests
response = requests.get('https://www.zhipin.com/wapi/zpgeek/search/joblist.json', params=params, cookies=cookies, headers=headers)
json_data = response.json()
job_contents = json_data["zpData"]["jobList"]
for job_content in job_contents:
jobName = job_content['jobName'] #职业名
salaryDesc = job_content['salaryDesc'] #薪资
skills = job_content['skills'] #技术
jobDegree = job_content['jobDegree'] #学历
welfareList = job_content['jobName'] #福利
jobExperience = job_content['jobExperience'] #工作经历
brandName = job_content['brandName'] #公司名
cityName = job_content['cityName'] #城市
bossName = job_content['bossName'] #老板名称
cityName = job_content['cityName'] #城市
encryptJobId = job_content['encryptJobId'] #伏笔1
securityId = job_content['securityId'] #伏笔26. 招聘信息已经成功爬取下来了,但是json里并没有跳转链接,因此接下来的目标是获取到具体职位的跳转链接。
6.1 点击进入任意一个招聘详情页,可以发现url非常的长,如下图
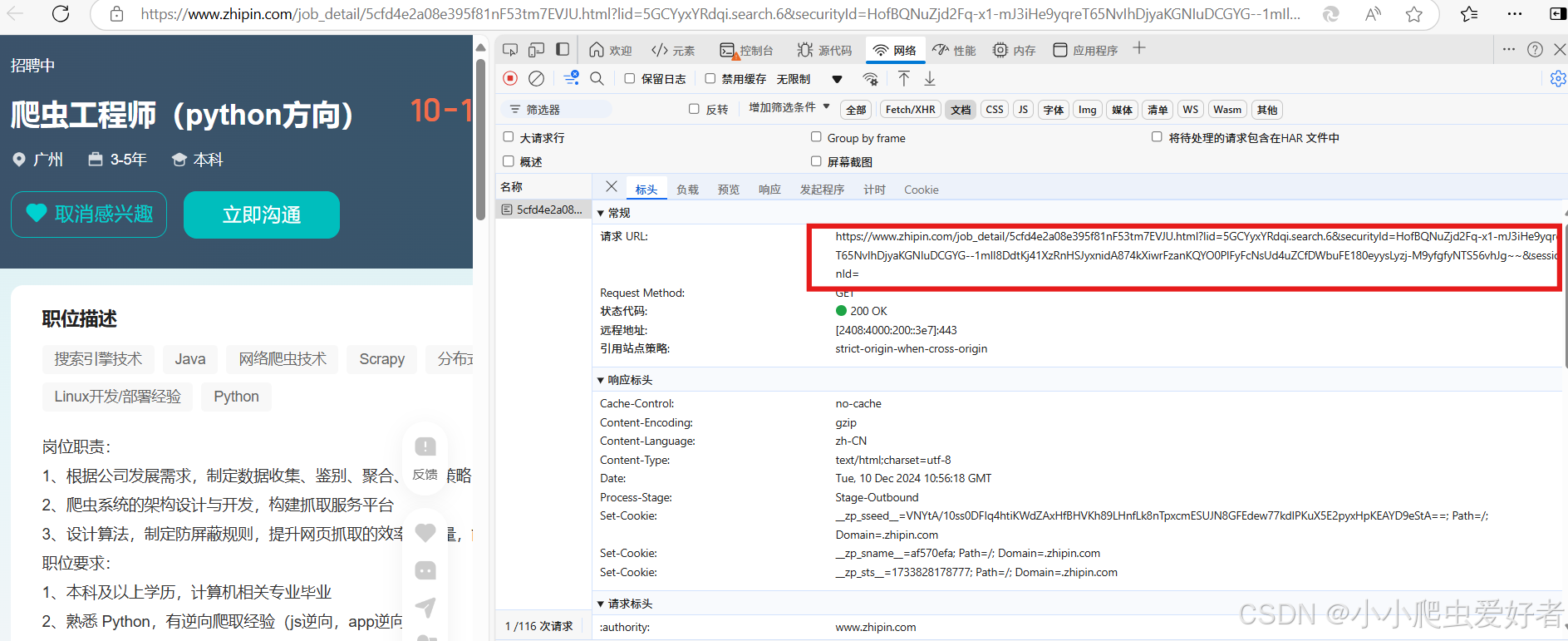
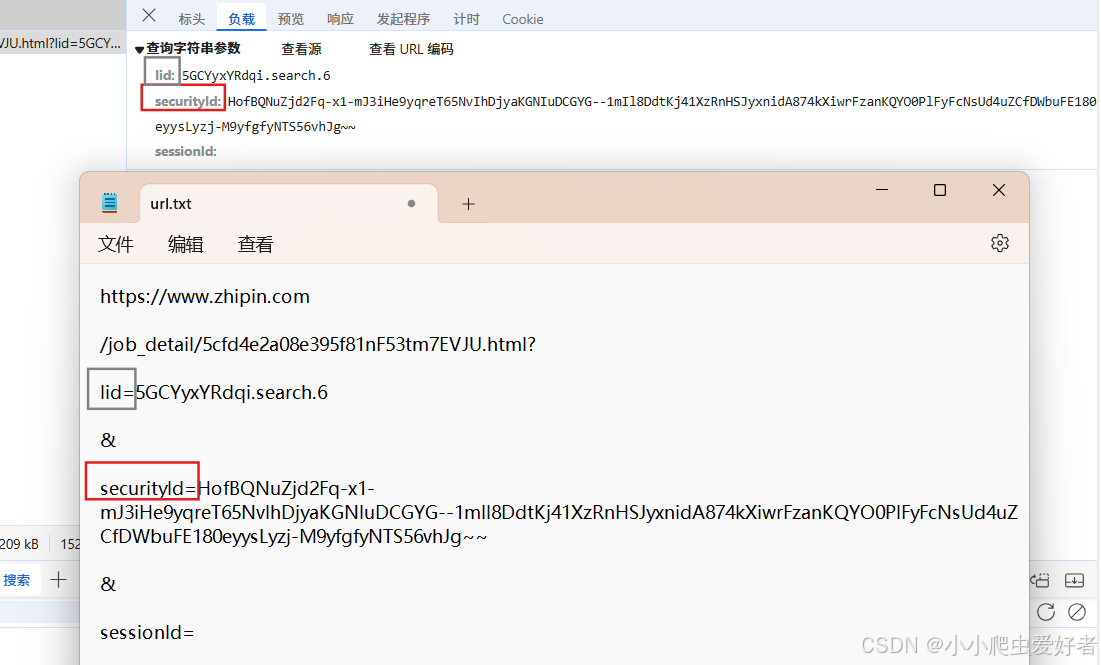
6.2 对该url进行解析,由下图可得出该链接由:
BOSS直聘网址 + 字符串 + lid + securityId + sessionId 组成,只要找到后面四个就可以得到具体链接
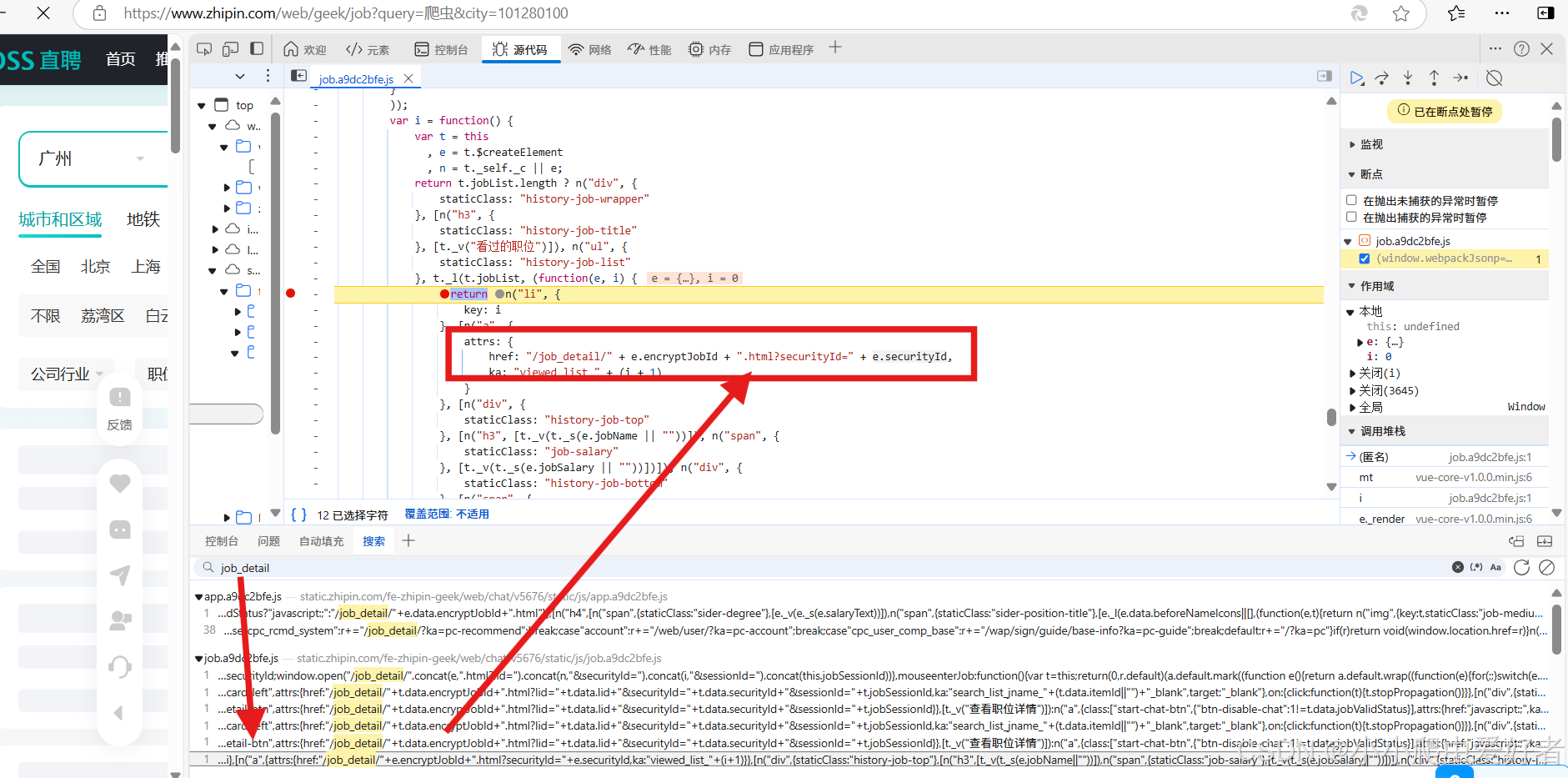
6.3 对于/job_detail/5cfd4e2a08e395f81nF53tm7EVJU.html?的获取,可以通过搜索/job_detail找到具体的加密方法,如下代码所示:
href: "/job_detail/" + e.encryptJobId + ".html?securityId=" + e.securityId具体查找方法如下图:
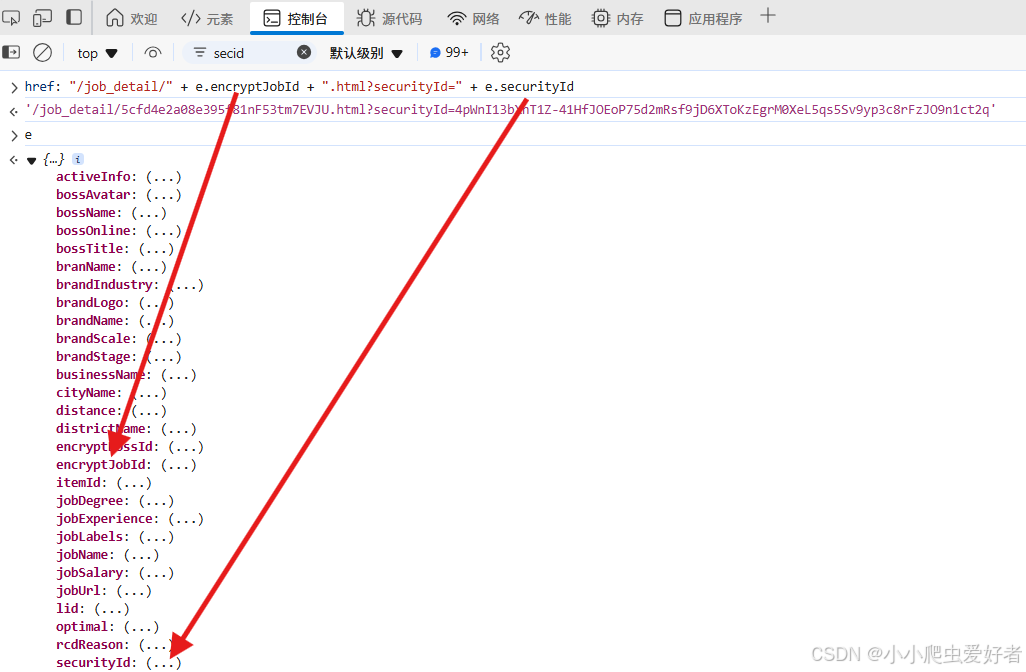
6.4 在控制台输出对应数据,可以发现url是由json中的encryptJobId和securityId组合,这两个值正是步骤5中伏笔1和伏笔2,如下图:
6.5 而最后一个参数sessionId值为空,到此url也能获得了。
7. 代码如下:
供用户输入的功能及获取城市编码:
# 用户提供搜索关键词
def user_input_query():
query = input("请输入职位关键词")
return query
# 用户提供搜索关键词及城市
def user_input_city():
city = input("请输入目标城市")
return city
# 接收城市返回城市编码
def get_code(city):
city_code = city_dict.get(city)
return city_code
while 1:
query = user_input_query()
city = user_input_city()
code = get_code(city)
if code == None:
print("城市不存在,请重新输入")
else:
print(f"正在{city}搜索{query},请稍等")
break获取职位信息:
# 获取到json数据
def get_request(query,city_code,index):
cookies = {
'lastCity': '101281000',
'__g': 'sem_bingpc',
'Hm_lvt_194df3105ad7148dcf2b98a91b5e727a': '1733815947',
'HMACCOUNT': 'C4603FF5FD89DD5B',
'wt2': 'DQ2hpC-SxREB8wHy5UR_O4qaluW35qPJ9KVXv5QgM8eGApk5z0ypsu98w0SL25-oEvW5LpyAhS4PycAKyuPooYw~~',
'wbg': '0',
'zp_at': 'LyeHbf68ytEAiQMeRW6-LCn4NJwmyMxsRCsDEqZKm8Q~',
'ab_guid': '2b362c14-998a-440d-bb02-05eef4dd9395',
'__zp_seo_uuid__': '49f53280-4c27-4cbf-95ec-0408792918f9',
'__l': 'r=https%3A%2F%2Fcn.bing.com%2F&l=%2Fwww.zhipin.com%2Fjob_detail%2Fd26a271e94045f4a1nZ73d-6EldR.html%3FsecurityId%3DuLxGTJgMPVWS1-e1rsVGxSKsL3FywIfBX8gEylrv1njeOrszuB8J7ffbmTYVN4BmMLnaoCQ~%26sessionId%3D&s=3&g=%2Fwww.zhipin.com%2Fsem%2F10.html%3F_ts%3D1733819062714%26sid%3Dsem_bingpc%26qudao%3Dbing_pc_H120003UY5%26plan%3DBOSS-%25E5%25BF%2585%25E5%25BA%2594-%25E5%2593%2581%25E7%2589%258C%26unit%3Dboss%25E7%259B%25B4%25E8%2581%2598-%25E7%25AC%25A6%25E5%258F%25B7%25E8%25AF%258D%26keyword%3Dboss%25E7%259B%25B4%25E8%2581%2598%25E7%25BD%2591%25E9%25A1%25B5%25E7%2589%2588%2528%26msclkid%3D7be2972fe9d11696e67af0781364e48b&friend_source=0&s=3&friend_source=0',
'Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a': '1733830631',
'__zp_stoken__': '63fafOTnDm8K0wrzCujwtCQgICA8%2FJDY5Mhg9OSU6O0A5OTw5Qjk5NBs0KcO4wrzEg3puX8OTQjskOTw8Ozk%2FPDs%2BFDk4xLXCtDg4J8KnwrvEgXhrXcOEW3cPfSXDpMK5D0XCuwrEgMODJynCgcK4QzQ8NlbCvjTCvgbCu0PCvgTCuzbCuTQ0NjYpOAxbDw44NEVHXgZGYUZUXFIET0pNJjY9PTvDo8K4w7YnOQQGBhMEDQ8PCg0LCQkJDg4MDAkODQ8PCg0zOcKcw4PEvMSgxLrCjsSYxabDjcKxxIXChsOTw4DEvcO%2Bw6fCrcOFw7TDpcKIw4zCssOiw73DucKXxIPCpcS5wo3Ds0nDhcKuw43CrMOdworDi8K4w7vChsKgwrbDrcK0wo7Dg8Khw4DDv8K6xIJcw7hMwpDCrsKwT8K9VsKIR8KnYsK4wrzCvMKpUU7CsEnDgMK7wprCtFTCuEVsXHbCrMK7woJ1fXbCvltycl1fYA0OP1hHDsOI',
'bst': 'V2R98gEOP43VtiVtRuzBkQKSy27DrVxyg~|R98gEOP43VtiVtRuzBkQKSy27DrezCw~',
'__c': '1733815946',
'__a': '51952642.1728739453.1728742713.1733815946.50.3.45.45',
}
headers = {
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'priority': 'u=1, i',
'referer': 'https://www.zhipin.com/web/geek/job?query=%E7%88%AC%E8%99%AB&city=101280100',
'sec-ch-ua': '"Microsoft Edge";v="131", "Chromium";v="131", "Not_A Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'token': 'yPy6F3g6gvwbyWll',
'traceid': 'F-c504e2QZW7X1Ubx6',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0',
'x-requested-with': 'XMLHttpRequest',
'zp_token': 'V2R98gEOP43VtiVtRuzBkQKSy27DrVxyg~|R98gEOP43VtiVtRuzBkQKSy27DrezCw~',
}
params = {
'scene': '1',
'query': query,
'city': city_code,
'experience': '',
'payType': '',
'partTime': '',
'degree': '',
'industry': '',
'scale': '',
'stage': '',
'position': '',
'jobType': '',
'salary': '',
'multiBusinessDistrict': '',
'multiSubway': '',
'page': index,
'pageSize': '30',
}
response = requests.get('https://www.zhipin.com/wapi/zpgeek/search/joblist.json', params=params, cookies=cookies, headers=headers)
response.raise_for_status()
json_data = response.json()
return json_data
# 获取招聘详细信息
def get_data(json_data,f):
job_contents = json_data["zpData"]["jobList"]
for job_content in job_contents:
jobName = job_content['jobName'] #职业名
salaryDesc = job_content['salaryDesc'] #薪资
skills = job_content['skills'] #技术
jobDegree = job_content['jobDegree'] #学历
welfareList = job_content['jobName'] #福利
jobExperience = job_content['jobExperience'] #工作经历
brandName = job_content['brandName'] #公司名
cityName = job_content['cityName'] #城市
bossName = job_content['bossName'] #老板名称
# 链接加密
encryptJobId = job_content['encryptJobId'] #伏笔1
securityId = job_content['securityId'] #伏笔2
url = "https://www.zhipin.com/job_detail/" + encryptJobId + ".html?securityId=" + securityId
f.write(f"{jobName}, {salaryDesc}, {skills}, {jobDegree}, {jobExperience}, {brandName}, {cityName}, {bossName}, {welfareList}, {url}")
完整代码如下:
import requests
from city import city_dict #导入城市-编码字典
# 获取到json数据
def get_request(query,city_code,index):
cookies = {
'lastCity': '101281000',
'__g': 'sem_bingpc',
'Hm_lvt_194df3105ad7148dcf2b98a91b5e727a': '1733815947',
'HMACCOUNT': 'C4603FF5FD89DD5B',
'wt2': 'DQ2hpC-SxREB8wHy5UR_O4qaluW35qPJ9KVXv5QgM8eGApk5z0ypsu98w0SL25-oEvW5LpyAhS4PycAKyuPooYw~~',
'wbg': '0',
'zp_at': 'LyeHbf68ytEAiQMeRW6-LCn4NJwmyMxsRCsDEqZKm8Q~',
'ab_guid': '2b362c14-998a-440d-bb02-05eef4dd9395',
'__zp_seo_uuid__': '49f53280-4c27-4cbf-95ec-0408792918f9',
'__l': 'r=https%3A%2F%2Fcn.bing.com%2F&l=%2Fwww.zhipin.com%2Fjob_detail%2Fd26a271e94045f4a1nZ73d-6EldR.html%3FsecurityId%3DuLxGTJgMPVWS1-e1rsVGxSKsL3FywIfBX8gEylrv1njeOrszuB8J7ffbmTYVN4BmMLnaoCQ~%26sessionId%3D&s=3&g=%2Fwww.zhipin.com%2Fsem%2F10.html%3F_ts%3D1733819062714%26sid%3Dsem_bingpc%26qudao%3Dbing_pc_H120003UY5%26plan%3DBOSS-%25E5%25BF%2585%25E5%25BA%2594-%25E5%2593%2581%25E7%2589%258C%26unit%3Dboss%25E7%259B%25B4%25E8%2581%2598-%25E7%25AC%25A6%25E5%258F%25B7%25E8%25AF%258D%26keyword%3Dboss%25E7%259B%25B4%25E8%2581%2598%25E7%25BD%2591%25E9%25A1%25B5%25E7%2589%2588%2528%26msclkid%3D7be2972fe9d11696e67af0781364e48b&friend_source=0&s=3&friend_source=0',
'Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a': '1733830631',
'__zp_stoken__': '63fafOTzDmsK4w4LCujksBQYIDQ5DKjY8Mx9COTA7Nz45PD01PDk8NRc6KSXCvMOVwoJuWsOSNTUkPD1ANTk6PTdAFDw5xLnCujg9JsOZwrXDm3tqYcOKW8KCDsKBK8OkwrwOScK1CsO1w4IrJ8KBwr1COEI2Y8K%2FOMOABsK%2BQsOCCsK7Q8K4ODo2Qyg0ElsKDzQ6RVJfCkhhU1VgTARKS1EoNjg8N8OdwrjEgyY1CgYTEggTDwoLEQUJDAgSEAwJCBITDwoLES05wpnDgsOIxoDFgMKLxJnFqsOTwrHEoMKMxJbEgsOMwovEvsKWxLHDtMOXwrzDoMKPw5rCpsOjwrjDvFLDskbEuMKsw79KwonCp8OJwq3EgsKSw4pIw5%2FCtsOywqrClGLChMKfw63CtcSCWcO5UMKOwq7CpU7DgVjCiFLCpl7CtsK8wrnCqE1QwrBMw4HCt8KUwrRhwrlJclzCg8Ktwrd8dXh3w4JVcmdcY14NCz5UDXjDiQ%3D%3D',
'bst': 'V2R98gEOP43VtiVtRuzBkQKSy27DrSwi8~|R98gEOP43VtiVtRuzBkQKSy27DrRxC8~',
'__c': '1733815946',
'__a': '51952642.1728739453.1728742713.1733815946.53.3.48.48',
}
headers = {
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
# 'cookie': 'lastCity=101281000; __g=sem_bingpc; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1733815947; HMACCOUNT=C4603FF5FD89DD5B; wt2=DQ2hpC-SxREB8wHy5UR_O4qaluW35qPJ9KVXv5QgM8eGApk5z0ypsu98w0SL25-oEvW5LpyAhS4PycAKyuPooYw~~; wbg=0; zp_at=LyeHbf68ytEAiQMeRW6-LCn4NJwmyMxsRCsDEqZKm8Q~; ab_guid=2b362c14-998a-440d-bb02-05eef4dd9395; __zp_seo_uuid__=49f53280-4c27-4cbf-95ec-0408792918f9; __l=r=https%3A%2F%2Fcn.bing.com%2F&l=%2Fwww.zhipin.com%2Fjob_detail%2Fd26a271e94045f4a1nZ73d-6EldR.html%3FsecurityId%3DuLxGTJgMPVWS1-e1rsVGxSKsL3FywIfBX8gEylrv1njeOrszuB8J7ffbmTYVN4BmMLnaoCQ~%26sessionId%3D&s=3&g=%2Fwww.zhipin.com%2Fsem%2F10.html%3F_ts%3D1733819062714%26sid%3Dsem_bingpc%26qudao%3Dbing_pc_H120003UY5%26plan%3DBOSS-%25E5%25BF%2585%25E5%25BA%2594-%25E5%2593%2581%25E7%2589%258C%26unit%3Dboss%25E7%259B%25B4%25E8%2581%2598-%25E7%25AC%25A6%25E5%258F%25B7%25E8%25AF%258D%26keyword%3Dboss%25E7%259B%25B4%25E8%2581%2598%25E7%25BD%2591%25E9%25A1%25B5%25E7%2589%2588%2528%26msclkid%3D7be2972fe9d11696e67af0781364e48b&friend_source=0&s=3&friend_source=0; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1733830631; __zp_stoken__=63fafOTzDmsK4w4LCujksBQYIDQ5DKjY8Mx9COTA7Nz45PD01PDk8NRc6KSXCvMOVwoJuWsOSNTUkPD1ANTk6PTdAFDw5xLnCujg9JsOZwrXDm3tqYcOKW8KCDsKBK8OkwrwOScK1CsO1w4IrJ8KBwr1COEI2Y8K%2FOMOABsK%2BQsOCCsK7Q8K4ODo2Qyg0ElsKDzQ6RVJfCkhhU1VgTARKS1EoNjg8N8OdwrjEgyY1CgYTEggTDwoLEQUJDAgSEAwJCBITDwoLES05wpnDgsOIxoDFgMKLxJnFqsOTwrHEoMKMxJbEgsOMwovEvsKWxLHDtMOXwrzDoMKPw5rCpsOjwrjDvFLDskbEuMKsw79KwonCp8OJwq3EgsKSw4pIw5%2FCtsOywqrClGLChMKfw63CtcSCWcO5UMKOwq7CpU7DgVjCiFLCpl7CtsK8wrnCqE1QwrBMw4HCt8KUwrRhwrlJclzCg8Ktwrd8dXh3w4JVcmdcY14NCz5UDXjDiQ%3D%3D; bst=V2R98gEOP43VtiVtRuzBkQKSy27DrSwi8~|R98gEOP43VtiVtRuzBkQKSy27DrRxC8~; __c=1733815946; __a=51952642.1728739453.1728742713.1733815946.53.3.48.48',
'priority': 'u=1, i',
'referer': 'https://www.zhipin.com/web/geek/job?query=%E7%88%AC%E8%99%AB&city=101020100',
'sec-ch-ua': '"Microsoft Edge";v="131", "Chromium";v="131", "Not_A Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'token': 'yPy6F3g6gvwbyWll',
'traceid': 'F-dccebbJEbotxD75U',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0',
'x-requested-with': 'XMLHttpRequest',
'zp_token': 'V2R98gEOP43VtiVtRuzBkQKSy27DrSwi8~|R98gEOP43VtiVtRuzBkQKSy27DrRxC8~',
}
params = {
'scene': '1',
'query': query,
'city': city_code,
'experience': '',
'payType': '',
'partTime': '',
'degree': '',
'industry': '',
'scale': '',
'stage': '',
'position': '',
'jobType': '',
'salary': '',
'multiBusinessDistrict': '',
'multiSubway': '',
'page': index,
'pageSize': '30',
}
response = requests.get('https://www.zhipin.com/wapi/zpgeek/search/joblist.json', params=params, cookies=cookies, headers=headers)
response.raise_for_status()
json_data = response.json()
return json_data
# 用户提供搜索关键词
def user_input_query():
query = input("请输入职位关键词")
return query
# 用户提供搜索关键词及城市
def user_input_city():
city = input("请输入目标城市")
return city
# 接收城市返回城市编码
def get_code(city):
try:
city_code = city_dict.get(city)
return city_code
except:
return 0
# 获取招聘详细信息
def get_data(json_data,f):
job_contents = json_data["zpData"]["jobList"]
for job_content in job_contents:
jobName = job_content['jobName'] #职业名
salaryDesc = job_content['salaryDesc'] #薪资
skills = job_content['skills'] #技术
jobDegree = job_content['jobDegree'] #学历
welfareList = job_content['jobName'] #福利
jobExperience = job_content['jobExperience'] #工作经历
brandName = job_content['brandName'] #公司名
cityName = job_content['cityName'] #城市
bossName = job_content['bossName'] #老板名称
# 链接加密
encryptJobId = job_content['encryptJobId'] #伏笔1
securityId = job_content['securityId'] #伏笔2
url = "https://www.zhipin.com/job_detail/" + encryptJobId + ".html?securityId=" + securityId
f.write(f"{jobName}, {salaryDesc}, {skills}, {jobDegree}, {jobExperience}, {brandName}, {cityName}, {bossName}, {welfareList}, {url}\n")
if __name__ == '__main__':
while 1:
query = user_input_query()
city = user_input_city()
code = get_code(city)
if code == None:
print("城市不存在,请重新输入")
else:
print(f"正在{city}搜索{query},请稍等")
break
f = open(f"{city}{query}职位.csv",mode='w',encoding='utf-8')
# 不贪心,就爬四页
for index in range(1,5):
json_data = get_request(query,code,index)
get_data(json_data,f)
成果展示:
注:大佬们应该一直带着疑问找到了这里,url不是由五部分组成吗,lid 去哪了,我不对lib进行添加是因为两个原因:
(1)有无lib,链接仍然能正常到达详情页
(2)为包含lib的方法进行断点,程序并未在此暂停,不过通过扣源代码也能找到lib的伪加密函数

结论:通过比较伏笔1和伏笔2,可以猜测lid的值也是json里的lid值。
以上为本人的思路及步骤,希望网上的各位大神有空能够点评小弟。

















 4954
4954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









