






本项目内容是:在携程旅行网中对广东省的景点数据进行爬取。
以下为详细步骤及思路:
1. 对爬取网页中数据的存储位置进行分析,广东省景点网页
打开开发者工具,使用搜索功能找到数据存放的位置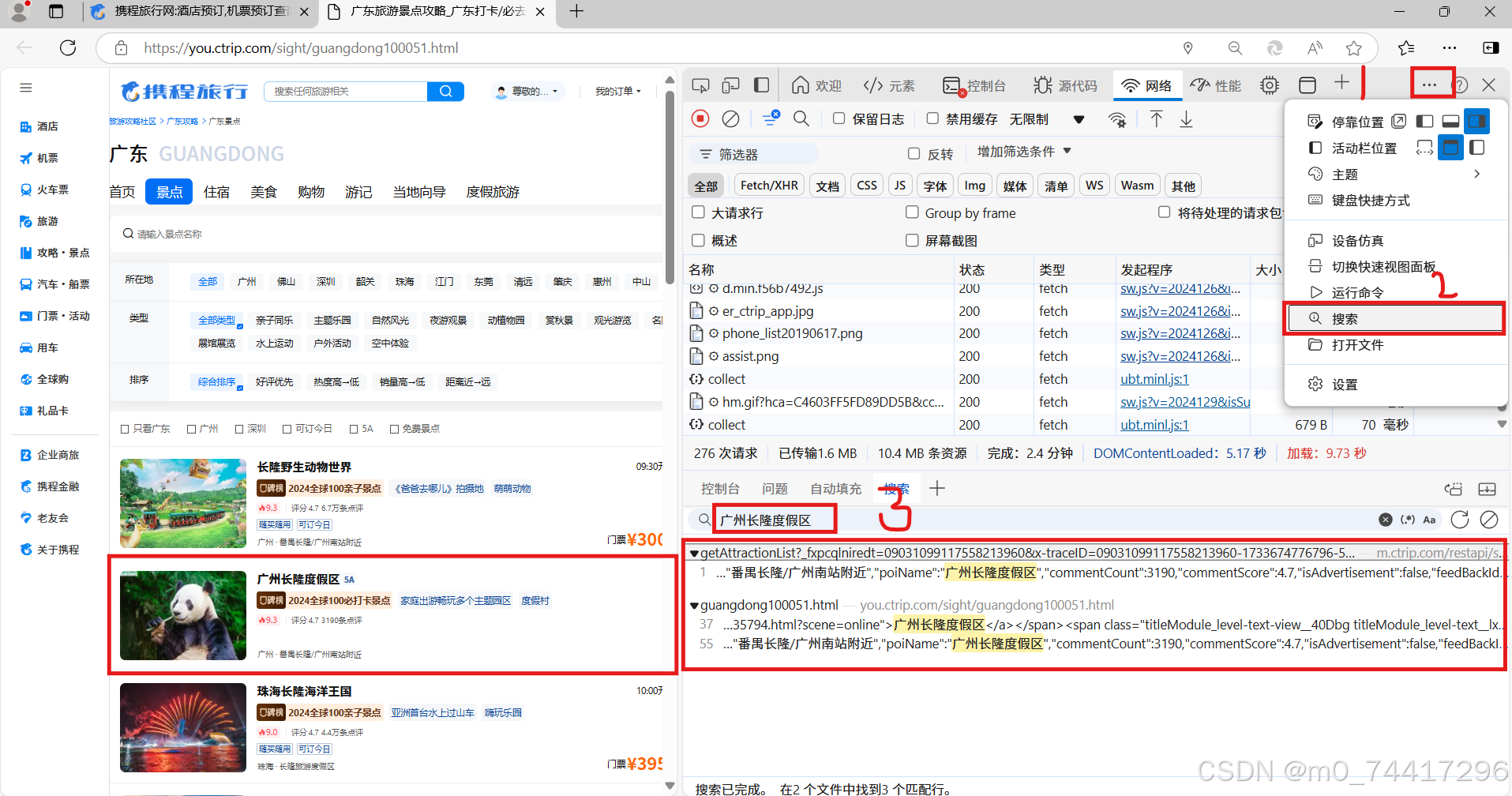
2. 通过搜索到的文件,可以发现数据存放地址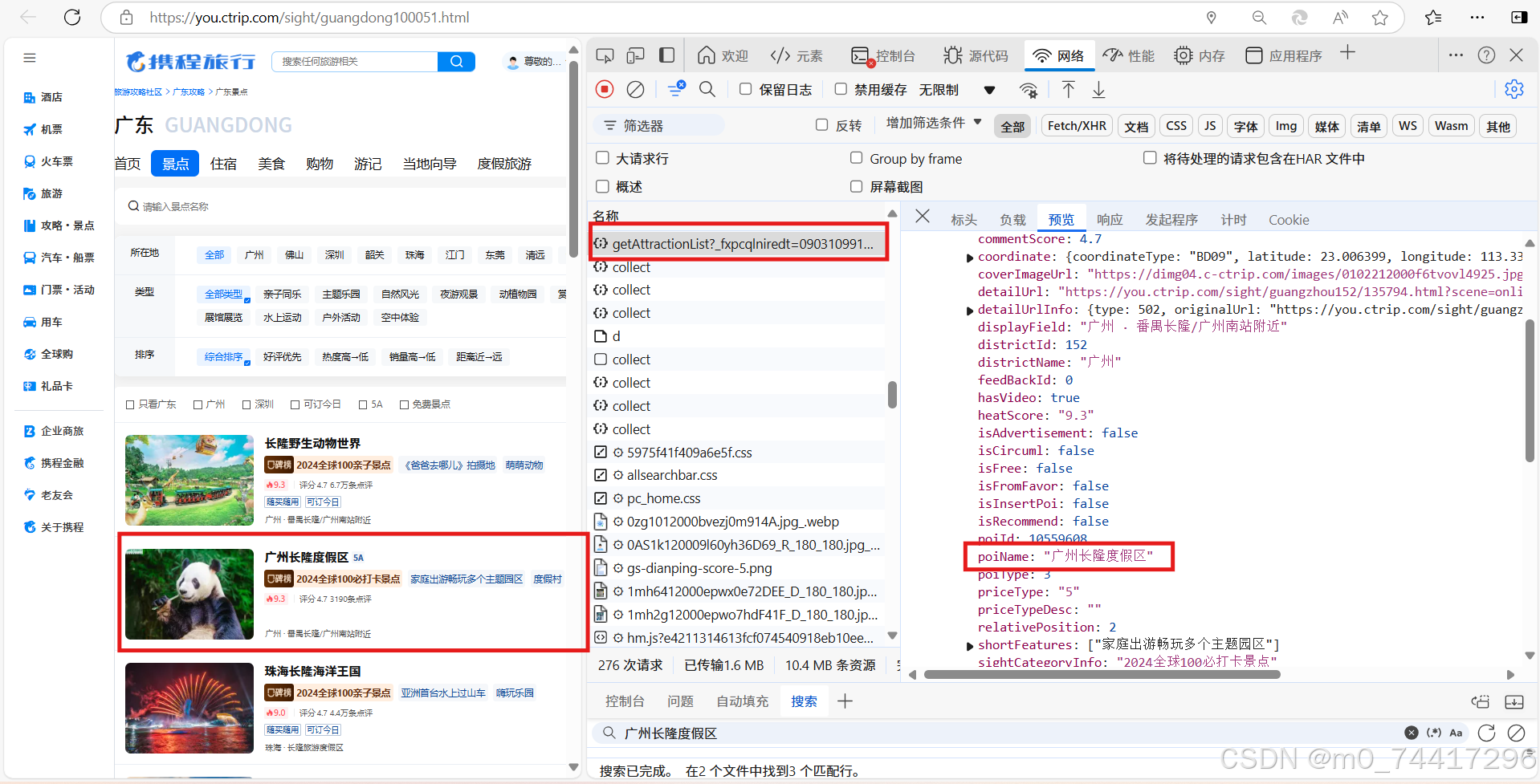
3. 获取该链接的json数据,即可找到所有数据内容。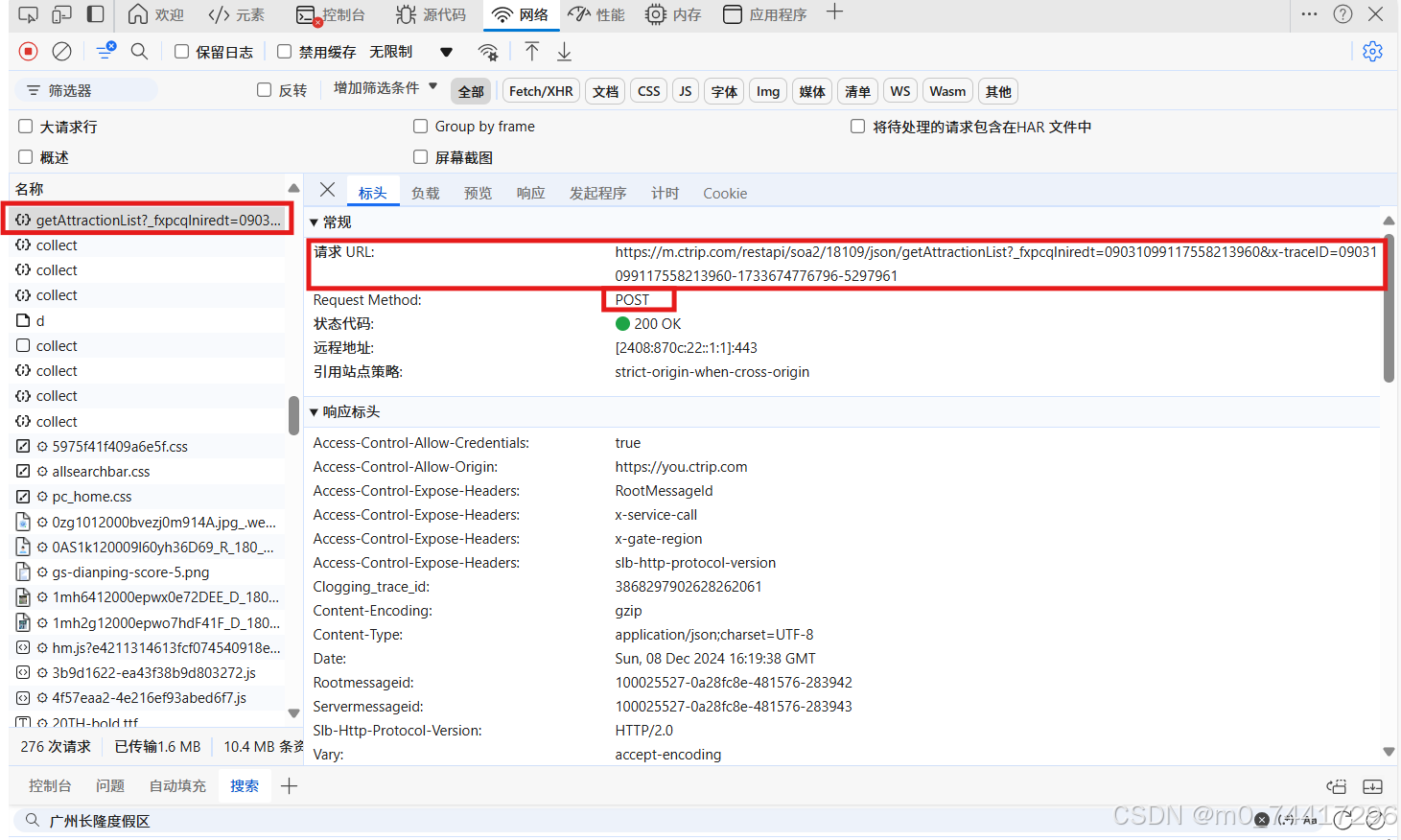
4. 对第二页的网页进行对比,目标便明确了,高亮为需进行逆向的属性
爬取目标链接为:
**https://m.ctrip.com/restapi/soa2/18109/json/getAttractionList?_fxpcqlniredt=09031099117558213960&x-traceID=09031099117558213960-1733674776796-5297961**
请求方式为:
post请求
参数为:
_fxpcqlniredt: 09031099117558213960
**x-traceID: 09031099117558213960-1733674776796-5297961**
请求负载为:
{"head":{ **"cid":"09031099117558213960"** ,"ctok":"","cver":"1.0","lang":"01","sid":"8888","syscode":"999","auth":"","xsid":"","extension":[]},"scene":"online","districtId":100051, **"index":1** ,"sortType":1,"count":10,"filter":{"filterItems":["0"]},"coordinate":{"latitude":21.28874136580043,"longitude":110.33244777197878,"coordinateType":"WGS84"},"returnModuleType":"all"}
5. 通过重复比较,可以发现 x-traceID 的值时刻变化着,便确实x-traceID存在加密,因此需要进行js逆向,而index的值是由于翻页产生的变化。
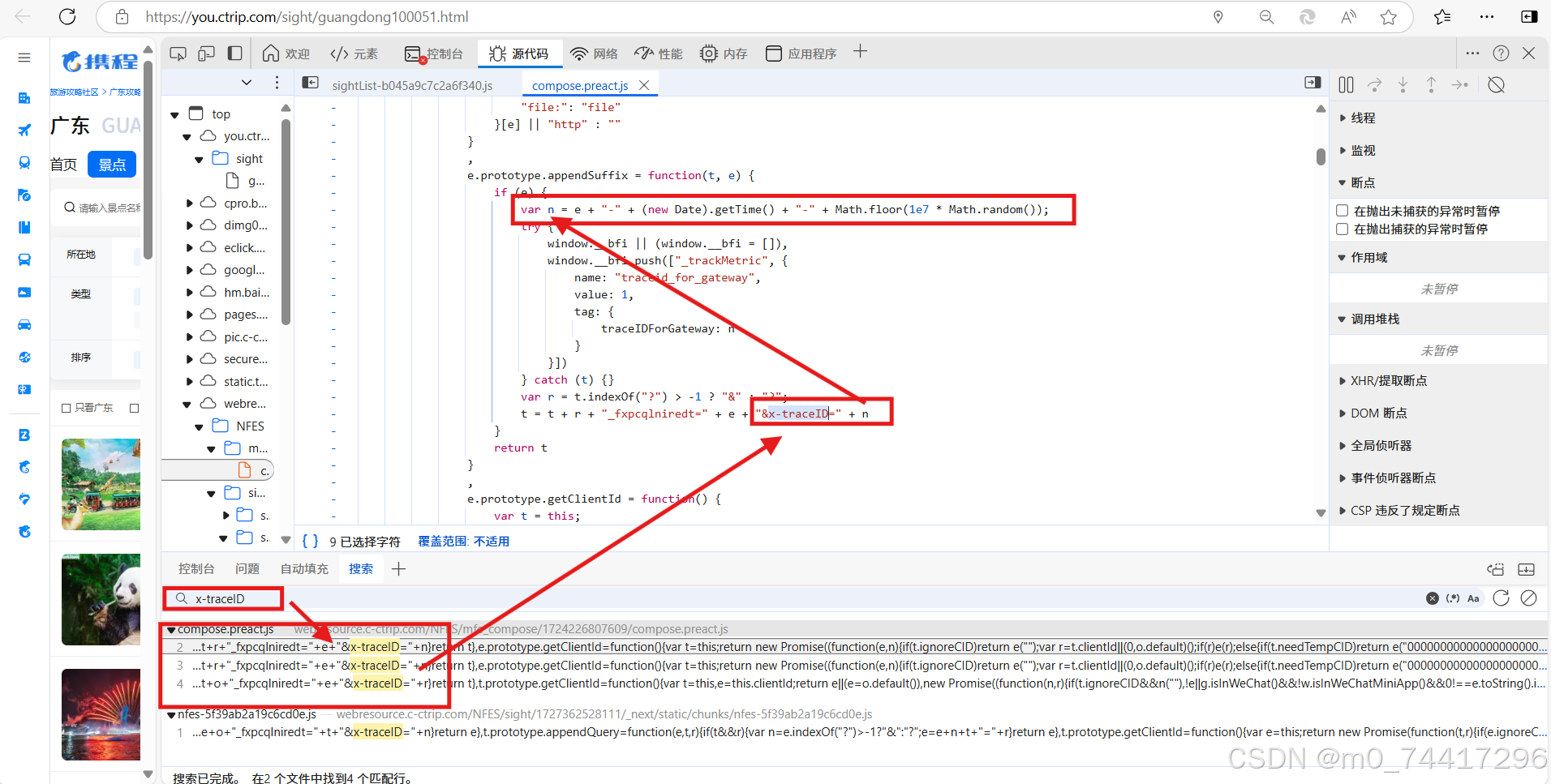 从上图可找到x-traceID的加密方法是:
从上图可找到x-traceID的加密方法是:
#var n = e + "-" + (new Date).getTime() + "-" + Math.floor(1e7 * Math.random());
#用python语言表示为:
import time
import random
n1 = int( time.time() * 1000 )
n2 = int(1e7 * random.random())
6.找到变化原因后,接着就是对网页进行爬取
由于数据存储在json里,因此需要对该链接的json数据进行获取
resp = requests.post(
"https://m.ctrip.com/restapi/soa2/18109/json/getAttractionList",
headers=headers,
cookies=cookies,
params=params,
json=json_data
)
html_json = resp.json()7. json数据的获取与字典相似,参考以下图片可编写如下代码: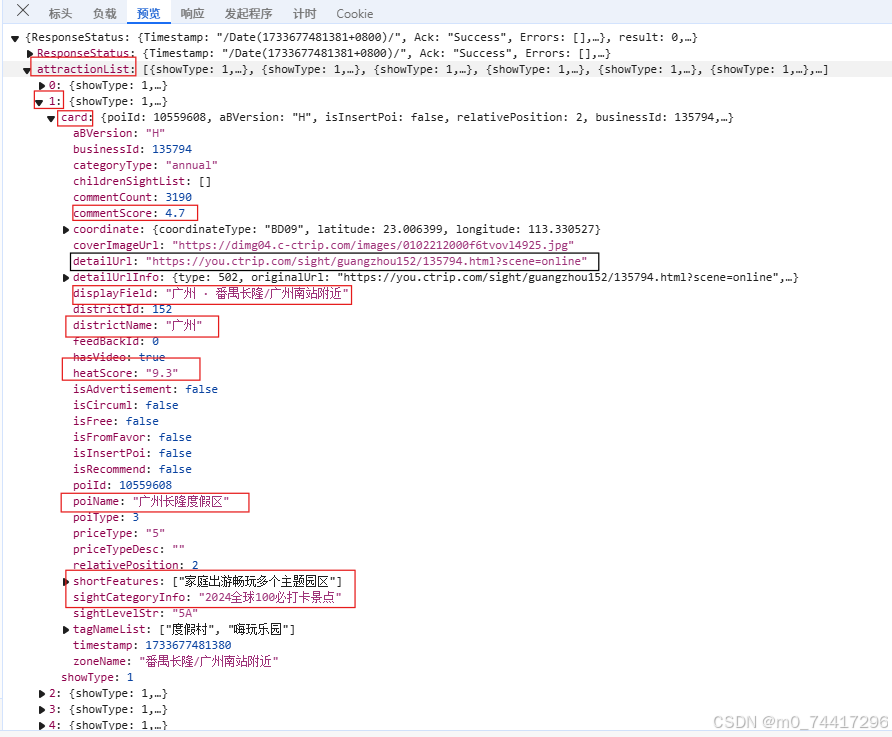
card = html_json['attractionList'][i]['card']
poiName = card['poiName'] #景点名
districtName = card['districtName'] # 城市
displayField = card['displayField'] # 地址
url = card['detailUrlInfo']['url'] # 链接
commentScore = card.get('commentScore',0) #评分
heatScore = card.get('heatScore',0) #热度
price = card.get('price','未提供') # 门票
features = card.get('shortFeatures','未提供')[0] # 特点
sightCategoryInfo = card.get('sightCategoryInfo','未提供') # 类别8. 完整代码如下所示:
import pymysql
import requests
import time
import random
#连接数据库
conn = pymysql.connect(host="127.0.0.1", database="gsc_db", user='root', password='123456', charset='utf8')
cursor = conn.cursor()
cookies = {
'UBT_VID': '1728978531192.7a32iNJ24XYh',
'MKT_CKID': '1728978531548.ta9kw.rmqq',
'GUID': '09031099117558213960',
'_RSG': 'rJaVC01L4g5oWzt1DGJhE9',
'_RDG': '2835c4e1c5f8bb2ed003d7adb458381615',
'_RGUID': '5a845410-0c7e-44f5-93ab-4d0341dfd832',
'nfes_isSupportWebP': '1',
'_ga': 'GA1.1.691848462.1728980346',
'_bfaStatusPVSend': '1',
'cticket': '67A823297D1D925133ED11DC609DBD186BF1B271E9FE1C4759326381FF82177B',
'login_type': '0',
'login_uid': '5DB309DF4469D70D7DE6CDF186BEE12E',
'DUID': 'u=274F4632961D3B1B682CA5A0E3A1FDD1&v=0',
'IsNonUser': 'F',
'AHeadUserInfo': 'VipGrade=0&VipGradeName=%C6%D5%CD%A8%BB%E1%D4%B1&UserName=&NoReadMessageCount=0',
'_RF1': '2408%3A8459%3A6a30%3A2848%3A555%3A3bd2%3A55be%3A5372',
'MKT_Pagesource': 'PC',
'_ubtstatus': '%7B%22vid%22%3A%221728978531192.7a32iNJ24XYh%22%2C%22sid%22%3A20%2C%22pvid%22%3A4%2C%22pid%22%3A0%7D',
'_bfi': 'p1%3D0%26p2%3D0%26v1%3D4%26v2%3D0',
'_bfaStatus': 'success',
'Hm_lvt_a8d6737197d542432f4ff4abc6e06384': '1732626315,1733409627,1733454424,1733471439',
'Hm_lpvt_a8d6737197d542432f4ff4abc6e06384': '1733471439',
'HMACCOUNT': 'C4603FF5FD89DD5B',
'_ga_9BZF483VNQ': 'GS1.1.1733471247.20.1.1733471450.0.0.0',
'_ga_5DVRDQD429': 'GS1.1.1733471247.20.1.1733471450.0.0.0',
'_ga_B77BES1Z8Z': 'GS1.1.1733471247.20.1.1733471450.49.0.0',
'_jzqco': '%7C%7C%7C%7C1733409631243%7C1.437472813.1728978531563.1733471461338.1733471505912.1733471461338.1733471505912.undefined.0.0.136.136',
'_bfa': '1.1728978531192.7a32iNJ24XYh.1.1733471503148.1733471502143.20.11.10650142842',
}
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'application/json',
'cookieorigin': 'https://you.ctrip.com',
'origin': 'https://you.ctrip.com',
'priority': 'u=1, i',
'referer': 'https://you.ctrip.com/',
'sec-ch-ua': '"Microsoft Edge";v="131", "Chromium";v="131", "Not_A Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0',
}
#x-traceID的生成
n1 = int( time.time() * 1000 )
n2 = int(1e7 * random.random())
t = cookies.get("GUID")
n = f'{t} + "-" + {n1} + "-" + {n2}'
params = {
'_fxpcqlniredt': t,
'x-traceID': n,
}
for index in range(1,301):
json_data = {
'head': {
'cid': t,
'ctok': '',
'cver': '1.0',
'lang': '01',
'sid': '8888',
'syscode': '999',
'auth': '',
'xsid': '',
'extension': [],
},
'scene': 'online',
'districtId': 100051,
'index': index,
'sortType': 1,
'count': 10,
'filter': {
'filterItems': [
'0',
],
},
'coordinate': {
'latitude': 21.28942580322746,
'longitude': 110.33324580318082,
'coordinateType': 'WGS84',
},
'returnModuleType': 'all',
}
resp = requests.post(
"https://m.ctrip.com/restapi/soa2/18109/json/getAttractionList",
headers=headers,
cookies=cookies,
params=params,
json=json_data
)
html_json = resp.json()
for i in range(0,10):
try:
card = html_json['attractionList'][i]['card']
# 不会缺少的数据量
poiName = card['poiName'] #景点名
districtName = card['districtName'] # 城市
displayField = card['displayField'] # 地址
url = card['detailUrlInfo']['url'] # 链接
# 部分会缺少的数据量,用get设置默认值
commentScore = card.get('commentScore',0) #评分
heatScore = card.get('heatScore',0) #热度
price = card.get('price','未提供') # 门票
features = card.get('shortFeatures','未提供')[0] # 特点
sightCategoryInfo = card.get('sightCategoryInfo','未提供') # 类别
sql = ("INSERT INTO gd_province (poiName,price,features,sightCategoryInfo,commentScore,heatScore,districtName,displayField,url) "
"VALUES ( %s, %s, %s, %s,%s, %s, %s, %s, %s)")
cursor.execute(sql, (poiName,price,features,sightCategoryInfo,commentScore,heatScore,districtName,displayField,url))
conn.commit()
except:
print(f"第{index}页的第{i+1}个信息框出错")
print(f"第{index}页爬取成功")
# 写入数据库后关闭数据库
cursor.close()
conn.close()9. 数据存入数据库中,使用sql语句查看数据内容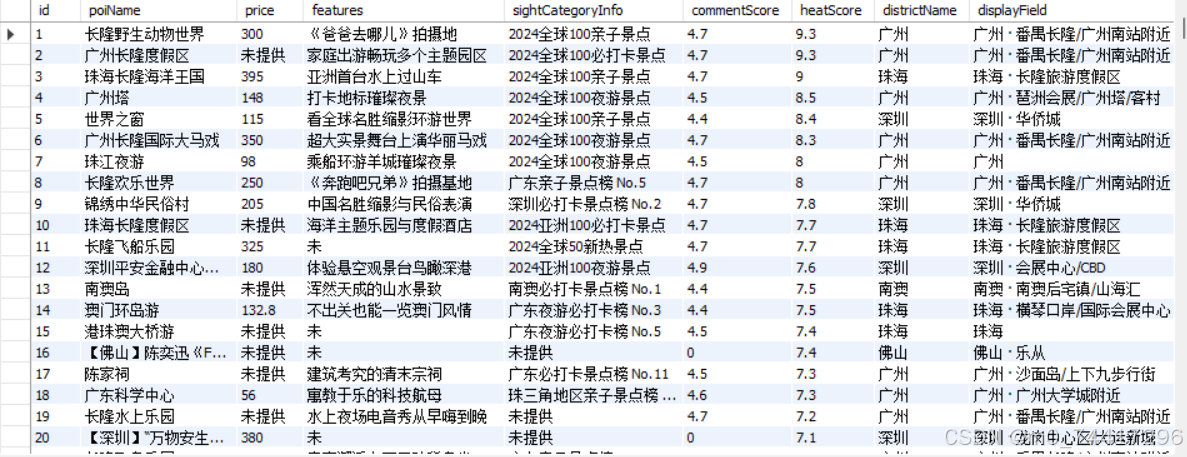

















 2985
2985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









