







1、数据载入
(1)在Jupyter下安装Python第三方库
!pip install pandas
!pip install numpy
!pip install scipy
!pip install matplotlib
!pip install scikit-learn
!pip install mlxtend实验操作图片:

(2)导入相关模块
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules实验操作图片:

(3)导入数据集
dataset=[['牛奶','洋葱','肉豆蔻','芸豆','鸡蛋','酸奶'],
['莳萝','洋葱','肉豆蔻','芸豆','鸡蛋','酸奶'],
['牛奶','苹果','芸豆','鸡蛋'],
['牛奶','独角兽','玉米','芸豆','酸奶'],
['玉米','洋葱','洋葱','芸豆','冰淇淋','鸡蛋']]实验操作图片

2、频繁项集挖掘
(1)one-hot编码
te=TransactionEncoder()
te_ary=te.fit(dataset).transform(dataset)
df=pd.DataFrame(te_ary,columns=te.columns_)
df实验操作图片
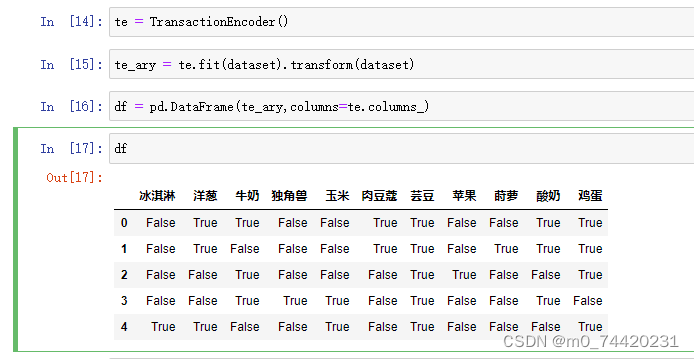
(2)计算频繁项集
思考巩固:
['牛奶','洋葱','肉豆蔻','芸豆','鸡蛋','酸奶'] (6项集)
['莳萝','洋葱','肉豆蔻','芸豆','鸡蛋','酸奶'] (6项集)
['牛奶','苹果','芸豆','鸡蛋'] (4项集)
['牛奶','独角兽','玉米','芸豆','酸奶'] (5项集)
['玉米','洋葱','洋葱','芸豆','冰淇淋','鸡蛋'] (6项集)
支持度计数:包含特定项集的个数
例如:{芸豆,洋葱}的支持度计数为3
支持度:包含项集的事务数与总事务数的比值(支持度确定项集的频繁程度)
{芸豆,洋葱}的支持度为
芸豆-->洋葱(假设表示为买芸豆的人会买洋葱)
支持度 = (芸豆、洋葱同时出现的概率)
置信度 = (芸豆、洋葱同时出现的概率占芸豆出现概率的比值)
频繁项集:满足最小支持度阈值的所有项集
3、关联规则挖掘
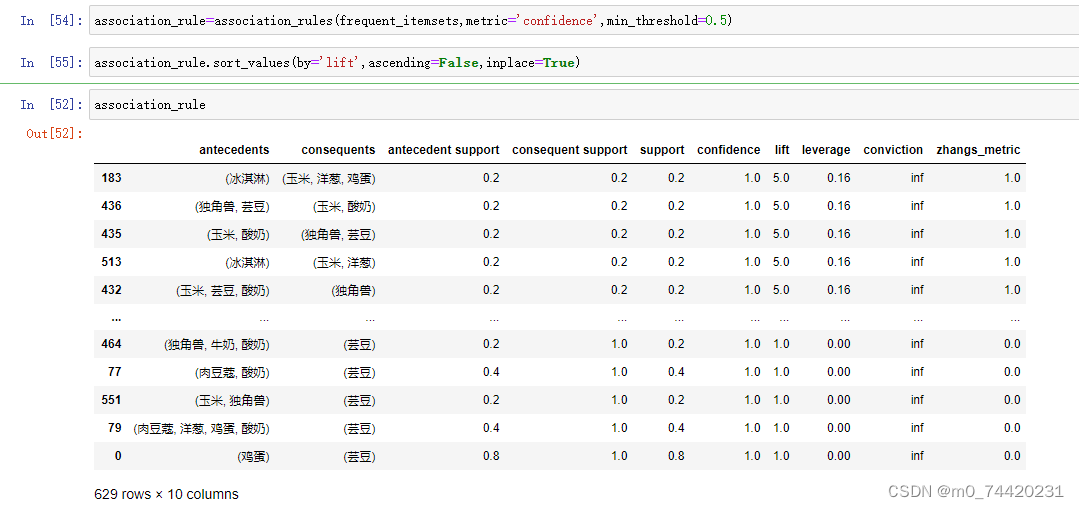
当最小支持度为50%;最小置信度为50%
frequent_itemsets=apriori(df,min_support=0.5,use_colnames=True)
frequent_itemsets.sort_values(by='support',ascending=False,inplace=True)
print(frequent_itemsets[frequent_itemsets.itemsets.apply(lambda x:len(x))==2])
association_rule=association_rules(frequent_itemsets,metric='confidence',min_threshold=0.5)
association_rule.sort_values(by=’lift’,ascending=False,inplace=Ture)
association_rule所得频繁项集以及关联规则如下

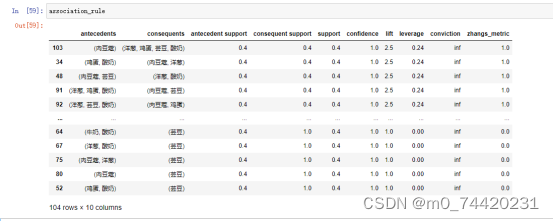
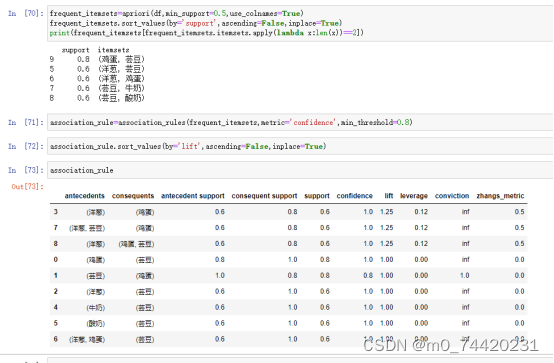
当最小支持度为30%;最小置信度为70%
所得频繁项集以及关联规则如下

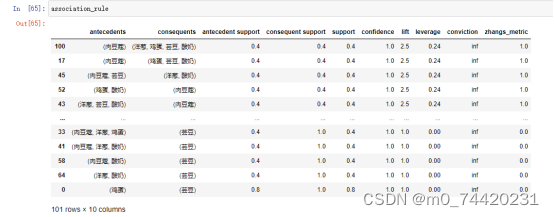
当最小支持度为30%;最小置信度为80%
所得频繁项集以及关联规则如下

当最小支持度为50%;最小置信度为90%
所得频繁项集以及关联规则如下
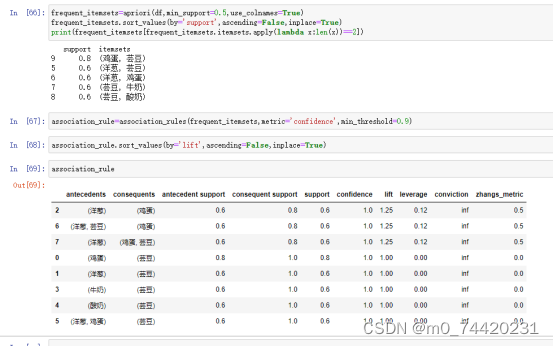
当最小支持度为50%;最小置信度为80%
所得频繁项集以及关联规则如下
4、项目总结
问题1:未事先正确操作以下步骤

误以为在anaconda的环境变量中添加即可
解决:已正确在Jupyter下安装Python第三方库
问题2:
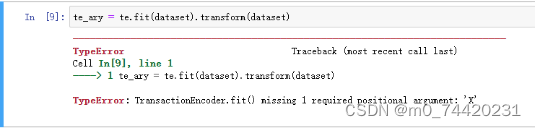
原因:上一步骤中
![]()
未打括号就运行,且后面添加之后没有再次运行此步骤。
已解决,并牢记修改之后必须运行一次
5、源代码
!pip install pandas
!pip install numpy
!pip install scipy
!pip install matplotlib
!pip install scikit-learn
!pip install mlxtend
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
dataset=[['牛奶','洋葱','肉豆蔻','芸豆','鸡蛋','酸奶'],
['莳萝','洋葱','肉豆蔻','芸豆','鸡蛋','酸奶'],
['牛奶','苹果','芸豆','鸡蛋'],
['牛奶','独角兽','玉米','芸豆','酸奶'],
['玉米','洋葱','洋葱','芸豆','冰淇淋','鸡蛋']]
te=TransactionEncoder()
te_ary=te.fit(dataset).transform(dataset)
df=pd.DataFrame(te_ary,columns=te.columns_)
df
frequent_itemsets=apriori(df,min_support=0.5,use_colnames=True)
frequent_itemsets.sort_values(by='support',ascending=False,inplace=True)
print(frequent_itemsets[frequent_itemsets.itemsets.apply(lambda x:len(x))==2])
association_rule=association_rules(frequent_itemsets,metric='confidence',min_threshold=0.5)
association_rule.sort_values(by=’lift’,ascending=False,inplace=Ture)
association_rule

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









