







一:Apriori算法介绍
关联规则挖掘是数据挖掘中最活跃的研究方法之一 。最早是由 Agrawal 等人提出的1993最初提出的动机是针对购物篮分析问题提出的,其目的是为了发现交易数据库中不同商品之间的联系规则。这些规则刻画了顾客购买行为模式,可以用来指导商家科学地安排进货,库存以及货架设计等。
Apriori算法是一种挖掘关联规则的频繁项集算法,一种最有影响的挖掘布尔关联规则频繁项集的算法。Apriori是由a priori合并而来的,它的意思是后面的是在前面的基础上推出来的,即先验推导。其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。在这里,所有支持度大于最小支持度的项集称为频繁项集,简称频集。
Apriori定律:
- 如果一个集合是频繁项集,则它的所有子集都是频繁项集。
- 如果一个集合不是频繁项集,则它的所有超集都不是频繁项集。
算法处理过程如下,在数据库中寻找关联度最高的一组值:
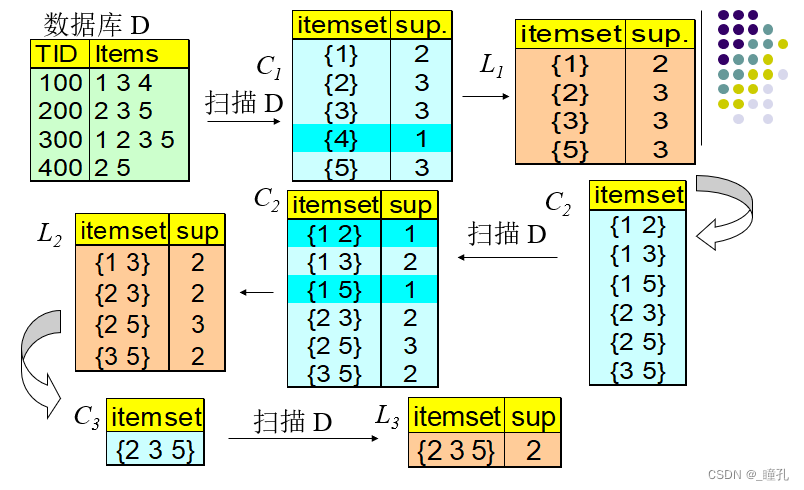
Apriori算法采用了逐层搜索的迭代的方法,算法简单明了,没有复杂的理论推导,也易于实现。但其有一些难以克服的缺点:
- 对数据库的扫描次数过多
- Apriori算法会产生大量的中间项集
- 采用唯一支持度
- 算法的适应面窄
总结来说:
- Apriori算法基本思想:频繁项集的任何子集也一定是频繁的。
- 用频繁的(k-1)-项集生成候选的频繁k-项集,用数据库扫描和模式匹配计算候选集的支持度
二:例题
挖掘出支持度为3的最大频繁项级:
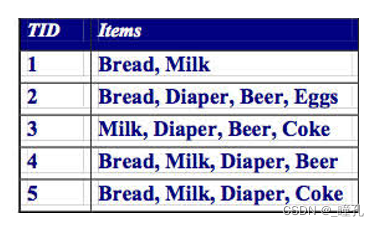
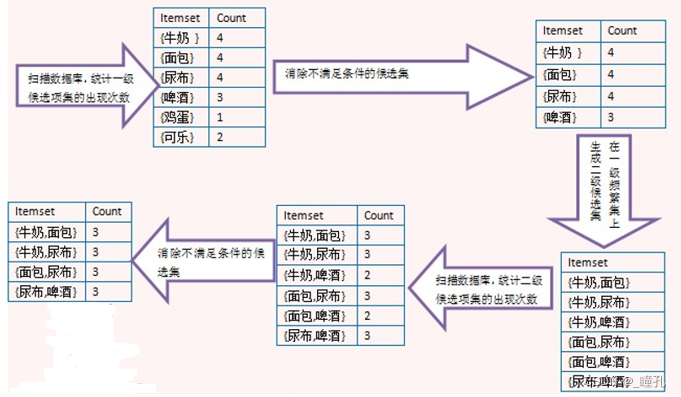
解答过程如下,这也是著名的“尿布与啤酒”问题
三:FP-growth算法
Apriori算法在产生频繁模式完全集前需要对数据库进行多次扫描,同时产生大量的候选频繁集,这就使Apriori算法时间和空间复杂度较大。但是Apriori算法中有一个很重要的性质:频繁项集的所有非空子集都必须也是频繁的。但是Apriori算法在挖掘额长频繁模式的时候性能往往低下,Jiawei Han提出了FP-Growth算法。
FP-growth算法将数据集存储在一种称作FP树的紧凑数据结构中,然后发现频繁项集或者频繁项对,即常在一块出现的元素项的集合FP树。FP代表频繁模式(Frequent Pattern)。FP树通过链接(link)来连接相似元素,被连起来的元素项可以看成一个链表。
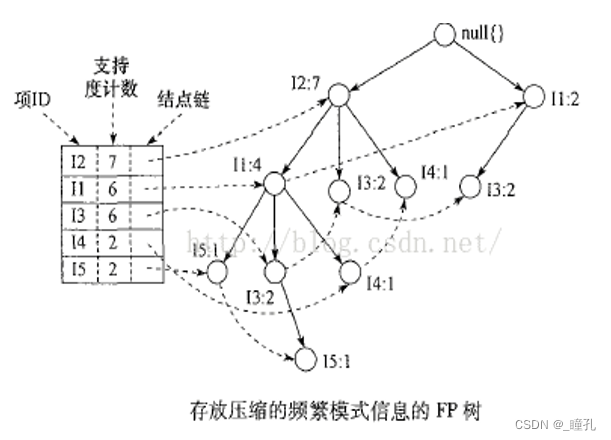
FP-growth算法虽然能高效地发现频繁项集,但是不能用于发现关联规则。FP-growth算法的执行速度快于Apriori算法,通常性能要好两个数量级以上。
FP-growth算法只需要对数据集扫描两次,它发现频繁项集的过程如下:
- 构建FP树
- 从FP树中挖掘频繁项集
如果有兴趣了解更多相关内容,欢迎来我的个人网站看看:瞳孔空间

















 2750
2750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









