






在机器学习中,一个常见的预设前提是数据是“静态”的,即其统计特性如均值和方差等保持不变。这一假设隐含地认为,如果模型在训练数据上表现优异,那么它在新流入的测试数据上也应该能够维持相同的性能。然而,现实世界的复杂性远非如此简单。实际的数据集往往是动态的,其统计属性随着时间的推移可能产生显著的变化。
当这种变化发生时,如果机器学习模型未能察觉并适应这种变化,它可能会因为无法准确预测而性能下降。这种现象,我们称之为——“概念漂移”。在快速变化的数据环境中,概念漂移是一个尤为关键的问题,因为它直接挑战了模型的稳定性和适应性。
什么是概念漂移(concept drift)?
概念漂移是机器学习模型学到的输入输出关系的变化。
举个垃圾邮件识别的例子:
假设有一个用大量的电子邮件数据集来训练的机器学习模型来检测电子邮件是否为垃圾邮件,他的正确率很高。如果垃圾邮件发送者想出了新的方法,使得曾经的垃圾邮件看起来像是普通邮件,那么这个模型在一段时间后检测的正确率会下降。这种变化就是概念漂移的一个例子。原因是垃圾邮件的概念,即正确的标签(目标变量)发生了变化;随着垃圾邮件发送策略的变化,垃圾邮件在数据集中的比例、特征也发生了变化,即数据分布发生了变化。
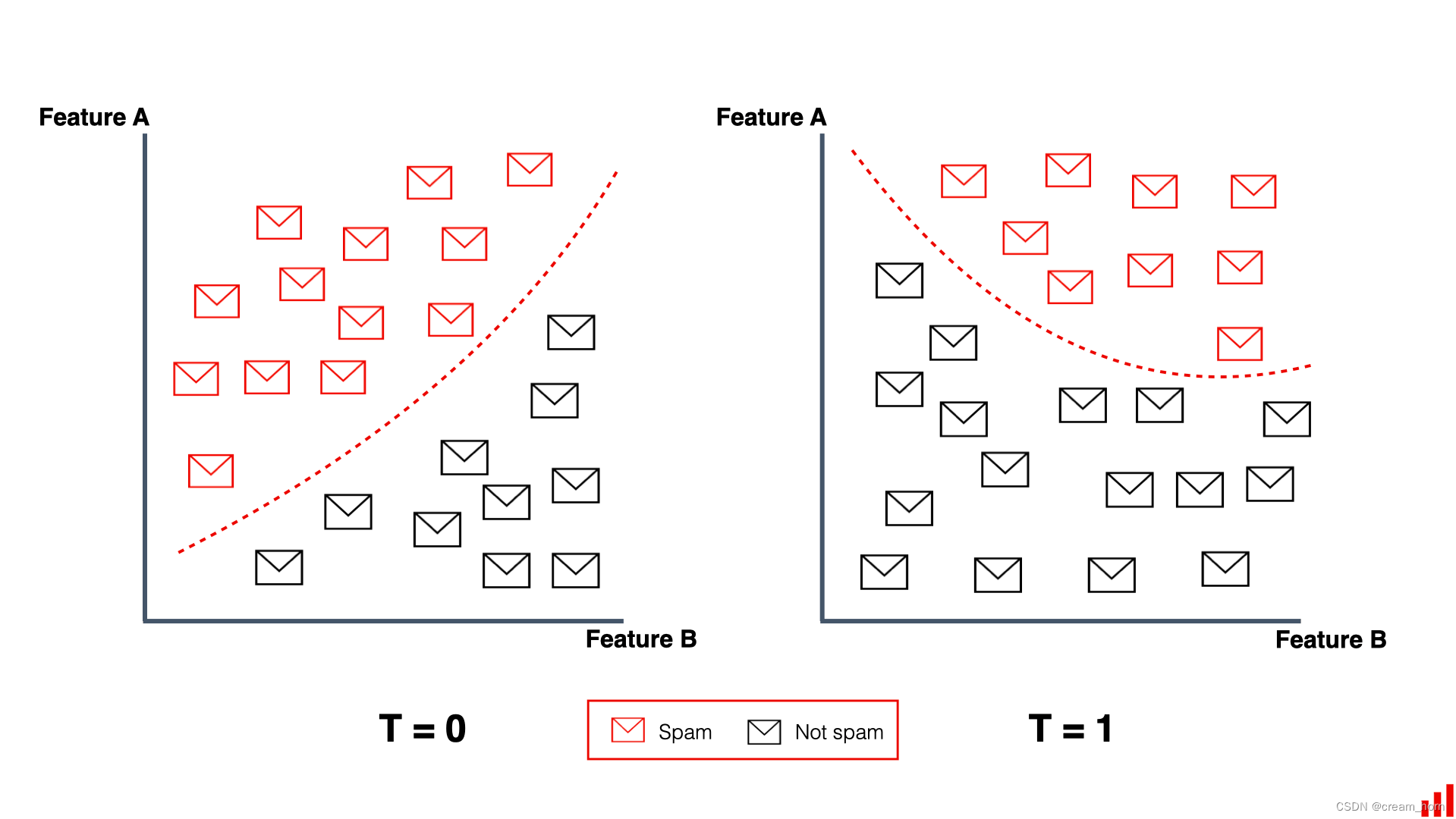
在上述例子中,我们可以得知概念漂移产生的两种常见原因:
- 数据概念的变化:垃圾邮件的概念发生了变化;
- 数据分布的变化:垃圾邮件的发送策略发送了改变,如输入特征(比如“邮件长度”“发送的设备类型”),数量比例等。
数据的变化可以采取任何形式,现实中的变化情况类别包括哪几类呢?
概念漂移的分类
突然(suddently):一个概念到一个新概念之间的转变突然发生。例如,突如其来的疫情可能导致大量预测模型瞬间失效,因为疫情改变了人们的消费习惯和行为模式,使得原有模型的输入和真实标签之间的关系发生了突变。
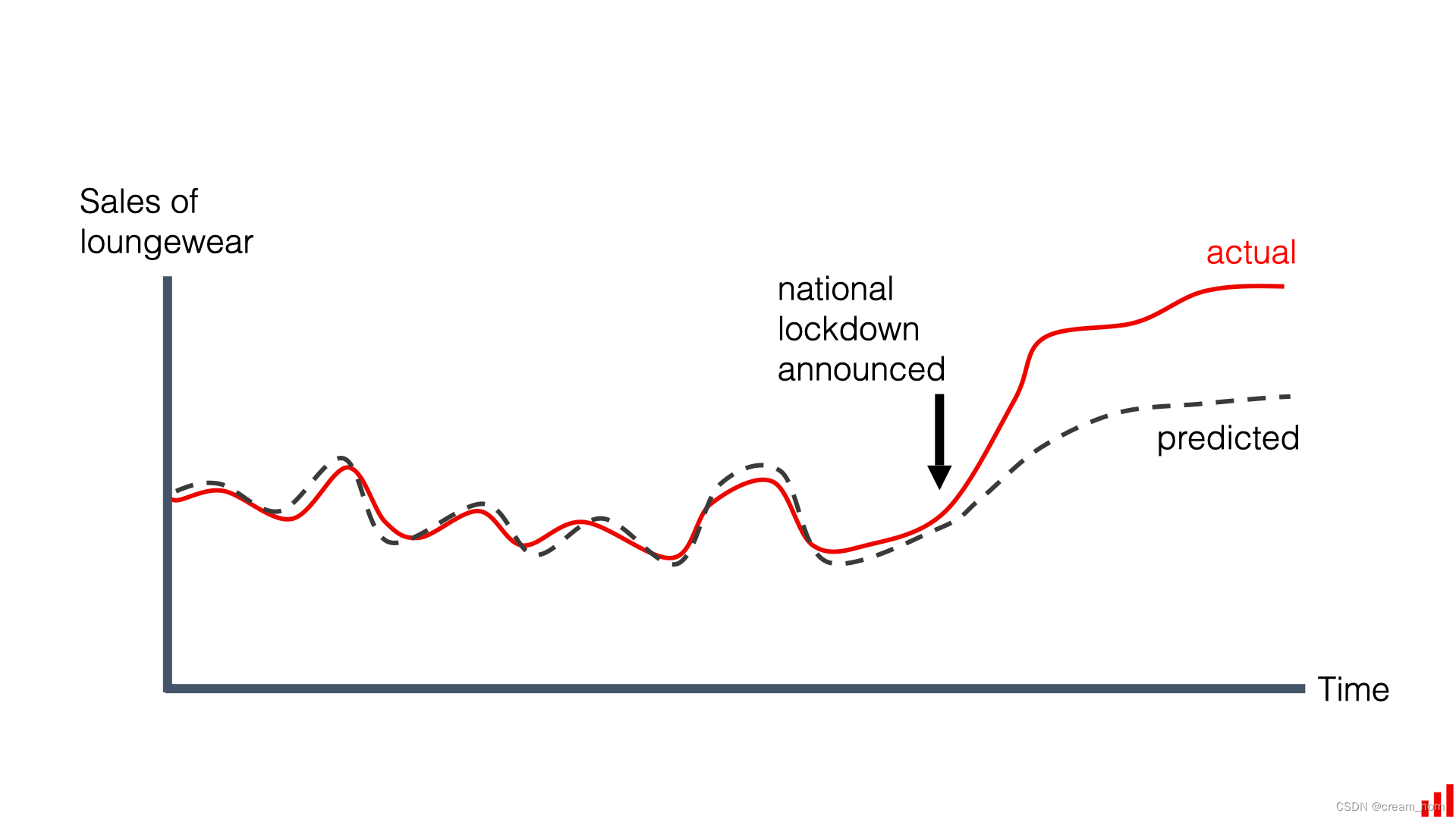
居家服的销量突然上升
增量(incremental)/渐进(gradually):随着新概念的出现和发展,概念之间的过渡会随着时间的推移而发生。一个典型的例子是手机的使用预测:过去,手机主要用于接打电话和发送短信,但随着时间的推移,手机逐渐赋予了更多功能,如社交媒体、移动支付等,使得其角色和用途发生了增量式的变化。
重复/季节性(recurrent):第一次观察到变化后再次发生,重复发生或遵循一个周期的模式变化。这种漂移的一个例子是每年的季节性天气变化,促使消费者在寒冷的月份购买保暖的外套,然后在春季气温上升时停止需求,然后在秋季再次开始。
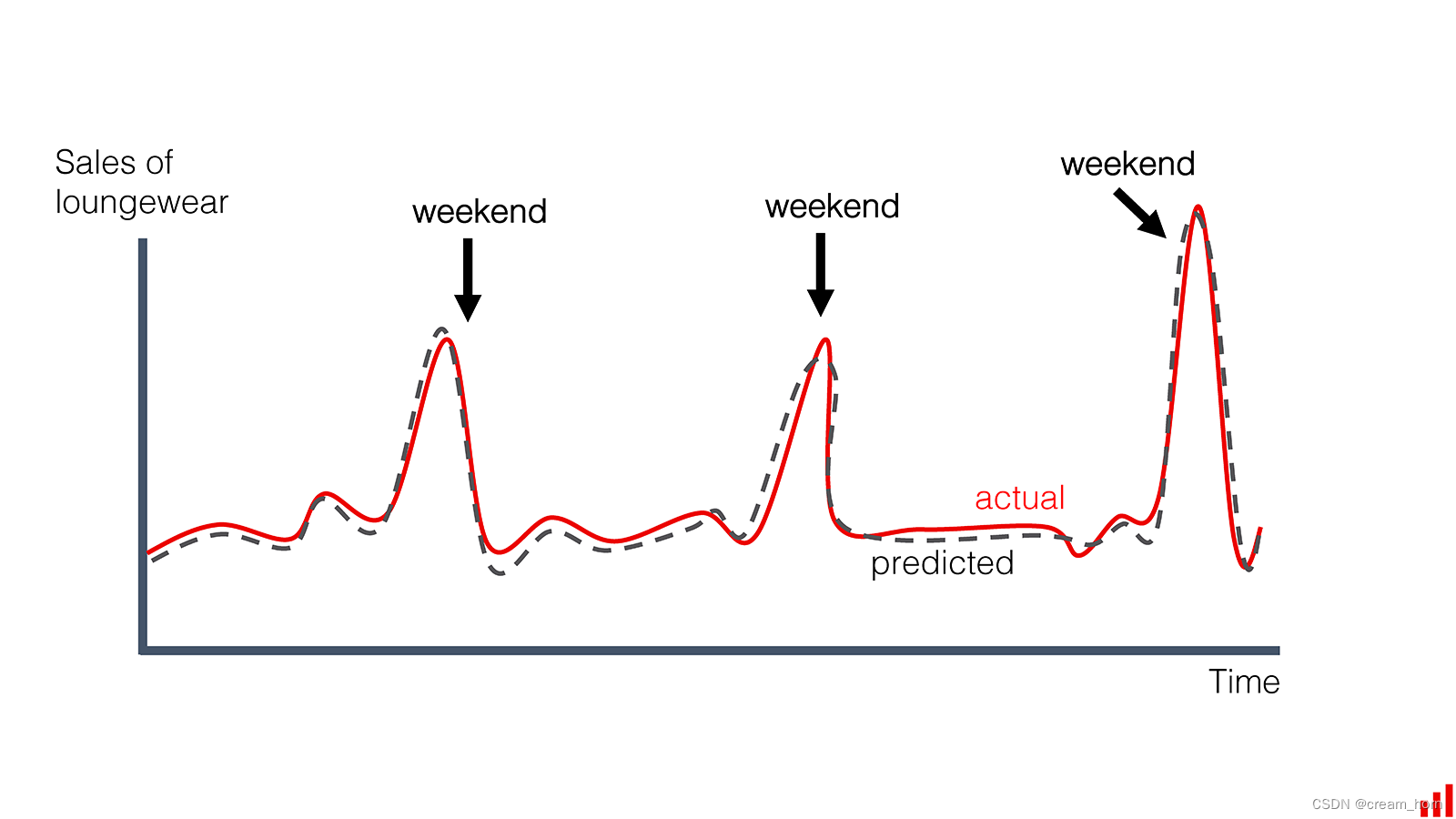
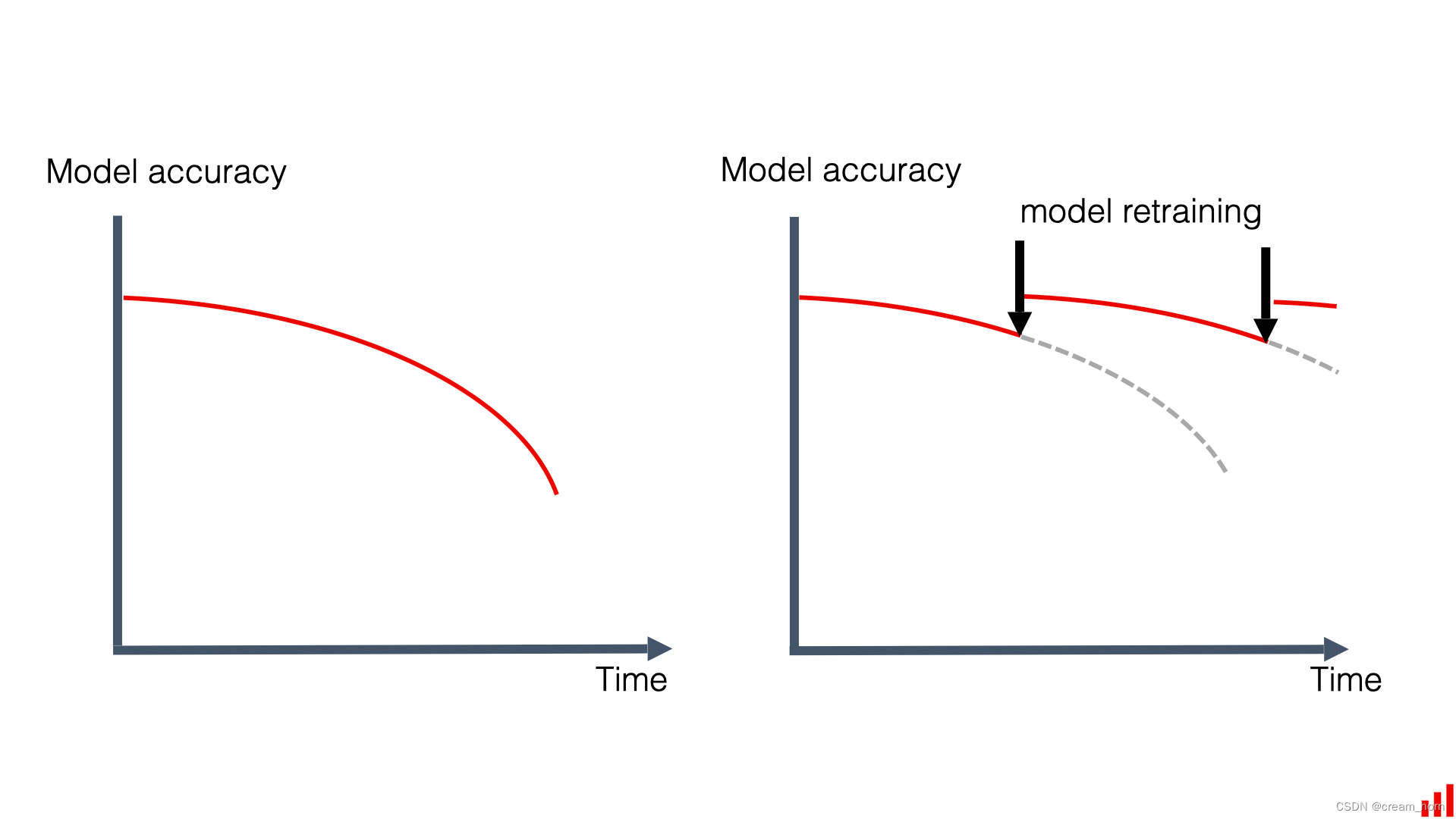
了解概念漂移的种类有助于模型监控,模型监控是指对部署的机器学习模型进行持续的观察和管理,目的是为了确保模型性能和准确性。在一些文章中,我们会看到“探测器”(Detector)这个术语,它在概念漂移的上下文中被广泛地使用,因为它传达了一个直观的概念:这些工具就像是“侦查员”或“监视器”,这个比喻强调了探测器的主动性和自动化特点,它们不断地监测数据流,以便及时发现并报告潜在的问题,也就是我们接下来讨论的“检测方法”。
常见概念漂移检测方法
要在监控过程中检测概念漂移,即需要检测输入和输出数据之间的关系是否发生了变化。
检测概念漂移的方法有多种分类方式,他们有各自的优缺点以及适合应用的场景。很多概念漂移检测方法可能同时属于多个分类,以下的分类方式并不唯一。
-
基于统计测试的检测方法
- 通过计算统计量(如均值、方差、偏度等),应用特定的统计检验(如ks检验、kl散度或卡方检验等),具体检测方法(如较早且基础的DDM(Drift Detection Method)),将传入数据的分布与早期参考批次的分布进行比较,使人们可以直观观察到数据分布的变化情况。
-
优点 适用场景:适合检测全局或长期的概念漂移,直观性强,基于数学统计原理对整个数据集的统计特性进行分析 适用对象:应用广泛,无论是离散数据还是连续数据,单变量还是多变量都能提供相应的检测方法 缺点 对数据分布的假设有一定要求——如果数据分布变化微小可能会被噪声覆盖,当数据分布不满足假设条件时,可能会导致检测结果的不准确 当输入数据和目标变量之间的关系不再是静态或线性时,假设可能不再成立 需要预先设定显著性水平和置信度,可能导致误报或漏报 计算复杂度:较高
-
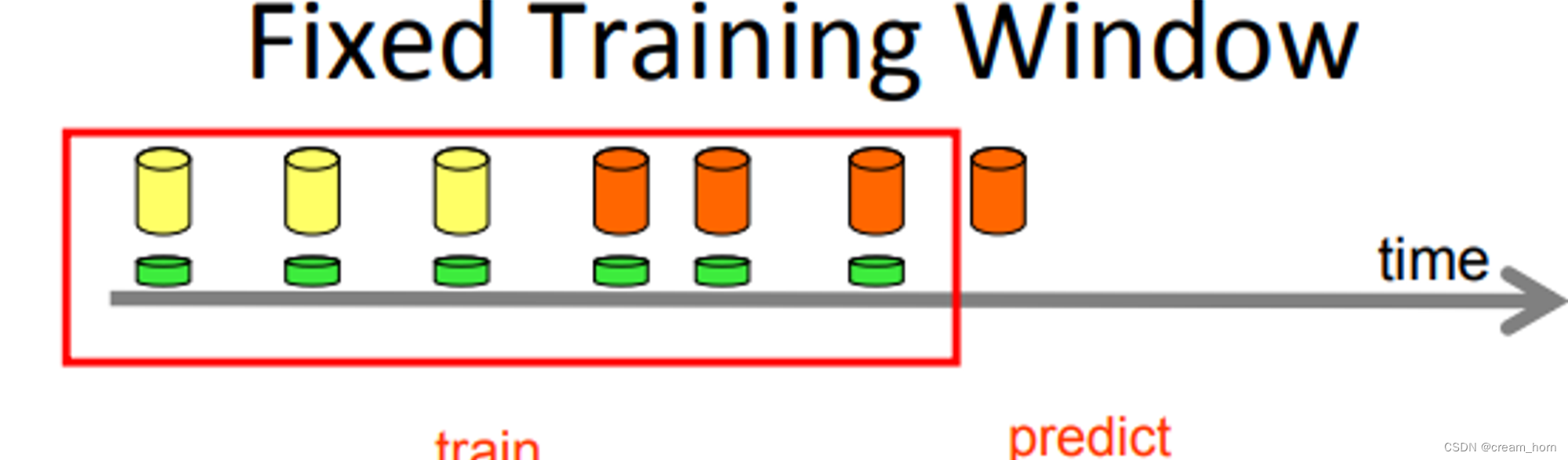
基于窗口的检测方法
- 将数据划分为多个固定大小或动态调整的窗口,并在每个窗口内单独计算统计量或模型性能。通过比较不同窗口的统计量或模型性能的变化,可以检测到概念漂移
-
优点 适用场景:捕捉局部或短期的概念漂移 适用对象:流数据/在线学习(数据连续到达,需要快速检测到任何变化),通过动态调整窗口大小,可以更灵活地适应不同速度和规模的变化;除此之外,不仅适用于数值型数据,还可以拓展到分类数据、文本数据等其他类型的数据。 缺点 窗口大小选择问题:过大可能无法及时检测到快速的概念变化;过小可能会导致对噪声或短暂波动过度敏感。 -
-
基于模型的检测方法
- 通过构建模型来捕捉数据的分布,监控其性能(准确度、精确度、召回率或F1分数等)变化,当模型指标下降或当新数据的分布与模型预期的分布不一致时,即可认为发生了概念漂移。这类方法包括基于神经网络、决策树、支持向量机等模型的方法。
-
优点 能识别复杂的数据分布变化,能够有效识别和捕捉数据分布和关系上发生的复杂、非线性、非平稳的变化 可以结合模型的预测性能来检测漂移,此外,基于模型的检测方法通常具有较高的自动化程度,可以自动调整模型参数以适应新的数据分布,从而实现对概念漂移的实时监测和预警 缺点 模型的构建和更新可能较为复杂,且需要选择合适的性能评价指标
-
基于学习的检测方法
- 通过应用机器学习算法来学习数据的正常行为模式,并据此识别出异常或数据分布的变化。特别是在使用基于距离的异常检测算法时,如欧氏距离和曼哈顿距离,我们能够更精确地捕捉到数据中的异常情况。
-
优点 能够自动学习数据的复杂模式,对于未知的概念漂移可能具有一定的适应能力 应用场景:适用于具有大量训练数据且概念漂移较为复杂的场景,如自然语言处理、图像识别等。
缺点 需要大量的训练数据来构建有效的模型,且可能受到模型泛化能力(在面对未曾见过的数据时的表现能力)的影响
-
上下文相关的检测方法
- 考虑数据的上下文信息来检测漂移。在日常生活中,我们经常会根据上下文来理解别人的话或某个事件,比如,当听到“下雨了”这句话时,如果上下文是在讨论明天是否适合户外活动,那我们就会理解到这句话意味着明天可能不适合出门。上下文通常指的是与当前处理的数据点或事件相关的背景信息或环境状态。这种上下文信息可以是显式的,例如数据集中的某些特征或属性,也可以是隐式的或隐藏的,例如:如果你的花费一天激增到几百几千块钱,可能被认为是一个异常值,但如果考虑到这一天是节假日,那么就是合理的。简单来说,就是一个能够“看”到数据背后故事或背景的探测器。
-
优点 能够更准确地反映数据分布的变化,尤其是当变化与上下文信息密切相关时 应用场景:适用于数据分布变化与上下文信息密切相关的场景,如推荐系统、地理位置相关的服务等 缺点 可能需要额外的上下文信息获取和处理步骤,增加了实现的复杂性
在实践中,可能需要尝试多种方法或者构建并结合多个探测器(集成方法)以提供强大的性能以形成更为全面的概念检测漂移系统,并通过交叉验证或其他评估技术来确定哪种方法在特定情况下表现最佳。
在考虑选择哪种检测方法时,取决于具体问题的性质、数据的特点、以及对性能和计算资源的要求。以下是一些具体情况的考虑因素:
方法选择考虑因素
| 数据特性 | 数据量 | 如果数据量很大,可能需要选择计算成本较低的方法 |
| 维数 | 高维数据可能需要降维技术或特定的距离度量方法 | |
| 流速 | 快速流动的数据流可能需要实时或在线检测方法 | |
| 性能要求 | 响应时间 | 对漂移响应时间的要求可能会影响选择实时或非实时的检测算法 |
| 准确性 | 对检测准确性的要求可能会影响选择统计测试或基于模型的方法 | |
| 业务和应用场景 | 成本敏感性 | 在一些应用中,错误警报的成本可能非常高,这可能需要更保守的检测阈值 |
| 实时决策需求 | 对于需要立即做出决策的应用,如金融交易监控,可能需要快速响应的检测方法 | |
| 监督与无监督 | 如果真实标签容易获得,可能会选择基于监督学习的检测方法;否则,无监督或半监督方法可能更合适 | |
| 自动化需求 | 如果希望检测系统需要较少的人工干预,可能需要选择自动化程度高的检测算法 | |
| 可解释性要求 | 在某些应用中,检测算法的决策过程需要是可解释的,以便用户能够理解并信任系统的输出 | |
概念漂移的检测关键应用于需要持续从数据流中学习并适应环境变化的场景:如股票市场预测、用户行为分析、环境监测等。
让我们来看一个实际应用。
实际应用和分析举例
案例:在金融领域,股票价格和交易量等时间序列数据可能会随市场条件的变化而发生概念漂移。
方法:MindSpore(一个开源的AI计算框架文档)中展示了使用他们的mindarmour组件来检测标普500指数记录的美国股市平均记录中的概念漂移。
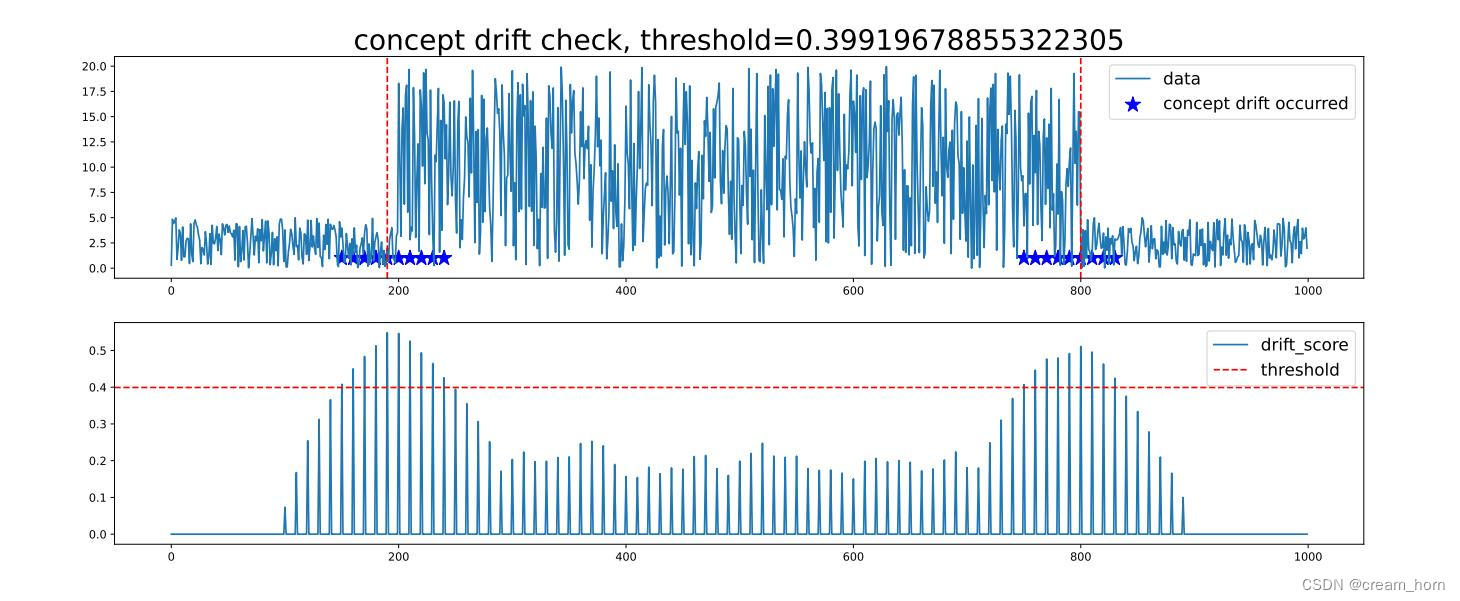
结果:通过检测,可能发现在某些特定时间段内,如经济危机或重大市场事件期间,数据分布发生了显著变化。投资者和风险管理经理能够识别市场趋势的变化,并采取相应措施,如重新训练模型或调整投资策略。
概念漂移检测是机器学习领域中的一个重要问题。通过不断的研究和探索,未来还会有更加智能高效的方法应对这个问题。感谢你的阅读~希望这篇博客能给你带来收获!

















 1130
1130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









