







写在前面,因为我们最近的大作业项目需要用到热点排行这个功能,因为我们是要使用Elasticsearch来存储数据,然后最初设想是在ES中实现这个热点排行的功能,但是经过仔细思考,在我们这个项目中使用ES来做热点排行是一个很蠢的方式,因为我们这只是一个很小的排行,所以最终我们还是使用Redis来实现热点排行
使用LRU?
LRU是一种常见的算法,假如我们设定TOP10的热点数据,那么我们可以规定LRU容量为10,当容量没有满的时候,我们可以直接放入,当满了的时候我们就将最后一个排除然后引入最新的放在首部
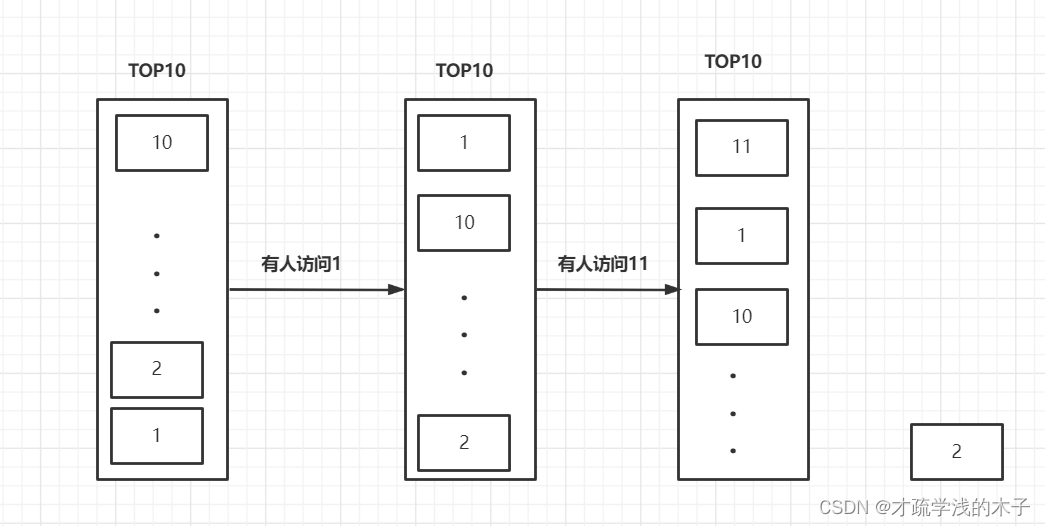
这看似实现了热点排行但是没有,比如说2号数据访问100次而11号数据才访问一次,那么使用LRU就把100次访问的排除掉了,这就是不合理的,所以我们应该以每个数据的访问频率来选择排行
如何进行访问率排行
把所有数据都加入内存中,然后记录每个数据被访问的频率,这看起来就是很简单的,使用zset就可以实现,但是假如你的数据有100w条呢?你这样全部存入Redis,那么会导致大key的出现,同时引起Redis的效率降低,那么可以单独启动一台服务器来保存排行榜的数据?这其实是浪费的,因为一般我们的排行榜都是TOP10~TOP100,基本占用不了多少内存,而在我们的项目中我们的数据量是比较少的,而且有上传时间,一般上传时间越近更容易上TOP10,而且我们需要的只是TOP10,所有有两种方案
第一种:在数据库中挑选最近上传的10条数据,然后如果有人访问了这10条数据,那么对应的数据的访问频率就加一,不在这10条数据里面就不去管它,然后经过一段时间就去掉末尾几条访问频率较低的数据,再随机挑选几条假如TOP10,然后循环
第二种:第一种还是存在一点缺陷,就是有可能最开始TOP10就是访问最高的,那么可能会把真正的TOP10挤下去,所有在第二种方案中,我们缓存20条数据,每隔一段时间去掉访问频率最低的5-10条,然后随机挑选进来补充至20条但是我们只取前10,其它与方案一类似,只是缓存更多的数据
代码编写
理解思路过后,代码编写是最简单的一步,如何在项目中引入Redis以及操作Redis的依赖配置就不再赘述,因为那个与代码编写逻辑没有什么关联
选择最近20条数据
public void getCur2MySQL(){
Set<ZSetOperations.TypedTuple<String>> set = new HashSet<>();
List<Integer> cur2Ids = baseMapper.getCur2Ids();
cur2Ids.stream().forEach(e->{
DefaultTypedTuple<String> tuple = new DefaultTypedTuple<String>(String.valueOf(e),0d);
set.add(tuple);
});
redisTemplate.opsForZSet().removeRange(Constant.POLICY_TOP_10,0,-1);
redisTemplate.opsForZSet().add(Constant.POLICY_TOP_10,set);
}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











