







文章目录
- 一. 基于FastAPI之Web站点开发
- 二. 基于Web请求的FastAPI通用配置
- 三. Python爬虫介绍
- 四. 使用Python爬取GDP数据
- 五. 多任务爬虫实现
- 六. 数据可视化
- 七. Logging日志模块
一. 基于FastAPI之Web站点开发
1. 基于FastAPI搭建Web服务器
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
# 通过@app路由装饰器收发数据
# @app.get(参数) : 按照get方式接受请求数据
# 请求资源的 url 路径
@app.get("/index.html")
def main():
with open("source/html/index.html", "rb") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/html"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
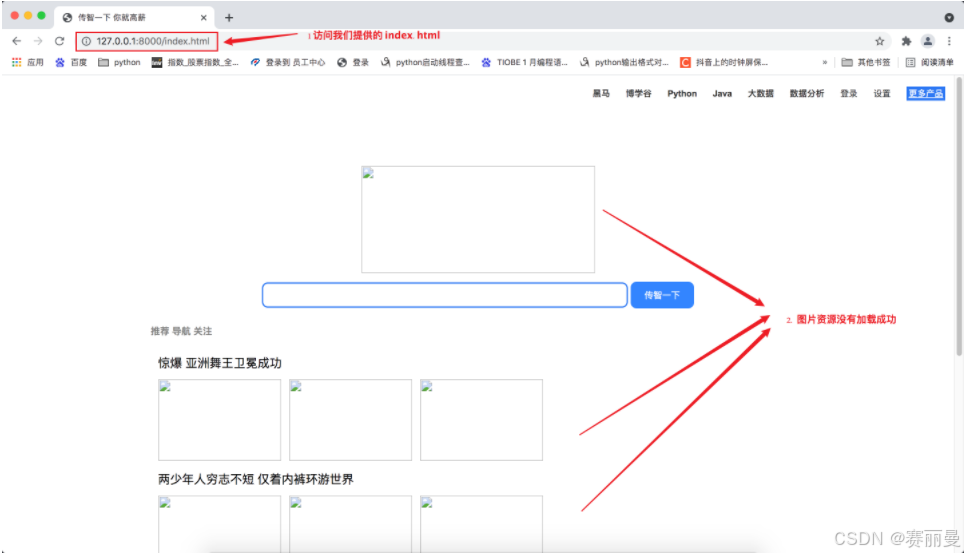
2. Web服务器和浏览器的通讯流程
实际上Web服务器和浏览器的通讯流程过程并不是一次性完成的, 这里html代码中也会有访问服务器的代码, 比如请求图片资源。

那像0.jpg、1.jpg、2.jpg、3.jpg、4.jpg、5.jpg、6.jpg这些访问来自哪里呢
答:它们来自index.html

3. 浏览器访问Web服务器的通讯流程

浏览器访问Web服务器的通讯流程:
浏览器(127.0.0.1/index.html) ==> 向Web服务器请求index.htmlWeb服务器(返回index.html) ==>浏览器浏览器解析index.html发现需要0.jpg ==>发送请求给Web服务器请求0.jpgWeb服务器收到请求返回0.jpg ==>浏览器接受0.jpg
通讯过程能够成功的前提:
浏览器发送的0.jpg请求, Web服务器可以做出响应, 也就是代码如下
# 当浏览器发出对图片 0.jpg 的请求时, 函数返回相应资源
@app.get("/images/0.jpg")
def func_01():
with open("source/images/0.jpg", "rb") as f:
data = f.read()
print(data)
return Response(content=data, media_type="jpg")
4. 加载图片资源代码
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
@app.get("/images/0.jpg")
def func_01():
with open("source/images/0.jpg", "rb") as f:
data = f.read()
print(data)
return Response(content=data 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5031
5031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









