







Pandas使用这些函数处理缺失值:
1)isnull和notnull: 检测是否为空值,可用于df和Series
2) dropna: 丢弃、删除缺失值
* axis: 删除行还是列,{0 or 'index',1 or 'columns'},default 0;
* how: 如果等于any则任何值为空都删除,如果等于all则所有值都为空才删除;
* inplace: 如果为Ture则覆盖当前df,否则返回新的df;
3) fillna:填充空值
* value: 用于填充的值,可以是单个值,或者字典(key是列名,value是值);
* method: 等于ffill使用前一个不为空的值填充forword fill;等于bfill使用后一个不为空的值填4)充4)backword fill;
* axis: 按行还是列填充,{0 or 'index',1 or 'columns'};
* inplace: 如果为True则修改当前df,否则返回新的df;
下面进入实例演示:
实例:特殊Excel的读取、清洗、处理:
我们要处理的execl如下图所示:

可以看出,在要处理的execl中 ,存在空行。而且分数存在缺失值,我们要做的就是对缺失值进行填充并且对成绩单进行合并。
步骤1:读取excel的时候,忽略前几个空行
studf = pd.read_excel("datas/student.xlsx",skiprows=2) #skiprows 可以指定需要跳过多少行运行结果:
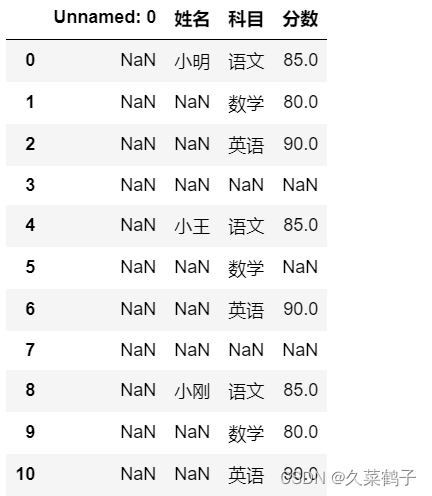
步骤2:检测空值
这里我将展示isnull方法。
studf.isnull() #判断 DataFrame 或者Series 里面是否为空值。返回结果为一个bool值:

isnull/notnull 方法还可以和.loc搭配使用。
# 筛选没有空分数的所有行
studf.loc[studf["分数"].notnull(),:]
步骤3:删除全是空值的列和行:
#删除全是空值的列
studf.dropna(axis="columns",how='all',inplace=True)
studf
#删除全是空值的行
studf.dropna(axis="index",how='all',inplace=True)
studf处理完后 ,execl如下:

可以看到还是会有一些空值,因为我们dropna的how=设定为“all”,所以一些不全为空值的列或行
无法删除。
步骤4:将分数列为空的填充为0分:
studf.fillna({"分数":0})
步骤5:将姓名的缺失值填充:
studf.loc[:,"姓名"]=studf["姓名"].fillna(method="ffill")
# 此.loc方法等同于在进行分数空值替换时,直接替换的方法
# method 中 ffill 意思是 如果为空值则使用前面的有效值填充,ffill: forword fill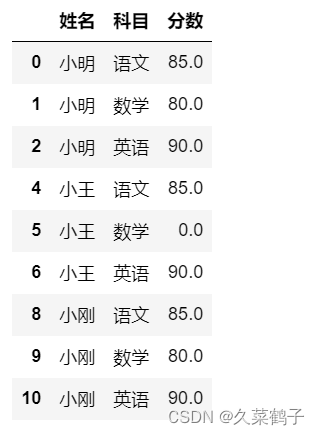
到这里差不多就完成了!
最后别忘了要对execl进行保存
studf.to_excel('datas/student_new.xlsx',index=False)本章结束,谢谢大家阅读!
撰写文章不易,希望大家多多点赞收藏!














 3603
3603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









