






Gilmer 等 (2017) 提出的 Message Passing Neural Networks (MPNNs) 框架,是一种用于处理图结构数据的通用方法,特别适合于量子化学中的分子属性预测问题。以下是对 MPNN 框架的详细分析:
1. 框架概述
MPNN 框架基于图神经网络的思想,将分子看作由节点(代表原子)和边(代表化学键)组成的图结构。MPNN 包括两个主要阶段:
- 消息传递阶段(Message Passing Phase):通过节点之间的信息交换来更新节点的隐藏状态。
- 读出阶段(Readout Phase):聚合图中所有节点的信息以生成整个图的特征向量,用于最终的预测任务。
2. 消息传递阶段
-
在消息传递阶段,MPNN 通过多次迭代来更新每个节点的隐藏状态。每次迭代包括两个步骤:
- 消息函数
M
t
M_t
Mt:从节点的邻居节点接收信息。消息计算如下:
m v t + 1 = ∑ w ∈ N ( v ) M t ( h v t , h w t , e v w ) m_{v}^{t+1} = \sum_{w \in N(v)} M_t(h_v^t, h_w^t, e_{vw}) mvt+1=w∈N(v)∑Mt(hvt,hwt,evw)
其中 N ( v ) N(v) N(v) 是节点 v v v 的邻居集合, h v t h_v^t hvt 和 h w t h_w^t hwt 分别为节点 v v v 和其邻居 w w w 的隐藏状态, e v w e_{vw} evw 是边的特征。 - 节点更新函数
U
t
U_t
Ut:利用接收到的消息来更新节点的隐藏状态:
h v t + 1 = U t ( h v t , m v t + 1 ) h_{v}^{t+1} = U_t(h_v^t, m_{v}^{t+1}) hvt+1=Ut(hvt,mvt+1)
- 消息函数
M
t
M_t
Mt:从节点的邻居节点接收信息。消息计算如下:
-
消息函数和节点更新函数 可以通过不同的神经网络架构(如 G R U GRU GRU 或 &LSTM&)实现,从而提高信息传递和更新的灵活性。
3. 读出阶段
- 在完成消息传递后,MPNN 使用 读出函数
R
R
R 聚合所有节点的隐藏状态来计算整个图的输出特征:
y ^ = R ( { h v T ∣ v ∈ G } ) \hat{y} = R(\{h_v^T | v \in G\}) y^=R({hvT∣v∈G})- 读出函数需要对节点的排列具有不变性,以确保图同构(Graph Isomorphism)的不变性。
4. MPNN 的创新点
- 泛化现有模型:MPNN 框架统一了多种现有的图神经网络模型,如 Gated Graph Neural Networks (GG-NN)、Molecular Graph Convolutions 等,使其在一个通用框架下进行对比和改进。
- 长距离依赖:通过增加虚拟边和主节点的方式,MPNN 能够更有效地捕捉长距离的节点依赖关系,从而提升对分子复杂结构的建模能力。
- 高效训练:MPNN 在 QM9 数据集上取得了量子力学属性预测的最新结果,同时相较于传统的 DFT 方法,计算效率提升了约 300,000 倍。
5. 应用与效果
- 数据集:MPNN 在 QM9 数据集上进行了测试,该数据集包含约 130k 个小分子的 13 项量子力学属性预测任务。
- 性能表现:MPNN 在 13 个预测任务中的 11 项达到了化学精度(Chemical Accuracy),证明其在量子化学预测中的高效性和准确性。
6. 代码分析
对模型中的关键代码进行分析,代码如下:
6.1数据处理模块
6.1.1 数据集侧写
class MyTransform: # 自定义数据预处理类,用于保留目标值
def __call__(self, data): # 使该类可调用,处理传入的数据
data = copy.copy(data) # 创建数据副本,避免修改原数据
data.y = data.y[:, target] # 仅保留目标值列
return data # 返回处理后的数据
class Complete: # 自定义补全数据类,生成完整的边连接信息
def __call__(self, data): # 使该类可调用,处理传入的数据
data = copy.copy(data) # 创建数据副本
device = data.edge_index.device # 获取数据所在的设备(CPU或GPU)
row = torch.arange(data.num_nodes, dtype=torch.long, device=device) # 创建节点的行索引
col = torch.arange(data.num_nodes, dtype=torch.long, device=device) # 创建节点的列索引
row = row.view(-1, 1).repeat(1, data.num_nodes).view(-1) # 重构行索引,使每个节点都连接到所有节点
col = col.repeat(data.num_nodes) # 重构列索引,确保每个节点都有连接
edge_index = torch.stack([row, col], dim=0) # 组合行列索引,得到完整的边连接信息
edge_attr = None # 初始化边的属性
if data.edge_attr is not None: # 如果原始数据中包含边的属性
idx = data.edge_index[0] * data.num_nodes + data.edge_index[1] # 计算边的索引
size = list(data.edge_attr.size()) # 获取边属性的大小
size[0] = data.num_nodes * data.num_nodes # 修改边属性的大小
edge_attr = data.edge_attr.new_zeros(size) # 创建一个新的全零边属性张量
edge_attr[idx] = data.edge_attr # 将原始边属性复制到新的边属性张量
edge_index, edge_attr = remove_self_loops(edge_index, edge_attr) # 去除自循环的边
data.edge_attr = edge_attr # 更新数据中的边属性
data.edge_index = edge_index # 更新数据中的边连接信息
return data # 返回处理后的数据
path = osp.join(osp.dirname(osp.realpath(__file__)), '..', 'data', 'QM9') # 设置数据集的路径
transform = T.Compose([MyTransform(), Complete(), T.Distance(norm=False)]) # 定义数据预处理流程,先后执行MyTransform、Complete和距离变换
dataset = QM9(path, transform=transform).shuffle() # 加载并随机打乱QM9数据集
# 标准化目标数据,使其均值为0,标准差为1
mean = dataset.data.y.mean(dim=0, keepdim=True) # 计算目标数据的均值
std = dataset.data.y.std(dim=0, keepdim=True) # 计算目标数据的标准差
dataset.data.y = (dataset.data.y - mean) / std # 标准化目标数据
mean, std = mean[:, target].item(), std[:, target].item() # 获取目标数据的均值和标准差,并转为标量
# 划分数据集为训练集、验证集和测试集
test_dataset = dataset[:10000] # 获取前10000个数据作为测试集
val_dataset = dataset[10000:20000] # 获取10000到20000个数据作为验证集
train_dataset = dataset[20000:] # 获取剩余的数据作为训练集
test_loader = DataLoader(test_dataset, batch_size=128, shuffle=False) # 定义测试集的数据加载器
val_loader = DataLoader(val_dataset, batch_size=128, shuffle=False) # 定义验证集的数据加载器
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True) # 定义训练集的数据加载器
从以上代码入手,发现数据集是通过QM9()类来调用的,在vscode上通过设置断点进行代码调试,来观察QM9()的信息,如下所示:
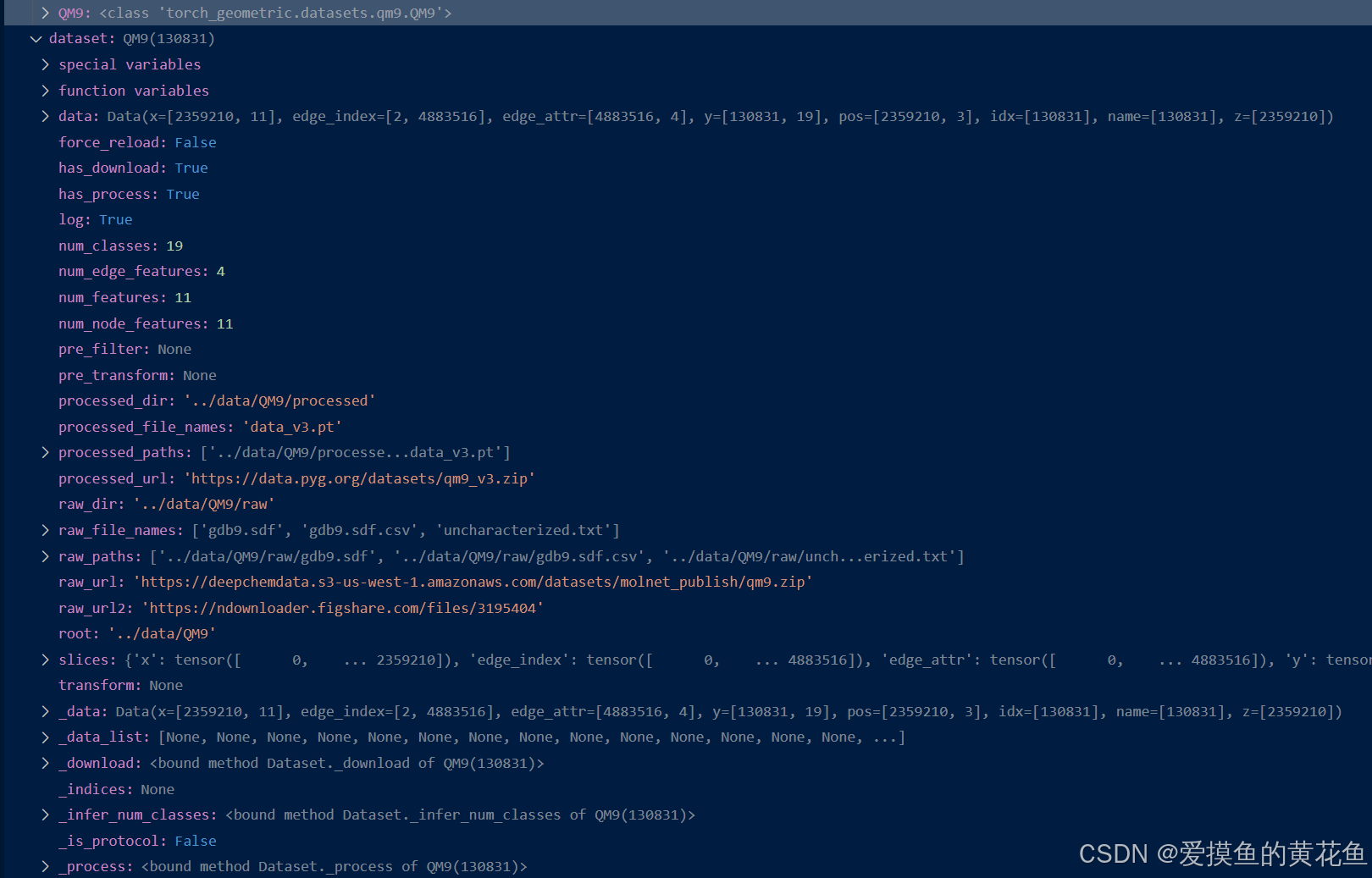
可知,QM9()类包含了许多信息,通过创建QM9()的实例,并对其命名为dataset,可知
- d a t a s e t . d a t a dataset.data dataset.data表示了QM9数据集的数据,包括了节点特征(原子特征) x x x,边索引 e d g e _ i n d e x edge\_index edge_index,边特征 e d g e _ a t t r edge\_attr edge_attr,每个分子的回归目标 y y y等等;
- d a t a s e t . n u m _ c l a s s dataset.num\_class dataset.num_class表示了回归目标的个数,共有19个回归目标需要预测;
- d a t a s e t . n u m _ e d g e _ f e a t u r e s dataset.num\_edge\_features dataset.num_edge_features表示了边特征的个数,且从 e d g e _ a t t r edge\_attr edge_attr的维度中也看出是4;
- ……不一一赘述
6.1.2 数据预处理
接下来,研究对数据进行预处理的代码
def process(self) -> None:
try:
from rdkit import Chem, RDLogger # 尝试从rdkit导入所需的模块
from rdkit.Chem.rdchem import BondType as BT # 从rdkit导入化学键类型
from rdkit.Chem.rdchem import HybridizationType # 从rdkit导入原子杂化类型
RDLogger.DisableLog('rdApp.*') # 禁用RDKit日志输出,避免冗长的日志信息
WITH_RDKIT = True # 设置标志变量,表示RDKit库已成功导入
except ImportError:
WITH_RDKIT = False # 如果没有安装rdkit,则设置为False
if not WITH_RDKIT: # 如果未安装rdkit
print(("Using a pre-processed version of the dataset. Please "
"install 'rdkit' to alternatively process the raw data."),
file=sys.stderr) # 提示用户安装rdkit以进行原始数据处理
data_list = fs.torch_load(self.raw_paths[0]) # 加载预处理的torch数据
data_list = [Data(**data_dict) for data_dict in data_list] # 将数据字典转换为Data对象
if self.pre_filter is not None: # 如果存在预处理过滤器
data_list = [d for d in data_list if self.pre_filter(d)] # 过滤数据
if self.pre_transform is not None: # 如果存在预处理变换
data_list = [self.pre_transform(d) for d in data_list] # 对数据进行变换
self.save(data_list, self.processed_paths[0]) # 保存处理后的数据
return # 结束函数
#--------------------------------------------------------
# 以上代码在安装了rdkit库以后可以不关注
# 定义原子类型和化学键类型映射
types = {'H': 0, 'C': 1, 'N': 2, 'O': 3, 'F': 4} # 原子类型映射
bonds = {BT.SINGLE: 0, BT.DOUBLE: 1, BT.TRIPLE: 2, BT.AROMATIC: 3} # 键类型映射
with open(self.raw_paths[1]) as f: # 打开目标数据文件
target = [[float(x) for x in line.split(',')[1:20]] # 解析目标值,从第二列到第二十列
for line in f.read().split('\n')[1:-1]] # 跳过文件的第一行和最后一行
y = torch.tensor(target, dtype=torch.float) # 将目标值转换为PyTorch张量
y = torch.cat([y[:, 3:], y[:, :3]], dim=-1) # 交换目标值的前后3列
y = y * conversion.view(1, -1) # 进行单位转换
with open(self.raw_paths[2]) as f: # 打开跳过的索引文件
skip = [int(x.split()[0]) - 1 for x in f.read().split('\n')[9:-2]] # 解析跳过的索引
suppl = Chem.SDMolSupplier(self.raw_paths[0], removeHs=False, sanitize=False) # 加载分子数据集,不去除氢原子,且不进行分子标准化
data_list = [] # 存储处理后的数据列表
for i, mol in enumerate(tqdm(suppl)): # 遍历每个分子,显示进度条
if i in skip: # 如果当前分子在跳过列表中,跳过处理
continue
N = mol.GetNumAtoms() # 获取分子的原子数
conf = mol.GetConformer() # 获取分子的构象
pos = conf.GetPositions() # 获取原子的位置坐标
pos = torch.tensor(pos, dtype=torch.float) # 转换为PyTorch张量
# 初始化各个特征列表
type_idx = [] # 原子类型索引
atomic_number = [] # 原子序数
aromatic = [] # 是否芳香
sp = [] # 是否sp杂化
sp2 = [] # 是否sp2杂化
sp3 = [] # 是否sp3杂化
num_hs = [] # 氢原子数量
# 遍历分子中的所有原子
for atom in mol.GetAtoms():
type_idx.append(types[atom.GetSymbol()]) # 添加原子类型索引
atomic_number.append(atom.GetAtomicNum()) # 添加原子序数
aromatic.append(1 if atom.GetIsAromatic() else 0) # 判断是否芳香
hybridization = atom.GetHybridization() # 获取原子的杂化类型
sp.append(1 if hybridization == HybridizationType.SP else 0) # 判断是否sp杂化
sp2.append(1 if hybridization == HybridizationType.SP2 else 0) # 判断是否sp2杂化
sp3.append(1 if hybridization == HybridizationType.SP3 else 0) # 判断是否sp3杂化
z = torch.tensor(atomic_number, dtype=torch.long) # 将原子序数转换为张量
rows, cols, edge_types = [], [], [] # 初始化边列表和边类型列表
for bond in mol.GetBonds(): # 遍历分子中的所有化学键
start, end = bond.GetBeginAtomIdx(), bond.GetEndAtomIdx() # 获取键的起始和终止原子索引
rows += [start, end] # 添加边的起始原子索引
cols += [end, start] # 添加边的终止原子索引
edge_types += 2 * [bonds[bond.GetBondType()]] # 添加边的类型(双向)
edge_index = torch.tensor([rows, cols], dtype=torch.long) # 转换为PyTorch张量,表示边的索引
edge_type = torch.tensor(edge_types, dtype=torch.long) # 转换为PyTorch张量,表示边的类型
edge_attr = one_hot(edge_type, num_classes=len(bonds)) # 对边的类型进行one-hot编码
perm = (edge_index[0] * N + edge_index[1]).argsort() # 计算边索引的排序
edge_index = edge_index[:, perm] # 对边索引进行排序
edge_type = edge_type[perm] # 对边类型进行排序
edge_attr = edge_attr[perm] # 对边属性进行排序
row, col = edge_index # 解包边索引
hs = (z == 1).to(torch.float) # 获取氢原子的标志(值为1表示氢原子)
num_hs = scatter(hs[row], col, dim_size=N, reduce='sum').tolist() # 计算每个原子的氢原子数量
# 将不同的原子特征进行one-hot编码和堆叠
x1 = one_hot(torch.tensor(type_idx), num_classes=len(types)) # 原子类型的one-hot编码
x2 = torch.tensor([atomic_number, aromatic, sp, sp2, sp3, num_hs], dtype=torch.float).t().contiguous() # 其他原子特征
x = torch.cat([x1, x2], dim=-1) # 将所有特征合并
# 获取分子的其他信息
name = mol.GetProp('_Name') # 获取分子的名称
smiles = Chem.MolToSmiles(mol, isomericSmiles=True) # 获取分子的SMILES表示
# 创建Data对象,包含原子特征、边索引、边属性、目标值等信息
data = Data(
x=x,
z=z,
pos=pos,
edge_index=edge_index,
smiles=smiles,
edge_attr=edge_attr,
y=y[i].unsqueeze(0), # 目标值
name=name,
idx=i, # 分子的索引
)
if self.pre_filter is not None and not self.pre_filter(data): # 如果存在预处理过滤器,且不通过过滤器
continue
if self.pre_transform is not None: # 如果存在预处理变换
data = self.pre_transform(data) # 对数据进行变换
data_list.append(data) # 将处理后的数据添加到数据列表中
self.save(data_list, self.processed_paths[0]) # 保存处理后的数据列表
在安装rdkit库之后,前半部分代码基本可以忽略不计,直接关注后半部分。
6.1.2.1 数据文件了解和初步处理
首先,模型对原始数据文件进行处理,QM数据集原始数据文件包括三个文件:
- qm9.sdf: 分子结构,打开文件,内容如下:(仅展示两个分子)
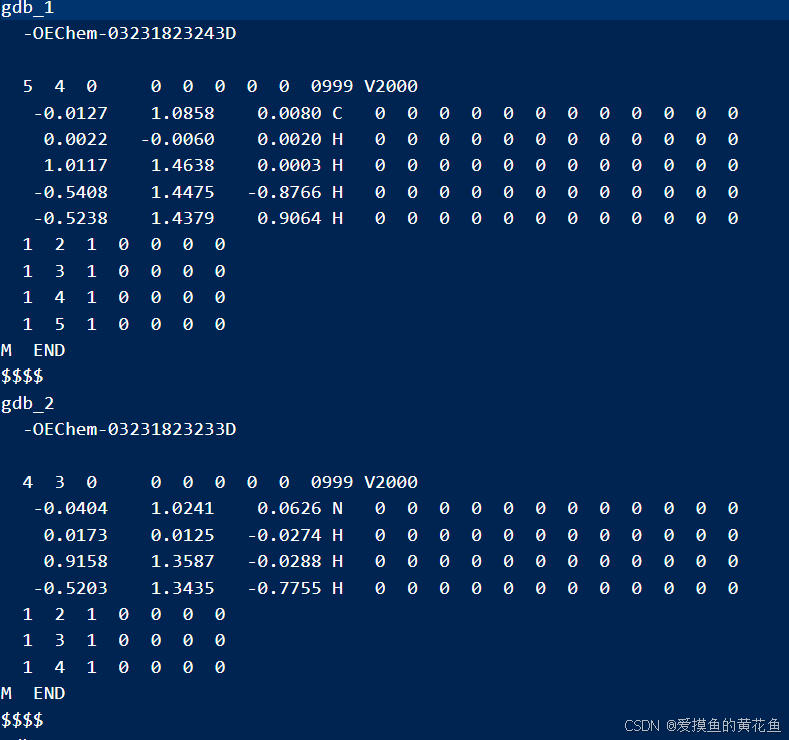
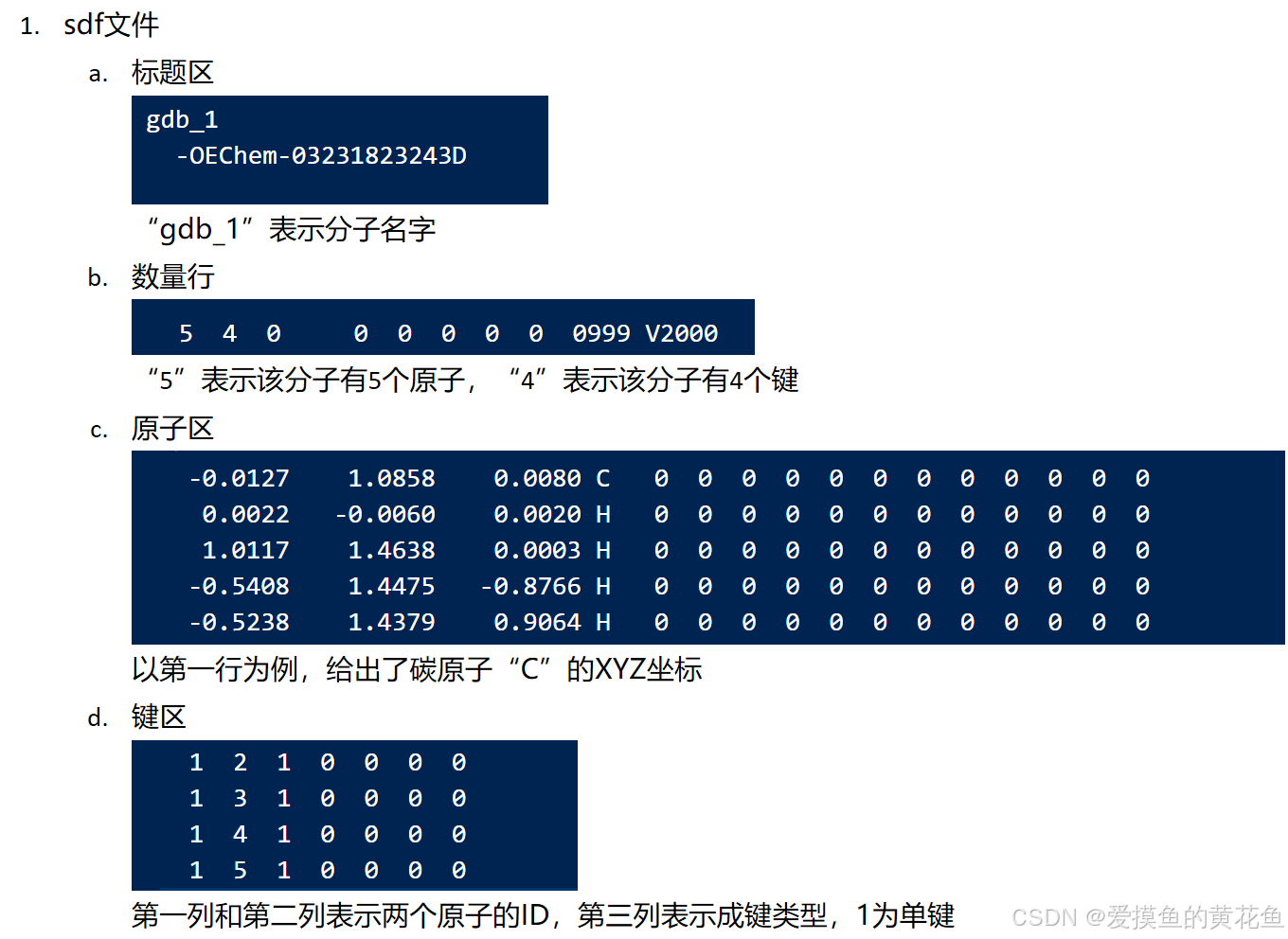
具体含义如下:
参考链接
- qm9.sdf.csv: 分子性质表,文件内容如下:(仅展示前8行内容)
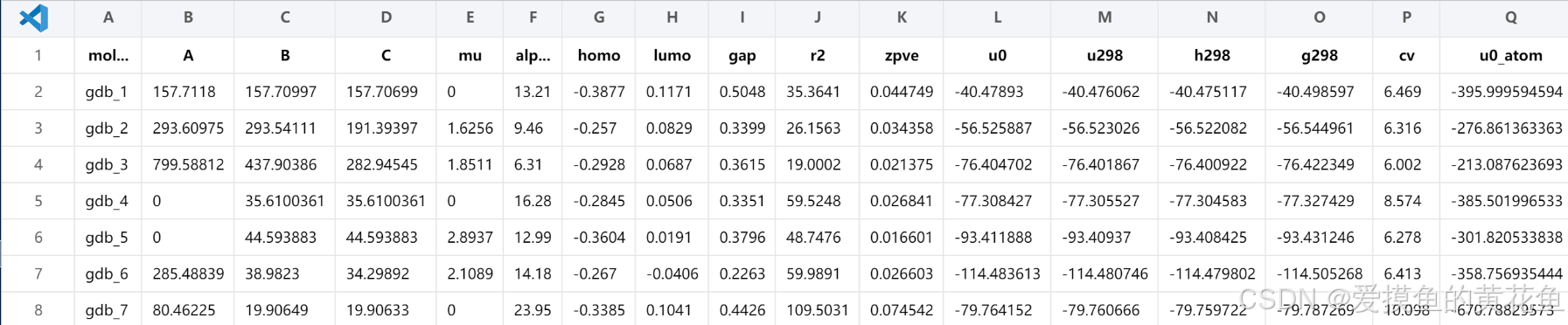
该表主要包含分子id和19个目标回归指标,详情如下:(sorry,太爱摸鱼所以就没翻译)
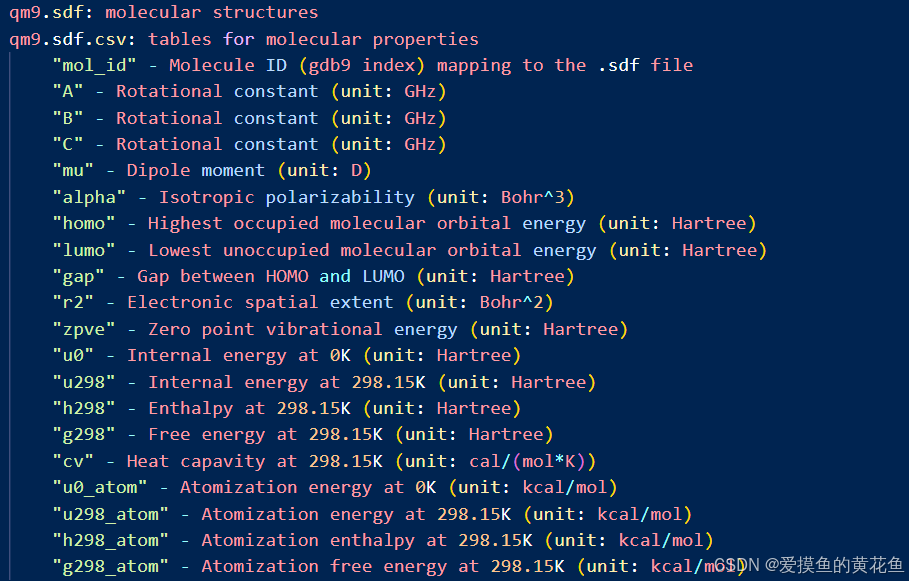
总的来说,QM9数据集就是用于预测这些指标的数据集。原论文利用MPNN框架也是做的这件事。 - uncharacterized.txt这个文件很奇怪,在代码中是要展示被跳过的分子是哪些,代码中专门有设定 s k i p skip skip变量来连接这个文件,并对该文件中的分子进行跳过,不做处理。
6.1.2.2 数据处理
之后就是在进行分子特征的提取,关键代码如下:
# 将不同的原子特征进行one-hot编码和堆叠
x1 = one_hot(torch.tensor(type_idx), num_classes=len(types)) # 原子类型的one-hot编码
x2 = torch.tensor([atomic_number, aromatic, sp, sp2, sp3, num_hs], dtype=torch.float).t().contiguous() # 其他原子特征
x = torch.cat([x1, x2], dim=-1) # 将所有特征合并
这里的
x
x
x 张量就是前面提取的特征进行concat操作之后得到的分子特征,维度是[
n
u
m
_
n
o
d
e
s
num\_nodes
num_nodes, 11]。
具体细节是如何构建分子特征的,代码已在上方,鱼认为姑且可以算是后话,闲下来时再进行补充,先允许鱼摸会鱼~
6.2 模型具体架构代码
接下来研究模型具体代码,查看其网络架构。
class Net(torch.nn.Module): # 定义神经网络模型
def __init__(self): # 网络初始化函数
super().__init__() # 调用父类的初始化方法
self.lin0 = torch.nn.Linear(dataset.num_features, dim) # 第一层全连接层,输入特征维度为dataset.num_features,输出为dim
nn = Sequential(Linear(5, 128), ReLU(), Linear(128, dim * dim)) # 定义NNConv的子网络结构
self.conv = NNConv(dim, dim, nn, aggr='mean') # 定义图卷积层,使用子网络nn并采取mean聚合方式
self.gru = GRU(dim, dim) # 定义GRU网络,用于序列建模
self.set2set = Set2Set(dim, processing_steps=3) # 定义Set2Set池化层,处理步骤为3
self.lin1 = torch.nn.Linear(2 * dim, dim) # 定义第二层全连接层
self.lin2 = torch.nn.Linear(dim, 1) # 定义输出层,输出一个值
def forward(self, data): # 前向传播函数
print(f"We will start with the following input data.") # 打印将要处理的输入数据
print(f"Input data shape: {data.x.shape}") # 打印输入数据的形状
# 解释:data.x表示节点特征,shape[0]表示节点数,shape[1]表示特征维度。节点也就是原子,特征包括原子序数、坐标等信息。一个data就是一个分子。
out = F.relu(self.lin0(data.x)) # 输入数据通过第一层全连接层并应用ReLU激活
print(f"First Linear layer output shape: {out.shape}") # 打印第一层输出的形状
h = out.unsqueeze(0) # 为GRU输入数据增加一个维度,unsqueeze(0)表示在第0维增加一个维度,比如原来是[64],增加后变为[1, 64]
print(f"GRU input shape: {h.shape}") # 打印GRU输入的形状
print() # 打印空行
print(f"Next, we will perform 3 NNConv and GRU operations.") # 打印接下来将进行3次NNConv和GRU操作
for i in range(3): # 循环进行3次图卷积和GRU操作
print(f"Starting operation {i + 1}.") # 打印开始第i+1次操作
print(f"NNConv input shape: {out.shape}") # 打印NNConv输入的形状
print(f"Edge index shape: {data.edge_index.shape}") # 打印边连接信息的形状
print(f"Edge attribute shape: {data.edge_attr.shape}") # 打印边属性的形状
m = F.relu(self.conv(out, data.edge_index, data.edge_attr)) # 图卷积层输出
print(f"NNConv output shape and GRU input(less 1 wnsqueeze): {m.shape}") # 打印图卷积层输出的形状
print(f"Hiddent state shape before GRU: {h.shape}") # 打印GRU输入的形状
out, h = self.gru(m.unsqueeze(0), h) # 使用GRU处理数据
print(f"GRU output shape: {out.shape}") # 打印GRU输出的形状
print(f"Hidden state shape: {h.shape}") # 打印隐藏状态的形状
out = out.squeeze(0) # 移除多余的维度
print(f"GRU output shape after squeeze: {out.shape}") # 打印移除维度后的形状
print() # 打印空行
print(f"Finshed 3 NNConv and GRU operations.") # 打印完成3次NNConv和GRU操作
out = self.set2set(out, data.batch) # 使用Set2Set池化层处理输出
print(f"Set2Set output shape: {out.shape}") # 打印Set2Set输出的形状
out = F.relu(self.lin1(out)) # 输入通过第二层全连接层并应用ReLU激活
print(f"Second Linear layer output shape: {out.shape}") # 打印第二层输出的形状
out = self.lin2(out) # 输入通过输出层
print(f"Output layer output shape: {out.shape}")
# 得到了最终的输出,out是一个标量,其表示的是模型对输入数据的预测值
return out.view(-1) # 将输出展平为一维
可以看到,模型的网络架构和前向函数可以说是非常简单的了,回顾消息传递阶段和读出阶段之前所讲公式,这里的代码就是公式的实现。接下来我将逐步分析网络架构:
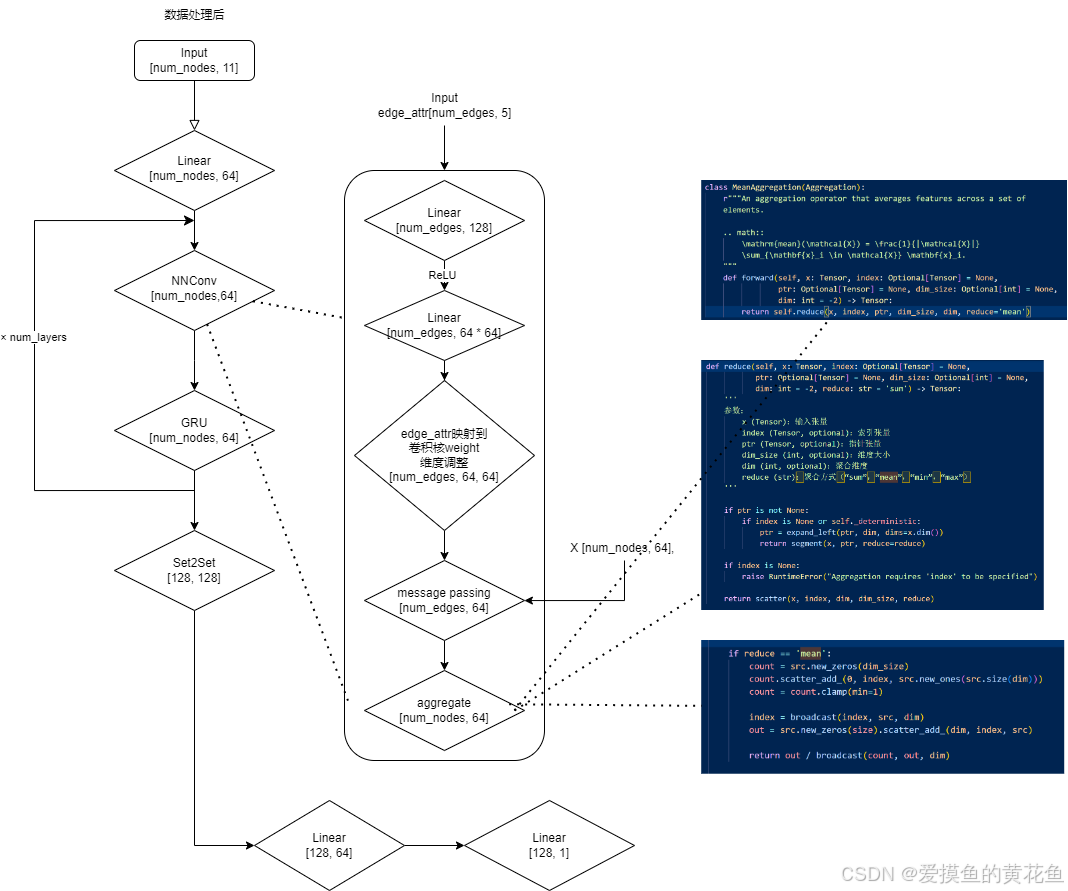
- L i n e a r Linear Linear 线性层进行维度变换,将11维的节点输入特征对齐到64维,映射到高维特征空间以便学习到更复杂的表示;
- N N C o n v NNConv NNConv 图卷积,网络中最最关键的一层架构,用于消息传递和聚合。采取 m e a n mean mean 方式聚合每个节点的邻居信息,并对节点特征进行更新;
- G R U GRU GRU 门控循环单元,用于序列建模。在消息传递过程中,节点的特征在多个时间步上变化, G R U GRU GRU 用于保持历史信息,使节点特征更新更加稳定并有效地整合之前的状态。 G R U GRU GRU 通过其内部的门控机制,可以有效避免梯度消失和爆炸的问题。
- S e t 2 S e t Set2Set Set2Set 是一种专门用于处理集合结构的池化方法,它通过多次迭代操作将节点级别的信息整合为图级别的全局表示。 S e t 2 S e t Set2Set Set2Set 池化可以将图中的所有节点的特征聚合成一个固定大小的向量,这个特征向量代表整个图(分子)的特征。
- 线性层降维并输出,最终输出是一维向量,表示模型对输入分子的预测值。
了解完整体网络架构后,现在开始研究其中的关键组分
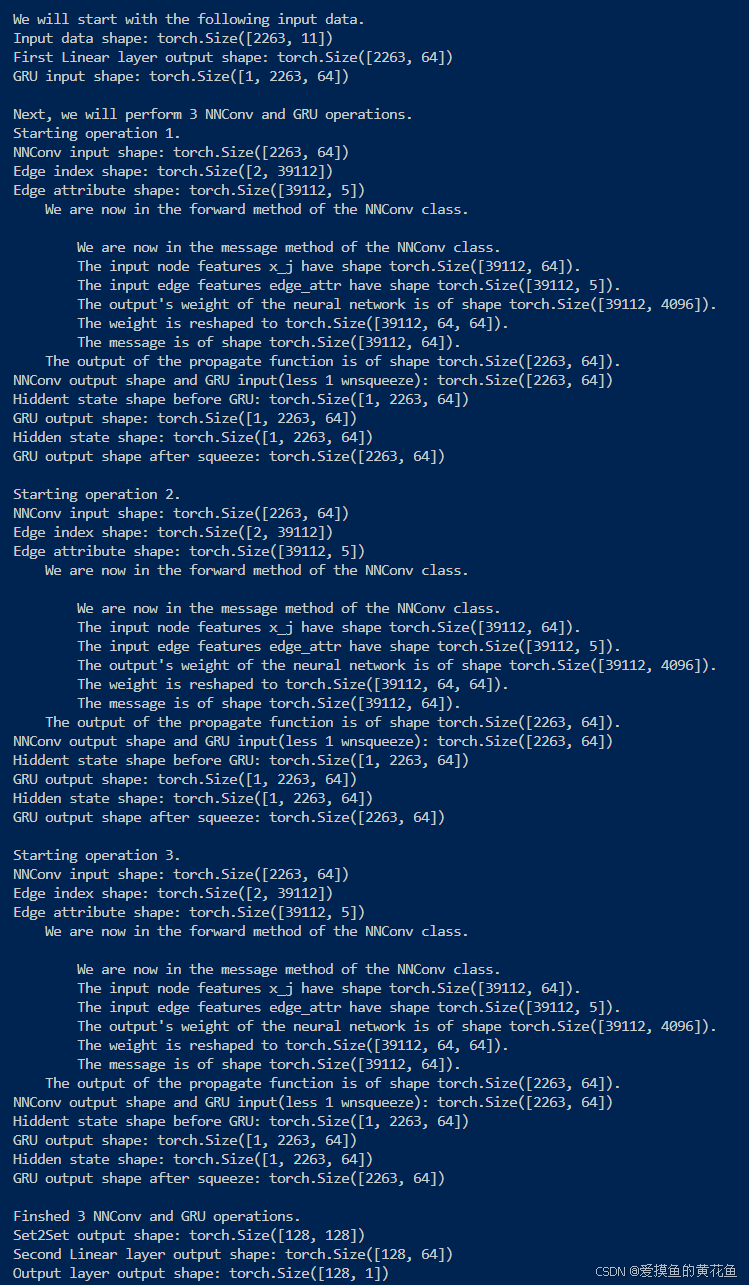
在代码中增加print语句,来查看张量计算流变化,(也可以通过python调试)接下来将结合以上打印内容进行分析
6.2.1 NNConv图卷积
图卷积操作用于聚合每个节点的邻居信息,并对节点特征进行更新,查看NNConv代码,发现其关键函数如下,对其进行研究。
6.2.1.1 propogate函数
def propagate(
self,
edge_index: Adj, # 输入的图的边索引,可以是稀疏张量或其他表示方式
size: Size = None, # 图的大小,默认值为None,表示自动推断大小
**kwargs: Any, # 其他传递的参数,用于构造和更新节点嵌入
) -> Tensor:
r"""The initial call to start propagating messages.这是开始传递消息的初始调用。
Args:
edge_index (torch.Tensor or SparseTensor): 定义图的连接关系/消息传递的稀疏矩阵。
size ((int, int), optional): 赋值矩阵的大小,默认自动推断。
**kwargs: 其他需要的数据,用于构造和聚合消息并更新节点嵌入。
"""
decomposed_layers = 1 if self.explain else self.decomposed_layers # 确定是否需要进行分解层处理
# 调用所有前向传播前的钩子函数,钩子函数指的是在前向传播之前对输入进行修改的函数
for hook in self._propagate_forward_pre_hooks.values():
res = hook(self, (edge_index, size, kwargs)) # 钩子函数调用,修改输入
if res is not None: # 如果钩子函数返回值不为None,更新输入
edge_index, size, kwargs = res
mutable_size = self._check_input(edge_index, size) # 检查并确定输入大小
# 运行“融合”消息和聚合(如果适用)
fuse = False # 初始化是否融合的标志位
if self.fuse and not self.explain: # 如果支持融合且不在解释模式下,解释模式就是用于解释模型的模式
if is_sparse(edge_index): # 如果输入是稀疏张量
fuse = True
elif (not torch.jit.is_scripting()
and isinstance(edge_index, EdgeIndex)): # 如果不是在脚本模式且edge_index是EdgeIndex类型
if (self.SUPPORTS_FUSED_EDGE_INDEX
and edge_index.is_sorted_by_col): # 支持融合且列已排序
fuse = True
if fuse: # 如果支持融合
coll_dict = self._collect(self._fused_user_args, edge_index,
mutable_size, kwargs) # 收集用户输入参数
msg_aggr_kwargs = self.inspector.collect_param_data(
'message_and_aggregate', coll_dict) # 收集用于消息传递和聚合的参数
for hook in self._message_and_aggregate_forward_pre_hooks.values():
res = hook(self, (edge_index, msg_aggr_kwargs)) # 调用前置钩子
if res is not None:
edge_index, msg_aggr_kwargs = res
out = self.message_and_aggregate(edge_index, **msg_aggr_kwargs) # 进行消息传递和聚合操作
for hook in self._message_and_aggregate_forward_hooks.values():
res = hook(self, (edge_index, msg_aggr_kwargs), out) # 调用后置钩子
if res is not None:
out = res
update_kwargs = self.inspector.collect_param_data(
'update', coll_dict) # 收集用于更新节点嵌入的参数
out = self.update(out, **update_kwargs) # 更新节点嵌入
else: # 否则,分别运行消息传递和聚合函数
if decomposed_layers > 1: # 如果有多层分解
user_args = self._user_args
decomp_args = {a[:-2] for a in user_args if a[-2:] == '_j'} # 找到以'_j'结尾的用户参数
decomp_kwargs = {
a: kwargs[a].chunk(decomposed_layers, -1) # 将参数在最后一个维度上分块
for a in decomp_args
}
decomp_out = [] # 存储每层的输出
for i in range(decomposed_layers): # 遍历每个分解层
if decomposed_layers > 1:
for arg in decomp_args:
kwargs[arg] = decomp_kwargs[arg][i] # 使用分解后的参数
coll_dict = self._collect(self._user_args, edge_index,
mutable_size, kwargs) # 收集输入参数
msg_kwargs = self.inspector.collect_param_data(
'message', coll_dict) # 收集消息传递参数
for hook in self._message_forward_pre_hooks.values():
res = hook(self, (msg_kwargs, )) # 调用前置消息钩子
if res is not None:
msg_kwargs = res[0] if isinstance(res, tuple) else res
out = self.message(**msg_kwargs) # 进行消息传递操作
for hook in self._message_forward_hooks.values():
res = hook(self, (msg_kwargs, ), out) # 调用后置消息钩子
if res is not None:
out = res
if self.explain: # 如果在解释模式下
explain_msg_kwargs = self.inspector.collect_param_data(
'explain_message', coll_dict) # 收集解释消息参数
out = self.explain_message(out, **explain_msg_kwargs) # 解释消息
aggr_kwargs = self.inspector.collect_param_data(
'aggregate', coll_dict) # 收集聚合参数
for hook in self._aggregate_forward_pre_hooks.values():
res = hook(self, (aggr_kwargs, )) # 调用前置聚合钩子
if res is not None:
aggr_kwargs = res[0] if isinstance(res, tuple) else res
out = self.aggregate(out, **aggr_kwargs) # 聚合消息
for hook in self._aggregate_forward_hooks.values():
res = hook(self, (aggr_kwargs, ), out) # 调用后置聚合钩子
if res is not None:
out = res
update_kwargs = self.inspector.collect_param_data(
'update', coll_dict) # 收集更新参数
out = self.update(out, **update_kwargs) # 更新节点嵌入
if decomposed_layers > 1: # 如果有多层分解
decomp_out.append(out) # 将当前层的输出添加到分解输出列表中
if decomposed_layers > 1: # 如果有多层分解
out = torch.cat(decomp_out, dim=-1) # 将所有分解层的输出在最后一个维度上拼接
for hook in self._propagate_forward_hooks.values():
res = hook(self, (edge_index, mutable_size, kwargs), out) # 调用后置传播钩子
if res is not None:
out = res
return out # 返回最终的传播输出
代码不支持融合,因此只用看后半else部分,分别进行传递和聚合。
奇怪的是,鱼对代码单步调试,发现其中所有的hook都没有运行到。
6.2.1.2 message函数
此外,对代码进行单步调试 ,发现消息传递函数如下
def message(self, x_j: Tensor, edge_attr: Tensor) -> Tensor: # 消息传递函数
'''
参数:
x_j (Tensor):邻居节点的特征
edge_attr (Tensor):边的特征
返回:
msg (Tensor):消息
'''ni
weight = self.nn(edge_attr) # 使用神经网络对边特征进行变换,得到权重
weight = weight.view(-1, self.in_channels_l, self.out_channels)
msg = torch.matmul(x_j.unsqueeze(1), weight).squeeze(1) # 将邻居节点特征与权重相乘,得到消息
return msg
6.2.1.3 aggregate函数
聚合函数最终是对以下MeanAggregation类的实现,
class MeanAggregation(Aggregation):
r"""An aggregation operator that averages features across a set of
elements.
.. math::
\mathrm{mean}(\mathcal{X}) = \frac{1}{|\mathcal{X}|}
\sum_{\mathbf{x}_i \in \mathcal{X}} \mathbf{x}_i.
"""
def forward(self, x: Tensor, index: Optional[Tensor] = None,
ptr: Optional[Tensor] = None, dim_size: Optional[int] = None,
dim: int = -2) -> Tensor:
return self.reduce(x, index, ptr, dim_size, dim, reduce='mean')
reduce函数调用了scatter函数
def reduce(self, x: Tensor, index: Optional[Tensor] = None,
ptr: Optional[Tensor] = None, dim_size: Optional[int] = None,
dim: int = -2, reduce: str = 'sum') -> Tensor:
'''
参数:
x (Tensor):输入张量
index (Tensor, optional):索引张量
ptr (Tensor, optional):指针张量
dim_size (int, optional):维度大小
dim (int, optional):聚合维度
reduce (str):聚合方式(“sum”,“mean”,“min”,“max”)
'''
if ptr is not None:
if index is None or self._deterministic:
ptr = expand_left(ptr, dim, dims=x.dim())
return segment(x, ptr, reduce=reduce)
if index is None:
raise RuntimeError("Aggregation requires 'index' to be specified")
return scatter(x, index, dim, dim_size, reduce)
scatter函数具体如下:
def scatter(
src: Tensor,
index: Tensor,
dim: int = 0,
dim_size: Optional[int] = None,
reduce: str = 'sum',
) -> Tensor:
r"""Reduces all values from the :obj:`src` tensor at the indices
specified in the :obj:`index` tensor along a given dimension
:obj:`dim`. See the `documentation
<https://pytorch-scatter.readthedocs.io/en/latest/functions/
scatter.html>`__ of the :obj:`torch_scatter` package for more
information.
Args:
src (torch.Tensor): The source tensor.
index (torch.Tensor): The index tensor.
dim (int, optional): The dimension along which to index.
(default: :obj:`0`)
dim_size (int, optional): The size of the output tensor at
dimension :obj:`dim`. If set to :obj:`None`, will create a
minimal-sized output tensor according to
:obj:`index.max() + 1`. (default: :obj:`None`)
reduce (str, optional): The reduce operation (:obj:`"sum"`,
:obj:`"mean"`, :obj:`"mul"`, :obj:`"min"` or :obj:`"max"`,
:obj:`"any"`). (default: :obj:`"sum"`)
"""
if isinstance(index, Tensor) and index.dim() != 1:
raise ValueError(f"The `index` argument must be one-dimensional "
f"(got {index.dim()} dimensions)")
dim = src.dim() + dim if dim < 0 else dim
if isinstance(src, Tensor) and (dim < 0 or dim >= src.dim()):
raise ValueError(f"The `dim` argument must lay between 0 and "
f"{src.dim() - 1} (got {dim})")
if dim_size is None:
dim_size = int(index.max()) + 1 if index.numel() > 0 else 0
# For now, we maintain various different code paths, based on whether
# the input requires gradients and whether it lays on the CPU/GPU.
# For example, `torch_scatter` is usually faster than
# `torch.scatter_reduce` on GPU, while `torch.scatter_reduce` is faster
# on CPU.
# `torch.scatter_reduce` has a faster forward implementation for
# "min"/"max" reductions since it does not compute additional arg
# indices, but is therefore way slower in its backward implementation.
# More insights can be found in `test/utils/test_scatter.py`.
size = src.size()[:dim] + (dim_size, ) + src.size()[dim + 1:]
# For "any" reduction, we use regular `scatter_`:
if reduce == 'any':
index = broadcast(index, src, dim)
return src.new_zeros(size).scatter_(dim, index, src)
# For "sum" and "mean" reduction, we make use of `scatter_add_`:
if reduce == 'sum' or reduce == 'add':
index = broadcast(index, src, dim)
return src.new_zeros(size).scatter_add_(dim, index, src)
if reduce == 'mean':
count = src.new_zeros(dim_size) # 初始化一个全0的tensor,大小为dim_size
count.scatter_add_(0, index, src.new_ones(src.size(dim))) # 将index中的元素作为索引,将src中的元素作为值,将1加到count中
count = count.clamp(min=1) # 将count中的元素限制在1以上
index = broadcast(index, src, dim) # 将index扩展到src的维度
out = src.new_zeros(size).scatter_add_(dim, index, src) # 将src中的元素根据index的值,加到out中
return out / broadcast(count, out, dim) # 将out中的元素除以广播后的count,广播函数把count扩展到out的维度
# For "min" and "max" reduction, we prefer `scatter_reduce_` on CPU or
# in case the input does not require gradients:
if reduce in ['min', 'max', 'amin', 'amax']:
if (not torch_geometric.typing.WITH_TORCH_SCATTER
or is_compiling() or is_in_onnx_export() or not src.is_cuda
or not src.requires_grad):
if (src.is_cuda and src.requires_grad and not is_compiling()
and not is_in_onnx_export()):
warnings.warn(f"The usage of `scatter(reduce='{reduce}')` "
f"can be accelerated via the 'torch-scatter'"
f" package, but it was not found")
index = broadcast(index, src, dim)
if not is_in_onnx_export():
return src.new_zeros(size).scatter_reduce_(
dim, index, src, reduce=f'a{reduce[-3:]}',
include_self=False)
fill = torch.full( # type: ignore
size=(1, ),
fill_value=src.min() if 'max' in reduce else src.max(),
dtype=src.dtype,
device=src.device,
).expand_as(src)
out = src.new_zeros(size).scatter_reduce_(
dim, index, fill, reduce=f'a{reduce[-3:]}',
include_self=True)
return out.scatter_reduce_(dim, index, src,
reduce=f'a{reduce[-3:]}',
include_self=True)
return torch_scatter.scatter(src, index, dim, dim_size=dim_size,
reduce=reduce[-3:])
# For "mul" reduction, we prefer `scatter_reduce_` on CPU:
if reduce == 'mul':
if (not torch_geometric.typing.WITH_TORCH_SCATTER
or is_compiling() or not src.is_cuda):
if src.is_cuda and not is_compiling():
warnings.warn(f"The usage of `scatter(reduce='{reduce}')` "
f"can be accelerated via the 'torch-scatter'"
f" package, but it was not found")
index = broadcast(index, src, dim)
# We initialize with `one` here to match `scatter_mul` output:
return src.new_ones(size).scatter_reduce_(
dim, index, src, reduce='prod', include_self=True)
return torch_scatter.scatter(src, index, dim, dim_size=dim_size,
reduce='mul')
raise ValueError(f"Encountered invalid `reduce` argument '{reduce}'")
以上scatter函数可以不用看,因为关键实现框架mean聚合的代码只有以下部分
if reduce == 'mean':
count = src.new_zeros(dim_size) # 初始化一个全0的tensor,大小为dim_size
count.scatter_add_(0, index, src.new_ones(src.size(dim))) # 将index中的元素作为索引,将src中的元素作为值,将1加到count中
count = count.clamp(min=1) # 将count中的元素限制在1以上
index = broadcast(index, src, dim) # 将index扩展到src的维度
out = src.new_zeros(size).scatter_add_(dim, index, src) # 将src中的元素根据index的值,加到out中
return out / broadcast(count, out, dim) # 将out中的元素除以广播后的count,广播函数把count扩展到out的维度
6.2.2 Set2Set全局池化
class Set2Set(Aggregation): # 定义Set2Set类,继承自Aggregation类,表示一种基于迭代内容的注意力聚合操作
r"""Set2Set聚合操作,基于迭代内容式注意力机制,详见论文
`"Order Matters: Sequence to sequence for Sets" <https://arxiv.org/abs/1511.06391>`_
数学公式:
\mathbf{q}_t &= \mathrm{LSTM}(\mathbf{q}^{*}_{t-1}) # q_t由LSTM生成,输入为上一步的q_star
\alpha_{i,t} &= \mathrm{softmax}(\mathbf{x}_i \cdot \mathbf{q}_t) # 计算注意力权重,基于节点特征和q_t的点积
\mathbf{r}_t &= \sum_{i=1}^N \alpha_{i,t} \mathbf{x}_i # 加权求和节点特征,得到r_t
\mathbf{q}^{*}_t &= \mathbf{q}_t \, \Vert \, \mathbf{r}_t # 将q_t和r_t拼接,得到q_star
Args:
in_channels (int): 输入特征的大小。
processing_steps (int): 迭代次数T。
**kwargs (optional): 额外的参数,传递给torch.nn.LSTM。
"""
def __init__(self, in_channels: int, processing_steps: int, **kwargs):
super().__init__() # 调用父类初始化方法
self.in_channels = in_channels # 保存输入特征的维度
self.out_channels = 2 * in_channels # 输出特征的维度是输入的两倍,用于拼接q_t和r_t
self.processing_steps = processing_steps # 迭代次数T
self.lstm = torch.nn.LSTM(self.out_channels, in_channels, **kwargs) # 定义LSTM,用于更新q_t和r_t
self.reset_parameters() # 初始化LSTM参数
def reset_parameters(self):
self.lstm.reset_parameters() # 重置LSTM层的参数
def forward(self, x: Tensor, index: Optional[Tensor] = None,
ptr: Optional[Tensor] = None, dim_size: Optional[int] = None,
dim: int = -2) -> Tensor:
# 前向传播函数,计算Set2Set聚合操作
self.assert_index_present(index) # 确保索引存在
self.assert_two_dimensional_input(x, dim) # 确保输入x是二维的
# 初始化LSTM的隐藏状态和q_star,分别为零张量
h = (x.new_zeros((self.lstm.num_layers, dim_size, x.size(-1))),
x.new_zeros((self.lstm.num_layers, dim_size, x.size(-1)))) # LSTM的初始隐藏状态
q_star = x.new_zeros(dim_size, self.out_channels) # 初始化q_star为零张量
for _ in range(self.processing_steps): # 迭代指定次数
q, h = self.lstm(q_star.unsqueeze(0), h) # 通过LSTM更新q_t和隐藏状态h
q = q.view(dim_size, self.in_channels) # 重塑q_t的形状
e = (x * q[index]).sum(dim=-1, keepdim=True) # 计算每个节点的注意力得分
a = softmax(e, index, ptr, dim_size, dim) # 对得分应用softmax,得到注意力权重
r = self.reduce(a * x, index, ptr, dim_size, dim, reduce='sum') # 根据注意力权重聚合邻居节点的特征
q_star = torch.cat([q, r], dim=-1) # 将q_t和r_t拼接,得到新的q_star
return q_star # 返回最终的q_star,表示图的全局特征
def __repr__(self) -> str:
# 重写__repr__方法,用于打印Set2Set对象的简洁表示
return (f'{self.__class__.__name__}({self.in_channels}, '
f'{self.out_channels})') # 返回类名和输入输出特征的维度
Set2Set数学公式如下:
q
t
=
L
S
T
M
(
q
t
−
1
∗
)
q
t
由LSTM生成,输入为上一步的
q
t
−
1
∗
q_t = LSTM({q}^{*}_{t-1}) \quad q_t \text{由LSTM生成,输入为上一步的} q^*_{t-1}
qt=LSTM(qt−1∗)qt由LSTM生成,输入为上一步的qt−1∗
α
i
,
t
=
s
o
f
t
m
a
x
(
x
i
⋅
q
t
)
计算注意力权重,基于节点特征和
q
t
的点积
\alpha_{i,t} = \mathrm{softmax}(\mathbf{x}_i \cdot \mathbf{q}_t) \quad \text{计算注意力权重,基于节点特征和} q_t \text{的点积}
αi,t=softmax(xi⋅qt)计算注意力权重,基于节点特征和qt的点积
r
t
=
∑
i
=
1
N
α
i
,
t
x
i
加权求和节点特征,得到
r
t
{r}_t = \sum_{i=1}^N \alpha_{i,t} \mathbf{x}_i \quad \text{加权求和节点特征,得到} r_t
rt=i=1∑Nαi,txi加权求和节点特征,得到rt
q
t
∗
=
q
t
∥
r
t
将
q
t
和
r
t
拼接,得到
q
t
∗
{q}^{*}_t = {q}_t \, \Vert \, {r}_t \quad \text{将} q_t \text{和} r_t \text{拼接,得到} q^*_t
qt∗=qt∥rt将qt和rt拼接,得到qt∗
总结来说,MPNN 提出了一个通用且灵活的框架,用于对图结构数据进行高效的特征学习和预测,尤其在量子化学和材料科学领域具有巨大的应用潜力。

















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









