







由于 FCM 算法中聚类中心 的选取是建立在聚类数目已知的基础上进行的,所以聚类数目和聚类中心的确定是整个聚 类过程的前提和关键,对聚类过程至关重要。故本题采用基于遗传模拟退火的自适应优化 算法,将长春市各区域内的物资投放点自动聚成k 类,个体适应度函数使用 FCM 的目标 函数 b J ,将 FCM 改进为自适应模糊 C-均值聚类算法。
算法流程:

结果展示:
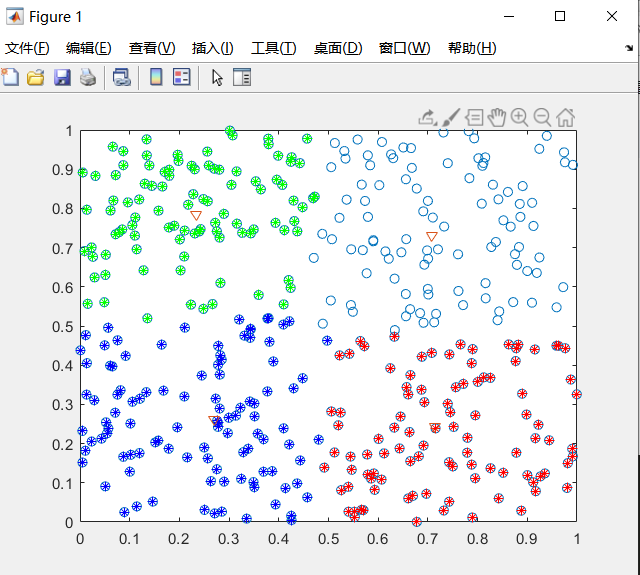

部分代码:
clc
clear all
close all
load X
m=size(X,2);% 样本特征维数
% 中心点范围[lb;ub]
lb=min(X);
ub=max(X);
%% 模糊C均值聚类参数
% 设置幂指数为3,最大迭代次数为20,目标函数的终止容限为1e-6
options=[3,20,1e-6];
% 类别数cn
cn=4;
%% 模拟退火算法参数
q =0.8; % 冷却系数
T0=100; % 初始温度
Tend=99.999; % 终止温度
%% 定义遗传算法参数
sizepop=10; %个体数目(Numbe of individuals)
MAXGEN=100;
[newObjV,center,U]=ObjFun(X,cn,[trace(1:NVAR,end)]',options); %计算最佳初始聚类中心的目标函数值
% 查看聚类结果
Jb=newObjV
U=U{1};
center=center{1};
figure
plot(X(:,1),X(:,2),'o')
hold on
maxU = max(U);
index1 = find(U(1,:) == maxU);
index2 = find(U(2, :) == maxU);
index3 = find(U(3, :) == maxU);
% 在前三类样本数据中分别画上不同记号 不加记号的就是第四类了
line(X(index1,1), X(index1, 2), 'linestyle', 'none','marker', '*', 'color', 'g');
line(X(index2,1), X(index2, 2), 'linestyle', 'none', 'marker', '*', 'color', 'r');
line(X(index3,1), X(index3, 2), 'linestyle', 'none', 'marker', '*', 'color', 'b');
% 画出聚类中心
plot(center(:,1),center(:,2),'v')
hold off
















 1043
1043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









