







简述Redis常用的数据结构及其如何实现的?
Redis支持的常用5种数据类型指的是value类型,分别为:字符串String、列表List、哈希Hash、集合Set、有序集合Zset,但是Redis后续又丰富了几种数据类型分别是Bitmaps、HyperLogLogs、GEO。
由于Redis是基于标准C写的,只有最基础的数据类型,因此Redis为了满足对外使用的5种数据类型,开发了属于自己独有的一套基础数据结构,使用这些数据结构来实现5种数据类型。
Redis底层的数据结构包括:简单动态数组SDS、链表、字典、跳跃链表、整数集合、压缩列表、对象。
Redis为了平衡空间和时间效率,针对value的具体类型在底层会采用不同的数据结构来实现,其中哈希表和压缩列表是复用比较多的数据结构,如下图展示了对外数据类型和底层数据结构之间的映射关系:
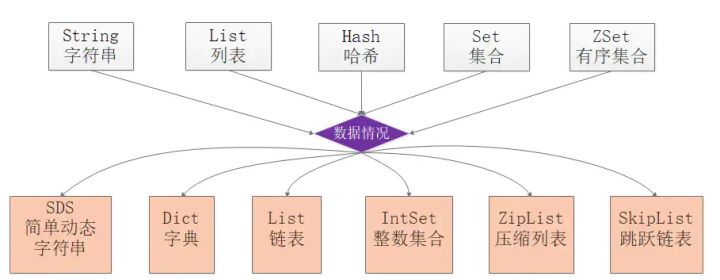
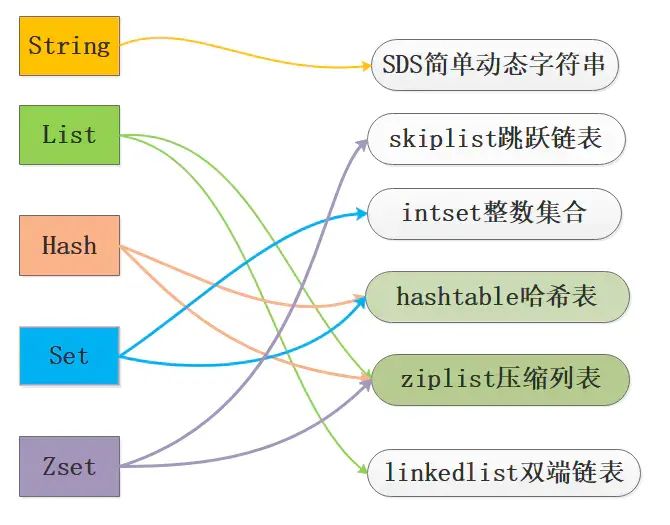
从图中可以看到ziplist压缩列表可以作为Zset、Set、List三种数据类型的底层实现,看来很强大,压缩列表是一种为了节约内存而开发的且经过特殊编码之后的连续内存块顺序型数据结构,底层结构还是比较复杂的。
Redis的SDS和C中字符串相比有什么优势?
在C语言中使用N+1长度的字符数组来表示字符串,尾部使用'\0'作为结尾标志,对于此种实现无法满足Redis对于安全性、效率、丰富的功能的要求,因此Redis单独封装了SDS简单动态字符串结构。
在理解SDS的优势之前需要先看下SDS的实现细节,找了github最新的src/sds.h的定义看下:
typedef char *sds;/*这个用不到 忽略即可*/struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; /* 3 lsb of type, and 5 msb of string length */ char buf[];};/*不同长度的header 8 16 32 64共4种 都给出了四个成员len:当前使用的空间大小;alloc去掉header和结尾空字符的最大空间大小flags:8位的标记 下面关于SDS_TYPE_x的宏定义只有5种 3bit足够了 5bit没有用buf:这个跟C语言中的字符数组是一样的,从typedef char* sds可以知道就是这样的。buf的最大长度是2^n 其中n为sdshdr的类型,如当选择sdshdr16,buf_max=2^16。*/struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; /* used */ uint16_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; /* used */ uint32_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; /* used */ uint64_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};#define SDS_TYPE_5 0#define SDS_TYPE_8 1#define SDS_TYPE_16 2#define SDS_TYPE_32 3#define SDS_TYPE_64 4#define SDS_TYPE_MASK 7#define SDS_TYPE_BITS 3复制代码
看了前面的定义,笔者画了个图:
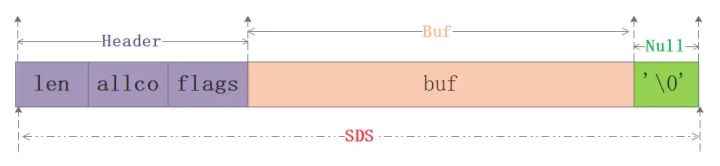
从图中可以知道sds本质分为三部分:header、buf、null结尾符,其中header可以认为是整个sds的指引部分,给定了使用的空间大小、最大分配大小等信息,再用一张网上的图来清晰看下sdshdr8的实例:
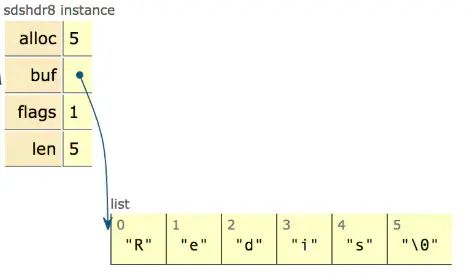
在sds.h/sds.c源码中可清楚地看到sds完整的实现细节,本文就不展开了要不然篇幅就过长了,快速进入主题说下sds的优势:
-
O(1)获取长度: C字符串需要遍历而sds中有len可以直接获得;
-
防止缓冲区溢出bufferoverflow: 当sds需要对字符串进行修改时,首先借助于len和alloc检查空间是否满足修改所需的要求,如果空间不够的话,SDS会自动扩展空间,避免了像C字符串操作中的覆盖情况;
-
有效降低内存分配次数:C字符串在涉及增加或者清除操作时会改变底层数组的大小造成重新分配、sds使用了空间预分配和惰性空间释放机制,说白了就是每次在扩展时是成倍的多分配的,在缩容是也是先留着并不正式归还给OS,这两个机制也是比较好理解的;
-
二进制安全:C语言字符串只能保存ascii码,对于图片、音频等信息无法保存,sds是二进制安全的,写入什么读取就是什么,不做任何过滤和限制;
老规矩上一张黄健宏大神总结好的图:
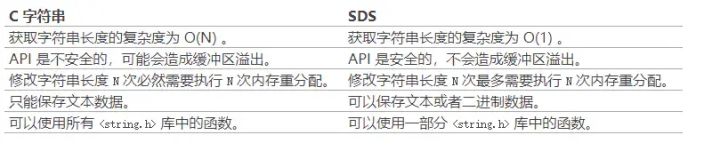
Redis的字典是如何实现的?简述渐进式rehash过程
字典算是Redis中常用数据类型中的明星成员了,前面说过字典可以基于ziplist和hashtable来实现,我们只讨论基于hashtable实现的原理。
字典是个层次非常明显的数据类型,如图:
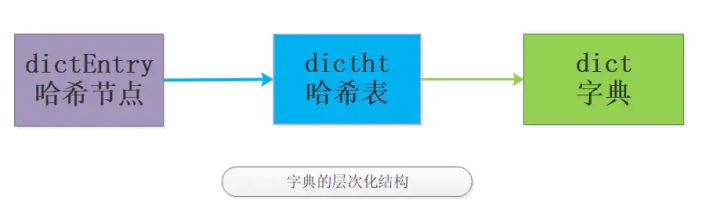
有了个大概的概念,我们看下最新的src/dict.h源码定义:
//哈希节点结构typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next;} dictEntry;//封装的是字典的操作函数指针typedef struct dictType { uint64_t (*hashFunction)(const void *key); void *(*keyDup)(void *privdata, const void *key); void *(*valD
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2422
2422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









