







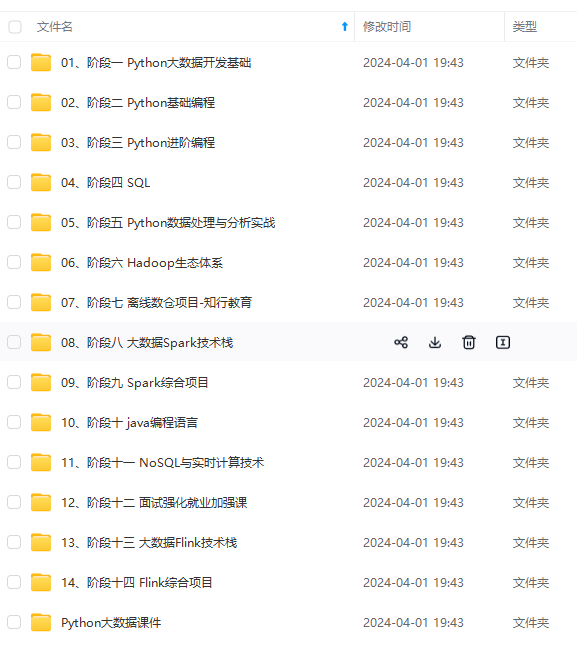
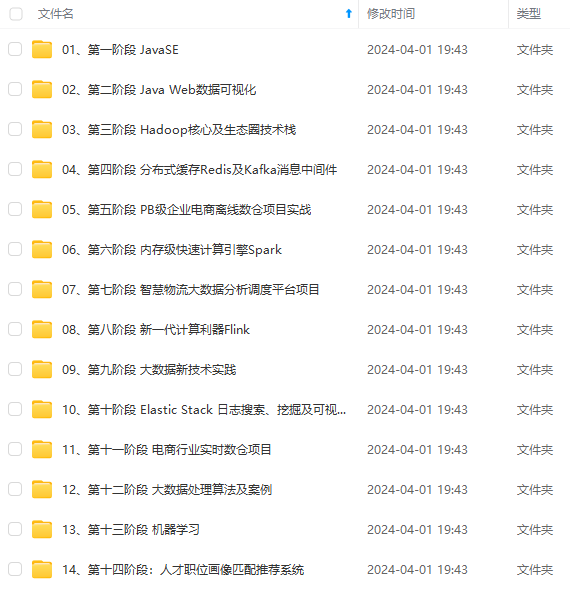
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
以【面试官面试】的形式来分享技术,本期是《Kafka系列》,感兴趣就关注我吧❤️
面试官:知道Kafka高水位吗
当前高水位就是复制偏移量嘛,记录了当前已提交消息的最大偏移量。
是这样的,Kafka的消息只有在所有分区副本都同步该消息后,才算是已提交的消息。
分区副本会根据首领分区副本提供的高水位,来避免未提交的消息被消费。

面试官思考中…
面试官:你说说Kafka是怎么保证消息可靠性的
嗯嗯好的。
在Broker方面,主要使用了分区多副本架构,来保证消息不丢失。
Kafka集群的每一个分区的首领副本,都会有n(复制系数)个broker机器去复制后,生成跟随者副本。
同时如果首领副本的机器挂了,跟随者副本会选举成为新的首领副本。
分区有多个备份是消息保存的一个可靠性保障。
面试官思考中…
面试官:还有吗,比如生产者消费者呢
噢噢还有的,还有在生产者、消费者方面的可靠性。
一、在生产者方面
- 提供了ack = all这种发送确认机制。也就是只有在消息成功写入所有副本后,才算该消息已提交,保证了消息的多备份。
- ack = all失败的话,生产者可以继续重试发送消息。
二、在消费者方面
- 消费者消费时,会根据偏移量进行消费,保证了消息的顺序性。
- 消费后会同步提交、异步提交偏移量,保证了消息不被重复消费。
面试官思考中…
面试官:那要是Kafka消费堆积了怎么办
这样的话,要从Broker和消费者两方面来看。
一、Broker的话
- 每个topic是分为多个分区给不同Broker处理,要合理分配分区数量来提高Broker的消息处理能力。比如3个Broker2个分区,可以改为3个Broker3个分区
- 也可以横向扩展Broker集群
二、消费者的话
- 可以增加消费者服务数量
- 提交偏移量时,可以把同步提交改为异步提交,来减少同步等待Broker的时间

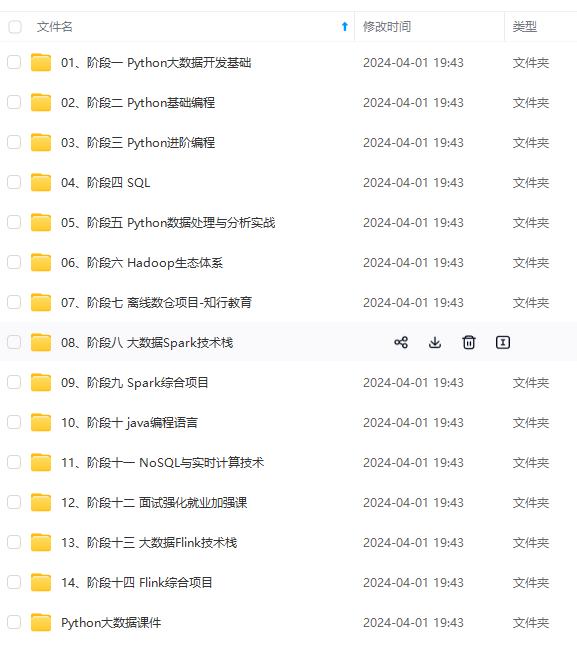
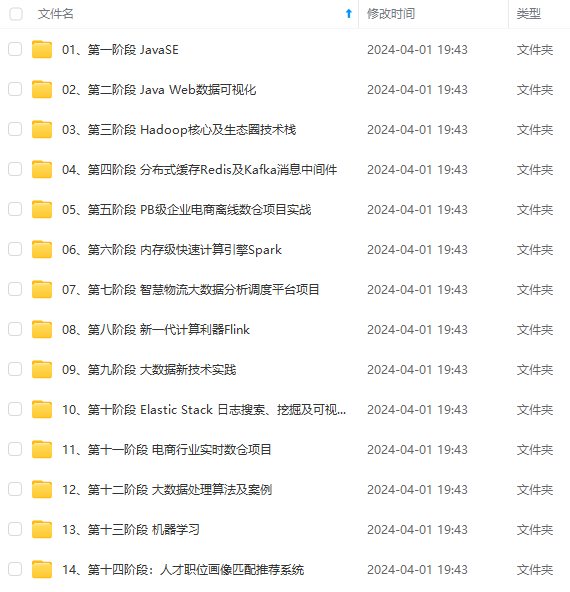
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**















 9215
9215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









