






前言
为什么使用MySQL
- Hive元数据的集中存放地为metastore,而metastore默认使用内嵌的derby数据库作为存储引擎,会默认将Hive元数据存放在Derby数据库中,只能允许一个会话连接,只适合简单的测试。
- 这在实际生产环境中的对于多用户访问存在短板,为了支持多用户会话,则需要一个独立的元数据库--使用Mysql数据库作为外置存储引擎,会完美解决这个问题。
- 应该明白的是,hive只是hadoop的一个插件工具--仓库工具,将结构化的数据进行存储,包括它的数据操作,依赖于mapreduce,它的数据管理,依赖于外部系统--MySQL。
步骤概述
- 首先获得对应版本的MySQL安装包和驱动包(mysql jar包),解压安装MySQL;
- 配置元数据到MySQL,进行相关文件配置,拷贝JDBC驱动包,创建新的元数据库;
- 初始化Hive元数据库,进行hive表创建测试;
- 查看MySQL元数据,外置数据库是否对接成功。
Hive-MySQL部署
详见资源:Xmid流程图。
最终验证:
组内分工:常峥 组内完成度:100%
hive是否安装成功,并测试MySQL是否与hive对接成功
1.1查看hive是否安装成功
 进入hive客户端,进行简单交互即说明hive安装成功
进入hive客户端,进行简单交互即说明hive安装成功


1.2MySQL是否安装成功,Hive-MySQL数据库部署成功
#启动mysql服务
[root@hadoop1 software]# systemctl start mysqld
#登录mysql
mysql -uroot -p“password”
出现mysql命令行界面即成功
- 查看hive3(设置的存储元数据的数据库),初始化后出现:
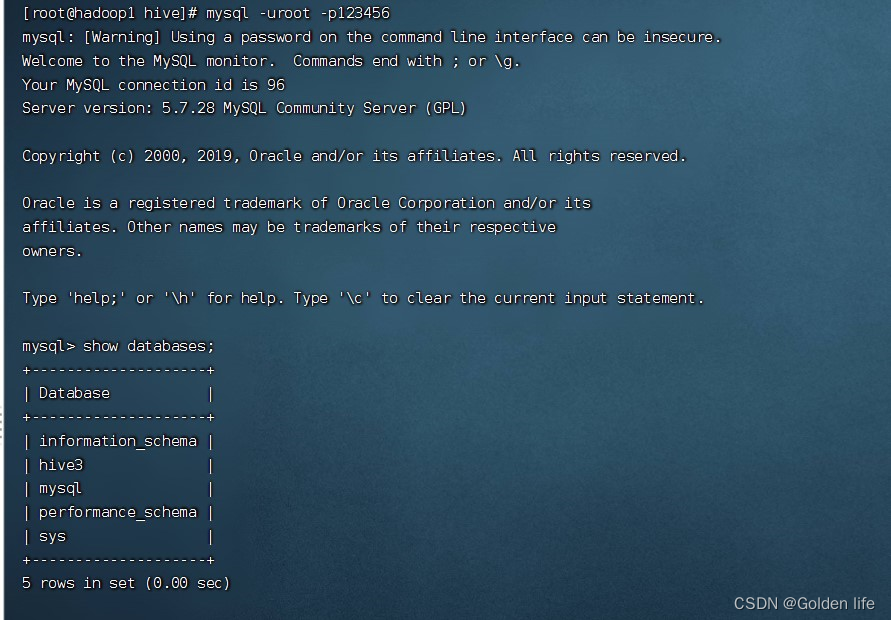
- 查看hive3里的74张元数据表:
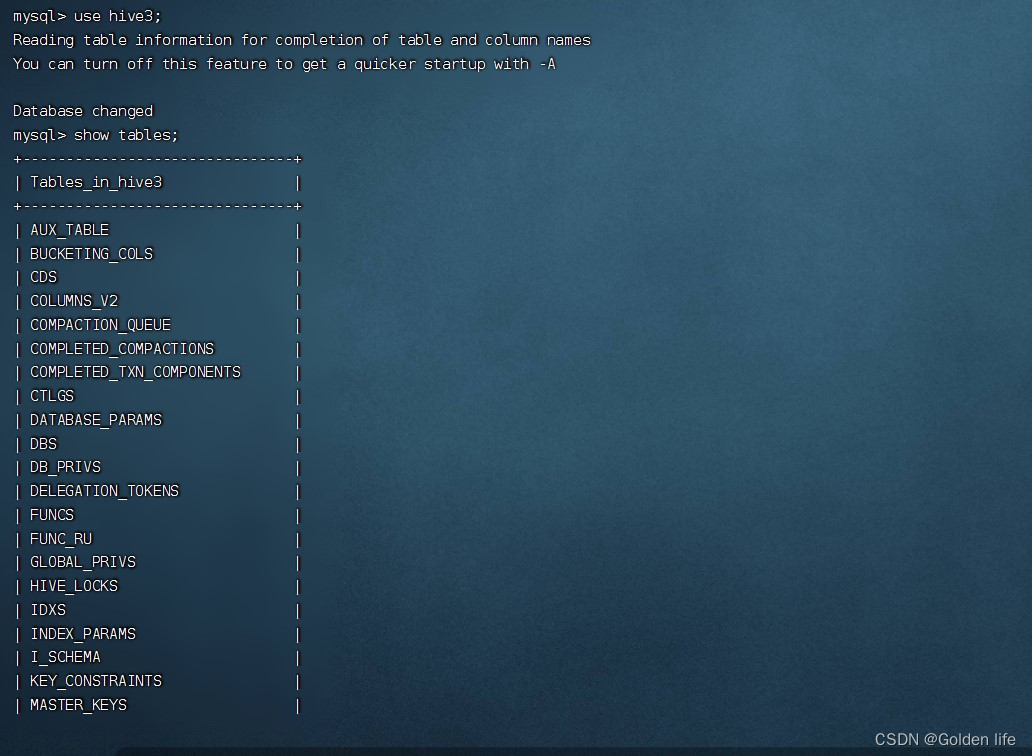
- 查看元数据库中的库、表、列信息:

至此hive元数据已存储于mysql中,可得出hive已成功对接MySQL
hive远程登录部署
组内分工:鲁超 组内完成度:100%
1、在对应配置文件中添加如下配置:
core-site.xml:
#配置hadoop核心配置文件
vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
<!--hiveserver2配置所有节点的用户都可作为代理用户-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!--hiveserver2配置用户能够代理的用户组为任意组-->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!--hiveserver2配置用户能够代理的用户为任意用户-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>hive-site.xml:
"<value>hadoop1</value>"指的是hive初始安装配置机器
#配置hive核心配置文件
vim /opt/module/hive/conf/hive-site.xml
#在文件中添加如下配置
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop1</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>2、分发文件
修改完配置文件后,将hive文件分发至目标机器:hadoop3
#远程拷贝命令scp,跨机器复制文件
#也可以使用之前写好的xsync分发命令
[root@hadoop1 hadoop-3.1.3]# scp -r /opt/module/hive hadoop3:/opt/module
分发成功:

3、测试
-
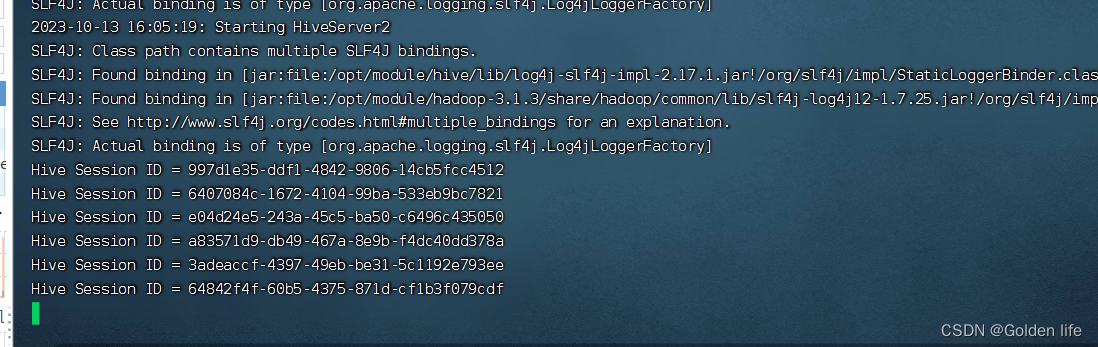
hadoop1启动hivesever2:
bin/hive --service hiveserver2服务会自动挂起:
-
hadoop3使用beeline远程连接hadoop1 hive
hadoop3使用beeline命令行远程登录hive,而beeline是使用JDBC的方式访问HiveServer2的客户端,远程登录的命令行会出现JDBC。
[root@hadoop1 hive]# bin/beeline -u jdbc:hive2://hadoop1:10000 -n root
-
远程连接的报错:hadoop1拒绝连接-连接失败

分析:节点不完整所致。
解决方法:关闭服务,查看节点,确保节点完整。解决后hadoop1重启hiveserver2服务,hadoop3使用beeline命令行远程登录hive,出现客户端页面即代表成功。
Hive-SQL语句实例操作练习
组内分工:邵明月 组内完成度:100%
使用执行sql脚本的方式进行表的创建,数据添加,查询。
一、创建sql脚本文件:
#在hive目录下创建datas目录
mkdir datas
#在datas下创建脚本文件和结果存储文档
touch hive_test1.sql
touch hive_result2.txt

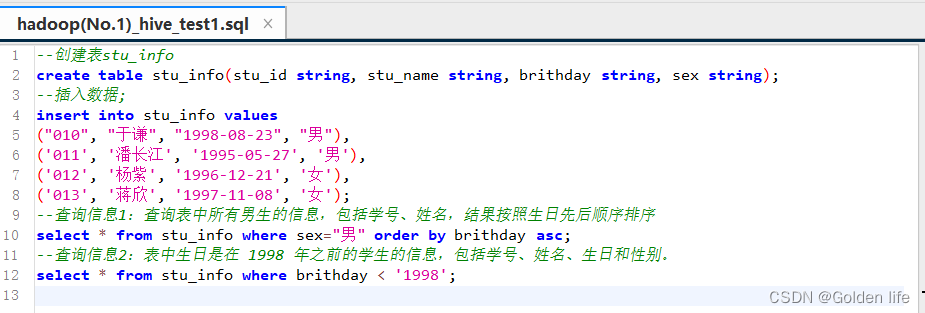
二、写入HQL语句:
三、执行sql脚本文件
并将结果存储在同一目录下的名为“hive_result2.txt”文档中
[root@hadoop1 hive]# bin/hive -f /opt/module/hive/datas/hive_test1.sql > /opt/module/hive/datas/hive_result2.txt
四、HQL语句分析:
组内分工:邵明月 组内完成度:100%
1、创建一个为stu_info的表
此处我分步进行表的存储,数据的插入,查询,多次执行sql脚本文件,以便报错时能查看为哪行错误
sql语句:
create table stu_info (stu_id string, stu_name string, brithday string, sex string);
#()内为表头字段,并设置了它们的数据类型1.1查看hive数据库:创建成功
#进入hive命令行查看已经创建的表
hive>show tables;
2、向stu_info表中插入数据:注意关键字完整及中英文符号
sql语句:插入四条完整信息
insert into stu_info values
('010', '于谦', '1998-08-23', '男'),
('011', '潘长江', '1995-05-27', '男'),
('012', '杨紫', '1996-12-21', '女'),
('013', '蒋欣', '1997-11-08', '女');
执行sql脚本文件,输入数据,显示插入成功:
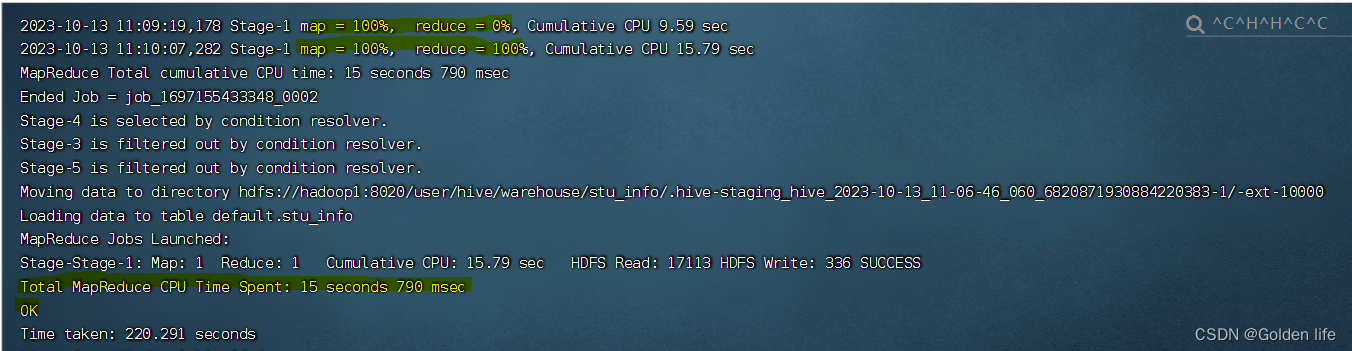
3、进行数据查询:
3.1执行脚本文件,查询表中所有男生的信息,包括学号、姓名,结果按照生日先后顺序排序
sql语句:
select * from stu_info where sex="男" order by brithday asc;
#where 查询条件
#order by 将查询数据进行排序,DESC为倒叙,ASC为升序sql脚本文件运行成功:

查看结果存储文档:
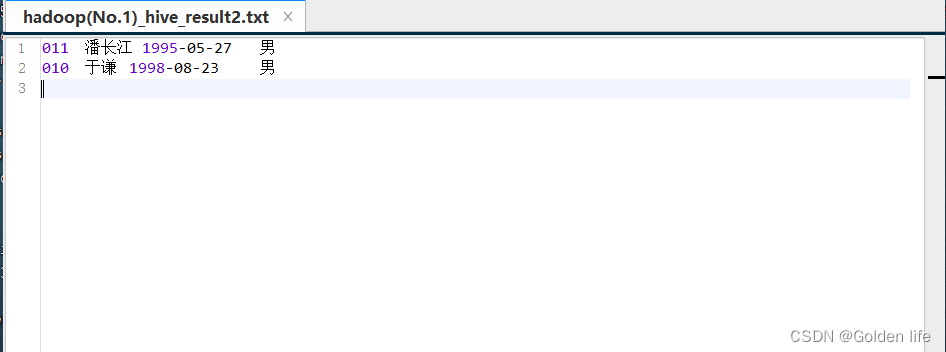
3.2查询表中生日是在 1998 年之前的学生的信息,包括学号、姓名、生日和性别。
sql语句:
select * from stu_info where brithday < '1998';sql脚本运行成功:

查询结果文档:
结果存储文档,查询sql语句运行结果:此文档每次运行一次将会更新覆盖上一次结果

文档贡献者:邵明月
成员:常峥、鲁超















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









