









随着网络技术的发展,数据变得越来越值钱,如何有效提取这些有效且公开的数据并利用这些信息变成了一个巨大的挑战。从而爬虫工程师、数据分析师、大数据工程师的岗位也越来越受欢迎。爬虫是 Python 应用的领域之一。
有 Python 基础对于学习 Python 爬虫具有事半功倍的效果。就像学英语一样,一个对英语一概不通的人听完别人读英语,自己也能读出来,但要把英语读好,学好音标非常有必要。
一、Python 开发环境的搭建
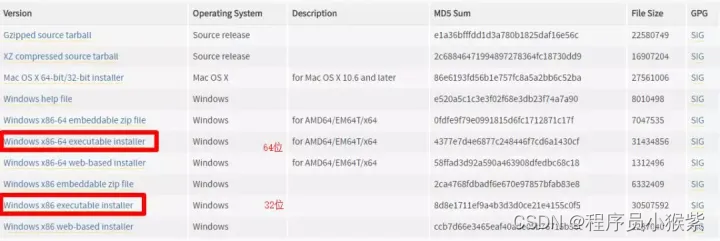
Python 目前流行 Python 2.x 与 Python 3.x 两个版本,由于 Python 2 只会维护到 2020 年,因此这里建议使用 python 3 来作为编程环境。
下载 Python:
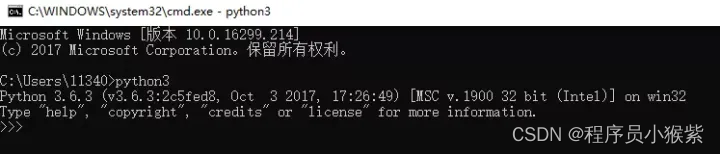
默认安装即可,如下图所示。
二、什么是爬虫?
网络爬虫:是指按照一定的规则,自动抓取万维网信息的程序或者脚本,从中获取大量的信息。
爬虫的作用主要有以下几点:
- 市场分析:电商分析、商圈分析、一二级市场分析等;
- 市场监控:电商、新闻、房源监控、票房预测、股票分析等;
- 商机发现:招投标情报发现、客户资料发掘、企业客户发现等;
- 数据分析:对某个 App 的下载量跟踪、用户分析、评论分析,虚拟货币详情分析……
三、爬虫基础知识补充
1. 网址的构成
网站的网址一般由协议+域名+加页面构成,如 https://auction.jd.com/home.html,域名一般是固定不变的,能改变的则是页面(home.html),所以在爬虫的过程中我们所需要解析的就是自己编写的不同页面的 URL,只有解析出各个不同页面的 URL 入口,我们才能开始爬虫(爬取网页)。
2. 网页的基本构成
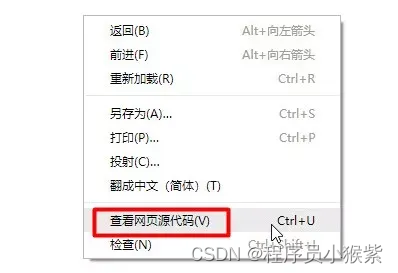
一般来说一个网页的页面主要有 HTML、CSS、JavaScript 构成,这里我们可以打开任意一个网页右击查看网页源代码。
3. 常见的加载模式
学习爬虫有必要了解网页常见的两种加载模式(后续爬虫过程中,经常需要用到)。
- 同步加载:改变网址上的某些参数会导致网页发生改变。如常见的网站翻页后网址会发生变化。
- 异步加载:改变网址上的参数不会使网页发生改变。如常见的网站翻页后网址不会发生变化。
4. 网页的请求过程
打开浏览器,地址栏输 http://baidu.com,按下回车,到用户看到内容,主要经历了如下步骤:
(1)开始进行域名解析
首先浏览器自身搜 DNS 缓存,搜 http://baidu.com 有没有缓存有没有过期,如果过期就结束,其次浏览器会搜索操作系统自身的 DNS 缓存并读取本地的 host 文件,浏览器发起一个 DNS 系统调用。
(2)浏览器获得 http://baidu.com 域名对应的 IP 地址后,发起 HTTP 三次握手
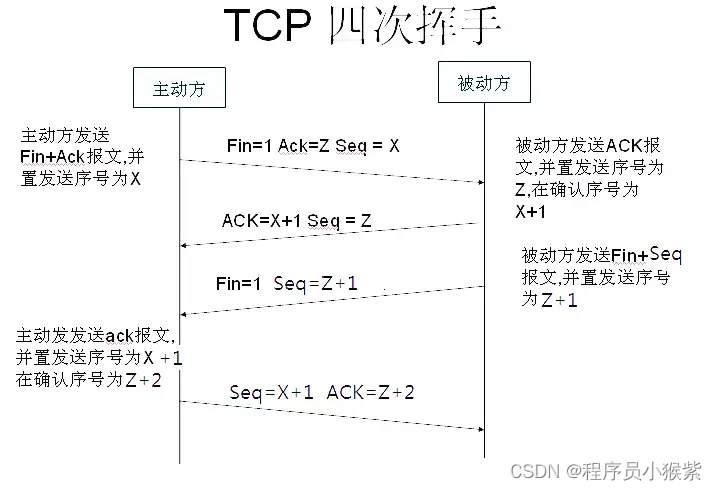
(3)建立 TCP/IP,浏览器就可以向服务器发送 HTTP 请求
TCP/IP 链接建立起来后,浏览器就可以向服务器发送 HTTP 请求。服务器接收到请求之后就会对请求做相应的处理,并将结果返回给浏览器。
(4)浏览器拿到资源之后对页面进行加载、解析、渲染,最后呈现给用户
5.谷歌浏览器之 HTTP 请求分析
打开 Chrome 开发工具(这里我们以打开百度网址为例),如下图:
- Elements(元素面板):使用“元素”面板可以通过自由操纵 DOM 和 CSS 来重演您网站的布局和设计。
- Console(控制台面板):在开发期间,可以使用控制台面板记录诊断信息,或者使用它作为 shell,在页面上与 JavaScript交互。
- Sources(源代码面板):在源代码面板中设置断点来调试 JavaScript ,或者通过
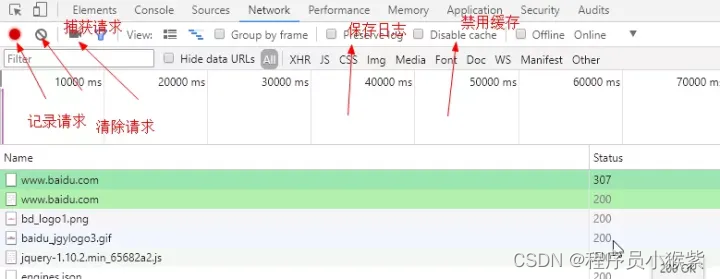
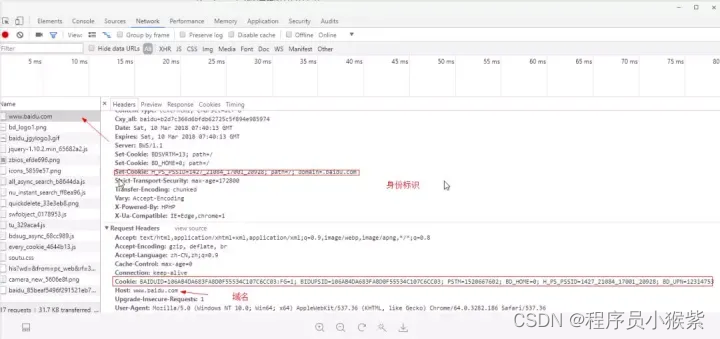
Workspaces(工作区)连接本地文件来使用开发者工具的实时编辑器。 - Network(网络面板):从发起网页页面请求 Request后得到的各个请求资源信息(包括状态、资源类型、大小、所用时间等),并可以根据这个进行网络性能优化。
四、豆瓣短评的数据爬取
Pycharm IDE 的安装:
接下来我们首先需要安装 Python 中常用开发软件 Pycharm IDE,安装只需要默认选择即可。
(1)三方包的安装。
第一种安装库模块的方式为:打开 Pycharm IDE,选择 file-Settings,如下图所示:
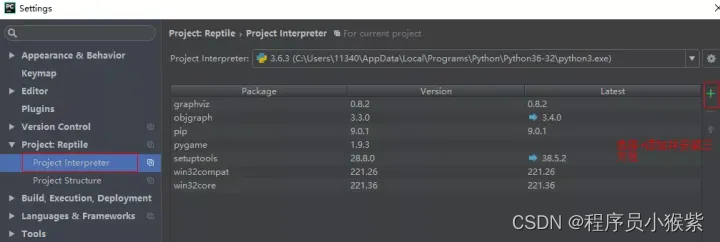
这时我们选择右方的"+"符号,如下图所示:
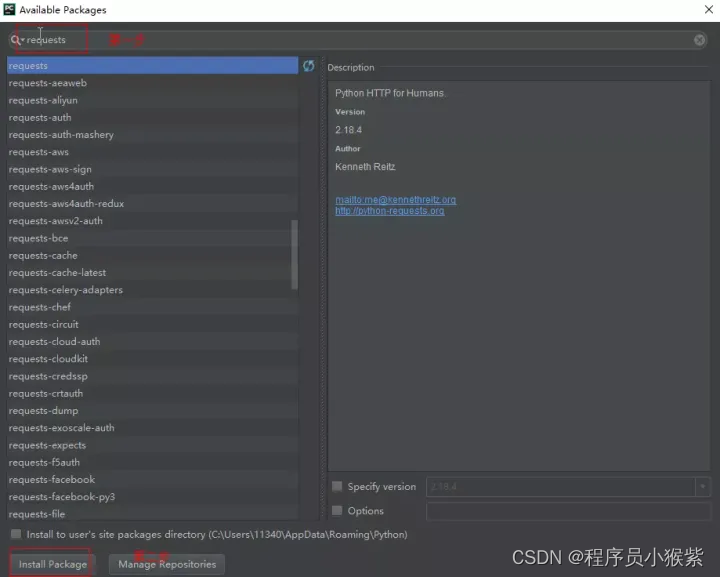
由于接下来需要进行爬取豆瓣短评的数据,所以我们首先需要安装一些三方包和模块。安装 openpyxl、lxml、requests、pandas 等,安装这些库模块的时候,我们只需要在搜索框中搜索对应的库模块就可以,然后选择左下方的 Install Package 即可,等待安装完毕。
第二种安装库模块的方式为:打开 cmd 命令行,输入 pip install requests 命令,出现 Successfully installed,则表明该模块安装成功。
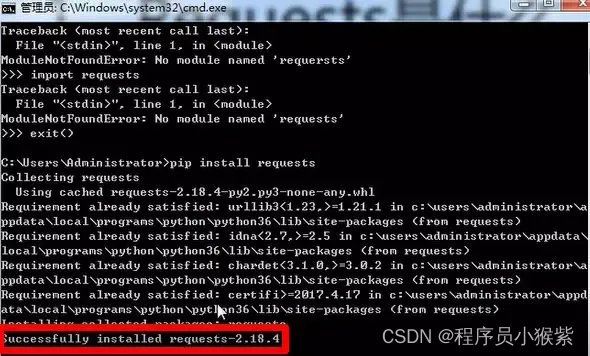
五、代码编写
爬取豆瓣短评需要用的知识点如下:
- 使用 Requests 爬取豆瓣短评;
- 使用 Xpath 解析豆瓣短评;
- 使用 pandas 保存豆瓣短评数据。
(1)Requests 库详解
Requests 是唯一的一个非转基因的 Python HTTP 库,人类可以安全享用,Requests 库是 Python 爬虫中的利器,使得我们爬虫更加方便,快速,它可以节约我们大量的工作,完全满足 HTTP 测试需求,所以我们安装这个库以爬取网页中的数据。
使用 Requests 抓取网页数据的一般步骤如下:
- 导入 Requests 库;
- 输入 URL;
- 使用 Get方法;
- 打印返回文本;
- 抛出异常。
(2)Xpath 解析
XPath 即为 XML 路径语言(XML Path Language),它是一种用来确定 XML 文档中某部分位置的语言,在开发中经常被开发者用来当作小型查询语言,XPath 用于在 XML 文档中通过元素和属性进行导航。
使用 Xpath 解析网页数据的一般步骤为:
- 从 lxml 导入etree。

- 解析数据,返回 XML 结构。

- 使用 .xpath() 寻找和定位数据。
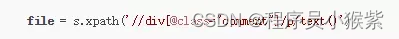
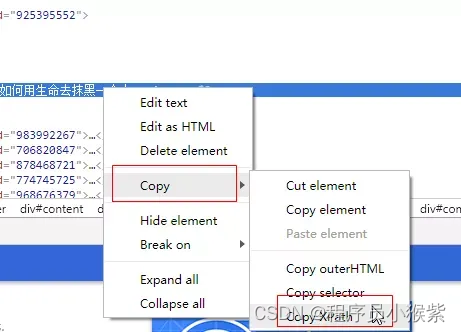
获取 Xpath 的方法直接从浏览器中复制即可:首先在浏览器上定位到需要爬取的数据,右键,点击“检查”,在“Elements”下找到定位到所需数据,右键 —> Copy —> Copy Xpath,即可完成 Xpath 的复制(事例如下图)。
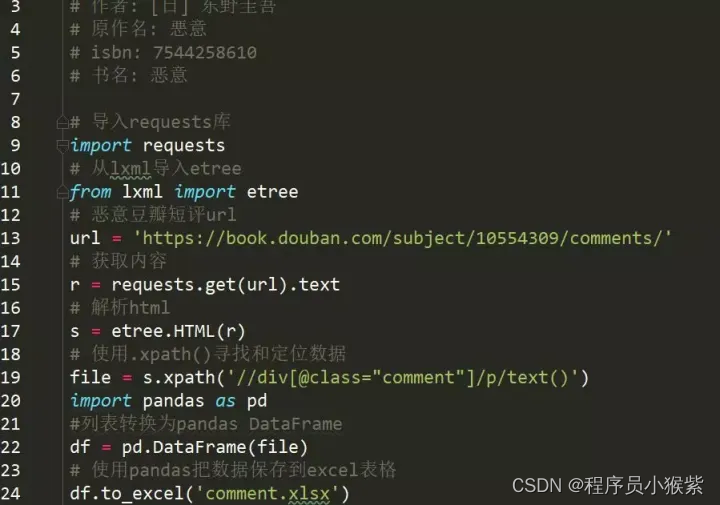
(3)pandas 讲解
pandas 是数据分析工作变得更加简单的高级数据结构和操作工具,主要使用 pandas 保存数据。
导入 pandas 代码如下:

pandas 保存数据到 Excel,其步骤为:导入相关的库;将爬取到的数据储存为 DataFrame 对象;从 Excel 文件中读取数据并保存。
事例代码如下:

通过上述对三方包的安装、Requests、Xpath 解析、pandas 保存数据介绍,接下来我们就正式开始对编写豆瓣短评数据代码编写。
单页豆瓣恶意图书评论数据的爬取代码,如下:

单页数据的爬取 Pycharm IDE 图片截图,如下:
爬取结束之后,已经自动保存为 Excel 表格,分别是 comment.xlsx、comment2.xlsx。
单页抓取效果如下图:

多页抓取效果如下图:
以上关于 Python 爬虫内容就讲到这里,如您有其他观点可在评论区留言交流,有好文也可给小宅投稿分享哦!
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
朋友们如果需要这份完整的资料可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

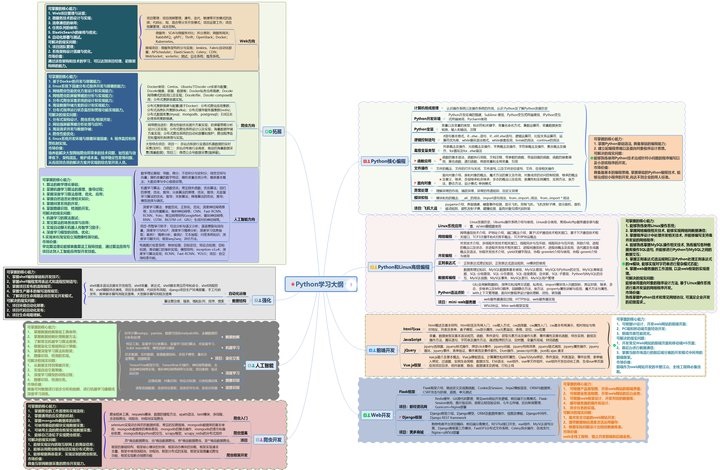
一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具

三、入门学习视频
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、python副业兼职与全职路线
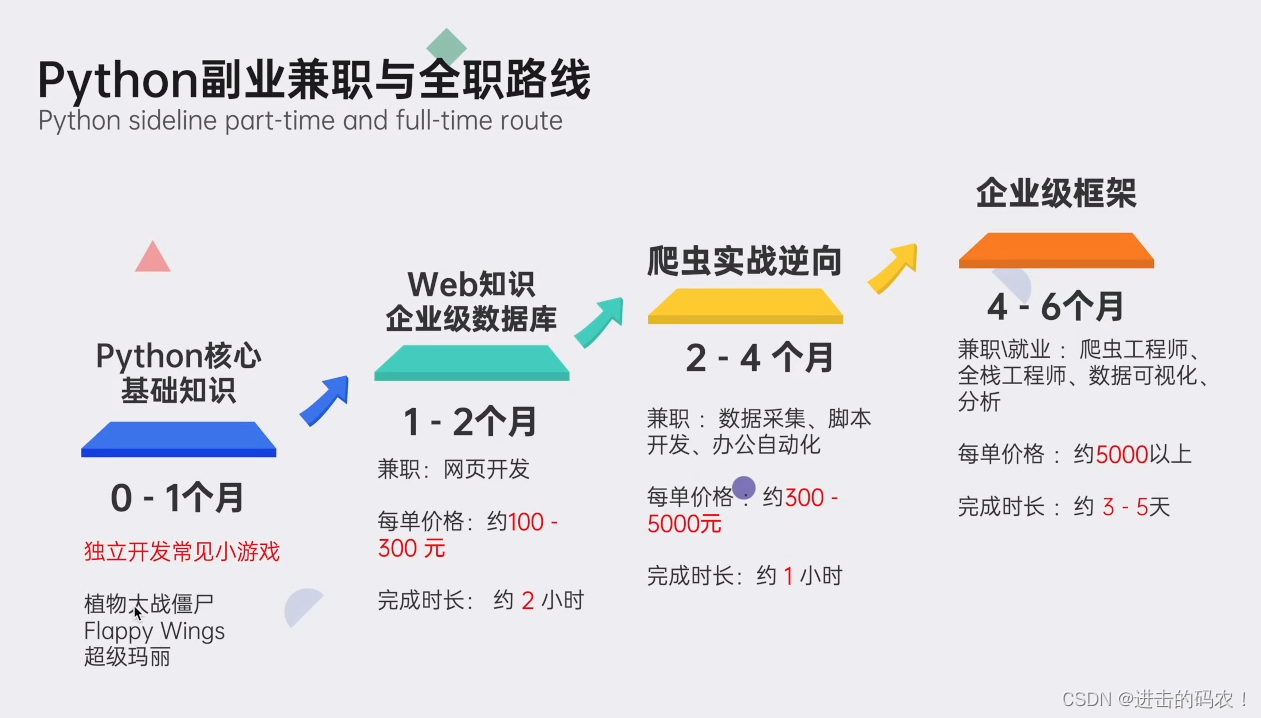

👉[[CSDN大礼包:《python兼职资源&全套学习资料》免费分享]](安全链接,放心点击)















 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









