









作为数据运营人员,在工作中处理数据,分析数据和运用数据,基本是常态。虽非数据分析岗位,但是也是一个要重度应用数据的岗位,如果自身没有获取数据的能力,其实是非常尴尬的。
一般对数据的获取,来自两个方面:内部数据和外部数据。
内部数据,无非就是在自己公司的数据库或数据统计平台中根据分析的需要取数。如果是要从数据统计平台中提取数据,一般的数据统计平台,都会支持数据导出,只需要导出需要的数据即可。如果是要从公司数据库中提取数据,则要求我们会用sql语言取数。
运用sql从公司数据库取数,主要就是学习数据库的“查”的基本操作,包括提取特定情况下的数据,数据的分组聚合和多表的联系,相对来说较为简单。
当然,对于产品或运营人员,我们有时也未见得有读取数据的权限,但是有句话说的好,有备无患。你掌握了一项技能,不能用到要好过你要用的时候,却不会。
外部数据的获取,主要有两种方式:
第一种就是获取外部公开的数据集,比如一些科研机构、企业、政府会开放一些数据,你需要到特定的网站去下载这些数据。这些数据集通常比较完善、质量相对较高(如中国统计信息网)。
第二种就是利用爬虫从网络中爬取,比如从招聘网站获取某个职位的招聘信息,租房网站获取某一地区的租房信息,电商网站获取某个商品的品论信息等等,基于这些爬取的数据,我们可以做数据分析。
我们要聊的是第二种外部获取数据的方式:利用python爬虫获取外部数据。
所以默认本文读者具备了python语法基本知识以及爬虫基本知识(如果没有这方面的知识,也不妨碍对文章的理解,同时笔者会在文章末尾附上曾在学习时遇见的很好的python基础学习以及爬虫基本知识学习的博客)。
我们就以最贴近生活的例子——求职者找工作为例子,聊聊如何利用爬虫来在招聘网站中快速获取想要的数据,然后据此分析,辅助决策。
我们先不着急撸管,哦,错了,是撸代码,先来捋一捋思路:
1,作为求职者,找一份工作,至少要了解下以下这些信息:岗位的市场行情,如薪资范围:工作1~3年,薪资如何?应届生,薪资如何?招聘公司的规模如何?公司的办公地址,距离居住地的路程是近是远?学历要求是怎样的?总体的市场行情如何。。。。。。
2,这些数据获取的方式,一般说来,要么是直接从第三方平台获得,要么就是利用爬虫技术爬取数据。显然 这些招聘信息已经放在招聘网上了,那就不用想了,最好的批量获取数据的方式就是,写个爬虫脚本,把关于求职工作岗位的一些数据爬取下来,然后保存在excel电子表格中,留待下一步分析。
ok,思路捋顺后,我们开干,这里,以拉钩网上的“产品运营”岗位做示例。
使用环境:win10+python3+Juypter Notebook
第一步:分析网页
要爬取一个网页,肯定首先分析一下网页结构。
现在很多网站都用了一种叫做Ajax(异步加载)的技术,就是说,网页打开了,先给你看上面一部分东西,然后剩下的东西再慢慢加载。 所以你可以看到很多网页,都是慢慢的刷出来的,或者有些网站随着你的移动,很多信息才慢慢加载出来。这样的网页有个好处,就是网页加载速度特别快(因为不用一次加载全部内容)。
但这个技术是不利于爬虫的爬取的,所以这个时候,我们就要费点功夫了。
很幸运的是,拉钩采用了这种技术。异步加载的信息,我们需要借助chrome浏览器的小工具进行分析,按F12即可打开,点击Nerwork进入网络分析界面,界面如下:
这时候是一片空白,我们按F5刷新一下刷新一下,就可以看到一系列的网络请求了。
然后我们就开始找可疑的网页资源。首先,图片,css什么之类的可以跳过,一般来说,关注点放在xhr这种类型请求上,如下:
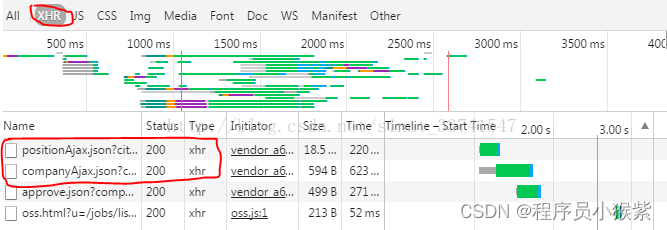
这类数据一般都会用json格式,我们也可以尝试在过滤器中输入json,来筛选寻找。
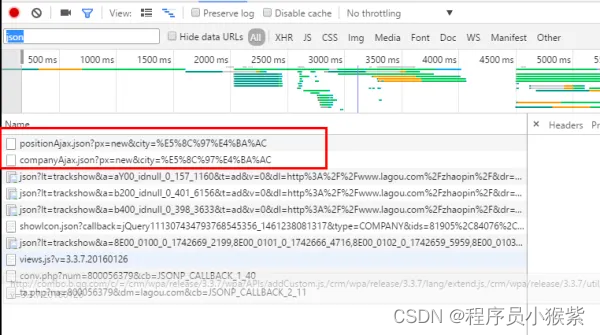
上图发现了两个xhr请求,从字面意思看很有可能是我们需要的信息,右键点击,在另一个界面打开:

what is this?Are you kidding me?嗯,这里是个坑,同样在写爬虫代码时候,如果在http请求中,不加入请求头信息,服务器返回信息也是这样的,但是笔者不明白的是,为什么,在这里笔者直接用浏览器新开窗口,也是这个拒绝访问的界面。如果有大神知道,希望给解解惑,拜谢!
回到正题,虽然新开窗口,无法访问,但条条大陆通罗马,我们可以在右边的框中,切换到“Preview”,然后点content——positionResult查看,能看到是关于职位的信息,以键值对的格式呈现,这就是json格式,特别适合网页数据交换。
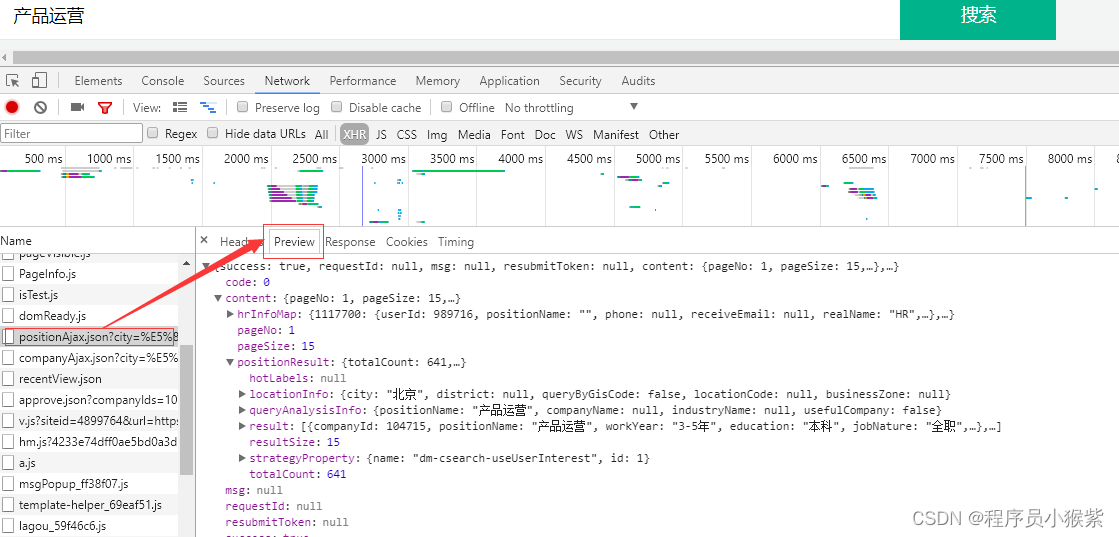
第一步网页分析,至此结束,下一步,我们来构造请求网址。
第二步,网址构造
在“Headers”中,看到网页地址,通过观察网页地址可以发现推测出: http://www.lagou.com/jobs/positionAjax.json?这一段是固定的,剩下的我们发现有个city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0
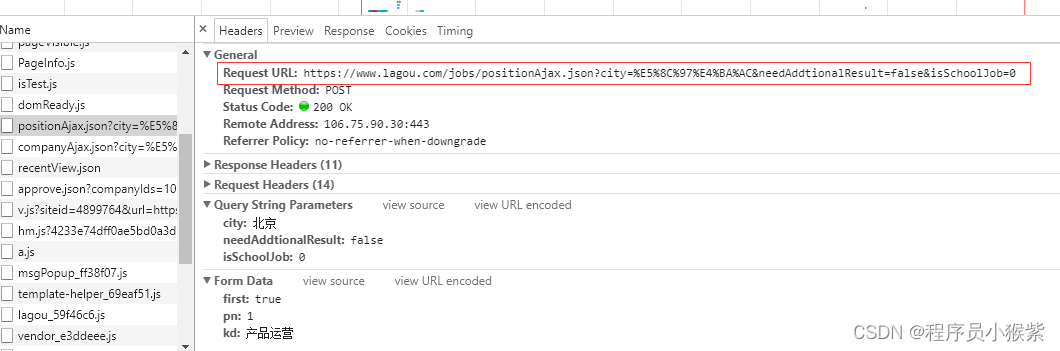
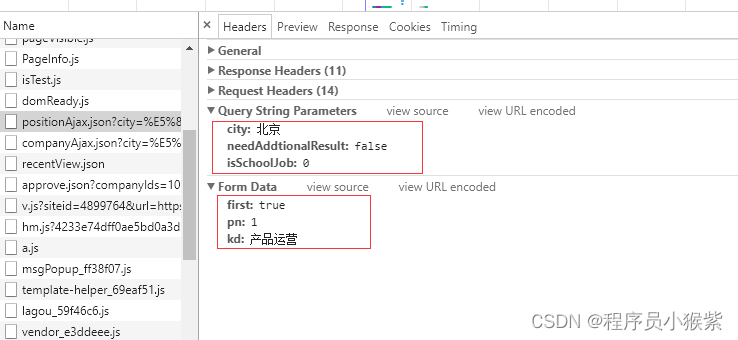
再查看请求发送参数列表,到这里我们可以肯定city参数便是城市,pn参数便是页数,kd参数便是职位关键字。
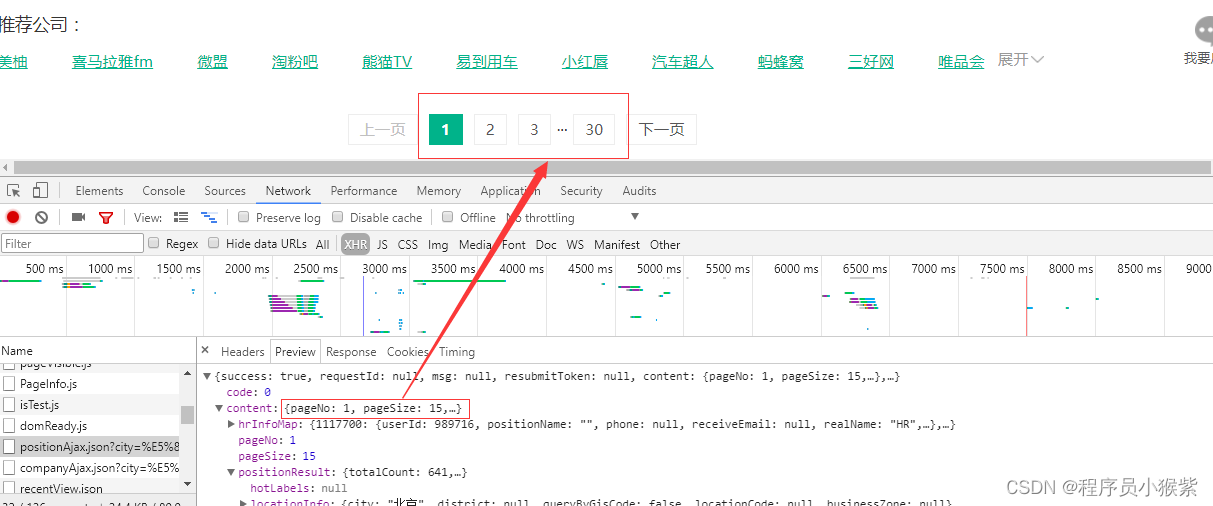
当然这只是一个网页的内容,对于更多页面的内容,怎么获取呢?再来看看关于“产品运营”职位,一共有30页,每页有15个数据,所以我们只需要构造循环,遍历每一页的数据。
第三步,编写爬虫脚本写代码
需要说明的是因为这个网页的格式是用的json,那么我们可以用json格式很好的读出内容。 这里我们切换成到preview下,然后点content——positionResult——result,可以发现出先一个列表,再点开就可以看到每个职位的内容。为什么要从这里看?有个好处就是知道这个json文件的层级结构,方便等下编码。
具体代码展示:
import requests,json
from openpyxl import Workbook
#http请求头信息
headers={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Content-Length':'25',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'user_trace_token=20170214020222-9151732d-f216-11e6-acb5-525400f775ce; LGUID=20170214020222-91517b06-f216-11e6-acb5-525400f775ce; JSESSIONID=ABAAABAAAGFABEF53B117A40684BFB6190FCDFF136B2AE8; _putrc=ECA3D429446342E9; login=true; unick=yz; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; TG-TRACK-CODE=index_navigation; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1494688520,1494690499,1496044502,1496048593; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1496061497; _gid=GA1.2.2090691601.1496061497; _gat=1; _ga=GA1.2.1759377285.1487008943; LGSID=20170529203716-8c254049-446b-11e7-947e-5254005c3644; LGRID=20170529203828-b6fc4c8e-446b-11e7-ba7f-525400f775ce; SEARCH_ID=13c3482b5ddc4bb7bfda721bbe6d71c7; index_location_city=%E6%9D%AD%E5%B7%9E',
'Host':'www.lagou.com',
'Origin':'https://www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_Python?',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'
}
def get_json(url, page, lang_name):
data = {'first': "true", 'pn': page, 'kd': lang_name,'city':"北京"}
#POST请求
json = requests.post(url,data,headers=headers).json()
list_con = json['content']['positionResult']['result']
info_list = []
for i in list_con:
info = []
info.append(i['companyId'])
info.append(i['companyFullName'])
info.append(i['companyShortName'])
info.append(i['companySize'])
info.append(str(i['companyLabelList']))
info.append(i['industryField'])
info.append(i['financeStage'])
info.append(i['positionId'])
info.append(i['positionName'])
info.append(i['positionAdvantage'])
# info.append(i['positionLables'])
info.append(i['city'])
info.append(i['district'])
# info.append(i['businessZones'])
info.append(i['salary'])
info.append(i['education'])
info.append(i['workYear'])
info_list.append(info)
return info_list
def main():
lang_name = input('职位名:')
page = 1
url = 'http://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
info_result=[]
title = ['公司ID','公司全名','公司简称','公司规模','公司标签','行业领域','融资情况',"职位编号", "职位名称","职位优势","城市","区域","薪资水平",'教育程度', "工作经验"]
info_result.append(title)
#遍历网址
while page < 31:
info = get_json(url, page, lang_name)
info_result = info_result + info
page += 1
#写入excel文件
wb = Workbook()
ws1 = wb.active
ws1.title = lang_name
for row in info_result:
ws1.append(row)
wb.save('职位信息3.xlsx')
main()
打开excel文件,查看数据是否存取成功:

我们看到,关于“产品运营”岗位的数据,被成功的保存在excel表格中。下一步就是,据此爬取的数据,做数据处理。关于数据分析中的第三个步骤:数据处理的问题,我们下回再聊。
爬虫是获取外部数据的一个很方便的工具,关于爬虫的知识,远不止于此,这里只是一个简单的示例。作为产品运营人员,虽然需要与数据打交道,但是写爬虫也未必是必须要掌握的技能。然而点亮这个技能树,我个人觉得肯定不会是坏事情。而且作为产品运营,难免会经常和技术同事打交道,如果我们在沟通时,能让双方站在对等的语言交流环境里,也会方便信息的沟通和理解。而让双方站在对等的语言交流环境里,最好的方法,就是熟悉对方的语言环境,这也是自己接触学习python主要原因之一。
技术距离普通人很远吗?或许以前是,但是现在这个时代,如果稍微以超前一点的视角来看待,也许不用几年,具备一点编程能力就不再是一个人的可选项技能,而是成为不得不掌握的基础办公技能,就跟现在,作为职场人你必须得掌握office办公软件一样。这个世界是动态的,用静态的眼光看世界看自己,只会越来越傻。和时代共振,我们才会找到又焦虑又舒服的频率。
最后
在学习python中有任何困难不懂的可以微信扫描下方CSDN官方认证二维码加入python交流学习
多多交流问题,互帮互助,这里有不错的学习教程和开发工具。
👉[[CSDN大礼包:《python安装包&全套学习资料》免费分享]](安全链接,放心点击)

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、Python练习题
检查学习结果。

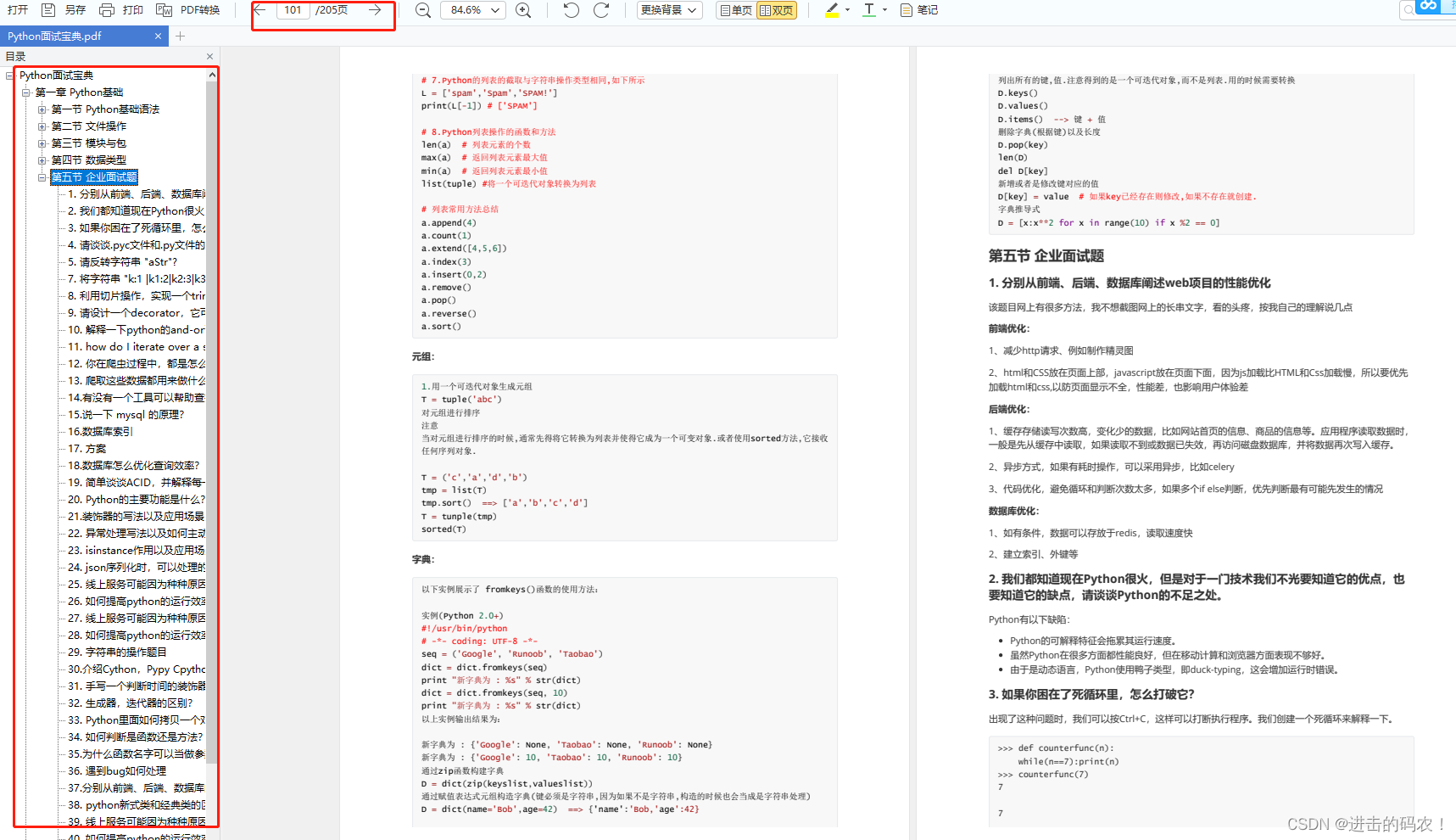
六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。














 1782
1782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









