







要别的图片:



要识别这些图片就必须解决图片的噪点、文本方向不一、图片尺寸过大这些问题。
代码:
import pyzbar.pyzbar as pyzbar
import easyocr,threading
import cv2,csv,os
#展示图片
def show(img):
cv2.imshow("",img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 将信息写入csv文件
def write(list):
with open("decodes.csv","a",newline="") as f:
headers=[
"文本内容",
"二维码内容"
]
writer=csv.writer(f)
#表头只写入一次
if os.path.getsize("decodes.csv")==0:
writer.writerow(headers)
writer.writerows(list)
# 将ocr的识别结果与二维码识别结果对应起来
def sort(decodes,txt):
list=[]
for i in txt:
for j in decodes:
decode=j[0].decode()
if i in decode:
list.append([i,decode])
return list
def main(src):
#使用easyocr提取图片内的文本
def ocr(img, list=[]):
reader = easyocr.Reader(["en"], gpu=True)
txt = reader.readtext(img)
# 简单显示一下进度
print("######",end="")
for i in txt:
res = i[1]
# 判断文本内容是否符合格式
if res[0] in "RYB" and res[1] in "123":
list.append(res)
# 将识别到的文本涂黑
img = cv2.rectangle(img, i[0][0], i[0][2], (0, 0, 0), -1)
# 判断文本数量是否符合预期,如果不,则旋转图片再次进行扫描
if len(list) < 3:
img = cv2.rotate(img, cv2.ROTATE_90_CLOCKWISE)
list = ocr(img, list)
return list
# 使用pyzbar提取图片中二维码的内容
def decode(img, decodes=[]):
decodes += pyzbar.decode(img)
# 如果识别到的二维码数量少于三,那再对图片进行预处理后继续识别
if len(decodes) < 3:
img2 = img.copy()
#将已经识别到的二维码涂黑,防止重复扫描
for i in decodes:
(x, y, h, w) = i.rect
img2 = cv2.rectangle(img2, (x, y), (x + h, y + w), (0, 0, 0), -1)
a, img2 = cv2.threshold(img2, 127, 255, 0)
decodes = decode(img2, decodes)
return decodes
#因为图片带有噪点,所以先对图片进行滤波处理
img=cv2.medianBlur(cv2.imread(src,0),3)
decodes=decode(img)
#缩小图片,减少gpu的计算量
img = cv2.resize(img, (0, 0), fx=0.3, fy=0.3)
txt = ocr(img)
list=sort(decodes,txt)
write(list)
#获取文件夹下的所有文件名字
def dir(src):
list=os.listdir(src)
return list
#程序入口
if __name__ == '__main__':
list = dir("1")
li=[]
# 使用多线程提高速度
for i in list:
t1 = threading.Thread(target=main, args=(f"1//{i}",))
t1.start()
li.append(t1)
for i in li :
i.join()
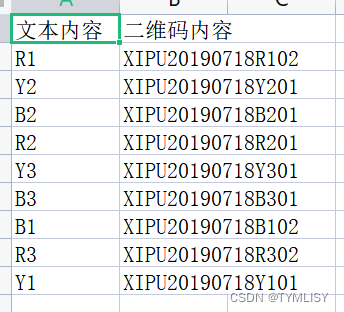
print(f"\n已完成,结果保存在decodes.csv中")识别结果:


















 1946
1946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











