






使用千问大模型+英特尔G8i实例部署智能组卷应用
1. 项目背景介绍
一、项目背景
随着教育信息化的不断推进和人工智能技术的飞速发展,教育领域对于智能化教学工具的需求日益增长。在这样的背景下,本项目旨在利用阿里云平台的英特尔 G8i 实例部署千问大模型,为教育工作者提供高效、便捷的试题生成与组卷服务,以提升教学质量和效率。
二、技术趋势与市场需求
- 人工智能在教育领域的应用逐渐广泛,大语言模型能够理解和处理自然语言,为教育资源的自动化生成提供了强大的技术支持。
- 教师在教学过程中需要花费大量时间和精力进行试题编写和组卷工作。自动生成试题并组卷的工具可以大大减轻教师的工作负担,提高教学效率。
- 阿里云平台作为国内领先的云计算服务提供商,拥有强大的计算资源和稳定的服务保障。英特尔 G8i 实例具有高性能的计算能力和良好的兼容性,能够为大模型的部署和运行提供有力支持。
三、项目目标
- 在阿里云平台的英特尔 G8i 实例上成功部署千问大模型。
- 开发基于大模型 API 的教育领域应用,实现根据教师输入的知识点和考点内容自动生成试题并组卷。
- 提供友好的用户界面,方便教师使用和操作。
- 确保生成的试题质量和组卷的合理性,满足教育教学的需求。
2. 使用到的硬件及大模型介绍
- 通义千问-7B(Qwen-7B-Chat)
通义千问-7B(Qwen-7B)是阿里云研发的通义千问大模型系列的70亿参数规模模型。Qwen-7B是基于Transformer的大语言模型,在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-7B 的基础上,使用对齐机制打造了基于大语言模型的AI助手Qwen-7B-Chat。
- 阿里云第八代Intel G8i CPU实例
阿里云八代实例G8i采用Intel® Xeon® Emerald Rapids或者Intel® Xeon® Sapphire Rapids,该实例支持使用新的AMX(Advanced Matrix Extensions)指令来加速AI任务。相比于上一代实例,八代实例在Intel® AMX的加持下,推理和训练性能大幅提升。
3. 模型部署
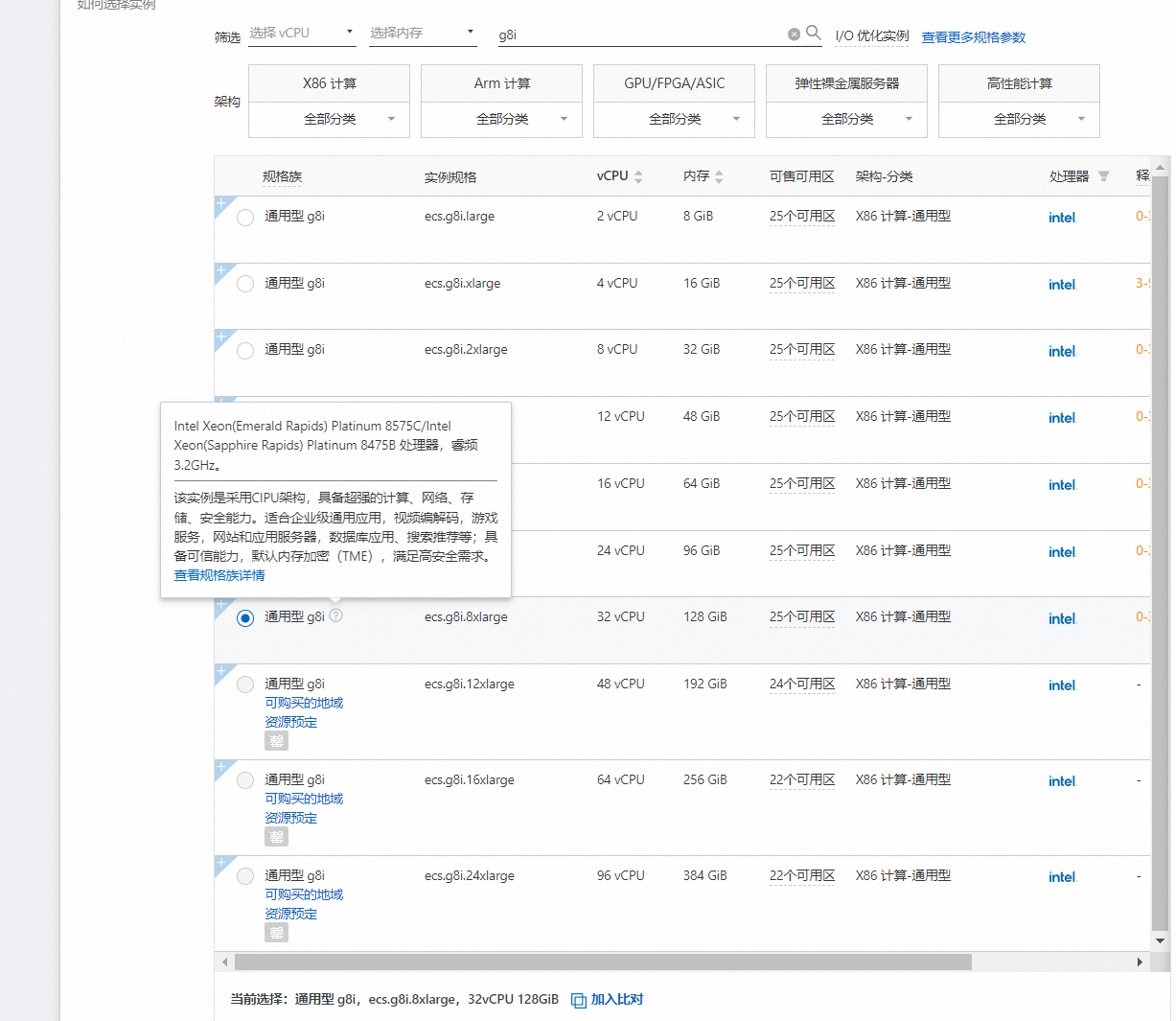
- 购买云服务器实例
实例规格如下
| 通用型 g8i | ecs.g8i.8xlarge | 32 vCPU | 128 GiB |
|---|
该实例是采用CIPU架构,具备超强的计算、网络、存储、安全能力。适合企业级通用应用,视频编解码,游戏服务,网站和应用服务器,数据库应用、搜索推荐等;具备可信能力,默认内存加密(TME),满足高安全需求。
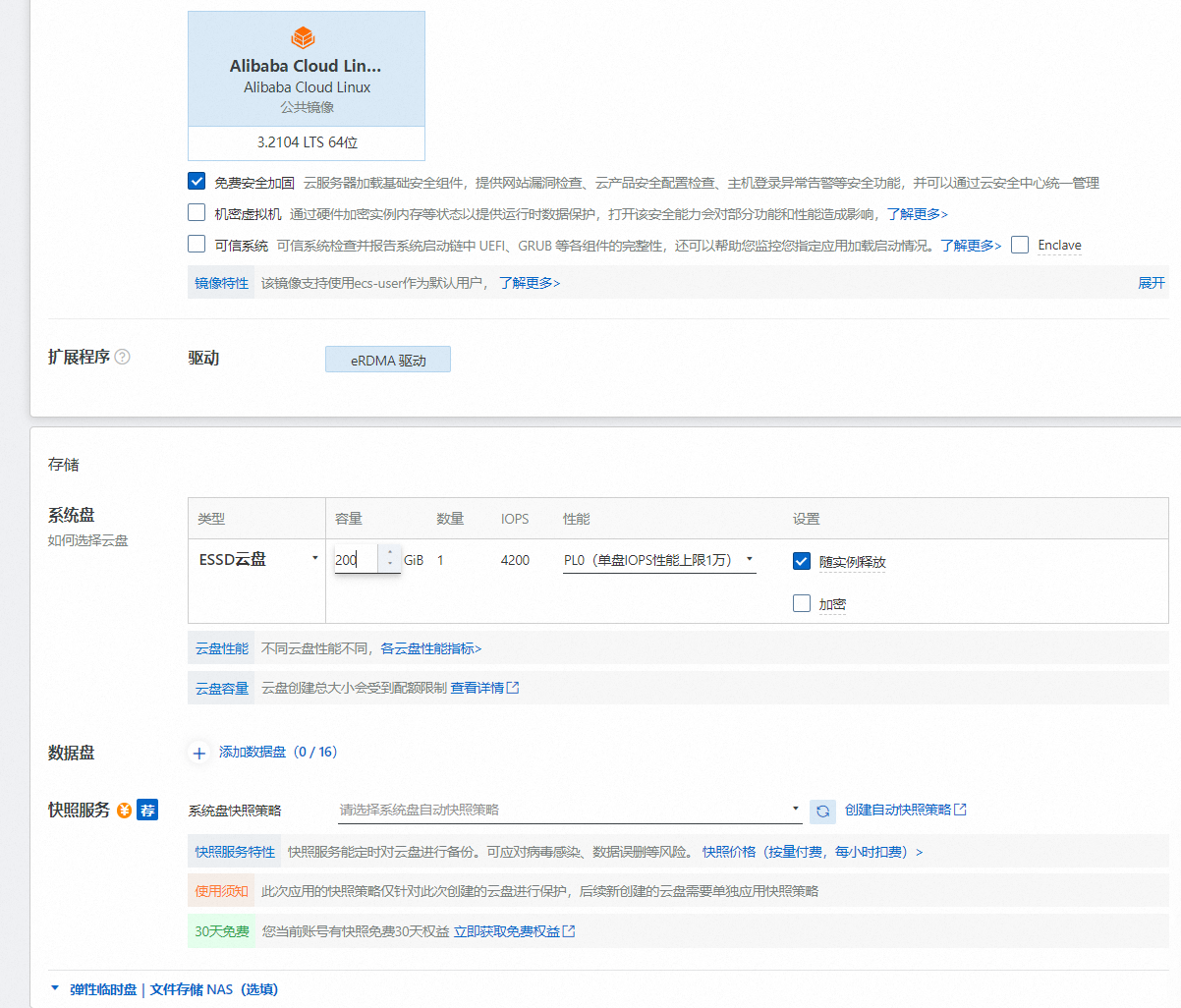
操作系统选择AilibabaCloud linux 存储选择 200GESSD云盘
公网带宽选择按流量计费
创建实例并登录
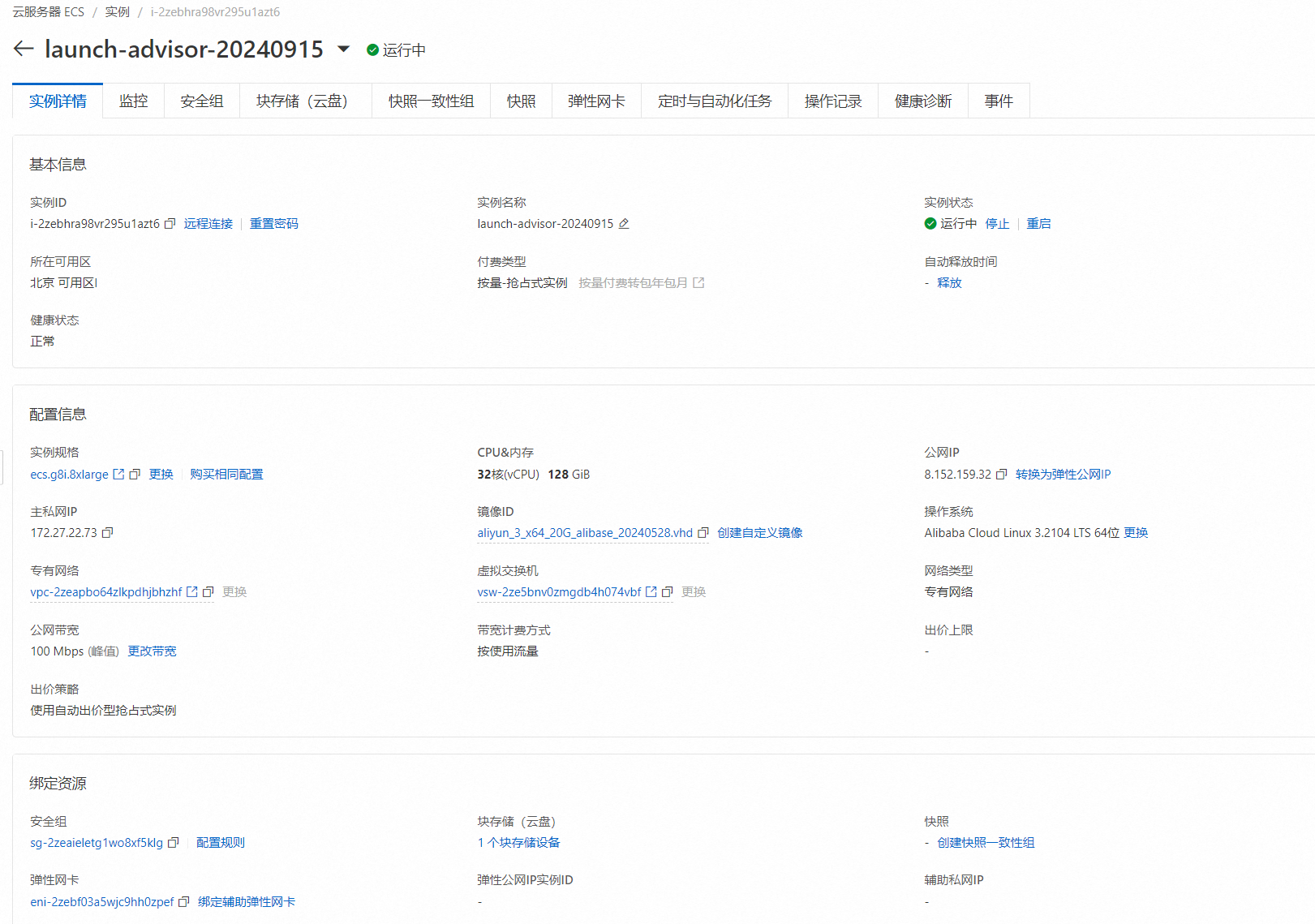
登录主机
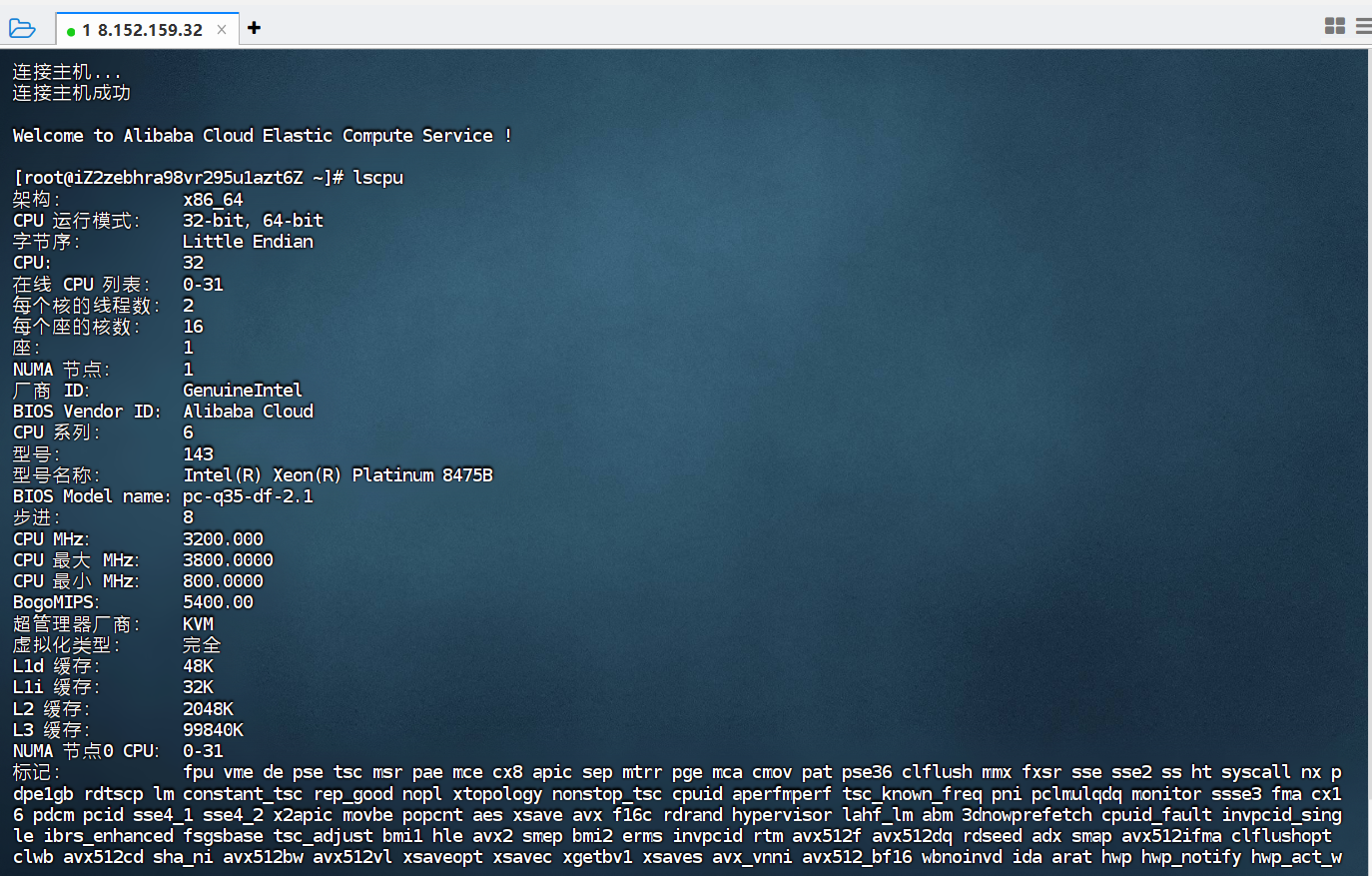
-
运行以下命令,添加docker-ce的dnf源。
sudo dnf config-manager --add-repo=https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo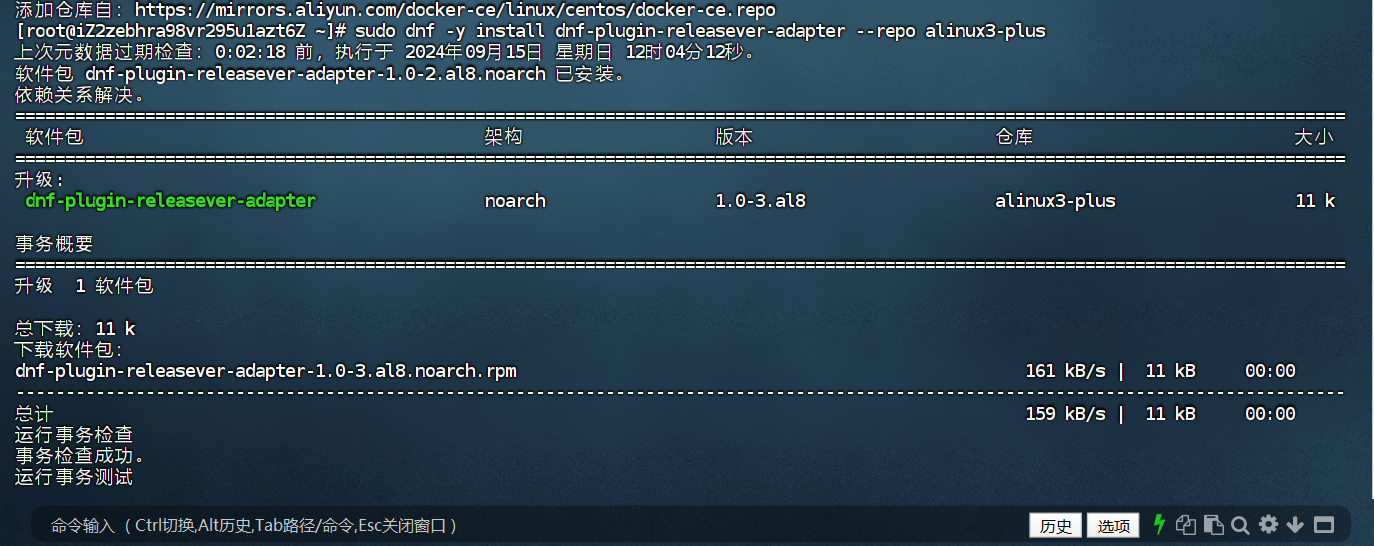
-
运行以下命令,安装Alibaba Cloud Linux 3专用的dnf源兼容插件。
sudo dnf -y install dnf-plugin-releasever-adapter --repo alinux3-plus -
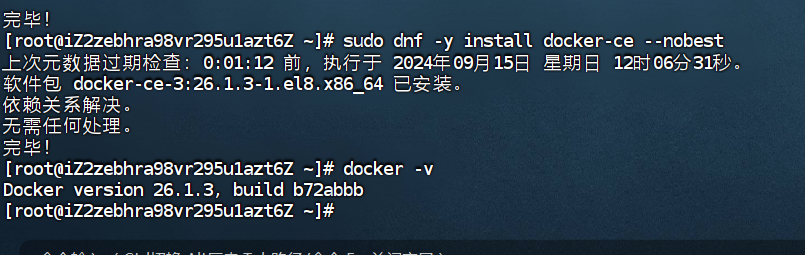
运行以下命令,安装Docker。
sudo dnf -y install docker-ce --nobest -
查看
docker版本信息。
docker -v
如下图回显信息所示,表示Docker已安装成功。
- 启动Docker守护进程并设置开机自启动。
-
执行以下命令,启动Docker服务,并设置开机自启动。
sudo systemctl start docker sudo systemctl enable docker

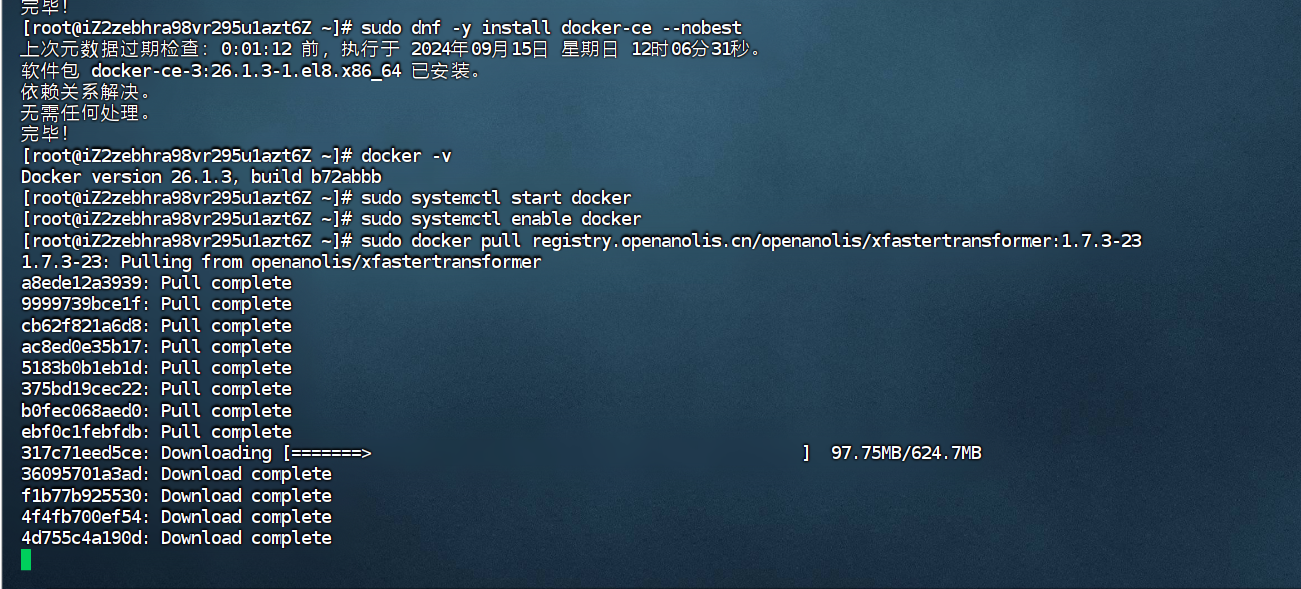
获取并运行Intel xFasterTransformer容器,等待下载完成
sudo docker pull registry.openanolis.cn/openanolis/xfastertransformer:1.7.3-23
sudo docker run -it --name xFT -h xFT --privileged --shm-size=16g --network host -v /mnt:/mnt -w /mnt/xFasterTransformer registry.openanolis.cn/openanolis/xfastertransformer:1.7.3-23
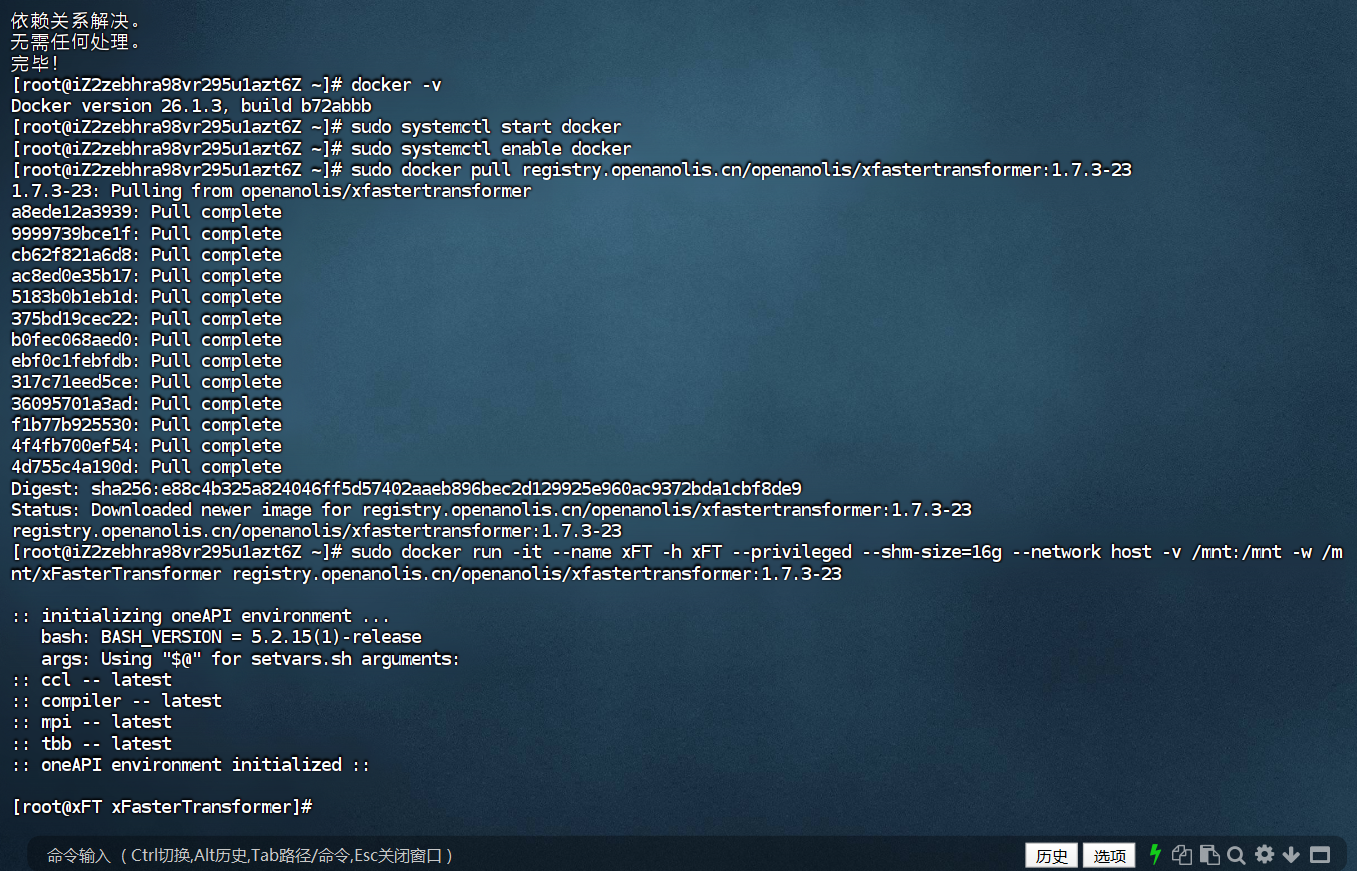
xFasterTransformer镜像中已包含对应版本的脚本代码,可以更新升级到最新的测试脚本。
yum update -y
yum install -y git
cd /root/xFasterTransformer
git pull
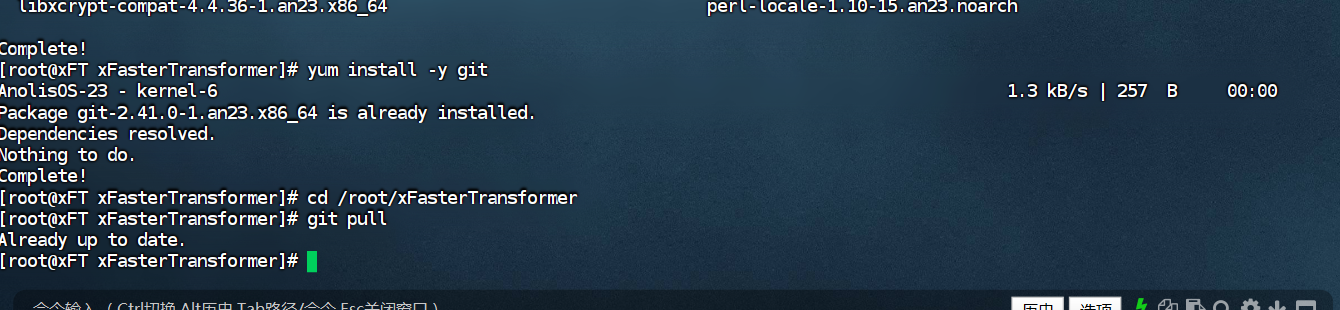
容器中安装依赖软件。
yum update -y
yum install -y wget git git-lfs vim tmux
启用Git LFS
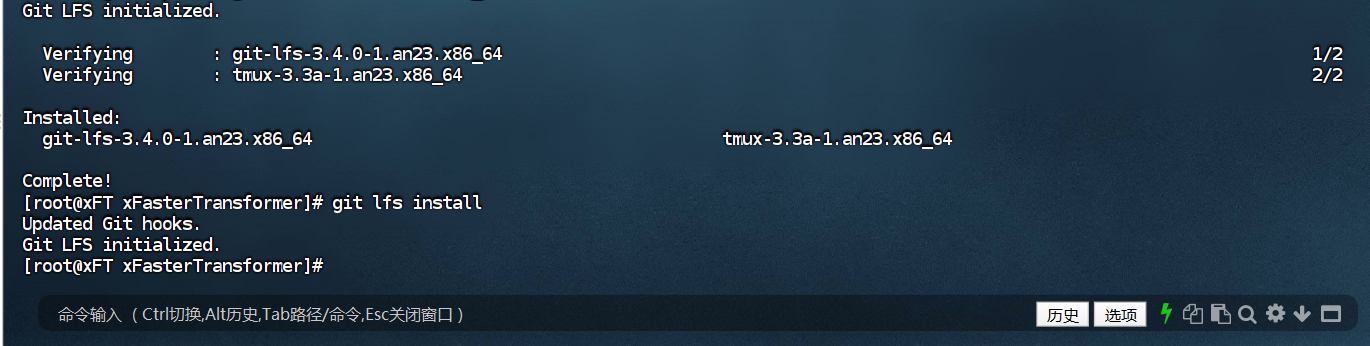
创建并进入模型数据目录。
mkdir /mnt/data
cd /mnt/data
tmux
-
下载Qwen-7B-Chat预训练模型。
git clone https://www.modelscope.cn/qwen/Qwen-7B-Chat.git /mnt/data/qwen-7b-chat -
转换模型数据。
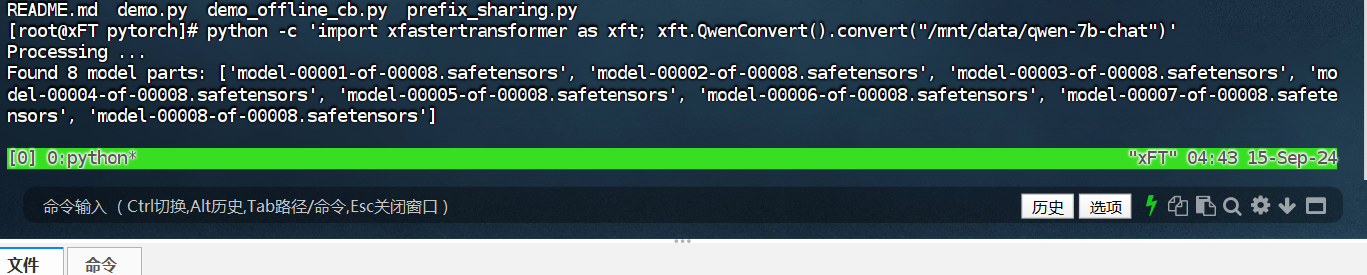
由于下载的模型数据是HuggingFace格式,需要转换成xFasterTransformer格式。生成的模型文件夹为
/mnt/data/qwen-7b-chat-xft。python -c 'import xfastertransformer as xft; xft.QwenConvert().convert("/mnt/data/qwen-7b-chat")'
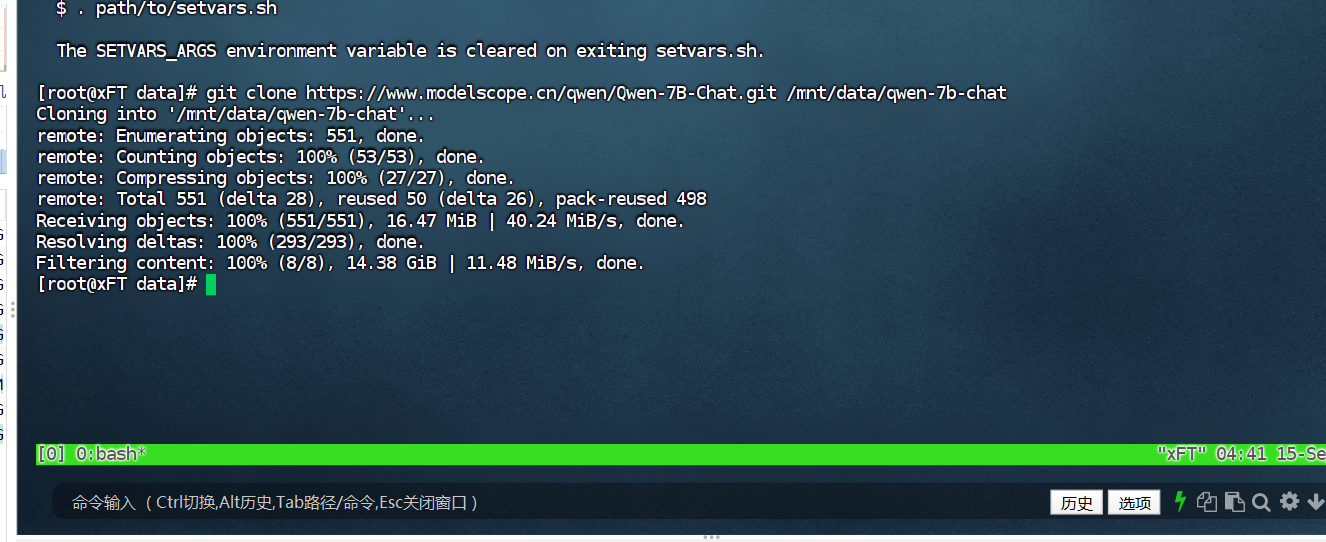
由于下载的模型数据是HuggingFace格式,需要转换成xFasterTransformer格式。生成的模型文件夹为/mnt/data/qwen-7b-chat-xft。
python -c 'import xfastertransformer as xft; xft.QwenConvert().convert("/mnt/data/qwen-7b-chat")'
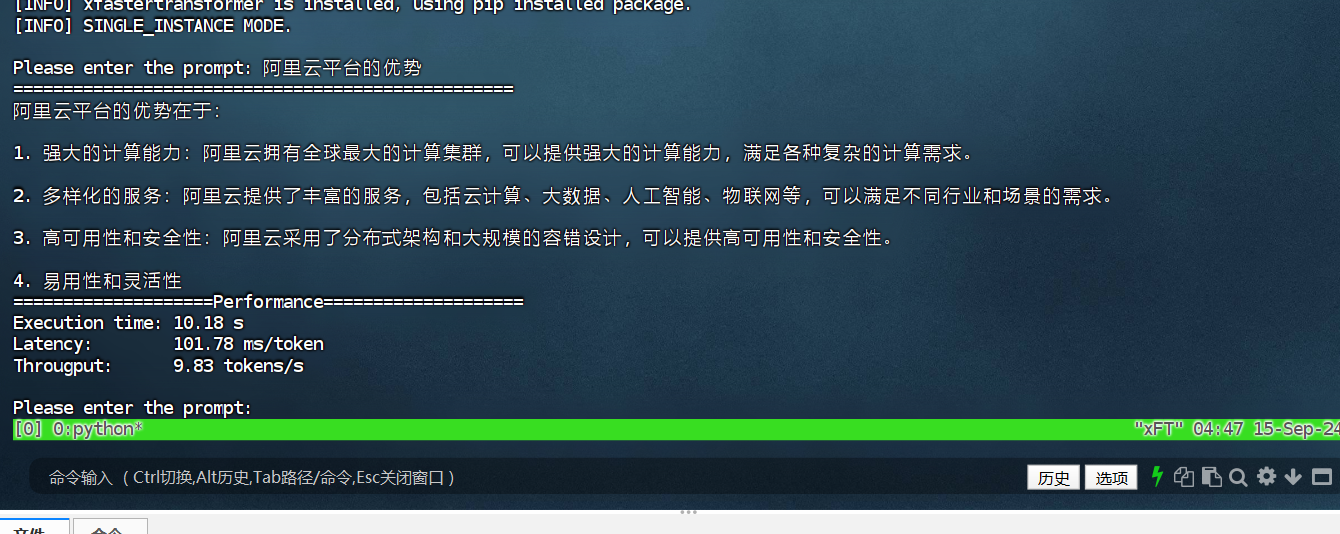
执行以下命令,启动AI对话程序。
cd /root/xFasterTransformer/examples/pytorch
OMP_NUM_THREADS=$(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') / 2)) LD_PRELOAD=libiomp5.so numactl -C $(seq -s, 0 2 $(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') - 2))) -m 0 python demo.py -t /mnt/data/qwen-7b-chat -m /mnt/data/qwen-7b-chat-xft -d bf16 --chat true
-
在容器中,依次执行以下命令,安装WebUI相关依赖软件。
cd /root/xFasterTransformer/examples/web_demo pip install -r requirements.txt -
执行以下命令,启动WebUI。
OMP_NUM_THREADS=$(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') / 2)) GRADIO_SERVER_NAME="0.0.0.0" numactl -C $(seq -s, 0 2 $(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') - 2))) -m 0 python Qwen.py -t /mnt/data/qwen-7b-chat -m /mnt/data/qwen-7b-chat-xft -d bf16当出现如下信息时,表示WebUI服务启动成功。

-
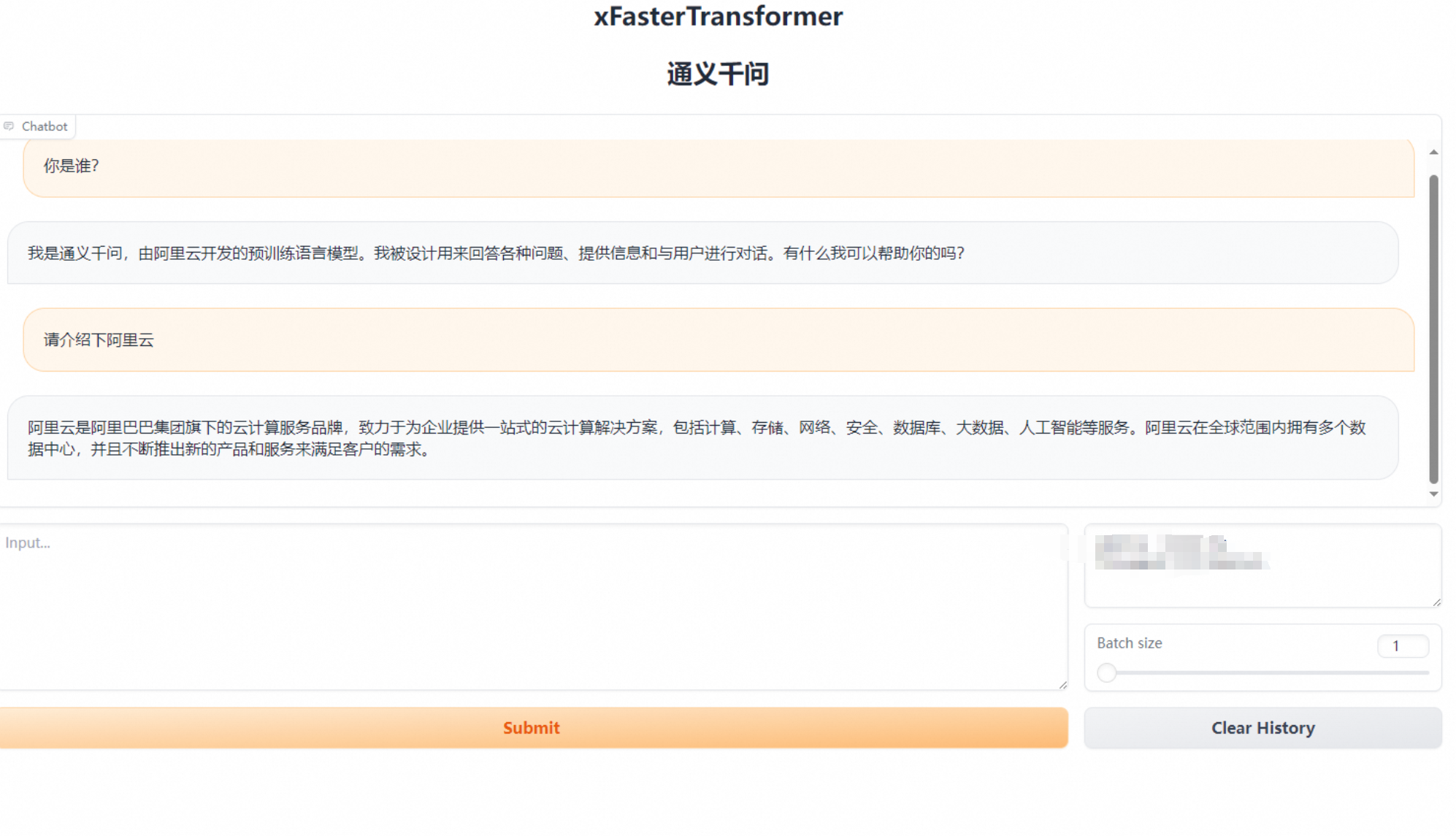
在浏览器地址栏输入
http://8.152.159.32:7860,进入Web页面。
4. 部署应用
使用VSCode进行开发,调用我们部署的千问大模型
使用API调用api_name: /predict
from gradio_client import Client, file
client = Client("http://8.152.159.32:7860/")
client.predict(
query="1+1
",
chatbot=[],
batch_size=2,
max_length=2048,
api_name="/predict"
)
client.predict(
api_name="/clean_input"
)
api_name: /predict
from gradio_client import Client
client = Client("http://8.152.159.32:7860/")
result = client.predict(
query="Hello!!",
chatbot=[],
batch_size=1,
max_length=2048,
api_name="/predict"
)
print(result)
Python程序代码
import requests
import streamlit as st
from docx import Document
from docx.shared import Pt
import base64
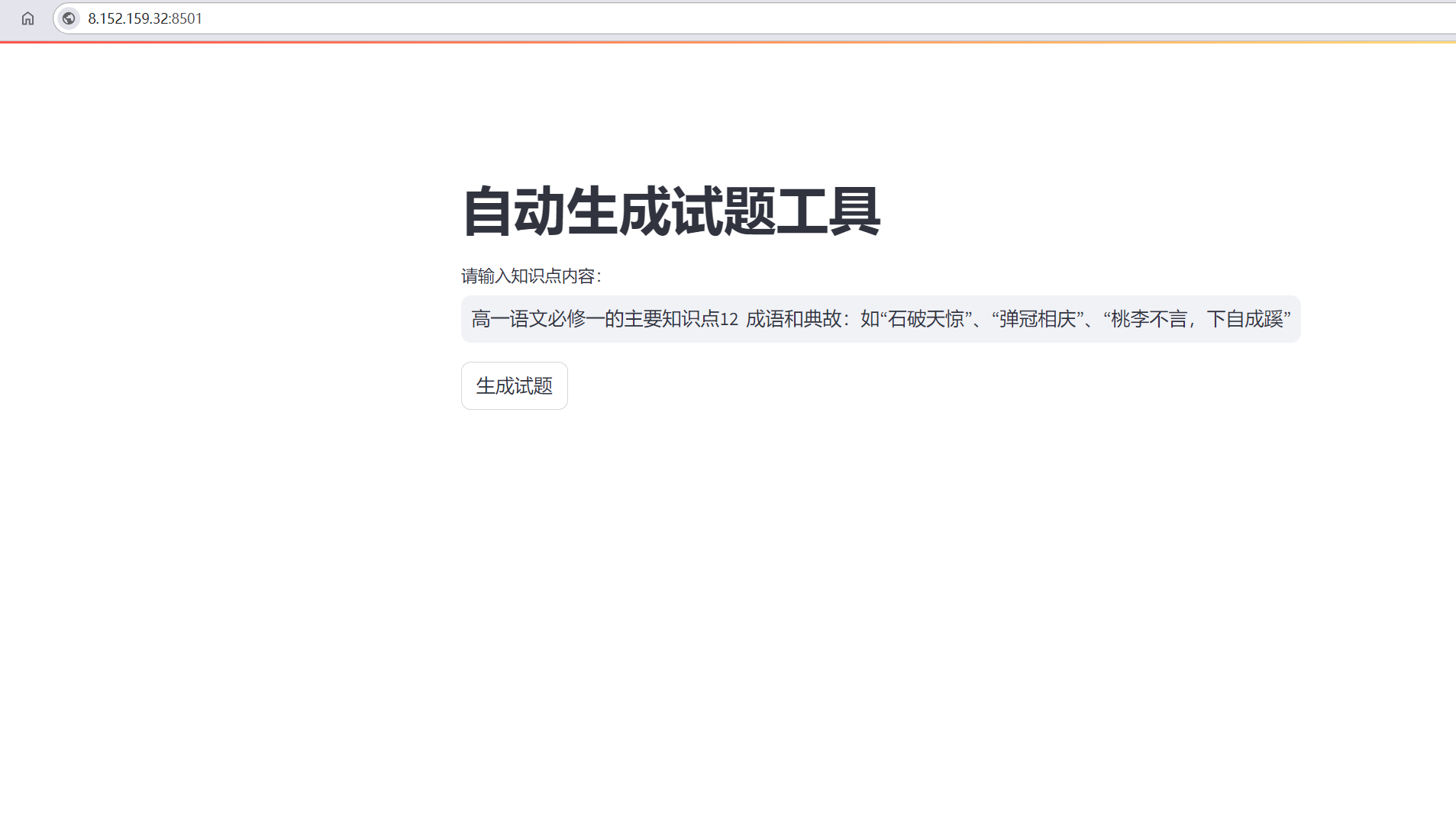
st.title("自动生成试题工具")
knowledge_point = st.text_input("请输入知识点内容:")
if st.button("生成试题"):
if knowledge_point:
api_url = "http://8.152.159.32:7860/?"
data = {"knowledge_point": knowledge_point}
response = requests.post(api_url, json=data)
if response.status_code == 200:
questions = response.json()
# 美化页面显示
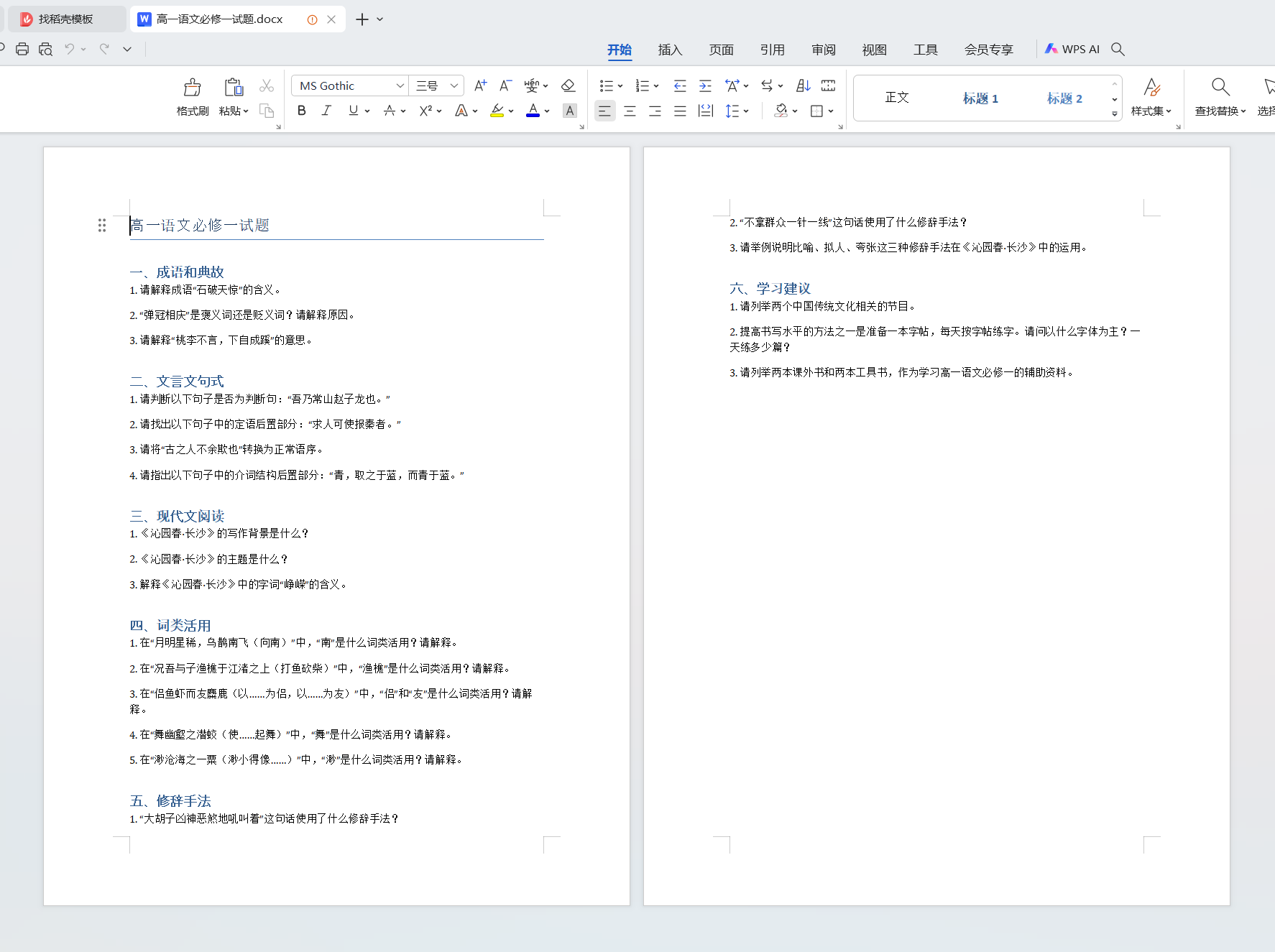
st.write("生成的试题:")
for index, question in enumerate(questions):
st.markdown(f"**试题 {index + 1}**:{question}")
# 生成可下载的 Word 文件
doc = Document()
for question in questions:
p = doc.add_paragraph()
p.add_run(question).font.size = Pt(12)
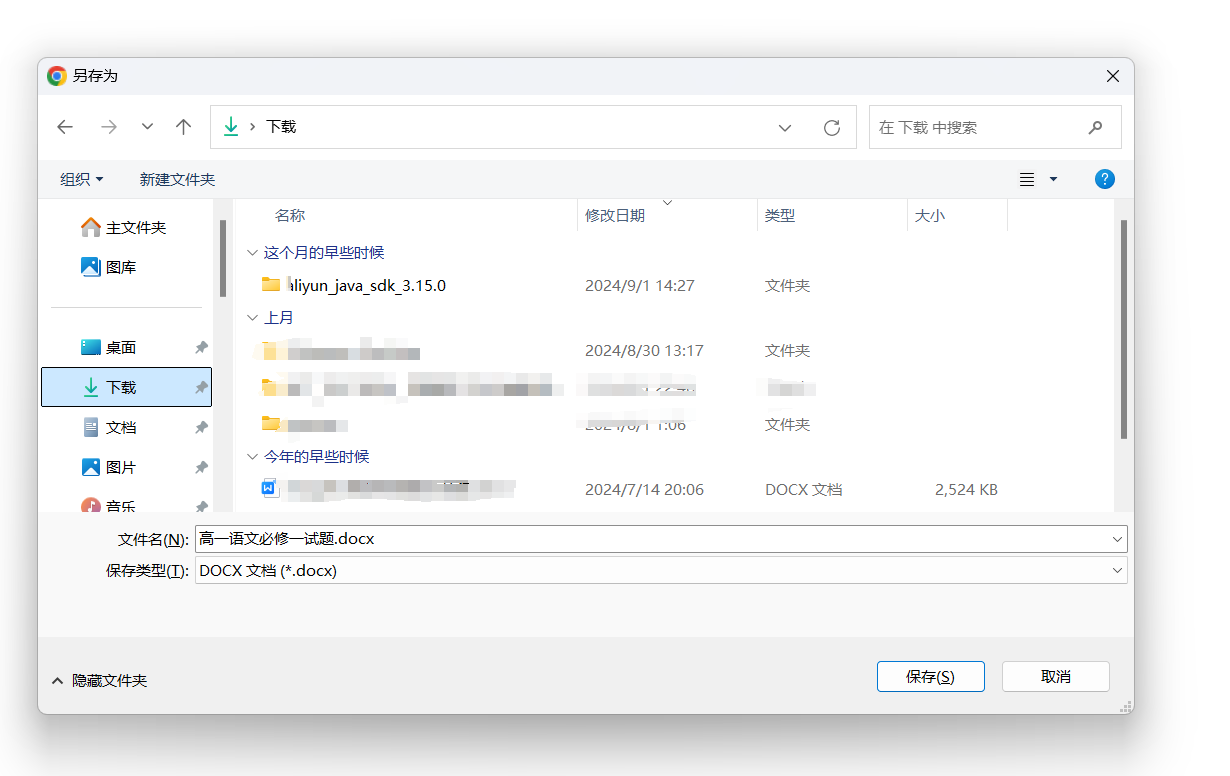
doc_filename = f"试题_{knowledge_point.replace(' ', '_')}.docx"
doc.save(doc_filename)
with open(doc_filename, "rb") as f:
bytes_data = f.read()
b64 = base64.b64encode(bytes_data).decode()
href = f'<a href="data:application/octet-stream;base64,{b64}" download="{doc_filename}">点击下载试题 Word 文件</a>'
st.markdown(href, unsafe_allow_html=True)
else:
st.error("无法生成试题,请检查 API 是否正确或网络是否正常。")
else:
st.warning("请输入知识点内容。")
点击下载试题
生成试题内容如下
5. 项目意义和可行性
项目意义
- 提高教学效率:教师可以快速获得符合教学要求的试题和试卷,节省大量的时间和精力。
- 提升教学质量:自动生成的试题可以涵盖更多的知识点和考点,提高试题的多样性和针对性。
- 促进教育公平:通过智能化的试题生成和组卷工具,可以为不同地区和学校的教师提供同等质量的教学资源。
- 推动教育信息化:本项目的实施将进一步推动人工智能技术在教育领域的应用,促进教育信息化的发展。
项目可行性
- 技术可行性:阿里云平台和英特尔 G8i 实例提供了强大的计算资源和技术支持,千问大模型在自然语言处理方面具有出色的表现,为项目的实施提供了技术保障。
- 经济可行性:使用云计算服务可以降低硬件设备的投入成本,同时提高资源的利用率。项目的开发和维护成本相对较低,具有较高的经济效益。
- 市场可行性:教育领域对于自动生成试题和组卷工具的需求较大,本项目的应用前景广阔。通过与教育机构和学校的合作,可以快速推广和应用本项目的成果。















 4669
4669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









