






zookeeper是针对谷歌chubby的一个开源实现,是高效和可靠的协同工作系统,提供分布式锁之类的基本操作(如统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等),用于构建分布式应用,减轻分布式应用程序所承担的协调任务。zookeeper使用Java编写,很容易编程接入,它使用了一个和文件树结构相似的数据模型,可以使用Java或者C来进行编程接入。
一,伪分布模式下安装zookeeper组件
1,搭建hadoop伪分布模式,ssh免密登录
详情见大数据处理架构hadoop分布式文件系统搭建(HDFS)下-CSDN博客
相关模块介绍
2,上传zookeeper组件到伪分布模式的主机下,并配置
tar -zxf 文件 #解压
mv apache-zookeeper-3.8.1-bin zookeeper #改名方便后续操作
sudo vim ~/.bashrc #在该文件中加入以下内容
在jdk配置的地方加入export CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export ZOOKEEPER_HOME=/opt/apps/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATHsource ~/.bashrc #使配置文件生效
zkEnv.sh #测试无报错输出即为配置成功


3.配置zookeeper专用配置文件。
cd zookeeper/conf #进入zookeeper组件的conf目录下
cp zoo_sample.cfg zoo.cfg #将zoo_sample.cfg复制为zoo.cfg
vim zoo.cfg #编辑zoo.cfg文件写入以下配置信息
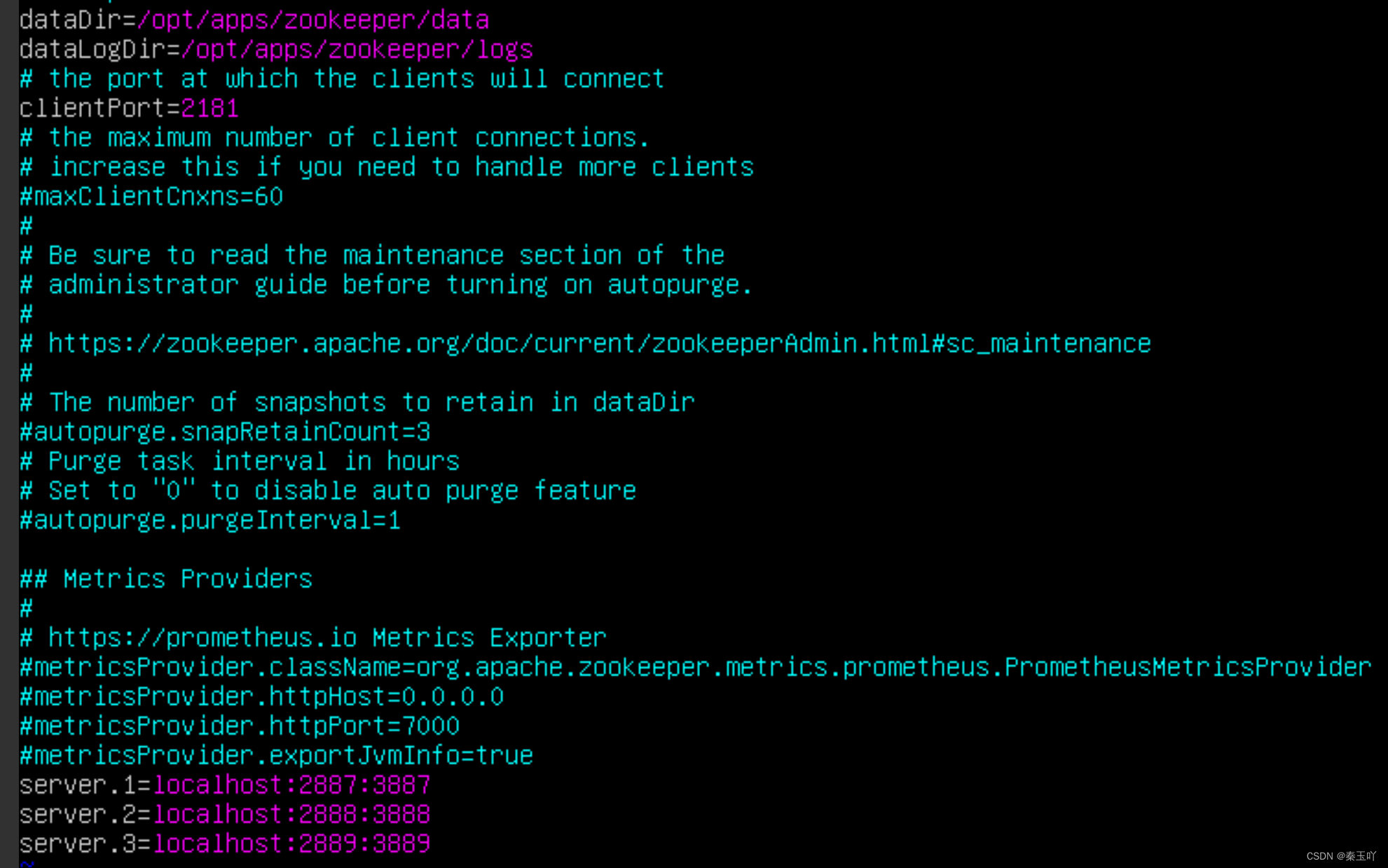
dataDir=/opt/apps/zookeeper/data #设置zookeeper的文件路径
dataLogDir=/opt/apps/zookeeper/logs #设置zookeeper的日志路径
serveer.1=loclhoster:2887:3887 #放在文件底部,因为是伪分布式没有三台虚拟机,所以设置不同的端口号
serveer.2=loclhoster:2888:3888
serveer.3=loclhoster:2889:3889
cp zoo.cfg zoo2.cfg
cp zoo.cfg zoo3.cfg #j将 zoo.cfg文件复制出两份,分别命名为 zoo2.cfg和 zoo3.cfg
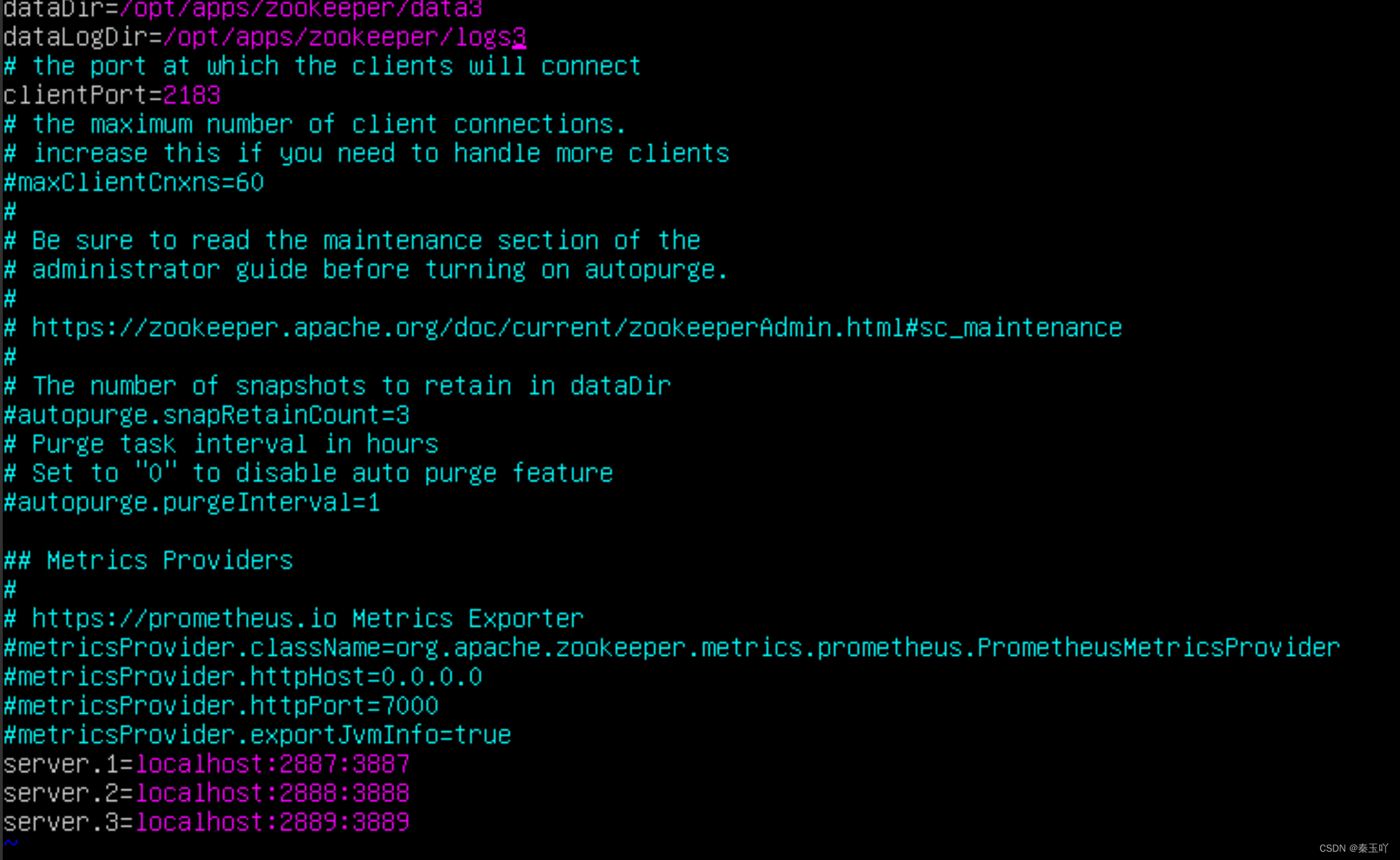
vim zoo2.cfg
vim zoo.3cfg #分别进入 zoo2.cfg和 zoo3.cfg修改客户端端口号
如下图

cd /opt/apps/zookeeper
mkdir log
mkdir log2
mkdir log3
mkdir data
mkdir data2
mkdir data3
vim data/myid #在该文件中写入数字1
vim data2/myid#在该文件中写入数字2
vim data3/myid#在该文件中写入数字3

4. 启动hdfs集群,启动zookeeper,查看zookeeper。
start-all.sh #启动hdfs集群所有端口
jps #查看端口是否打开

cd /opt/apps/zookeeper/conf #进入conf目录
zkServer.sh start zoo.cfg #启动第一个zookeeper客户端
zkServer.sh start zoo2.cfg#启动第二个zookeeper客户端
zkServer.sh start zoo3.cfg#启动第三个zookeeper客户端
jps #查看端口
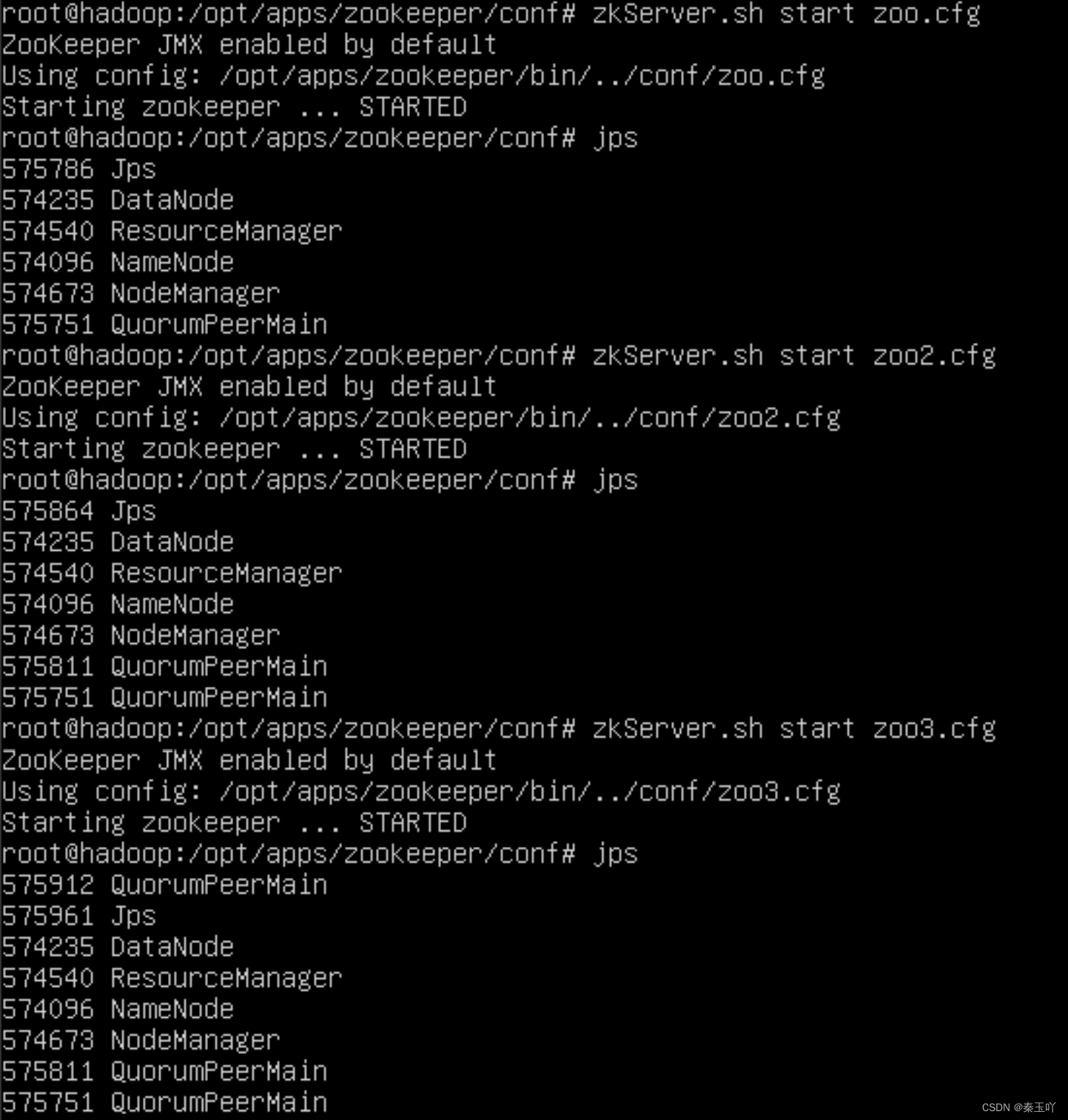
zkServer.sh status zoo.cfg
zkServer.sh status zoo2.cfg
zkServer.sh status zoo3.cfg #查看zookeeper启动状态并将他们分别分配为一个leader两个follower(一主二仆)
关闭zookeeper
zkServer.sh stop zoo.cfg
zkServer.sh stop zoo2.cfg
zkServer.sh stop zoo3.cfg
stop-all.sh #关闭集群

二、全分布模式下安装zookeeper组件
1. 上传zookeeper组件到虚拟机主机中,解压并配置
(1)解压更名
tar -zxf apache-zookeeper-3.8.1-bin.tar.gz
mv apache-zookeeper-3.8.1-bin zookeeper

(2) 配置环境变量
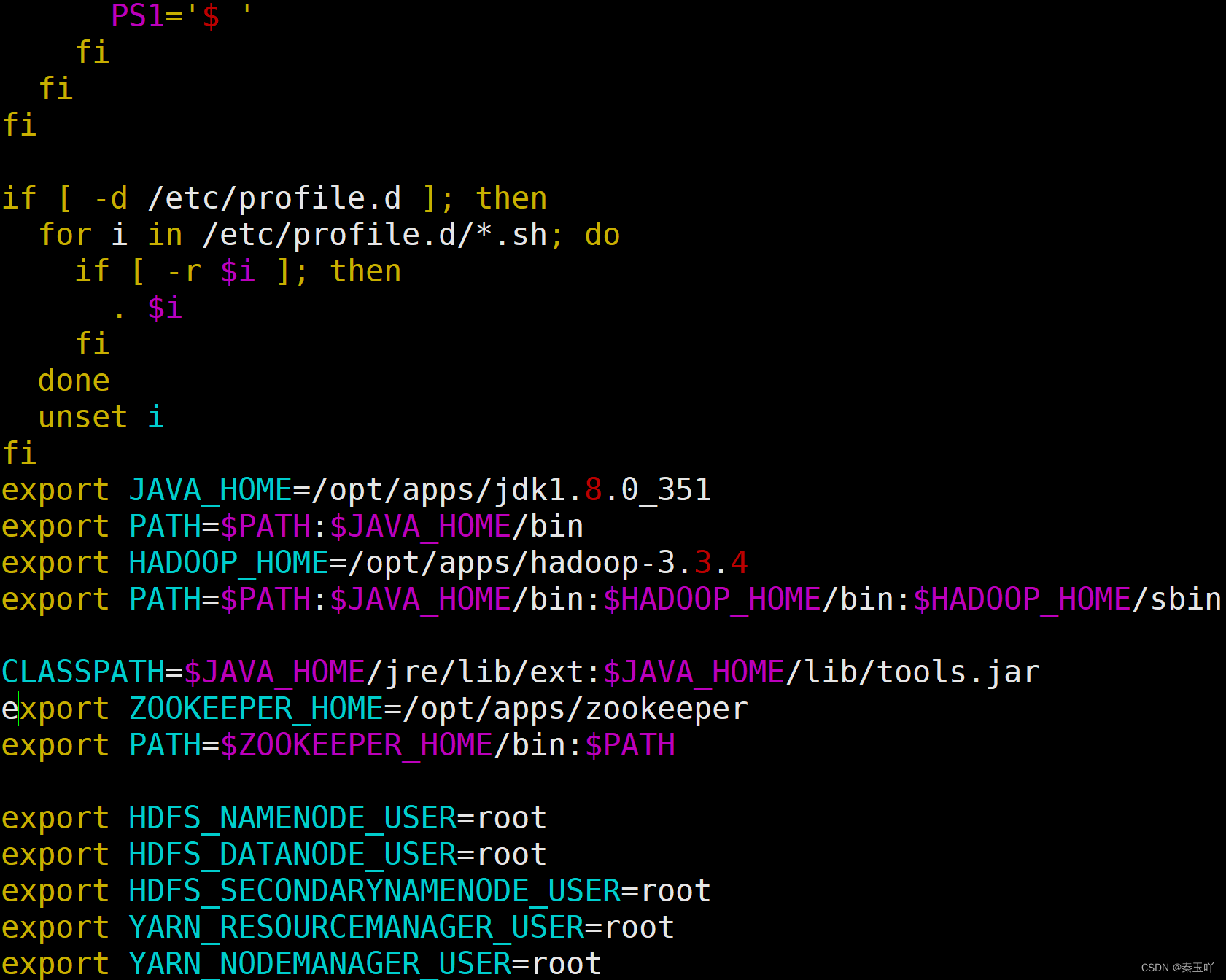
sudo vim /etc/profile #在该文件中加入以下内容
在jdk配置的地方加入export CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export ZOOKEEPER_HOME=/opt/apps/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATHsource /etc/profile #使配置文件生效
zkEnv.sh #测试无报错输出即为配置成功
 (3)配置zookeeper专用配置文件
(3)配置zookeeper专用配置文件
cp zoo_sample.cfg zoo.cfg #进入zookeeper的conf将zoo_sample.cfg复制为zoo.cfg文件
vim zoo.cfg #进入zoo.cfg文件对zookeeper进行配置
添加以下内容
dataDir=/opt/apps/zookeeper/data #设置zookeeper的文件路径
dataLogDir=/opt/apps/zookeeper/logs #设置zookeeper的日志路径
serveer.1=hadoop:2888:3888
serveer.2=hadoop2:2888:3888
#进入zookeeper目录
mkdir logs #创建日志文件目录存放日志
mkdir data #创建运行文件目录
echo 1 > data/myid #在运行文件目录创建myid文件并写入1



(4)将文件分发给从机
scp -r zoo.cfg hadoop2:/opt/apps/zookeeper/conf/ #传输zookeeper组件给从机
scp -r /etc/profile hadoop2:/etc/profile #传输环境配置
source /etc/profile #生效配置
echo 2 > myid #写入数字2在从机的data目录的myid文件中

2.启动hdfs集群,启动zookeeper,查看状态
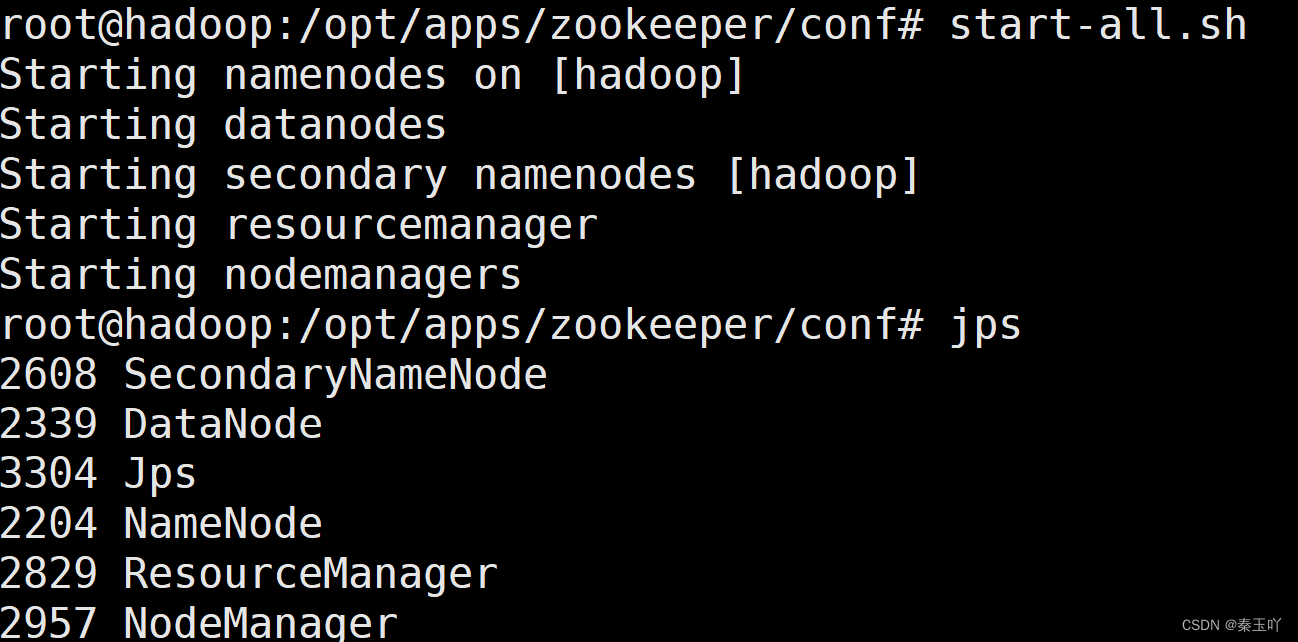
start-all.sh #启动集群
zkServer.sh start #启动zookeeper组件
zkServer.sh status #查看zookeeper状态,两台机器会分配
jps #查看进程


 3.关闭hdfs,关闭zookeeper
3.关闭hdfs,关闭zookeeper
stop-all.sh #关闭hdfs
zkServer.sh stop #关闭zookeeper
















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









