







本博客会从一个从未部署过任何环境的电脑上一步步复现如何本地训练自定义模型并成功部署到Maixcam上实现数字识别的功能。
文章中会引用到我当时学习是参考到的文章,都会在下面列出来,在此对这些向我提供过帮助的博主表示感谢!!
本文中默认读者已经了解过相对应的知识,一些非常详细的操作我会引用一些文章。
前期的准备工作:搭建环境,框架,制作自己的数据集已经准备好了,就可以开始训练自己的模型了。
训练目标检测模型需要修改两个yaml文件中的参数,分别在data和model目录下面。
1.1 修改数据配置文件
我们找到VOC.yawl文件,复制一份粘贴在同路径下,取名为number.yawl (由于我们做的是数字识别的模型,就取这个名字方便自己看)
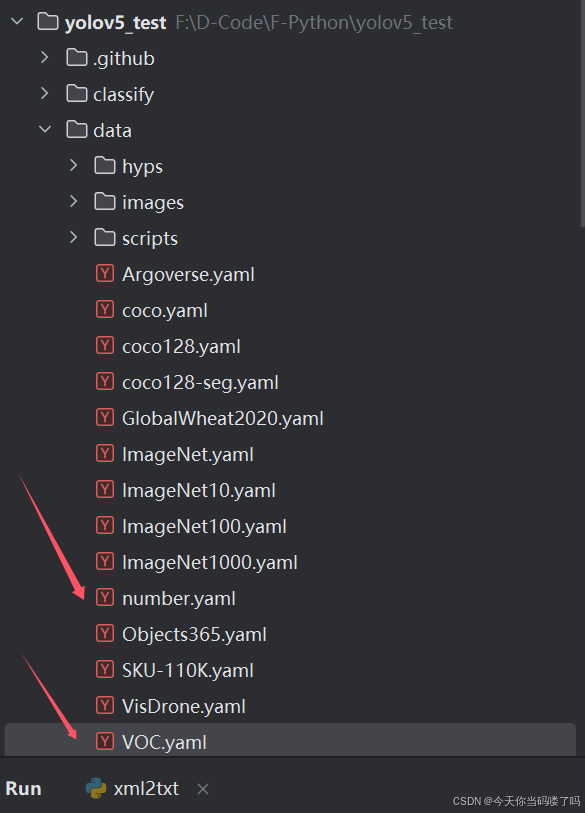
随后,我们number.yawl文件前面的内容更改为下图所示:
path: 绝对路径
train: path下面的训练集路径
val: path下面的验证集路径
nc: 训练集种类的个数
names: 种类对应的名字,顺序要和打标时的顺序一致,不要弄错了
1.2 修改模型参数文件
由于我们选择的预训练权重是yolov5s.pt,故我们将model文件夹中的yolov5s.yaml复制一份在同一路径下,取名为yolov5s_number.yaml
随后,我们打开yolov5s_number.yaml后只需要修改下图中的数字,改为8(我们识别8个数字)
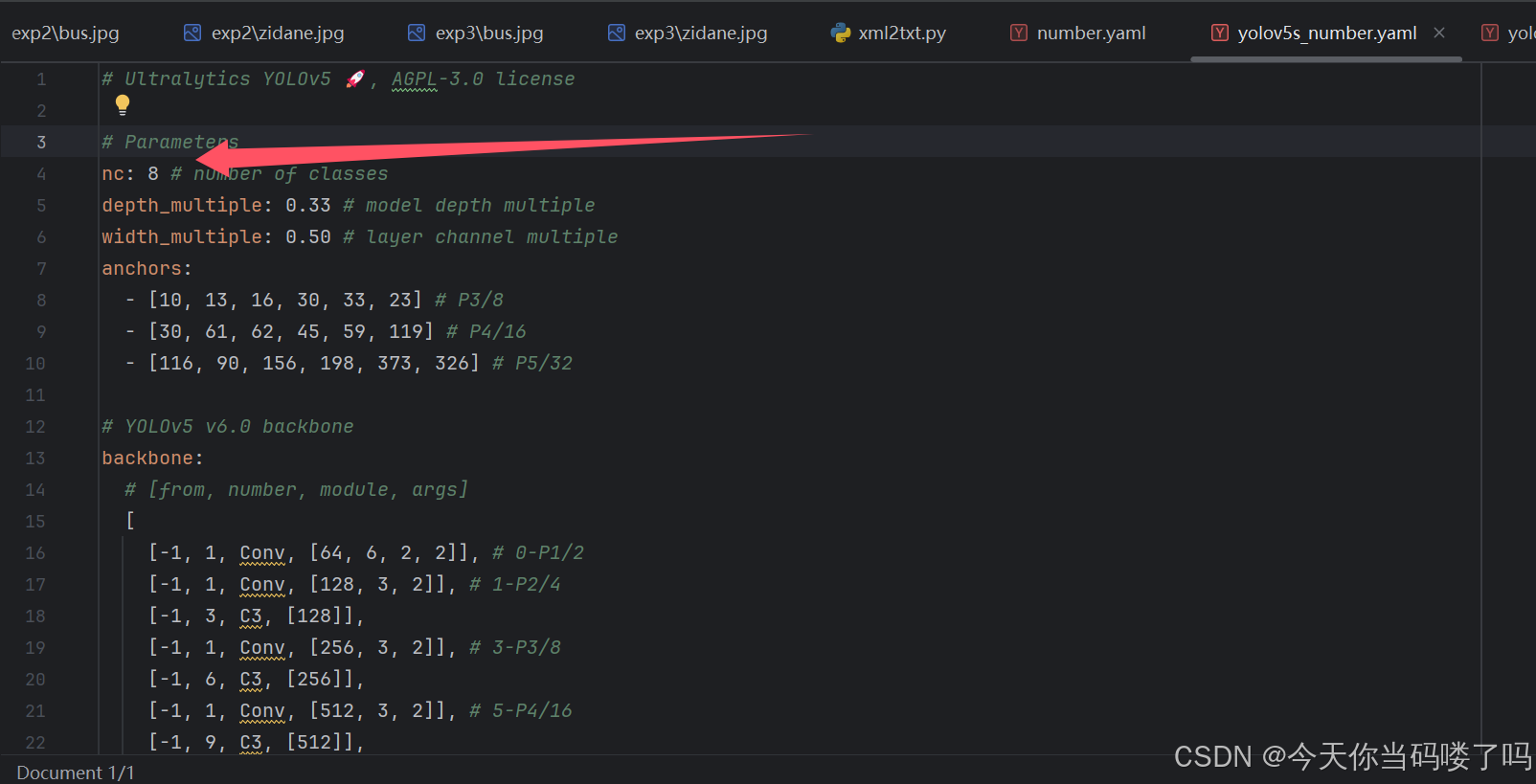
相应的模型参数就设置好了。
1.3 根据自己的需求修改train.py的配置
我们将train.py翻到最下面 右击parse_opt() 转到函数定义,如下图:
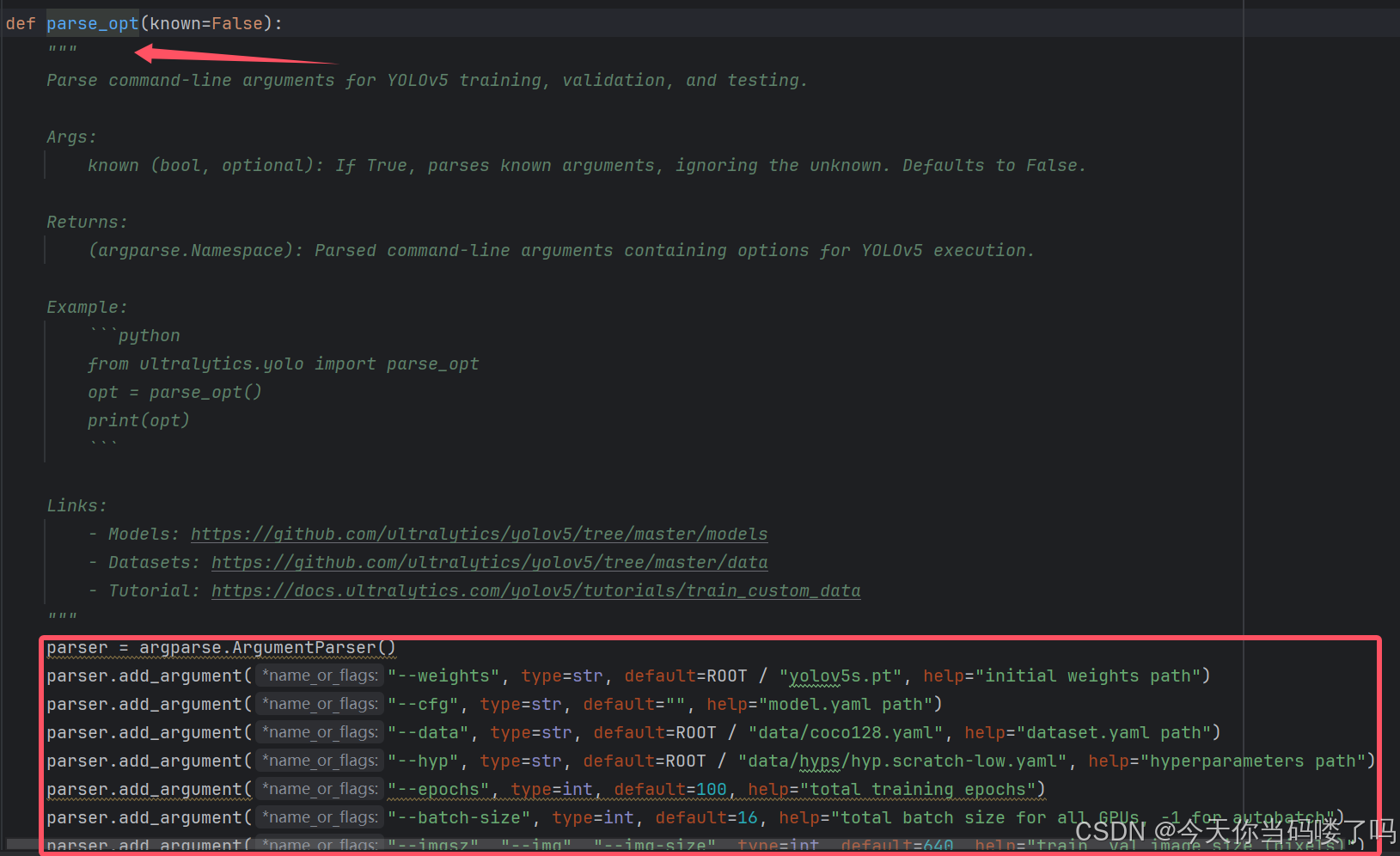
下面附上一些参数的解析
opt模型主要参数解析:
–weights:初始化的权重文件的路径地址
–cfg:模型yaml文件的路径地址
–data:数据yaml文件的路径地址
–hyp:超参数文件路径地址
–epochs:训练轮次
–batch-size:喂入批次文件的多少
–img-size:输入图片尺寸
–rect:是否采用矩形训练,默认False
–resume:接着打断训练上次的结果接着训练
–nosave:不保存模型,默认False
–notest:不进行test,默认False
–noautoanchor:不自动调整anchor,默认False
–evolve:是否进行超参数进化,默认False
–bucket:谷歌云盘bucket,一般不会用到
–cache-images:是否提前缓存图片到内存,以加快训练速度,默认False
–image-weights:使用加权图像选择进行训练
–device:训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)
–multi-scale:是否进行多尺度训练,默认False
–single-cls:数据集是否只有一个类别,默认False
–adam:是否使用adam优化器
–sync-bn:是否使用跨卡同步BN,在DDP模式使用
–local_rank:DDP参数,请勿修改
–workers:最大工作核心数
–project:训练模型的保存位置
–name:模型保存的目录名称
–exist-ok:模型目录是否存在,不存在就创建
这张图片是点这里:Yolov5认真总结6000字
这个博主总结的,在此引用一下。

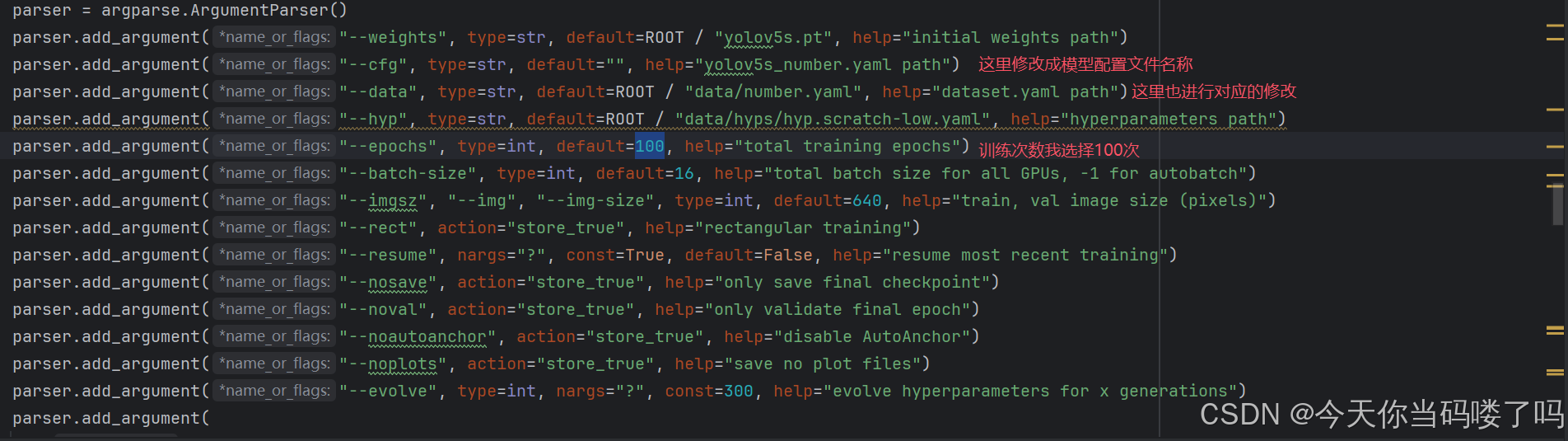
我标注修改处的,是一定要修改的;其他的注释是一些较为重要的参数,对于小白而言不改也可。具体修改的地方为defalut后
479行:是我们训练的初始权重的位置,是以.pt结尾的文件,第一次训练用别人已经训练出来的权重。可能有朋友会想,自己训练的数据集和别人训练的数据集不一样,怎么能通用呢?实际上他们是通用的,后面训练会调整过来。而如果不填已有权重,那么训练效果可能会不好;
480行:训练模型文件,在本项目中对应wzry_model.yaml;
481行:数据集参数文件,在本项目中对于wzry_parameter.yaml;
482行:超参数设置,是人为设定的参数。包括学习率啥的等等,可不改;
483行:训练轮数,决定了训练时间与训练效果。如果选择训练模型是yolov5x.yaml,那么大约200轮数值就稳定下来了(收敛);
484行:批量处理文件数,这个要设置地小一些,否则会out of memory。这个决定了我们训练的速度;
485行:图片大小,虽然我们训练集的图片是已经固定下来了,但是传入神经网络时可以resize大小,太大了训练时间会很长,且有可能报错,这个根据自己情况调小一些;
487行:断续训练,如果说在训练过程中意外地中断,那么下一次可以在这里填True,会接着上一次runs/exp继续训练
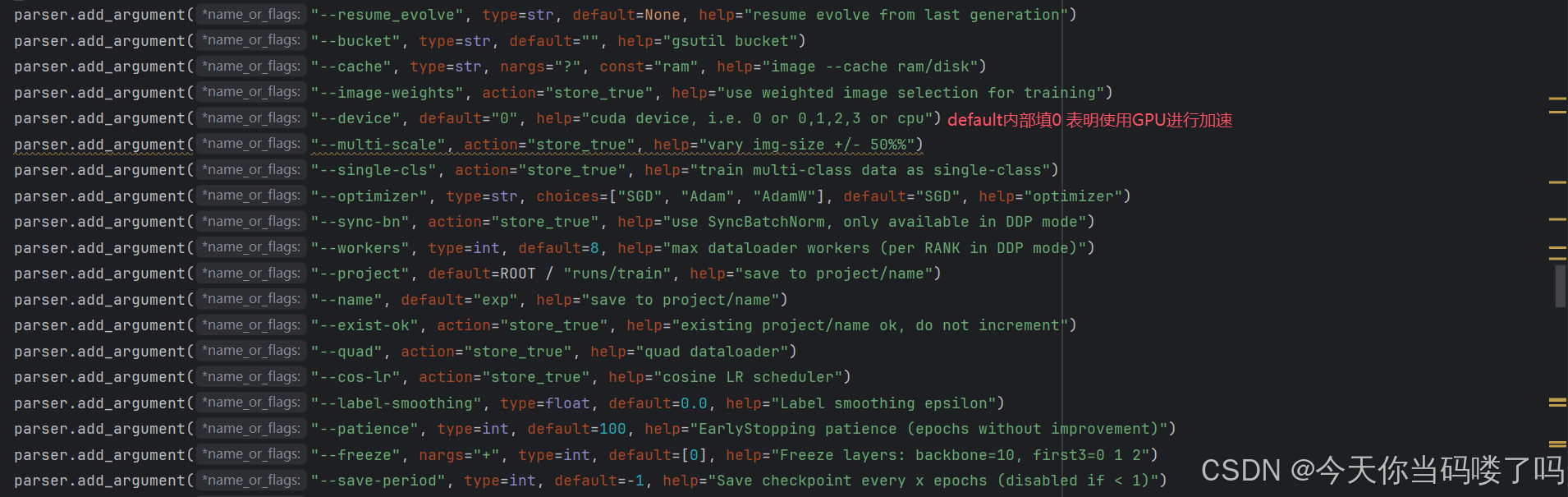
496行:GPU加速,填0是电脑默认的CUDA,前提是电脑已经安装了CUDA才能GPU加速训练,安装过程可查博客
501行:多线程设置,越大读取数据越快,但是太大了也会报错,因此也要根据自己状况填小。
我进行了这些更改:
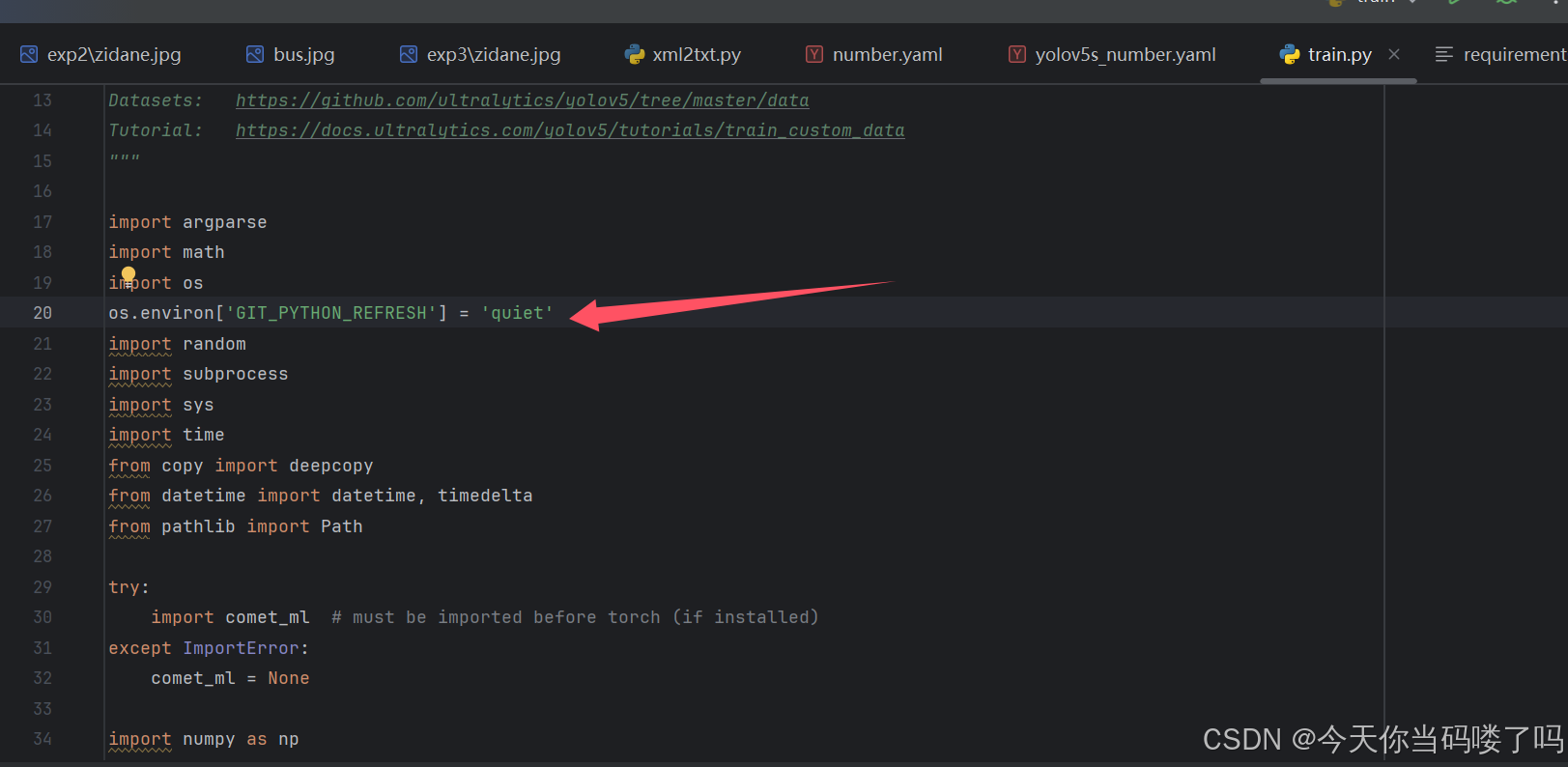
运行train.py后发现报错ImportError:Bad git executable.
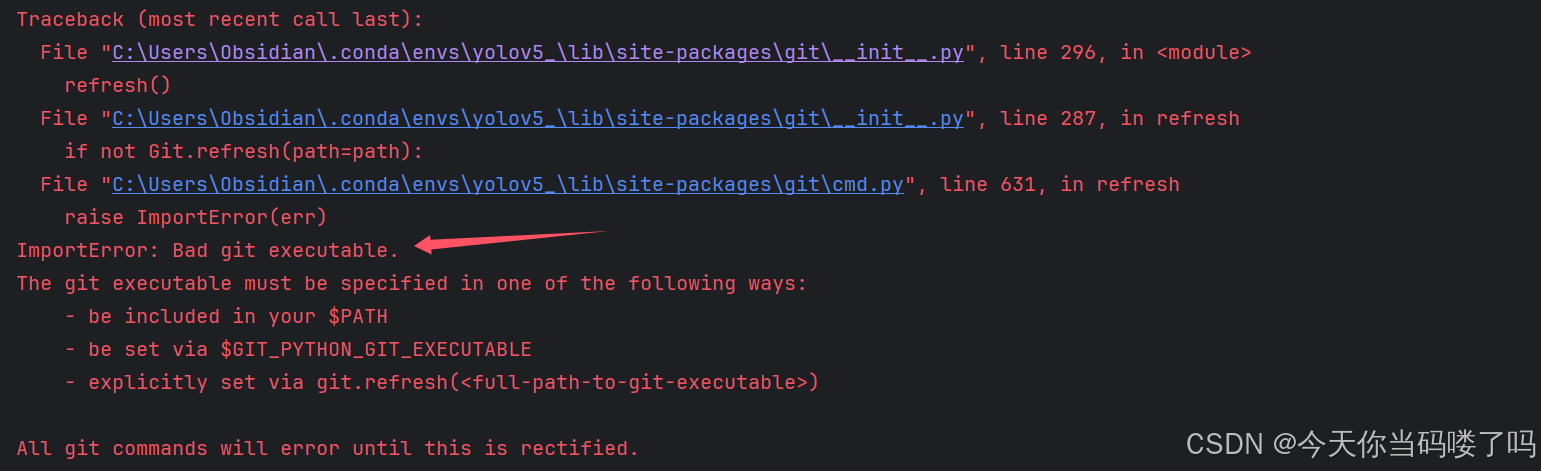
只需要在文件开头加上这一句话:
os.environ[‘GIT_PYTHON_REFRESH’] = ‘quiet’ 即可
再次运行train.py 发现报错
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 26.00 MiB. GPU 0 has a total capacity of 6.00 GiB of which 3.59 GiB is free. Of the allocated memory 1.35 GiB is allocated by PyTorch, and 38.87 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
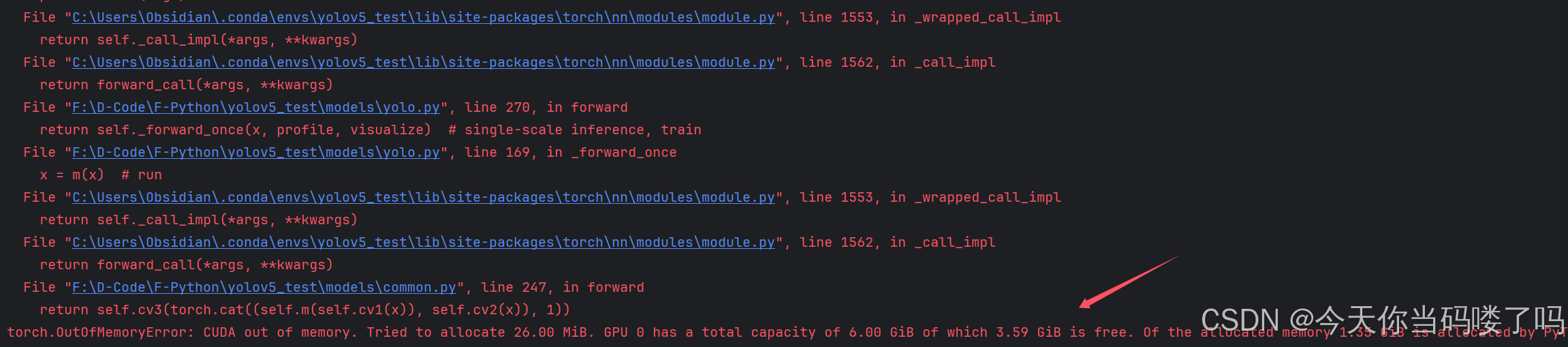
这就是**–batch-size:喂入批次文件的多少**过大导致的 我们将其从16调整为8,重新运行,发现已经开始跑起来了

Tips:可能有的电脑会遇到一些其他的错误,只需要复制错误语句去CSDN上面搜,大部分都可以找得到解决方法。
1.4 训练,启动!
接下来就慢慢等待吧!
资料如图所示:
通过百度网盘分享的文件:资料.zip
链接:https://pan.baidu.com/s/16h4Th9UbOF9YfJEgItYwYA?pwd=6969
提取码:6969

















 3124
3124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









