






文章开始前打个小广告——分享一份Python学习大礼包(激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程)点击领取,100%免费!
Python数据分析基础全流程攻略如下(适合初学、转岗、无编程基础小白,直接教学,没有额外链接)
一、学习
针对数据分析模块,python学习的内容并非全都要学(SQL也是如此),即不需要像程序员一样学那么多,也要知道推动应用的部分是统计学知识,你要知道有回归这个东西,才去用python实现它
大部分内容都需要额外百度和学习才可走完,但基本都是免费的
主要的学习框架包括:
1、程序语言基础(输入输出,,循环等)
2、数据分析相关库使用(numpy、pandas、matplotlib)
3、统计学理论应用,分析案例实战
在工作流程中,python是工具,主要作用是在【已有数据】的情况下,将【数据导入软件】,【写逻辑得出分析结果】,最后【可视化为图表和结论输出】
明确一点:python只是逻辑承接的工具,学会他并不能学会逻辑,相当于有剑没剑法,但剑法和剑缺一不可。
二、程序语言基础
程序语言基础是大一的必修课,非理工科的同学或许不接触(尤其是财会,商科),重要的学习【程序思维】,把电脑当成一个严谨的【执行人、工具、打工人】,用逻辑思维语句,通过交互界面让他输出你的想法。
1、输入输出
最基础的,当你在交互界面输出print的时候,系统会把你输入的输出出来
你说一句话,他就说一句话。你怎么说,他就怎么说。
>>>print(1)
1
>>> print(“Hello World”)
HelloWorld
>>> a = 1
>>> b = ‘runoob’
>>> print(a,b)
1runoob
如果你有很多话想说,比如说一个文档,里面存了好多数据,那你就需要准备好excel、csv和txt文件,然后换一个函数比如read_csv 和read_table就可以把这些文档导入
data = pd.read_csv(‘文件路径/result.csv’,sep=‘,’)
>>>print(data)
你的文件就到了python里
2、数据格式
对于计算机来说,所有【输入】都必须归类,数字不只是数字,有整数、;汉字,英文都是字符串;以及更近一步的,列表类型,map类型,元组类型。
不同的类型满足不同的需求、计算方式等
数据类型汇总:
数字:Int()整数、float()小数、bool()布尔类型、complex()复数
字符串(str) :包括:文字,符号,字母,特殊字符等
单引号,双引号,三单引号,三双引号括起来的都是字符串
多行打印:输出元素时换行
单行打印:在同一行输出
列表:带方括号格式,元素之间逗号分隔,元素可以是数字、字符或其他数据类型
例如:[(1, 2), ‘三’, ‘d’, {‘y’: 0}]
元组:半圆括号格式,元素可以是数字、字符或其他数据类型
例如:([1, 2], ‘三’, ‘d’, {‘y’: 0})
字典:大括号格式元素之间相互对应,查询功能,{key:value}key要求是不可变类型,value可以是任何数据类型(整形、字符串、列表、元组、字典),包括可迭代对象。不可变类型有:字符串、元组。
例如:{‘a’:1,‘b’:2}
不同的类型有不同的规则,正如同你知道1可以+2但是不可以+渭河,只有同类型才可以相互运算
3、定义变量
到这个阶段,你可以自己定义一些变量了(注意数据类型)
>>>name = ‘渭河’
>>>print(name)
>>>prtint(‘类型’,type(name))
>>>prtint(‘值’,name)
输出结果:渭河
类型 <class ‘str’>
值 渭河
工作里需要定义很多变量,比如让a = 0 ,让a = [],让他们等于一个空数组,用来计算、循环、储存各种数字和结果
4、算数运算符
这里就是最基础的逻辑,在上面你已经可以输入变量,定义变量,输出变量,链路已经ok了,现在就是说上面的:你要往上面加逻辑。
比如业务方给你提了一个需求:我要今天订单+昨天的订单
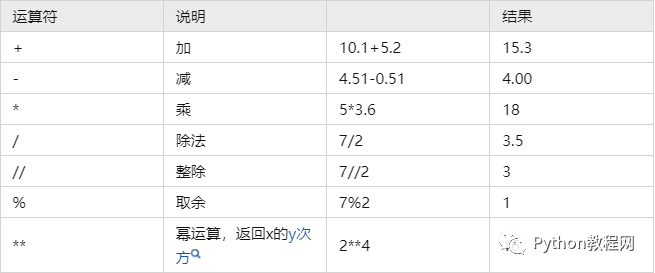
5、
函数这两个字初中就学过了,输入一个x 等于一个 y。包括第一个print,包括我们说的算数运算符,背后都有源码写了一个函数,直接调用函数,就是调用背后的逻辑
举个例子,前面学习了 len() 函数,通过它我们可以直接获得一个字符串的长度。我们不妨设想一下,如果没有 len() 函数,要想获取一个字符串的长度,该如何实现呢?
n=0
for c in “http://www.nowcoder.com/link/pc_kol_bzwh”:
n = n + 1
print(n)>>>33
函数的本质就是一段有特定功能、可以重复使用的代码,这段代码已经被提前编写好了,并且为其起一个“好听”的名字。在后续编写程序过程中,如果需要同样的功能,直接通过起好的名字就可以调用这段代码。
下面演示了如何将我们自己实现的 len() 函数封装成一个函数:
#自定义 len() 函数
def my_len(str):
length = 0
for c in str:
length = length + 1
return length
#调用自定义的 my_len() 函数
length = my_len(“http://www.nowcoder.com/link/pc_kol_bzwh”)
print(length)
#再次调用 my_len() 函数
length = my_len(“http://www.nowcoder.com/link/pc_kol_bzwh”)
print(length)
在函数内实现加减乘除,比如计算出前两天的订单,前两年的订单,每天只需要调用函数即可
6、循环
循环是相对抽象的点,你就想象计算机不断的运行一次逻辑,这次逻辑可以递增,递减,的各种运行,来实现一些诸如【累计求和】这样的逻辑
Python中的循环语句有 2 种,分别是 while 循环和 for 循环

add = “http://www.nowcoder.com/link/pc_kol_bzwh”
#for循环,遍历 add 字符串
for ch in add:
print(ch,end=“”)
运行结果为:
http://www.nowcoder.com/link/pc_kol_bzwh
我自己学的时候,其实比c来说更痛苦的是,这个“ch”他很不规范,一般在c里面就写ijk,好理解,实际上这里的ch就类比c里面的ijk,意思是有这么一个扫描机器人,对着“add”这个字符串扫过去,每扫一次记一个数,记到ch这个东西里,最后把它输出来。
循环可以做很多事,测试不同输入下(吧要输入的变成字符串,然后让程序遍历),函数的结果,然后输出结果(比如拟合的误差值,来直接判断哪个变量更合适)
以上,可以被认为是程序语言基础的部分,实际的基础还有很多,并且巩固上述知识点,有最基础的算法帮忙练习(比如实现累计求和,相加等)这些需要自己去补齐(例如if函数等,这个很好理解)
这里往下,我们开始python库里数据分析包的实践(其实主要就是调用函数)
二、数据分析python库实践
1、常用的库
库可以看做是一堆函数的集合,就像是一本,import 库名 就像是命令计算机打开这本字典
常用的库主要是三个,算上数据科学的可以有十个
分别是:
Pandas、Numpy(数据清晰、分析、探索、数组处理);Scikit-learn、TensorFlow、Keras(机器学习库)、Gradio(机器学习部署);SciPy、Statsmodels(统计专用库);matplotlib、Seaborn(可视化)
一般来说,学Pandas、Numpy、Plotly足够了
2、Numpy库
Numpy突出一个数组处理能力,你就把数组看成一个excel表格,在一个个单元格内储存着数据
结合上面的基础教程,当一个数据进来的时候,你应该准备好一个个箱子把数据装进去,这些动作涉及的函数就包括
(1)数组创建

例如:
import numpy as np
a = np.array([1,2,3,4])
b = np.array([,'点赞','分享','求关注'])print(a)
数组之间可运算(参考线性代数的逻辑),数组可和数组进行加减乘除
选择数组间的数字,基本的索引和切片,转置(transpose),三角函数运算,皆可百度,你只要知道他如何使用,数学上对于数组的运算皆可实现
3、Pandas库
pandas库的优势在于:对齐各种不同类型的数据源、集成时间序列功能、灵活处理缺失数据、合并出现在其它数据库的关系型运算
说白了,比numpy更灵活,有时候只用pandas也可以满足需求
学习思路是:
(1)熟悉series、两个数据类型
(2)常用的索引方法和

(3)索引、选取、计算和过滤逻辑学习思路如numpy
(4)介绍一些汇总统计可以利用dataframe去做,例如corr方法,cov方法
(5)处理缺失数据,包括dropna\fillna\isnull\notnull等函数
上述的两种库不要死记硬背函数,最好是记住他能做什么,比如可以处理数组,运算数组,切割、索引数组,可以填补缺失值、可以排序。
两个库的主要函数基本体现在数据的预处理中,从这里开始要意识到,你越来越接近需要统计学的地方了,当数据预处理之后,才到怎么做分析的地步(后面讲)
3、matpoltlib
很明确的说,80%的需求,excel可以满足。用python不是不行,优势是自由度更高,图表更接近、科研的样式;劣势是啥呢,不符合大部分工作场景,比如你有一组数据,做了个图,ppt发给老板,老板不满意,总不能自己写代码吧。一般都是把数据考进ppt或者excel可以直接在里面操作,效率更高。

闲话少说,我们开始
(1)创建空图表
Figure和subplot可以创建一个图表对象
fig = plt.figure()
ax1 = fig.add_subplot(2,2,1)
从这里开始就可以发布绘图命令,也就是把数据填入横纵坐标
(2)绘制图像
form numpy. import randn
plt.plot(randn(50).csmsum(),'k--')_
= ax1.hist(randn(100),bins=20,color = 'k',alpha = 0.3)
ax2.scatter(np.arange(30),np.arange(30)+3*randn(30))

你要知道图像的所有参数是可控的,包括颜色、标记、线型、坐标轴、间距、刻度、图例、注释,应有尽有。
所以为什么说他更适合科研,因为论文可能就只需要几张图;但是在工作中,可能一天就要好几张图来,你没时间写那么快。可视化的内容,了解即可。
(3)了解图的种类
线形图:
series(np.random.randn(10).cumsum(),index =np.arange(0,100,10))
柱状图:
data.polt(kind = ‘bar’,ax=axes[0],color=‘k’,alpha = 0.7)
直方图:hist(bins = 50)
饼图:plt.pie()
专题:数据聚合和分组运算
SQL里面有group by函数,python也可以做到,实际上,大部分基础的数据处理都属于分组运算,比如【每天】【所有城市】的订单,就是对日期和城市进行分组。不同的分组得到的结果就是指标在维度上的拆解。
事实上,python对数据的分组能力比sql要强大,只是在数据处理效率上弱一点,这就看你需要分组到什么地步,来决定你是不是需要把数据专门导出来用python处理
最基础的分组函数表示为:
假设数据组为两列指标data1&data2,维度为key1&ley2
group = df[‘data1’].groupby(dt[‘key’])
生成的group就是一个groupby对象,你可以理解为是一个准备好的分组器,然后需要配合各种聚合函数输出结果,
例如:
group.mean()
也可以连起来写
mean =df[‘data1’].groupby([df[‘key1’],df[‘key2’]]).mean()
一些常用的聚合函数如下:

专题:时间序列
时间序列在python可以概括为:时间函数处理+时间格式数据,充分描绘出时间序列的分布,加入各种运算,主要模块是:datetime、、calendar
比如当前的时间:now = datetime.now
datetime以毫秒形式储存时间,delta = datatime(2022,12,14) - datatime(2022,12,1)
时间函数也可以用字符串实现互相转化,
比如:value = '2022-12-24’
datetime.strptime(value,‘%Y-%m-%d’)
也可以用dateutil这个包中的parser.parse来解析日期,比如:
parse(‘2022-12-24’)
输出:datetime.datetime(2022,12,24,0,0)
datetime的格式定义

时间序列格式的变量,其实就是一列时间,加上各种各样的指标,比如1.1号,1;1.2号,记2
可以用如下方法定义:
dates =
[datetime(2022,12,1),datetime(2022,12,2),datetime(2022,12,3),datetime(2022,12,4),datetime(2022,12,5),datetime(2022,12,6),datetime(2022,12,7),datetime(2022,12,8)]
ts = Series(np…randn(6),index = dates)
就得到了两列时间序列的series变量
python可以做到:生成固定日期范围(pd.date_range),偏移固定日期量(nowday = datetime(2022,12,1)+3*day(),移动日期数据等,都属于数据预处理的操作。
以上,大部分能用python处理数据的工作基本已经分享完了,很多细节可以自己去敲代码和百度弥补,最后在实际的数据分析工作中,完成数据处理、展示的部分即可开展你的各种分析(比如通过不同的分组拆解指标,可视化找出下降的波动等)
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
点击领取,100%免费!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python70个实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】


















 1947
1947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









